Python trace库:自动化测试中的8大利器,提升测试效率
发布时间: 2024-10-14 18:04:03 阅读量: 25 订阅数: 37 

Python项目-自动办公-56 Word_docx_格式套用.zip
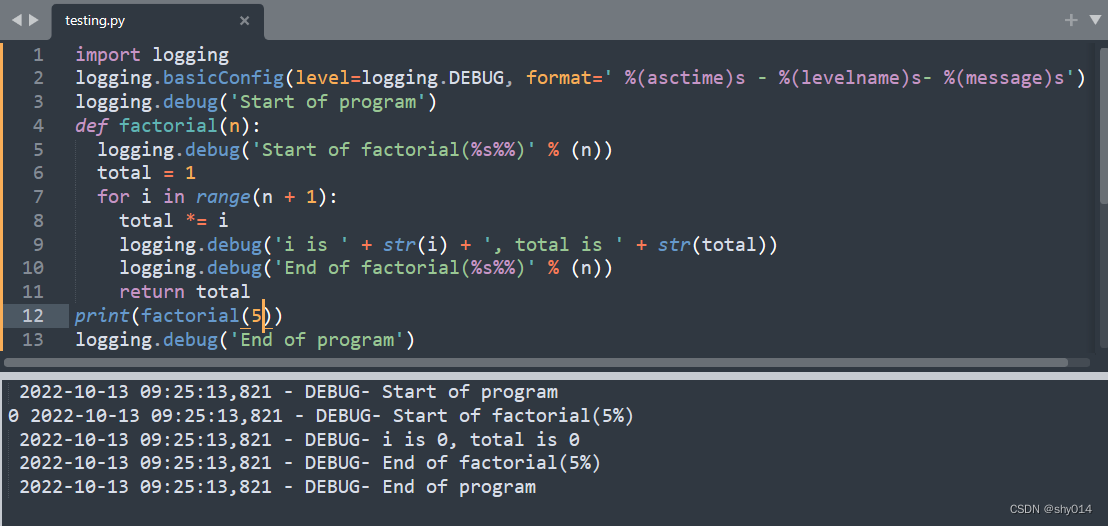
# 1. Python trace库简介
Python trace库是一个强大的工具,主要用于跟踪Python程序执行过程中的各种信息,包括函数调用、行执行等。它在自动化测试中扮演着重要的角色,可以帮助测试人员快速定位问题所在,并对测试覆盖范围进行深度分析。
## 1.1 Python trace库的概念和作用
### 概念
Trace库作为Python的一个标准库,提供了代码执行的跟踪功能。它可以记录程序运行过程中的每一步,并将跟踪的结果输出到标准输出或者文件中。
### 作用
- **代码审查**:帮助开发者理解代码执行流程。
- **性能分析**:识别程序中的性能瓶颈。
- **错误诊断**:提供错误发生的上下文信息,辅助调试。
- **覆盖率分析**:评估测试用例对代码的覆盖程度。
## 1.2 trace库在自动化测试中的重要性
### 自动化测试的挑战
在自动化测试过程中,确保测试覆盖率和提高代码质量是主要挑战之一。测试人员需要不断地优化测试用例,以覆盖更多的代码路径和边缘情况。
### trace库的应用
Trace库提供了一种手段,通过追踪代码的执行,使得测试人员能够:
- **评估测试覆盖**:了解哪些代码被执行了,哪些没有。
- **优化测试用例**:根据覆盖率结果,对测试用例进行补充和完善。
- **提升代码质量**:通过分析未覆盖的代码,发现潜在的缺陷和问题。
Trace库的这些功能对于提高自动化测试的效率和代码质量具有重要意义。
# 2. trace库的基础使用
## 2.1 安装和配置trace库
### 2.1.1 安装trace库的步骤
在本章节中,我们将详细介绍如何安装trace库,以及trace库的配置方法。首先,安装trace库是非常简单的,只需要使用Python的包管理工具pip即可完成。
```bash
pip install trace
```
在安装完成后,我们可以通过运行trace库的命令行工具来检查是否安装成功。
```bash
python -m trace --help
```
如果能够看到trace命令的使用帮助信息,则说明trace库已经成功安装。
### 2.1.2 trace库的配置方法
在本章节中,我们将介绍如何配置trace库以适应不同的使用场景。trace库提供了多种配置选项,可以通过命令行参数或者配置文件来设置。
#### 命令行参数配置
trace库的命令行工具支持多种参数,例如`--trace`用于指定需要跟踪的模块,`--count`用于生成调用次数统计信息。
```bash
python -m trace --trace --count myscript.py
```
#### 配置文件配置
除了命令行参数之外,trace库还支持使用配置文件来设置。配置文件通常是一个Python脚本,其中定义了一个`main`函数,该函数接受一个参数`trace_template`,用于配置trace的行为。
```python
# trace_config.py
import trace
import sys
def main(trace_template):
tracer = trace.Trace(
tracedirs=[sys.prefix, sys.exec_prefix],
trace=1,
count=1
)
tracer.run('execfile("myscript.py")')
if __name__ == '__main__':
main(trace_template=trace.Trace)
```
在配置文件中,我们可以设置跟踪的目录、是否启用跟踪以及是否生成调用次数统计信息等。
```bash
python trace_config.py
```
通过上述两种方式,我们可以灵活地配置trace库以满足不同的需求。在下一节中,我们将介绍trace库的基本功能和命令行工具的使用。
## 2.2 基本功能和命令
### 2.2.1 trace库的基本功能介绍
在本章节中,我们将深入探讨trace库的基本功能。trace库主要用于跟踪Python程序的执行,包括函数调用、执行时间、代码覆盖率等信息。
#### 函数调用跟踪
trace库可以跟踪程序中所有函数的调用情况,包括函数的调用次数、调用顺序等。
```python
def foo():
print("foo called")
def bar():
print("bar called")
foo()
bar()
```
```bash
python -m trace --trace myscript.py
```
执行上述命令后,trace库会输出函数调用的详细信息。
#### 代码覆盖率分析
除了跟踪函数调用外,trace库还可以分析代码覆盖率,即哪些代码被执行过,哪些没有。
```python
def foo():
print("foo called")
def bar():
print("bar called")
foo()
if __name__ == "__main__":
bar()
```
```bash
python -m trace --count --trace myscript.py
```
执行上述命令后,trace库会输出代码覆盖率的统计信息。
### 2.2.2 如何使用trace命令行工具
在本章节中,我们将详细介绍如何使用trace命令行工具。trace命令行工具提供了多种选项,可以通过`--help`参数查看所有可用选项。
```bash
python -m trace --help
```
trace命令行工具的主要选项包括:
- `--trace`:跟踪指定模块的执行。
- `--count`:生成调用次数统计信息。
- `--ignore-dir`:忽略指定目录的文件。
- `--ignore-module`:忽略指定模块的跟踪。
通过这些选项,我们可以灵活地使用trace命令行工具来跟踪程序的执行情况,分析代码覆盖率等。
## 2.3 trace库的数据分析
### 2.3.1 调用次数统计
在本章节中,我们将详细介绍如何使用trace库进行调用次数统计。trace库可以统计每个函数的调用次数,这对于性能分析和优化非常有帮助。
```python
def foo(n):
if n > 0:
foo(n-1)
def bar():
foo(5)
foo(3)
bar()
```
```bash
python -m trace --count myscript.py
```
执行上述命令后,trace库会输出每个函数的调用次数。
### 2.3.2 代码覆盖率分析
在本章节中,我们将介绍如何使用trace库进行代码覆盖率分析。代码覆盖率分析可以帮助我们了解哪些代码被执行过,哪些没有,这对于测试覆盖率的提升非常有帮助。
```python
def foo():
print("foo called")
def bar():
print("bar called")
foo()
if __name__ == "__main__":
bar()
```
```bash
python -m trace --count --trace myscript.py
```
执行上述命令后,trace库会输出代码覆盖率的统计信息,包括被执行过的代码行和未被执行的代码行。
在本章节中,我们介绍了trace库的基础使用,包括安装、配置、基本功能和命令行工具的使用。在下一章中,我们将深入探讨trace库的进阶功能,包括排除特定文件或目录、使用限制条件过滤输出等。
# 3. 深入理解和使用trace库
在本章节中,我们将深入探讨Python trace库的高级功能和使用技巧,这些内容对于有经验的Python开发者来说将是非常有价值的。我们将介绍如何排除特定文件或目录、使用限制条件过滤输出、跟踪函数调用和执行时间以及生成错误跟踪报告等高级用法。此外,我们还将探讨如何将trace库集成到自动化测试和性能测试中,以及如何在大型项目和分布式测试环境中应用trace库。
## 3.1 进阶功能介绍
### 3.1.1 排除特定文件或目录
在使用trace库进行代码分析时,可能需要排除一些特定的文件或目录,比如第三方库文件或者生成的临时文件。这样可以确保分析结果更加清晰,只关注我们感兴趣的代码部分。
```python
import trace
import sys
# 创建Trace对象
tracer = trace.Trace(
tracedirs=[sys.prefix, sys.exec_prefix], # 设置追踪的目录
trace=1, # 设置追踪级别
ignoredirs=[sys.prefix + '/lib'] # 设置忽略的目录
)
# 执行追踪
tracer.run('python hello.py')
```
在上述代码中,我们创建了一个`Trace`对象,并设置了要追踪的目录以及要忽略的目录。当运行追踪时,只有位于`tracedirs`中的目录会被追踪,而位于`ignoredirs`中的目录则会被忽略。
### 3.1.2 使用限制条件过滤输出
有时我们可能只对满足特定条件的函数调用感兴趣,例如只分析执行时间超过某个阈值的函数。Trace库提供了一种灵活的方式来自定义追踪过滤条件。
```python
import trace
import sys
def filter_func(frame, event, arg):
# 只跟踪执行时间超过1秒的函数
return event == 'call' or (event == 'return' and arg > 1)
tracer = trace.Trace(
trace=1,
filter=filter_func
)
# 执行追踪
tracer.run('python hello.py')
```
在上述代码中,我们定义了一个`filter_func`函数,它根据事件类型和参数来决定是否追踪某个事件。在这个例子中,我们只追踪执行时间超过1秒的函数调用。
## 3.2 运行时数据跟踪
### 3.2.1 如何跟踪函数调用和执行时间
Trace库可以用来跟踪函数的调用次数以及执行时间,这对于性能调优和代码审查非常有帮助。
```python
import trace
import sys
import time
def test_function():
# 模拟一个耗时操作
time.sleep(0.5)
tracer = trace.Trace(
tracedirs=[sys.prefix, sys.exec_prefix],
trace=1
)
# 启动计时
start_time = time.time()
tracer.run('python -c "test_function()"')
# 结束计时
end_time = time.time()
print(f"Total time taken: {end_time - start_time} seconds")
```
在上述代码中,我们定义了一个简单的耗时函数`test_fun

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python trace库是一个强大的工具,可帮助开发人员跟踪和调试代码。本专栏深入探讨了trace库的各个方面,从入门指南到高级用法。涵盖了7种掌握代码跟踪的技巧、代码追踪原理、5个调试复杂代码流程的真实案例、性能优化中的应用、监控和分析生产环境代码的策略、构建高效问题诊断流程的步骤、自动化测试中的利器、与其他调试工具的比较、解决真实世界问题的策略、避免常见错误的建议、安全使用调试工具的指南、评估和优化调试过程的步骤、扩展和自定义调试体验的技巧、跟踪并发代码的挑战和策略、监控和调试Web应用的关键点、调试数据处理流程的技巧、调试和优化模型训练的最佳实践、监控云端代码执行的策略、调试移动应用后台逻辑的技巧,以及与IDE和编辑器的集成方法。通过阅读本专栏,开发人员可以全面了解trace库,并有效地利用它来提高代码调试效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
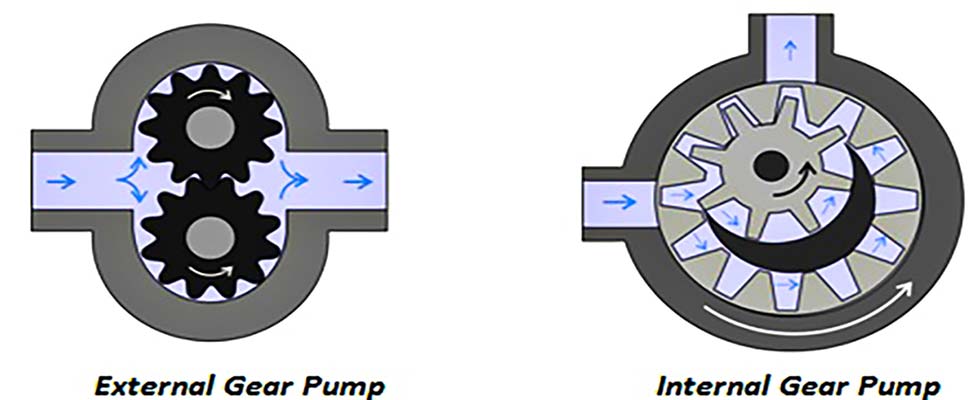
案例揭秘:Pumplinx如何在外啮合齿轮泵设计中大显神威
# 摘要
Pumplinx技术在啮合齿轮泵设计中的应用是本文研究的核心,详细探讨了Pumplinx在啮合齿轮泵设计中的关键作用,包括工作原理、仿真分析、性能优化和故障诊断等方面。通过对啮合齿轮泵的基础工作原理以及Pumplinx技术的理论概述,文章阐述了Pumplinx如何突破传统设计方法的瓶颈,以及在实际工程应用中的显著优势。本文还着重介绍了Pumplinx技术的进
【HP MSA 2040 升级专家】:平滑升级存储系统,步骤全解析

# 摘要
本文全面介绍了HP MSA 2040存储系统的升级过程,包括准备工作、实际操作流程以及升级后的优化和维护措施。首先,详述了制定升级计划、系统及数据备份的重要性,并强调了环境检查和验证的必要性。在实际操作中,文章指导了如何下载和安装升级软件,配置存储系统,并进行了功能验证与性能测试。升级后,探讨了系统监控、性能调优以及如何应对潜在的系统问题,并强调了持续
ForceControl-V7.0自定义脚本和插件开发:扩展软件的核心功能

# 摘要
本文详细介绍了ForceControl-V7.0的使用和开发技巧,包括自定义脚本与插件的开发环境搭建、脚本语言基础、逻辑实现、调试与测试,以及插件架构、设计原则、开发流程和部署管理。此外,还探讨了高级脚本应用,如与外部系统集成、性能优化和安全性考虑。最后,通过案例研究与实战演练,展示了自定义脚本和插件在实际业务中的应用场景,以及故障排除和性能优化的实战技巧。本文旨在
【Calibre转换进阶必学】:提升转换效率和质量的高级技巧

# 摘要
本文全面介绍和深入分析了Calibre转换工具的基础知识、转换原理、效率提升技巧、质量控制方法以及面临的未来挑战和展望。首先,概述了Calibre转换的基础知识和整体框架。接着,深入探讨了其转换引擎的核心机制、元数据处理流程、错误诊断与修复策略。文章还提供了提高Calibre转换效率的高级配置技巧、插件和脚本使用、硬件加速与云服务集成等方法。此外,详细讨论了确保转换质量的参数调整、文本处理、图
MicroLogix 1100维护与服务:延长控制器寿命的黄金策略

# 摘要
本文全面介绍了MicroLogix 1100控制器的应用、维护和服务支持策略。首先概述了控制器的基本特点及其在工业自动化中的应用,接着深入探讨了控制器的硬件和软件维护方法,包括硬件清洁检查、软件更新以及系统监测。文章还讨论了服务支持的重要性,包括标准化服务流程、技术支持资源和预防性维护计划。此外
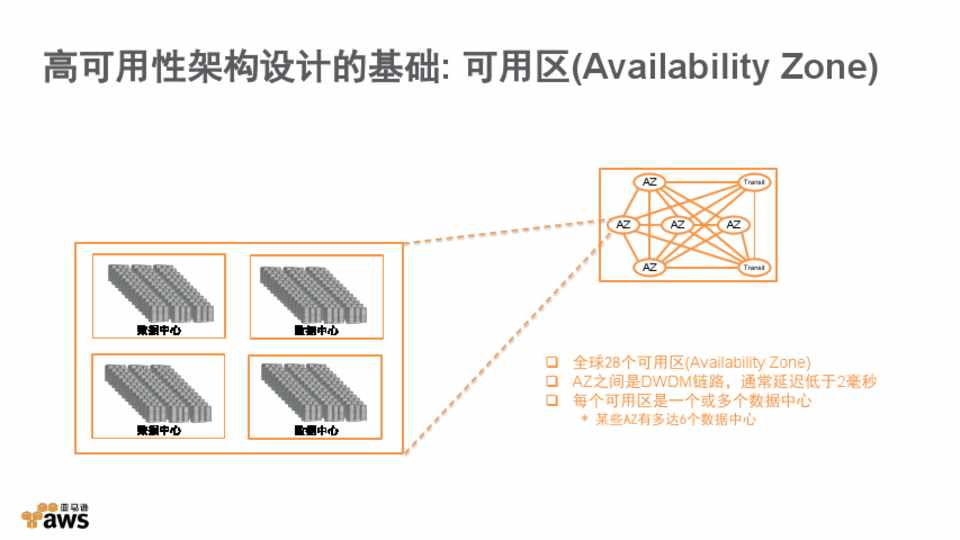
【INCA专家谈】:揭秘最佳实践,分享在高可用性架构中的关键角色
# 摘要
高可用性架构是现代信息技术基础设施中的核心需求,它确保系统在面对硬件故障、软件缺陷甚至自然灾害时仍能持续运作。本文首先概述了高可用性架构的概念、定义以及衡量标准,接着深入探讨了其理论基础,包括设计原则、容量规划与资源管理。文章进一步分析了实现高可用性的关键技术,如多层负载均衡、数据持久化与备份策略以及故障转移与自我修复机制。此外,本文通过实践案例展示了高可用性在分布式系统、云服
实习后的反思:揭秘计算机专业大学生如何在实习中规划职业道路

# 摘要
本文探讨了计算机专业学生实习经验对于职业规划的重要性,并对理论基础与实践演练两方面进行了深入分析。首先概述了计算机科学领域的关键分支和职业路径,进而探讨了实习经历中项目管理、技术能力提升和职业素养发展等实践环节。本文还分析了实习生面临的挑战与机遇,并讨论了如何将实习经验转化为职业优势。
【CODESYS面向对象编程深度解析】:掌握方法、属性、动作接口的终极秘籍

# 摘要
本文旨在全面介绍CODESYS平台下的面向对象编程(OOP)实践,从基础理论到高级应用,为读者提供系统的知识框架和实操指导。首先概述CODESYS的OOP环境和理论基础,详细探讨类和对象的定义、封装、继承和多态性等核心概念。继而,文章深入到CODESYS特有的类结构和设计原则,涵盖SOLID原则和设计模式的实际应用。紧接着,通过
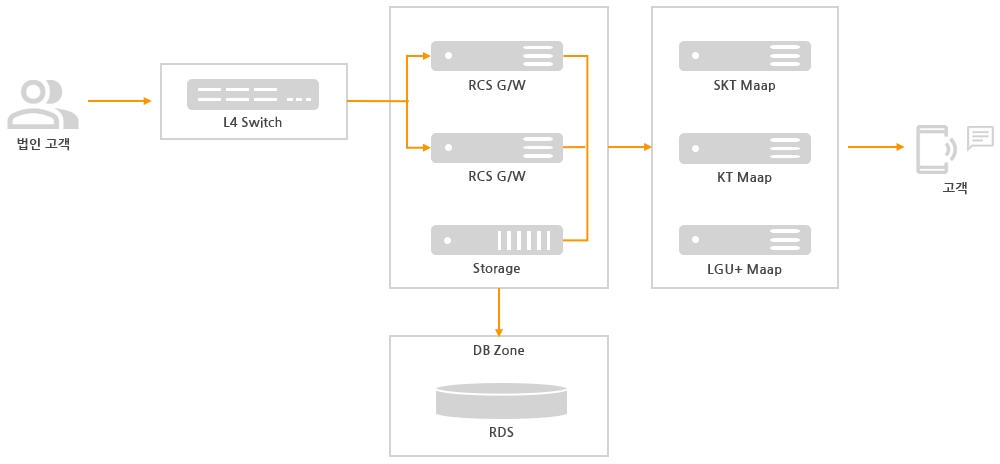
【RCS-2000 V3.1.3新版本更新】:特性亮点+迁移指南+ERP集成
# 摘要
本文详细介绍了RCS-2000 V3.1.3版本的更新亮点,包括核心性能的显著提升、用户界面的革新和安全性增强。深入分析了性能优化的原理与效果,以及新界面设计给用户带来的操作便捷性。文中还提供了详尽的迁移指南,包括准备工作、实施步骤和系统优化,旨在确保用户能够顺利迁移到新版本并最大化地利用其特性。进一步地,本文探讨了RCS-2000 V3.1.3与ERP系统集成的实践,以
硬件描述语言仿真深入探讨:Quartus9.0 HDL仿真秘籍
# 摘要
本文全面介绍了硬件描述语言(HDL)仿真在现代电子设计中的应用,重点阐述了Quartus II这一主流集成设计环境的仿真功能。从基础环境配置到HDL语法基础,再到高级仿真技巧和应用案例,本文详细讨论了如何通过Quartus II进行有效的项目设计、仿真测试、时序分析、功耗优化和参数化设计。通过对具体仿真模型、仿真库、测试平台的搭建以及仿
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )