ActiveMQ消息持久化及消息存储机制详解
发布时间: 2024-02-24 20:44:29 阅读量: 56 订阅数: 44 
# 1. ActiveMQ 消息持久化简介
## 1.1 消息持久化的概念
消息持久化是指在消息发送和接收过程中,保证消息不会因为系统故障或断电而丢失的机制。通过持久化机制,消息可以被可靠地存储和恢复,确保消息的可靠性和一致性。
## 1.2 ActiveMQ 中消息持久化的作用
在ActiveMQ中,消息持久化能够确保即使服务器宕机或重启,消息仍能够被恢复,不会丢失。这对于需要可靠消息传递的应用场景非常重要,比如金融交易、订单处理等。
## 1.3 消息持久化的优势和适用场景
使用消息持久化能够提供数据的持久性保证,即使在系统故障或重启的情况下也能够保证消息的完整性。适用于对数据一致性要求较高的应用场景,可以降低系统出现异常时数据丢失的风险。
希望这些内容能够帮助到你。接下来,我们可以继续编写第二章的内容,请问你是否对第二章的内容有要求?
# 2. ActiveMQ 消息存储机制
ActiveMQ 的消息存储机制是整个消息系统的核心部分,它直接关系到消息的可靠性和性能。在本章中,我们将深入探讨 ActiveMQ 中的消息存储结构、消息存储的策略及配置,以及消息存储的优化与性能调优。让我们一起来详细了解 ActiveMQ 的消息存储机制。
### 2.1 ActiveMQ 中的消息存储结构
在 ActiveMQ 中,消息存储主要分为两部分:持久化消息和非持久化消息。持久化消息会被存储在磁盘上,而非持久化消息则只存在于内存中。ActiveMQ 的消息存储结构由消息日志、索引文件和页文件三部分组成。消息日志用于记录消息的发送与接收情况,索引文件用于检索消息的位置和内容,而页文件则用于存储消息的具体内容。
### 2.2 消息存储的策略及配置
消息存储的策略是指在不同场景下如何选择合适的消息存储方式。ActiveMQ 支持多种消息存储策略,如 JDBC、LevelDB、KahaDB 等。在配置消息存储时,需要考虑到消息的持久化要求、高可用性和性能等因素,通过合理的配置来达到最佳的存储效果。
```java
// 示例:配置使用KahaDB持久化存储
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:amq="http://activemq.apache.org/schema/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://activemq.apache.org/schema/core
http://activemq.apache.org/schema/core/activemq-core.xsd">
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}">
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
</broker>
</beans>
```
### 2.3 消息存储的优化与性能调优
为了提高消息存储的性能,我们可以对消息存储进行优化和调优。一般来说,可以通过批量处理、异步写入、索引优化等方式来提升消息存储的性能。在实际应用中,根据业务场景和负载情况,合理地进行消息存储的优化能够显著提升系统的性能和稳定性。
通过本章的学习,我们对 ActiveMQ 的消息存储机制有了更深入的了解,包括消息存储结构、存储策略及配置,以及优化与性能调优。在下一章,我们将进一步探讨 ActiveMQ 消息持久化的实现方式。
# 3. ActiveMQ 消息持久化实现方式
消息持久化是消息中间件中一个非常重要的特性,它可以确保即使在消息发送和接收之间出现故障的情况下,消息仍然可以被正常地传递。在ActiveMQ中,消息的持久化可以通过多种方式来实现,包括文件系统消息存储、数据库消息存储以及其他常见的消息持久化方式。
#### 3.1 文件系统消息存储
文件系统消息存储是ActiveMQ中最常见的消息持久化方式之一。它通过将消息持久化存储在本地文件系统中,确保消息在重启、宕机等情况下不会丢失。文件系统消息存储通常通过配置ActiveMQ的持久化适配器来实现,以下是一个简单的配置示例:
```xml
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost">
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
<!-- 其他配置参数 -->
</broker>
```
在上面的示例中,`kahaDB` 就是ActiveMQ中用于文件系统消息存储的持久化适配器,它将持久化的消息存储在 `${activemq.data}/kahadb` 目录下。
#### 3.2 数据库消息存储
除了文件系统消息存储外,ActiveMQ还提供了基于数据库的消息存储方式。通过将消息持久化存储在数据库中,可以更好地支持分布式部署和高可用性的需求。在ActiveMQ中,可以轻松地配置使用诸如MySQL、PostgreSQL、Oracle等常见的数据库作为消息持久化存储介质,以下是一个简单的配置示例:
```xml
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
<!-- 其他配置参数 -->
</broker>
```
上述示例中,`jdbcPersistenceAdapter`是ActiveMQ中用于数据库消息存储的持久化适配器,通过配置`dataSource`参数,可以指定使用的数据库连接池。
#### 3.3 其他常见的消息持久化方式
除了文件系统消息存储和数据库消息存储之外,ActiveMQ还支持诸如 LevelDB、JDBC、JDBC Master Slave 等其他常见的消息持久化方式。在实际应用中,根据具体的业务场景和需求,可以选择合适的持久化方式来确保消息的可靠性和稳定性。
通过本章的介绍,我们了解了ActiveMQ中消息持久化的实现方式,包括文件系统消息存储、数据库消息存储以及其他常见的消息持久化方式。在实际应用中,合理选择并配置消息持久化方式,可以有效地提升系统的可靠性和稳定性。
# 4. ActiveMQ 消息存储与高可用性
消息存储与高可用性是消息中间件非常重要的特性,对于保证消息系统的稳定性和可靠性至关重要。在ActiveMQ中,消息存储与高可用性是非常值得深入了解和探讨的话题。
### 4.1 主从复制机制下的消息存储
在ActiveMQ的高可用性架构中,主从复制(Master-Slave)是常见的方式之一。通过主从复制机制可以实现消息的热备份,一旦主节点宕机,从节点可以立即接管服务,确保消息系统的稳定运行。在主从复制机制下,消息存储的架构也需要相应的调整和配置,以保证数据的一致性和可靠性。
```java
// Java代码示例:ActiveMQ 主从复制消息存储配置
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:amq="http://activemq.apache.org/schema/core">
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="master"
dataDirectory="/data/master" start="true">
<networkConnector name="master-to-slave" uri="static:(tcp://slave:61616)"
duplex="false" userName="user" password="password" />
</broker>
</beans>
```
**代码说明:** 上述配置是在ActiveMQ中设置主节点(master)的配置,其中配置了数据存储目录和主从复制的连接参数。
### 4.2 ActiveMQ 集群中的消息存储架构
在ActiveMQ集群中,消息存储架构需要考虑多个节点之间的数据同步和负载均衡。通过合理的消息存储架构设计,可以最大程度地提升消息系统的承载能力和稳定性。
```python
// Python代码示例:ActiveMQ 集群消息存储架构设计
cluster = {
"broker-1": {
"host": "localhost",
"port": 61616,
"storage": "jdbc",
"database_url": "jdbc:postgresql://localhost:5432/activemq",
"username": "admin",
"password": "admin"
},
"broker-2": {
"host": "localhost",
"port": 61617,
"storage": "kahaDB",
"data_directory": "/data/kahadb"
}
}
```
**代码说明:** 上述代码是一个ActiveMQ集群的消息存储架构设计示例,包括了两个节点(broker-1和broker-2)的配置信息,包括存储类型、数据库连接信息等。
### 4.3 同步与异步复制的比较与应用
在消息存储的高可用性设计中,同步复制和异步复制是两种常见的数据复制方式。它们分别有着不同的特点和适用场景,需要根据实际需求进行选择和配置。
```go
// Go代码示例:ActiveMQ 消息存储的同步与异步复制配置
type ReplicationConfig struct {
SyncReplication bool
ReplicationBuffer int
}
func main() {
config := ReplicationConfig{
SyncReplication: false,
ReplicationBuffer: 1024,
}
if config.SyncReplication {
fmt.Println("使用同步复制")
} else {
fmt.Println("使用异步复制,缓冲区大小为", config.ReplicationBuffer)
}
}
```
**代码说明:** 上述示例展示了通过Go语言配置ActiveMQ消息存储的同步与异步复制方式,根据配置参数选择不同的复制方式。
希望以上内容能够满足您的需求。如果还需要其他章节内容或有其他问题,请随时告诉我。
# 5. ActiveMQ 消息丢失与消息重放机制
在实际的消息系统中,消息丢失是一个常见并且严重的问题,可能会导致系统数据不一致或者业务逻辑错误。因此,消息系统在设计时需要考虑消息丢失的可能性,并采取相应的措施来保证消息的可靠性。本章将重点介绍ActiveMQ中消息丢失与消息重放机制的实现原理和最佳实践。
#### 5.1 消息丢失的常见原因分析
消息丢失可能由多种原因导致,主要包括网络异常、消息生产者或消费者异常、消息存储异常等情况。以下是一些常见的导致消息丢失的原因:
1. 网络异常:在消息传输过程中,由于网络问题导致消息无法正常发送到目标节点;
2. 消息生产者异常:消息生产者由于程序错误或者异常退出,未能成功发送消息;
3. 消息消费者异常:消息消费者在处理消息时发生错误或者崩溃,导致消息未能被正常消费;
4. 消息存储异常:消息存储系统出现故障或者数据丢失,导致消息不能被正确保存。
#### 5.2 ActiveMQ 中的消息重放机制
ActiveMQ提供了消息重放机制来保证消息的可靠性传输。通过消息重放机制,即使消息在传输过程中发生丢失,也能够重新发送消息,确保消息被正确消费。以下是消息重放机制的基本实现原理:
1. 消息重发:ActiveMQ允许配置消息重发的次数和间隔时间,当消息未被确认消费时,系统会根据配置进行消息的重发;
2. 事务机制:在使用事务模式发送消息时,消息在被消费者确认消费之前不会真正从队列中移除,确保消息不会因为消费者异常而丢失;
3. 消费者确认:消费者可以通过确认机制告知ActiveMQ消息已经被正确消费,如果消费者因为异常退出,消息会被重新发送。
#### 5.3 保证消息不丢失的最佳实践
为了保证消息不丢失,我们可以采取以下最佳实践:
1. 设置消息重发机制:合理配置消息重发次数和间隔时间,确保消息在出现异常时能够被重新发送;
2. 使用事务模式发送消息:确保消息在被消费者确认消费前不会从队列中移除,避免消息丢失;
3. 增加监控机制:定期检查消息系统的健康状态,及时发现问题并进行处理;
4. 异常处理机制:在消息生产者和消费者中添加异常处理机制,保证程序的稳定性和可靠性。
通过以上的最佳实践,我们可以有效地提高消息系统的可靠性和稳定性,避免消息丢失对系统造成的损失。
希望以上内容能够对您理解ActiveMQ中的消息丢失与消息重放机制有所帮助。
# 6. ActiveMQ 消息持久化的最佳实践
消息持久化是保证消息系统可靠性的重要手段,以下是一些关于消息持久化的最佳实践,希望对你有所帮助。
6.1 怎样选择合适的消息存储机制
在选择消息存储机制时,需要考虑数据量、性能、可靠性以及业务需求。一般的选择包括文件系统存储和数据库存储。对于小型应用和数据量较小的场景,可以选择文件系统存储,而对于大型应用和需要复杂查询的场景,可以选择数据库存储。在进行选择时,一定要充分考虑业务特点和系统需求。
```python
# Python代码示例
def choose_storage_mechanism(data_volume, performance, reliability, business_needs):
if data_volume == "small" and performance == "good" and reliability == "acceptable":
return "File system storage"
elif data_volume == "large" and performance == "high" and reliability == "high" and business_needs == "complex queries":
return "Database storage"
else:
return "Consult with system architects"
```
代码总结:根据数据量、性能、可靠性和业务需求选择合适的消息存储机制。
结果说明:根据具体的情况,选择合适的消息存储机制能更好地满足业务需求。
6.2 如何做好消息持久化的监控与维护
对于消息持久化,监控与维护同样重要。可以通过监控消息存储的数据量、写入速度、读取速度等指标来了解系统运行情况,并设置相应的告警机制。在维护方面,定期对消息存储进行清理,删除过期数据或者进行数据迁移,以确保系统的稳定性和性能。
```java
// Java代码示例
public class MessagePersistenceMonitor {
public void monitorStorage(String storageType, int dataVolume, int writeSpeed, int readSpeed) {
// 监控存储指标并设置告警机制
// ...
}
public void maintainStorage(String storageType) {
// 对消息存储进行定期清理和数据迁移
// ...
}
}
```
代码总结:监控消息存储的指标并设置告警机制,定期维护消息存储以确保系统稳定性。
结果说明:通过监控与维护,可以及时发现问题并保持消息存储系统的良好状态。
6.3 消息持久化与业务系统集成的注意事项
在将消息持久化应用到业务系统中时,需要注意数据一致性、事务操作和高可用性。确保消息的持久化存储与业务系统的操作相互配合,保证数据的完整性。同时,在高可用性要求较高的场景下,需要考虑消息存储的集群部署,以提高系统的容错能力。
```javascript
// JavaScript代码示例
function integrateWithBusinessSystem(persistenceType, dataConsistency, transactionOperation, highAvailability) {
if (persistenceType === "database" && dataConsistency === "strong" && transactionOperation === "supported" && highAvailability === "required") {
// 需要集成消息存储的高可用性部署
// ...
} else {
// 其他集成注意事项
}
}
```
代码总结:在集成业务系统时,根据数据一致性、事务操作和高可用性需求进行相关处理。
结果说明:合理集成消息持久化与业务系统,能够更好地保证系统的运行稳定性和数据的完整性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨Apache ActiveMQ消息中间件的各个方面,包括消息队列概念与基本工作原理、Java应用如何与ActiveMQ进行消息发送与接收、消息持久化与存储机制、消息传递方式与分发机制、消息的事务处理与确认机制、消息监听器的作用、消息的可靠性传递与高可用性保证、虚拟主题的使用与配置、消息过滤与选择性消费、定时消息与延时消息实现原理、分布式消息队列与集群部署、消息队列监控与性能调优、消息事务与Spring事务管理结合、消息的序列化与反序列化,以及SSL加密通信与安全机制的实现。旨在帮助读者全面深入地了解ActiveMQ,并掌握其在实际应用中的各种技术实现与应用场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CMOS集成电路设计实战解码】:从基础到高级的习题详解,理论与实践的完美融合
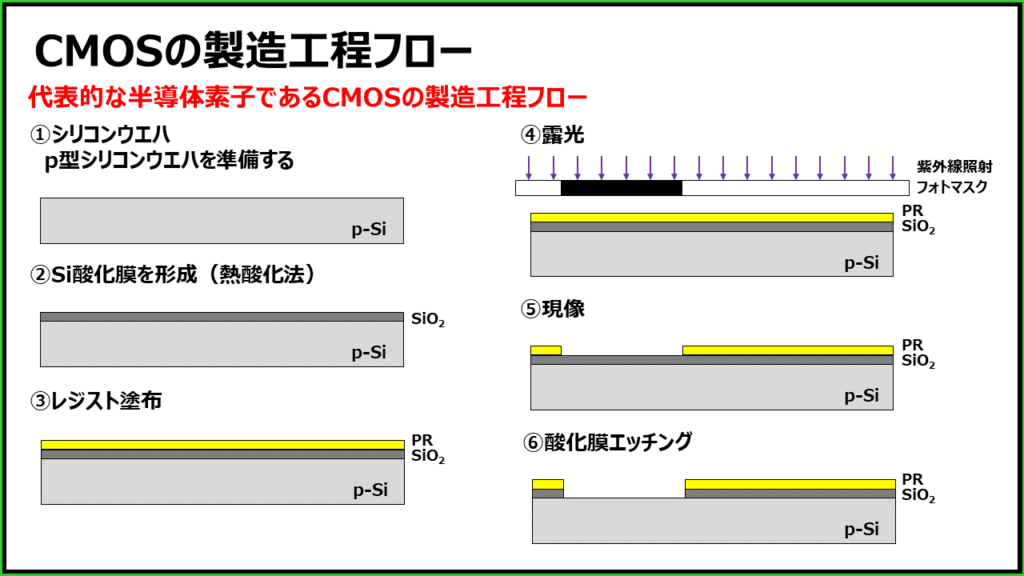
# 摘要
CMOS集成电路设计是现代电子系统中不可或缺的一环,本文全面概述了CMOS集成电路设计的关键理论和实践操作。首先,介绍了CMOS技术的基础理论,包括晶体管工作机制、逻辑门设计基础、制造流程和仿真分析。接着,深入探讨了CMOS集成电路的设计实践,涵盖了反相器与逻辑门设计、放大器与模拟电路设计,以及时序电路设计。此外,本文还
CCS高效项目管理:掌握生成和维护LIB文件的黄金步骤

# 摘要
本文深入探讨了CCS项目管理和LIB文件的综合应用,涵盖了项目设置、文件生成、维护优化以及实践应用的各个方面。文中首先介绍了CCS项目的创建与配置、编译器和链接器的设置,然后详细阐述了LIB文件的生成原理、版本控制和依赖管理。第三章重点讨论了LIB文件的代码维护、性能优化和自动化构建。第四章通过案例分析了LIB文件在多项目共享、嵌入式系统应用以及国际化与本地化处理中的实际应
【深入剖析Visual C++ 2010 x86运行库】:架构组件精讲

# 摘要
Visual C++ 2010 x86运行库是支持开发的关键组件,涵盖运行库架构核心组件、高级特性与实现,以及优化与调试等多个方面。本文首先对运行库的基本结构、核心组件的功能划分及其交互机制进行概述。接着,深入探讨运行时类型信息(RTTI)与异常处理的工作原理和优化策略,以及标准C++内存管理接口和内存分配与释放策略。本文还阐述了运行库的并发与多线程支持、模板与泛型编程支持,
从零开始掌握ACD_ChemSketch:功能全面深入解读
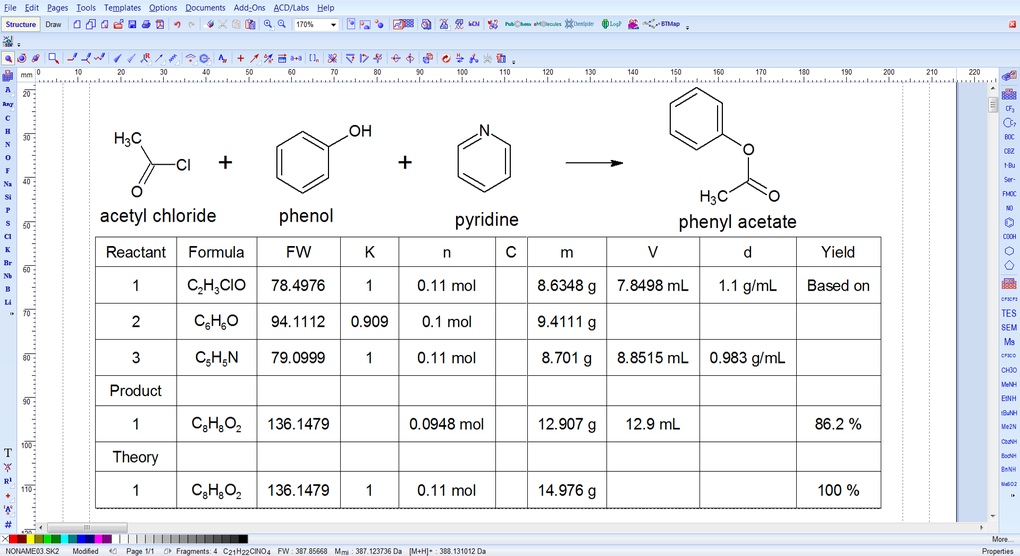
# 摘要
ACD_ChemSketch是一款广泛应用于化学领域的绘图软件,本文概述了其基础和高级功能,并探讨了在科学研究中的应用。通过介绍界面布局、基础绘图工具、文件管理以及协作功能,本文为用户提供了掌握软件操作的基础知识。进阶部分着重讲述了结构优化、立体化学分析、高
蓝牙5.4新特性实战指南:工业4.0的无线革新

# 摘要
蓝牙技术是工业4.0不可或缺的组成部分,它通过蓝牙5.4标准实现了新的通信特性和安全机制。本文详细概述了蓝牙5.4的理论基础,包括其新增功能、技术规格,以及与前代技术的对比分析。此外,探讨了蓝牙5.4在工业环境中网络拓扑和设备角色的应用,并对安全机制进行了评估。本文还分析了蓝牙5.4技术的实际部署,包
【Linux二进制文件执行错误深度剖析】:一次性解决执行权限、依赖、环境配置问题(全面检查必备指南)
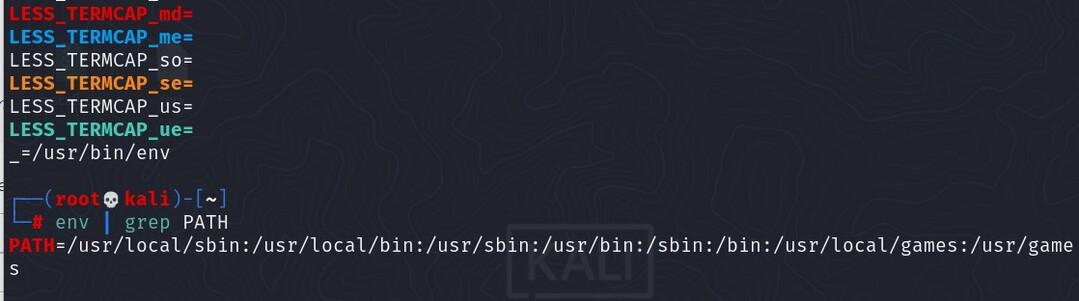
# 摘要
本文详细探讨了二进制文件执行过程中遇到的常见错误,并提出了一系列理论与实践上的解决策略。首先,针对执行权限问题,文章从权限基础理论出发,分析了权限设置不当所导致的错误,并探讨了修复权限的工具和方法。接着,文章讨论了依赖问题,包括依赖管理基础、缺失错误分析以及修复实践,并对比了动态与静态依赖。环境配置问题作为另一主要焦点,涵盖了
差分输入ADC滤波器设计要点:实现高效信号处理
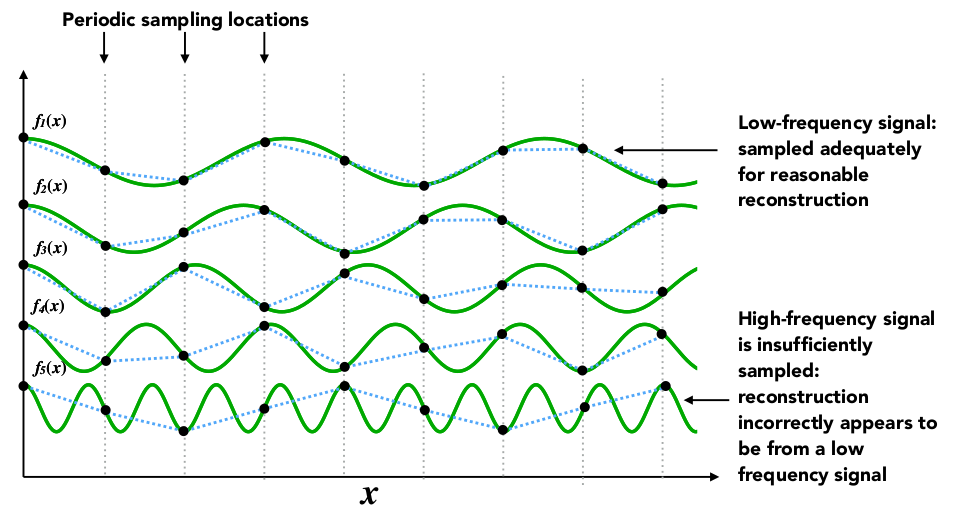
# 摘要
本论文详细介绍了差分输入模数转换器(ADC)滤波器的设计与实践应用。首先概述了差分输入ADC滤波器的理论基础,包括差分信号处理原理、ADC的工作原理及其类型,以及滤波器设计的基本理论。随后,本研究深入探讨了滤波器设计的实践过程,从确定设计规格、选择元器件到电路图绘制、仿真、PCB布局,以及性能测试与验证的方法。最后,论文分析了提高差分输入ADC滤波器性能的优化策略,包括提升精
【HPE Smart Storage性能提升指南】:20个技巧,优化存储效率

# 摘要
本文深入探讨了HPE Smart Storage在性能管理方面的方法与策略。从基础性能优化技巧入手,涵盖了磁盘配置、系统参数调优以及常规维护和监控等方面,进而探讨高级性能提升策略,如缓存管理、数据管理优化和负载平衡。在自动化和虚拟化环境下,本文分析了如何利用精简配置、快照技术以及集成监控解决方案来进一步提升存储性能,并在最后章节中讨论了灾难恢复与备份策略的设计与实施。通过案
【毫米波雷达性能提升】:信号处理算法优化实战指南
# 摘要
毫米波雷达信号处理是一个涉及复杂数学理论和先进技术的领域,对于提高雷达系统的性能至关重要。本文首先概述了毫米波雷达信号处理的基本理论,包括傅里叶变换和信号特性分析,然后深入探讨了信号处理中的关键技术和算法优化策略。通过案例分析,评估了现有算法性能,并介绍了信号处理软件实践和代码优化技巧。文章还探讨了雷达系统的集成、测试及性能评估方法,并展望了未来毫米波雷达性能提升的技术趋
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )