【mmap文件操作详解】:如何在Python中高效读写大型文件?
发布时间: 2024-10-13 09:35:19 阅读量: 4 订阅数: 6 

# 1. mmap文件操作的基本概念
## 1.1 内存映射的定义
内存映射(memory-mapped file)是一种将磁盘文件内容直接映射到进程地址空间的技术,使得文件的读写操作可以通过普通的内存访问来进行。这种机制允许程序访问文件数据时不需要显式的文件I/O操作,而是像访问内存一样简单。这不仅可以提高文件操作的效率,还可以简化程序的设计。
## 1.2 mmap的适用场景
内存映射特别适用于处理大型文件,因为它不需要将整个文件加载到内存中就可以开始读写操作。在需要频繁访问文件数据,或者多个进程需要共享文件数据时,使用内存映射可以极大地提高性能和效率。
```python
import mmap
# 打开文件,准备进行内存映射
with open('example.txt', 'r+b') as f:
# 创建内存映射对象
map = mmap.mmap(f.fileno(), 0)
# 读取映射区域的数据
data = map.read(10)
print(data)
# 关闭映射
map.close()
```
以上代码展示了如何在Python中使用`mmap`模块打开一个文件,并创建一个内存映射对象,然后读取映射区域的数据。这是一个简单的例子,用于展示mmap的基本使用。在后续章节中,我们将深入探讨mmap的更多细节和高级用法。
# 2. mmap文件操作的理论基础
在本章节中,我们将深入探讨内存映射(mmap)的理论基础,包括其概念、工作原理以及在文件操作中的优势。我们将详细分析mmap与传统文件操作方式的对比,并探讨mmap在大型文件处理和多进程共享内存场景中的应用。
### 2.1 内存映射的概念和原理
#### 2.1.1 内存映射的基本概念
内存映射是一种将磁盘文件内容映射到进程的地址空间的技术。在内存映射中,文件的内容被看作是在进程的虚拟内存地址空间中的一个连续区域。进程可以通过读写这个虚拟内存区域来读写磁盘上的文件,而不需要进行显式的文件I/O操作。
这种方式的主要优点是简化了文件操作的复杂性,因为可以像操作内存一样直接操作文件内容。内存映射通常用于大文件处理,因为它可以提高文件访问的效率。
#### 2.1.2 内存映射的工作原理
内存映射的工作原理涉及操作系统内核的几个关键组件:文件系统、虚拟内存管理器以及内存管理单元(MMU)。当进程调用`mmap`系统调用时,操作系统会将文件的部分或全部内容映射到进程的地址空间。
这个过程中,操作系统的虚拟内存管理器会创建一个内存映射区域,并将其与文件描述符关联起来。当进程访问这个内存区域时,MMU将虚拟地址转换为物理地址,如果对应的物理页不在物理内存中,操作系统会触发一个缺页中断,将文件内容从磁盘加载到物理内存中。
### 2.2 mmap在文件操作中的优势
#### 2.2.1 与传统文件操作方式的对比
传统的文件操作方式涉及使用如`read`和`write`这样的系统调用,这些调用需要显式地将数据从文件复制到用户空间,然后再从用户空间复制回内核空间。
相比之下,内存映射方式允许进程直接访问映射的内存区域,省去了这些复制操作。这不仅减少了CPU的使用,还减少了数据在不同内存层次之间移动的时间,从而提高了文件操作的效率。
#### 2.2.2 mmap在大型文件处理中的优势
在处理大型文件时,内存映射的优势尤为明显。由于文件内容被映射到虚拟内存空间,进程可以像访问普通内存一样访问文件的任意部分。这意味着进程可以随机访问大文件的任何位置,而无需将整个文件加载到内存中。
### 2.3 mmap的应用场景
#### 2.3.1 大型数据集的处理
在大数据分析中,内存映射可以用于高效地处理大型数据集。例如,在科学计算和数据密集型应用中,数据通常存储在大型文件中。通过内存映射,应用程序可以访问和分析这些数据,而不需要将整个文件加载到内存中。
#### 2.3.2 多进程共享内存的场景
内存映射也可以用于多进程共享内存的场景。多个进程可以映射同一个文件到它们的地址空间,从而实现内存共享。这种方式允许多个进程高效地读写同一份数据,而无需通过进程间通信机制。
为了更好地理解内存映射的工作原理,我们可以使用以下代码示例来演示如何在Linux系统中创建一个内存映射。
```c
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
const char *filename = "examplefile";
const size_t filesize = 1024; // 1KB file for demonstration
// 创建或打开文件
int fd = open(filename, O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
if (fd == -1) {
perror("open");
return 1;
}
// 截断文件到指定大小
if (ftruncate(fd, filesize) == -1) {
perror("ftruncate");
close(fd);
return 1;
}
// 创建内存映射
void *map_address = mmap(0, filesize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (map_address == MAP_FAILED) {
perror("mmap");
close(fd);
return 1;
}
// 读写映射的内存
char *map_ptr = (char *)map_address;
map_ptr[0] = 'H';
map_ptr[filesize - 1] = '!';
// 同步映射区域到磁盘
if (msync(map_address, filesize, MS_SYNC) == -1) {
perror("msync");
munmap(map_address, filesize);
close(fd);
return 1;
}
// 清理资源
if (munmap(map_address, filesize) == -1) {
perror("munmap");
close(fd);
return 1;
}
close(fd);
return 0;
}
```
在这个例子中,我们首先创建了一个名为"examplefile"的文件,然后使用`mmap`系统调用将其内容映射到进程的地址空间。我们设置内存映射区域的大小为1KB,并使用`PROT_READ | PROT_WRITE`来设置映射区域的访问权限。通过`MAP_SHARED`标志,我们指定映射区域为共享模式,允许多个进程共享映射的内存区域。
映射成功后,我们通过指针`map_ptr`直接访问和修改映射区域的内容。在修改完成后,我们使用`msync`系统调用将修改后的内存区域同步到磁盘,确保文件内容的更新。最后,我们使用`munmap`系统调用解除映射,并关闭文件描述符。
这个示例展示了内存映射的基本步骤,并且通过代码逻辑的逐行解读分析了每个步骤的作用。在实际应用中,内存映射可以大大简化大文件处理的复杂性,并提高数据访问的效率。
# 3. Python中mmap的实践操作
在本章节中,我们将深入探讨Python中mmap模块的实际应用。我们将从基本使用到高级操作,再到错误处理和优化,逐步深入,使读者能够熟练掌握mmap在Python中的应用。
## 3.1 Python中mmap模块的基本使用
### 3.1.1 mmap模块的引入和初始化
在Python中,mmap模块是标准库的一部分,无需额外安装即可使用。要使用mmap模块,我们首先需要引入它:
```python
import mmap
```
接着,我们可以使用`mmap.mmap()`函数创建一个内存映射对象。这个函数的原型如下:
```python
mmap.mmap(fileobj, length, access=mmap.ACCESS_DEFAULT, offset=0, whence=0)
```
- `fileobj`:一个打开的文件对象,用于映射。
- `length`:映射区域的长度,以字节为单位。
- `access`:定义了映射区域的访问模式,默认是可读写。
- `offset`:映射区域的起始偏移量,默认为0。
- `whence`:定义了偏移量的计算方式,默认是相对于文件开始位置。
例如,我们要映射一个文件的前1024字节,可以这样写:
```python
with open('example.txt', 'r+b') as ***
*** 移动到文件末尾
file.write(b'example') # 写入示例数据
file.seek(0) # 回到文件开始
mm = mmap.mmap(file.fileno(), 1024)
```
### 3.1.2 基本的读写操作示例
一旦我们有了一个mmap对象,就可以像操作普通字节类型一样对其进行读写。例如,读取映射区域的前10个字节:
```python
data = mm.read(10)
print(data)
```
写入数据也很简单:
```python
mm.write(b'new data')
```
请注意,任何对映射对象的写入都会直接反映到文件中,因为映射对象和文件共享相同的内存区域。
### 3.2 Python中mmap的高级操作
#### 3.2.1 文件锁定和同步机制
在多进程或多线程环境中,对同一文件的访问需要同步机制来防止数据损坏。mmap模块提供了一些方法来锁定或解锁映射区域:
```python
# 锁定映射区域
mm.lock()
# 解锁映射区域
mm.unlock()
```
这些方法确保了在多进程环境中,对文件的访问是互斥的。
#### 3.2.2 带偏移量的读写操作
在某些情况下,我们可能需要在映射区域的中间位置读写数据。这时,我们可以使用`mmap.mmap.seek(offset, whence)`方法来设置当前操作的位置。
```python
# 设置当前操作的位置
mm.seek(10) # 从文件开始处计算偏移
mm.write(b'offset data')
```
## 3.3 Python中mmap的错误处理和优化
### 3.3.1 常见错误及其处理方法
在使用mmap时,可能会遇到一些常见的错误,例如权限错误、文件不存在等。这些错误可以通过异常处理来捕获并适当处理。
```python
try:
mm = mmap.mmap(file.fileno(), 1024)
except OSError as e:
print(f"Error: {e.strerror}")
```
### 3.3.2 性能优化和资源管理
为了优化性能,我们可以考虑使用内存映射的同步机制来减少锁的竞争,或者调整映射区域的大小来减少内存碎片。同时,确保及时关闭mmap对象来释放资源是很重要的。
```python
# 关闭mmap对象
mm.close()
```
在本章节中,我们介绍了Python中mmap模块的基本使用、高级操作以及错误处理和优化。这些内容将帮助读者在实际应用中更好地理解和使用mmap。
# 4. mmap文件操作的实战案例
在本章节中,我们将深入探讨mmap文件操作的实际应用,通过具体的案例来展示如何在实际项目中有效地使用mmap技术。我们将涵盖大型二进制文件处理、多进程共享内存的实践以及mmap在缓存机制中的应用。每个案例都将包含详细的步骤说明、代码示例、逻辑分析和参数说明,以确保读者能够清晰地理解并应用这些技术。
## 4.1 大型二进制文件处理
处理大型二进制文件时,传统的文件操作方法可能会因为内存限制而变得低效。通过使用mmap,我们可以将文件内容映射到内存地址空间,从而实现高效的随机访问和修改。
### 4.1.1 二进制文件的映射和读取
首先,我们需要了解如何使用Python的mmap模块来映射二进制文件。以下是一个简单的示例代码,展示了如何映射一个二进制文件并读取其内容。
```python
import mmap
# 打开文件
with open('large_binary_file', 'r+b') as f:
# 创建内存映射对象
mm = mmap.mmap(f.fileno(), 0)
# 读取文件内容
data = mm.read(1024) # 假设我们读取前1024字节
# 输出读取的数据
print(data)
# 关闭映射
mm.close()
```
在这个例子中,我们使用`mmap.mmap`创建了一个内存映射对象`mm`,它将文件`large_binary_file`映射到内存中。参数`f.fileno()`表示文件描述符,`0`表示整个文件都被映射。`mm.read(1024)`读取了文件的前1024字节数据。
### 4.1.2 数据解析和修改实例
映射文件后,我们可以像操作普通内存一样操作文件内容。例如,如果我们知道文件中特定格式的数据布局,我们可以直接在映射的内存中解析和修改这些数据。
```python
# 假设我们知道数据格式如下:
# struct {
# unsigned int id;
# char name[32];
# }
# 解析第一个数据项
offset = 0
id = struct.unpack_from('I', mm, offset)[0]
name = struct.unpack_from('32s', mm, offset + 4)
print(f'ID: {id}, Name: {name.decode().strip()}')
# 修改数据项
new_id = 1234
new_name = 'New Name'.encode()
struct.pack_into('I', mm, offset, new_id)
struct.pack_into('32s', mm, offset + 4, new_name)
# 验证修改
mm.seek(0)
id, name = struct.unpack_from('I32s', mm, offset)
print(f'Modified ID: {id}, Name: {name.decode().strip()}')
```
在这个例子中,我们使用`struct.unpack_from`和`struct.pack_into`函数来直接在内存映射区域解析和修改数据。`struct.unpack_from`用于从指定偏移量处解析数据,而`struct.pack_into`用于将新数据打包到指定的偏移量。
## 4.2 多进程共享内存的实践
多进程共享内存是mmap的另一个重要应用场景,它可以提高进程间通信的效率。
### 4.2.1 创建共享内存
在Python中,我们可以使用mmap模块来创建一个跨进程共享的内存区域。
```python
import mmap
import os
# 创建一个共享内存对象
size = 1024 # 分配1024字节的共享内存
shm = mmap.mmap(-1, size)
# 写入数据
shm.write(b'Hello, World!')
# 获取共享内存的文件描述符
fd = shm.fileno()
# 在另一个进程中访问共享内存
pid = os.fork()
if pid == 0:
# 子进程
new_mm = mmap.mmap(fd, size)
data = new_mm.read()
print(f'Received: {data.decode()}')
new_mm.close()
else:
# 父进程
os.waitpid(pid, 0)
shm.close()
```
在这个例子中,我们首先创建了一个共享内存对象`shm`,并将其文件描述符`fd`传递给`os.fork()`来创建一个子进程。子进程通过文件描述符`fd`打开相同的共享内存,并读取父进程写入的数据。
### 4.2.2 多进程间的数据同步和通信
共享内存虽然提供了高效的数据共享方式,但也带来了同步问题。我们需要确保多个进程在访问共享内存时不会发生冲突。
```python
import mmap
import os
import threading
# 创建共享内存和锁
size = 1024
shm = mmap.mmap(-1, size)
lock = threading.Lock()
def child_process():
with lock:
data = shm.read()
print(f'Received: {data.decode()}')
def parent_process():
shm.write(b'Hello, World!')
shm.flush() # 确保数据写入共享内存
os.waitpid(pid, 0)
# 创建锁文件
lock_fd = os.open('shm.lock', os.O_CREAT | os.O_RDWR)
f = os.fdopen(lock_fd, 'w')
pid = os.fork()
if pid == 0:
# 子进程
f.write('child')
f.flush()
child_process()
else:
# 父进程
f.write('parent')
f.flush()
parent_process()
shm.close()
os.close(lock_fd)
```
在这个例子中,我们使用了文件锁来同步父子进程对共享内存的访问。`threading.Lock()`用于同步线程,而文件锁`f`用于同步进程。在读写共享内存之前,我们需要获得锁,以避免并发访问导致的数据不一致问题。
## 4.3 mmap在缓存机制中的应用
在分布式系统中,缓存是一种常见的优化手段。使用mmap可以有效地创建和管理缓存映射文件。
### 4.3.1 缓存映射文件的创建和管理
我们可以使用mmap来创建一个持久化的缓存文件,这个文件可以在多个进程或服务实例之间共享。
```python
import mmap
import os
# 创建或打开一个缓存文件
cache_file_path = 'cache_file'
cache_size = 1024 * 1024 # 1MB缓存大小
if not os.path.exists(cache_file_path):
with open(cache_file_path, 'wb') as f:
f.write(b'\0' * cache_size)
cache_fd = os.open(cache_file_path, os.O_RDWR)
# 创建内存映射对象
cache_mm = mmap.mmap(cache_fd, cache_size)
# 检查缓存是否有效
def check_cache():
if cache_mm.read(4) != b'VALID':
cache_mm.seek(0)
cache_mm.write(b'VALID')
cache_mm.flush()
check_cache()
```
在这个例子中,我们首先检查缓存文件是否存在,如果不存在则创建一个大小为1MB的文件,并用空字节填充。然后,我们创建一个内存映射对象`cache_mm`来映射这个缓存文件。
### 4.3.2 缓存的读写和失效处理
为了管理缓存的有效性,我们可以定义一个简单的机制来标记缓存是否有效。
```python
# 写入缓存数据
def write_to_cache(key, value):
with lock:
offset = hash(key) % cache_size
cache_mm.seek(offset)
cache_mm.write(value)
cache_mm.flush()
# 从缓存读取数据
def read_from_cache(key):
with lock:
offset = hash(key) % cache_size
cache_mm.seek(offset)
value = cache_mm.read(1024) # 假设值的大小为1024字节
return value
# 缓存失效处理
def invalidate_cache(key):
with lock:
offset = hash(key) % cache_size
cache_mm.seek(offset)
cache_mm.write(b'\0' * 1024) # 用空字节替换旧值
# 示例:使用缓存
key = 'example_key'
value = b'This is a cached value'
write_to_cache(key, value)
cached_value = read_from_cache(key)
print(f'Cached value: {cached_value.decode()}')
invalidate_cache(key)
cached_value = read_from_cache(key)
print(f'Cached value after invalidation: {cached_value.decode()}')
```
在这个例子中,我们定义了`write_to_cache`和`read_from_cache`函数来处理缓存的写入和读取操作。我们使用`invalidate_cache`函数来处理缓存的失效。这些函数都使用了前面定义的`lock`来确保线程安全。
以上案例展示了mmap在实际应用中的强大功能,包括大型文件处理、多进程共享内存以及缓存机制的实现。通过这些示例,我们可以看到mmap如何提高数据处理效率和实现进程间通信。每个案例都包含了详细的代码说明和逻辑分析,以便读者更好地理解和应用这些技术。
# 5. mmap文件操作的进阶技巧
在本章节中,我们将深入探讨mmap文件操作的进阶技巧,包括内存映射的同步和并发控制、特殊文件系统的mmap操作以及调试和性能分析方法。这些高级技巧对于优化大型应用程序和系统性能至关重要,尤其是在需要高效数据处理和多进程协作的场景中。
## 5.1 内存映射的同步和并发控制
### 5.1.1 内存映射的同步机制
在多进程环境中,当多个进程同时访问同一内存映射区域时,同步机制变得尤为重要。mmap提供了几种同步机制,例如POSIX共享内存对象中的`ftruncate()`和`mmap()`的`MAP_SHARED`标志,可以用来同步文件内容和内存映射区域。此外,`msync()`函数可以用来同步内存映射区域和文件系统。
### 5.1.2 并发读写的策略和实现
为了处理并发读写,可以使用互斥锁(mutex)或其他同步原语来保护对内存映射区域的访问。以下是一个使用互斥锁的示例代码:
```c
#include <pthread.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void* map_address = NULL;
void* thread_function(void* arg) {
pthread_mutex_lock(&lock);
// 读写内存映射区域
// ...
pthread_mutex_unlock(&lock);
return NULL;
}
int main() {
// 初始化内存映射
int fd = open("file", O_RDWR);
map_address = mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
pthread_t thread_id;
pthread_create(&thread_id, NULL, thread_function, NULL);
pthread_join(thread_id, NULL);
close(fd);
return 0;
}
```
在这个示例中,我们定义了一个互斥锁`lock`,并在`thread_function`中使用`pthread_mutex_lock()`和`pthread_mutex_unlock()`来确保对共享内存区域的独占访问。
## 5.2 特殊文件系统的mmap操作
### 5.2.1 网络文件系统的mmap应用
网络文件系统(NFS)通常不支持mmap,因为网络延迟和数据一致性问题难以保证。但是,对于一些特殊的网络文件系统,如Google的gNFS,可以通过特定的协议和优化来支持mmap操作。
### 5.2.2 内存文件系统的mmap实践
内存文件系统(如tmpfs)可以有效地使用mmap进行数据操作。由于数据存储在内存中,mmap可以提供极快的访问速度和更低的延迟。以下是一个示例,展示如何在内存文件系统上进行mmap操作:
```c
int fd = open("/dev/shm/myfile", O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
ftruncate(fd, file_size);
void* map_address = mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
```
在这个示例中,我们打开(或创建)一个位于内存文件系统中的文件,并通过`mmap()`对其进行映射。
## 5.3 调试和性能分析
### 5.3.1 mmap操作的调试技巧
调试mmap操作时,可以使用`strace`工具来追踪系统调用。这有助于识别和定位问题,如权限错误、内存分配失败等。例如:
```bash
strace -e mmap ./your_program
```
此外,使用`gdb`可以附加到正在运行的程序,设置断点并检查内存映射区域。
### 5.3.2 性能分析和瓶颈诊断
性能分析mmap操作时,可以使用`perf`工具来检测系统调用和CPU使用情况。这有助于识别性能瓶颈,例如频繁的页面错误或同步操作。例如:
```bash
perf record -g ./your_program
perf report
```
通过这些高级技巧,开发者可以更有效地利用mmap进行高效的数据处理和共享内存操作,同时确保应用的稳定性和性能。
```mermaid
graph LR
A[开始] --> B[初始化内存映射]
B --> C[互斥锁保护]
C --> D[读写操作]
D --> E[资源清理]
E --> F[结束]
```
在本章节介绍的进阶技巧中,我们讨论了内存映射的同步和并发控制、特殊文件系统的mmap操作以及调试和性能分析方法。这些内容对于高级开发者来说是必不可少的,尤其是在需要优化大型应用程序和系统性能时。通过实际的代码示例和分析,我们展示了如何在实际应用中应用这些技巧,以及如何使用现代工具进行调试和性能优化。
# 6. mmap文件操作的未来展望
## 6.1 mmap技术的最新发展
### 6.1.1 新兴的操作系统特性
随着技术的不断进步,新兴的操作系统开始引入了更多与mmap相关的特性,以提升内存映射文件操作的性能和易用性。例如,现代操作系统可能会提供更高效的内存映射机制,减少映射和解除映射的开销,以及提供更细粒度的内存映射控制。这些特性使得mmap操作更加灵活,能够更好地满足不同应用程序的需求。
### 6.1.2 mmap技术在新场景下的应用
mmap技术的应用场景也在不断扩展。除了传统的大型文件处理和多进程共享内存外,mmap技术在一些新兴的应用场景中也展现出了巨大的潜力。例如,在大数据处理和实时分析领域,mmap可以用于优化数据的读取速度和处理效率。在云计算环境中,mmap可以用于实现跨节点的内存共享,提高分布式计算的性能。
## 6.2 mmap与其他技术的融合
### 6.2.1 mmap与数据库技术的结合
数据库管理系统(DBMS)是信息系统的核心组件之一,而mmap技术与数据库技术的结合可以带来许多优势。例如,通过mmap,数据库可以更高效地处理大量的数据文件,尤其是在读取和缓存操作上。此外,mmap可以用于优化数据库的缓存机制,减少磁盘I/O操作,提高整体性能。
### 6.2.2 mmap在云计算环境下的应用
云计算环境中,mmap技术可以用于优化数据的存储和访问。通过内存映射,云服务提供商可以提供更快的数据读写速度,从而提升服务的响应时间和吞吐量。此外,mmap还能够用于实现跨虚拟机或容器的数据共享,这对于分布式系统和微服务架构来说是非常有价值的。
## 6.3 mmap的未来趋势和挑战
### 6.3.1 开源社区对mmap的贡献
开源社区在mmap技术的发展中扮演着重要角色。通过开源项目,开发者可以分享他们对mmap技术的理解和改进,不断推动技术的发展和创新。社区中的代码库和工具可以帮助开发者更好地理解和使用mmap,同时也能促进mmap在不同平台和应用场景中的普及。
### 6.3.2 mmap面临的挑战和应对策略
尽管mmap技术有着广泛的应用前景,但它也面临着一些挑战。例如,mmap依赖于底层操作系统的支持,这意味着它的兼容性和可移植性可能会受到限制。此外,不当的使用mmap可能会导致内存泄漏和数据一致性问题。为了应对这些挑战,开发者需要深入了解mmap的工作机制,合理设计应用程序,并采取适当的资源管理和错误处理策略。通过持续的研究和实践,mmap技术将继续发展,以满足未来技术发展的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 mmap 库,揭示了内存映射的本质和高级应用。从入门概念到最佳实践,专栏涵盖了 mmap 的方方面面,包括高效读写大型文件、文件锁、性能测试、多线程应用、安全分析、数据库交互、内存管理和自定义对象构建。此外,还提供了实战演练、进阶教程和解决常见问题的指南,帮助读者掌握 mmap 的精髓,构建高效、安全和可扩展的内存映射解决方案。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python NetBIOS库文件与网络自动化:脚本编写与应用案例

# 1. NetBIOS协议基础与Python库概述
## NetBIOS协议简介
NetBIOS(Network Basic Input/Output System)是一种为网络提供名称解析和会话服务的应用程序编程接口(API)
zc.buildout监控与日志:跟踪构建过程与维护日志的7大技巧
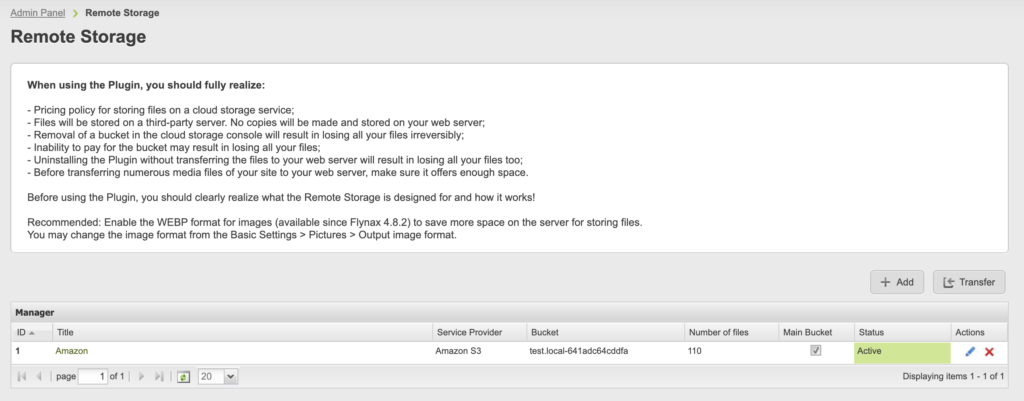
# 1. zc.buildout监控与日志概述
## 1.1 zc.buildout简介
zc.buildout是一个Python开发的工具,用于创建和部署Python应用程序。它能够管理应用程序的依赖,自动化部署过程,并且配置运行环境。
## 1.2 监控的重要性
在使用zc.buildout部署应用程序时,监控变
Jinja2.exceptions的异常上下文:如何利用上下文信息调试错误,提升调试效率

# 1. Jinja2.exceptions异常处理概述
在Python的Web开发中,Jinja2是一个广泛使用的模
Django GIS GDAL原型社区与资源:利用开源资源提升开发效率
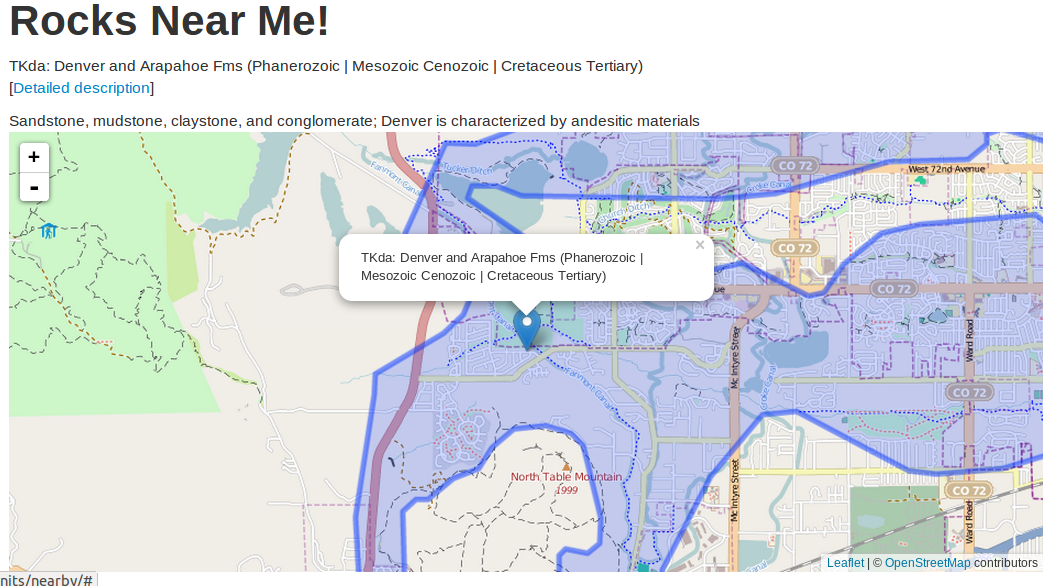
# 1. Django GIS GDAL概述
在当今快速发展的IT行业中,地理信息系统(GIS)和遥感技术已经成为不可或缺的组成部分。Django GIS和GDAL作为这两个领域的代表技术,为开发者提供了强大的工具集,以便在Web应用中集成GIS和地理空间数据处理能力。本章节将概述Django GIS和GDAL的基本概念、应用场景以及它们之间的关系,为后续章节的深入探讨打下坚实的基础。
## 1
【Django调试工具的日志记录】:使用django.views.debug进行高级日志记录与分析的6大策略

# 1. Django调试工具概述
Django是一个强大的Python Web框架,它内置了许多有用的调试工具,可以帮助开发者更快地定位和解决问题。在这些工具中,Django的调试工具特别值得一提,因为它不仅可以帮助开发者在开发过程中快速发现错误,还可以在生产环境中提供有用的信息。这些工具包括异常报告、日志记录和
【Feeds库在自动化测试中的应用】:动态内容测试的新方法

# 1. Feeds库概述
## 1.1 Feeds库简介
在当今快速发展的IT行业中,Feeds库作为一种强大的自动化测试工具,已经成为许多测试工程师的首选。它不仅能够模拟用户操作,还能够有效地处理动态内容,提高测试效率和覆盖率。
## 1.2 Feeds库的起源和发展
Feeds库起源于一个
【实战演练】Akismet库:构建高效垃圾评论过滤器
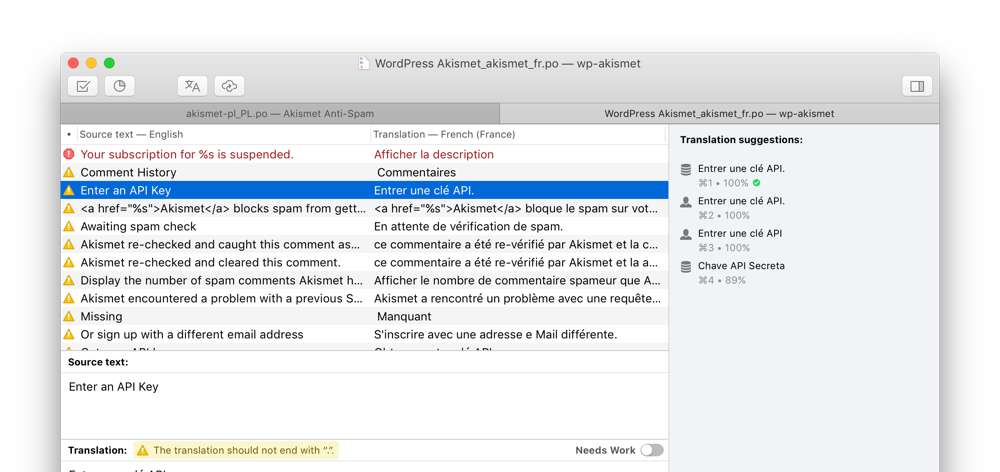
# 1. Akismet库简介
## Akismet库的基本概念
Akismet是一款强大的反垃圾邮件库,最初由Automattic公司为WordPress开发,现在已成为一个开源项目。它通过分析和比较提交的评论与已知的垃圾评论数据库,帮助开发者识别和过滤掉网络上的垃圾评论。
## Akismet库的应用场景
Akismet库广泛应用于博客平台、论坛和电商网站等,用于自动检测和过滤垃圾评论。这不仅减少了垃圾信息
Django时区转换深度解析:内部逻辑及转换方法全揭秘

# 1. Django时区转换基础概念
## 1.1 时区的定义和重要性
时区是按照地球上的经度划分的区域,每个区域使用相同的标准时间。这种划
【Python邮件处理必修课】:深入解析email.Encoders的10个核心用法

# 1. Python邮件处理基础
在当今的IT行业中,邮件处理是日常工作中不可或缺的一部分。Python作为一门强大的编程语言,提供了丰富的库和模块来简化邮件的创建、发送和接收过程。在本章中,我们将从Python邮件处理的基础开始,逐步深入探讨email.Encoders模块的功能和用法。
## 1.1 邮件处理的
【数据库索引优化】:用django.db.backends优化索引的高效方法

# 1. 数据库索引基础与重要性
## 什么是数据库索引?
数据库索引是一种帮助数据库高效获取数据的数据结构。可以将其类比为书籍的目录,当需要快速找到书中某一页的内容时,我们会先查阅目录。数据库索引通过减少数据检索时间来提高数据库查询性能。
## 索引的类型和选择
常见的数据库
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )