【Commons-EL高级使用场景剖析】:复杂数据操作解决方案(专家级案例分析)
发布时间: 2024-09-26 01:00:57 阅读量: 108 订阅数: 44 

# 1. Commons-EL概述
## 1.1 Commons-EL简介
Commons-EL是Apache Commons项目的一部分,旨在提供一个Java语言的表达式语言解析和执行引擎。该引擎支持标准的表达式语言规范,广泛应用于配置文件解析、动态查询构建以及在运行时对各种数据结构的访问和操作。它通过定义一套简单的API和表达式语法规则,允许开发者在运行时动态构建和执行表达式,大大增强了应用程序的灵活性和可维护性。
## 1.2 应用场景
Commons-EL的使用场景非常广泛,它可以在任何需要对数据进行动态查询、操作或转换的地方发挥效用。比如在Web应用中,可以用来动态生成数据报表;在企业级应用中,可以用于编写灵活的业务规则;在大数据处理框架中,可用于定义数据处理流程。它的轻量级和高扩展性使得Commons-EL成为许多Java开发者处理复杂表达式逻辑的首选工具。
## 1.3 基本使用方法
使用Commons-EL,首先需要获取依赖并将其加入到项目中。接下来,通过创建一个表达式解析器实例来编译和执行表达式。例如,如果需要获取一个对象的某个属性值,可以简单地使用如下代码:
```java
ExpressionFactory factory = new ExpressionFactoryImpl();
Expression exp = factory.createExpression("myObject.propertyName");
Object result = exp.evaluate(myObject);
```
上述代码中,`myObject` 是一个包含 `propertyName` 属性的对象实例。Commons-EL通过这种方式简化了对复杂对象的操作过程。
# 2. Commons-EL核心组件详解
## 2.1 表达式引擎架构
### 2.1.1 表达式的类型与结构
Commons-EL作为一个表达式语言,支持多种类型的表达式,包括但不限于变量访问、方法调用、算术运算、逻辑运算、条件运算等。在这一部分,我们将深入探讨Commons-EL表达式的类型和基本结构。
表达式基本结构通常包括:
- 字面量(Literal):表示具体的值,如数字、字符串、布尔值等。
- 变量(Variable):表示存储数据的容器,可以在表达式中被引用和赋值。
- 运算符(Operator):对操作数进行运算的符号,例如加号(+)、减号(-)、乘号(*)、除号(/)等。
- 函数(Function):执行特定任务的代码块,通常使用函数名和参数列表来调用。
Commons-EL通过解析和执行这些组件,实现了复杂表达式的处理。例如,以下表达式展示了这些组件如何结合使用:
```el
${math:sqrt(16) + 1 > 4 && flag}
```
在这个表达式中:
- `${}` 是表达式的界定符;
- `math:sqrt` 是一个函数,表示计算平方根;
- `16` 是一个字面量;
- `+` 和 `>` 是运算符;
- `flag` 是一个变量。
### 2.1.2 核心表达式组件与作用
Commons-EL的核心表达式组件包括解析器、上下文和函数库。每个组件都扮演着重要的角色:
- 解析器(Parser):负责将文本形式的表达式解析成可执行的内部表示形式。
- 上下文(Context):存储表达式中所引用的变量和它们的值,提供了变量与数据之间的映射。
- 函数库(Function Library):提供可调用函数的集合,扩展了表达式语言的功能。
通过这些组件,Commons-EL能执行如数学运算、字符串处理、逻辑判断等操作,并将其运用到实际的业务逻辑中。例如,以下代码展示了函数和变量的结合使用:
```java
// 设置上下文中的变量
ELContext context = new ELContext();
context.setVariable("name", "Alice");
// 执行表达式,打印 "Hello, Alice"
String result = (String) ELManager.evaluate("${'Hello, ' + name}", context);
System.out.println(result);
```
上述代码中,`name`变量在表达式中被引用并组合成一个完整的字符串。
## 2.2 表达式解析与执行过程
### 2.2.1 解析流程概述
表达式解析过程包括以下步骤:
1. **词法分析**:将输入的文本表达式转换成一个个的标记(Token)。
2. **语法分析**:将标记按照表达式的语法规则组织成语法树(Syntax Tree)。
3. **语义分析**:对语法树进行语义检查,确保表达式中的每个元素都有意义。
4. **中间代码生成**:将语法树转换成中间表示形式(Intermediate Representation)。
解析流程结束后,表达式引擎会得到一个可以执行的内部表示,接下来进入求值阶段。
### 2.2.2 表达式求值策略
求值策略定义了如何计算表达式的结果:
- **从左到右**:按照表达式在文本中的顺序,从左向右依次计算。
- **操作符优先级**:根据操作符的优先级来决定计算顺序,如算术运算中的乘除优先于加减。
- **短路求值**:对于逻辑运算中的 `&&` 和 `||`,如果第一个操作数已经可以确定整个表达式的结果,则不会计算第二个操作数。
求值时,表达式引擎会使用上下文中的变量值进行计算,从而得到最终结果。
## 2.3 引擎扩展性与自定义表达式
### 2.3.1 自定义表达式实现机制
Commons-EL允许开发者实现自定义的表达式。开发者可以创建自己的函数、运算符和行为,并将它们集成到表达式引擎中。
实现机制通常包括:
- **定义扩展接口**:如 `FunctionMapper` 和 `VariableMapper`。
- **实现接口**:编写自定义逻辑来实现这些接口。
- **注册扩展**:将自定义的实现注册到表达式引擎中。
通过这些步骤,开发者可以灵活地扩展Commons-EL,使其满足特定的业务需求。
### 2.3.2 扩展组件集成实践
以一个自定义函数实现为例,我们需要执行以下步骤:
1. **创建函数类**:实现 `***mons.el.FunctionMapper` 接口。
```java
public class CustomFunctionMapper implements FunctionMapper {
@Override
public Method resolveFunction(String prefix, String localName) {
if ("custom".equals(prefix) && "sayHello".equals(localName)) {
try {
return CustomFunctions.class.getMethod("sayHello", ELContext.class);
} catch (NoSuchMethodException e) {
// 处理异常
}
}
return null;
}
}
```
2. **注册到引擎**:在创建 `ELManager` 实例时使用自定义的 `FunctionMapper`。
```java
ELManager manager = ELManager.create();
manager.setFunctionMapper(new CustomFunctionMapper());
```
3. **使用自定义函数**:在表达式中引用并使用自定义的函数。
```el
${custom:sayHello(context)}
```
上述步骤展示了如何通过扩展Commons-EL来实现自定义功能。通过集成实践,开发者可以更好地控制表达式的执行和输出。
# 3. Commons-EL在复杂数据操作中的应用
## 3.1 数据结构操作技巧
在处理复杂数据时,能够有效地操作数据结构对于提高程序的效率和可维护性至关重要。Apache Commons EL作为一个强大的表达式语言库,为复杂数据操作提供了丰富的方法和技巧。
### 3.1.1 集合操作与映射关系处理
在数据处理中,集合操作是最基础也是最常见的需求。Apache Commons EL提供了一套丰富的API来操作集合,如添加、删除、查找和遍历元素等。例如,我们可以通过EL表达式来过滤集合中的元素,实现条件查询。
```java
// 示例代码展示如何使用Commons EL进行集合操作
Collection<String> fruits = Arrays.asList("apple", "banana", "cherry", "date");
// 使用EL表达式过滤集合中的元素
String expression = "fruits.?[ it.startsWith('b') ]";
Collection<String> filteredFruits = (Collection<String>) new ExpressionParser().parseExpression(expression).getValue(fruits);
```
逻辑分析:在上述代码中,我们定义了一个包含水果名称的`Collection`,然后创建了一个表达式来筛选出所有以字母'b'开头的元素。通过`parseExpression`方法解析该表达式,并通过`getValue`方法获取筛选后的结果。
处理映射关系通常涉及到键值对的数据结构。在Apache Commons EL中,可以利用表达式语言来获取映射中的值,或者通过键来检索映射中对应的条目。
### 3.1.2 复杂对象图的遍历和映射
在企业级应用中,对象图的遍历和映射是一个经常遇到的问题,尤其是当对象之间的关系错综复杂时。Commons EL支持通过表达式来实现对对象图的深度遍历和映射。
```java
// 示例代码展示如何使用Commons EL遍历复杂对象图
class Person {
private String name;
private int age;
private List<Address> addresses;
// Getters and setters...
}
class Address {
private String street;
private String city;
// Getters and setters...
}
List<Person> persons = ...; // 初始化人员列表
// EL表达式遍历每个人员的地址并打印
String expression = "persons.?[ addresses.?[ city == 'New York' ] ].name";
for (Object name : new ExpressionParser().parseExpression(expression).getValue(persons)) {
System.out.println(name);
}
```
逻辑分析:在该示例中,我们创建了一个包含多个`Person`对象的列表,每个`Person`对象可能有多个`Address`对象。我们的目标是找出所有住在纽约的人员的名字。通过构建的表达式,我们可以在一个步骤中完成对嵌套对象的查询,并返回符合条件的结果。
## 3.2 高级函数和操作符
Commons EL不仅支持基本的数据操作,还提供了高级函数和操作符,这些可以极大地增强程序的表达能力和灵活性。
### 3.2.1 内置函数的高级用法
Commons EL内置了许多实用的函数,比如数学函数、日期和时间函数等。高级用法中,可以通过自定义函数来扩展这些内置函数的功能。
```java
// 示例代码展示如何自定义EL函数
public static String toUpper(String input) {
return input.toUpperCase();
}
// 在EL解析器中注册自定义函数
ExpressionParser parser = new ExpressionParserBuilder()
.withFunction("toUpper", toUpper.class)
.build();
String expression = "toUpper('hello world')";
String result = parser.parseExpression(expression).getValue(String.class);
System.out.println(result); // 输出: HELLO WORLD
```
逻辑分析:在上述代码中,我们自定义了一个名为`toUpper`的函数,该函数将输入的字符串转换为大写。然后,我们在创建`ExpressionParser`解析器时将此函数注册进去。之后就可以在EL表达式中直接使用`toUpper`函数了。
### 3.2.2 自定义操作符和表达式
对于特定的业务逻辑,Commons EL允许开发人员定义自定义操作符来扩展表达式的功能。这样可以按照业务需求创建可读性更强、更符合业务逻辑的表达式。
```java
// 示例代码展示如何自定义操作符
ExpressionParser parser = new ExpressionParserBuilder()
.withOperator("contains", new ContainsOperator())
.bui
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Commons-EL库入门介绍与使用》专栏深入剖析了Commons-EL库的核心概念、源码机制、安全机制、调试技巧和最佳实践。专栏涵盖了从基础到高级的各种主题,包括:项目集成、性能优化、自定义函数开发、与JSTL的结合、大型应用中的策略、与SpEL的对比、微服务中的角色、扩展库开发、企业级部署和监控、与JPA的整合、大数据中的应用和高级使用场景。通过深入浅出的讲解和实战技巧,本专栏旨在帮助读者全面掌握Commons-EL库,并将其有效应用于各种项目中,提升开发效率和系统性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【跨模块协同效应】:SAP MM与PP结合优化库存管理的5大策略

# 摘要
本文旨在探讨SAP MM(物料管理)和PP(生产计划)模块在库存管理中的核心应用与协同策略。首先介绍了库存管理的基础理论,重点阐述了SAP MM模块在材料管理和库存控制方面的作用,以及PP模块如何与库存管理紧密结合实现生产计划的优化。接着,文章分析了SAP MM与PP结合的协同策略,包括集成供应链管理和需求驱动的库存管理方法,以减少库存
【接口保护与电源管理】:RS232通信接口的维护与优化
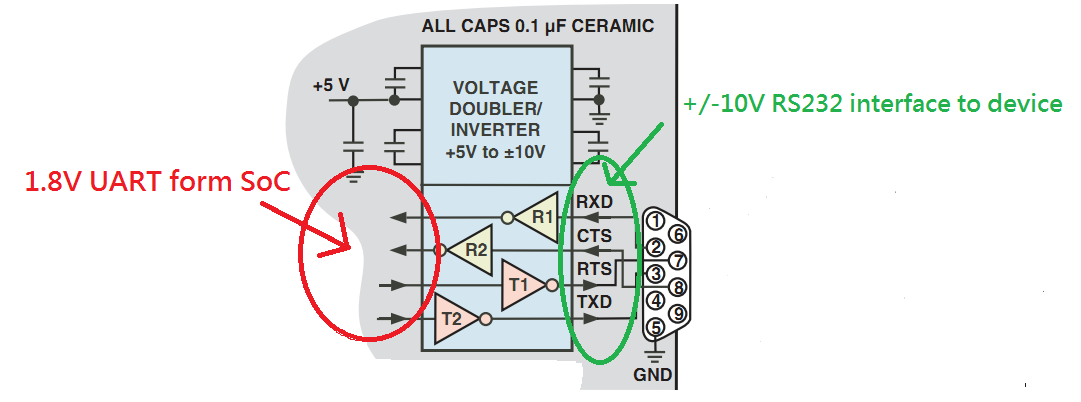
# 摘要
本文全面探讨了RS232通信接口的设计、保护策略、电源管理和优化实践。首先,概述了RS232的基本概念和电气特性,包括电压标准和物理连接方式。随后,文章详细分析了接口的保护措施,如静电和过电压防护、物理防护以及软件层面的错误检测机制。此外,探讨了电源管理技术,包括低功耗设计和远程通信设备的案例
零基础Pycharm教程:如何添加Pypi以外的源和库

# 摘要
Pycharm作为一款流行的Python集成开发环境(IDE),为开发人员提供了丰富的功能以提升工作效率和项目管理能力。本文从初识Pycharm开始,详细介绍了环境配置、自定义源与库安装、项目实战应用以及高级功能的使用技巧。通过系统地讲解Pycharm的安装、界面布局、版本控制集成,以及如何添加第三方源和手动安装第三方库,本文旨在帮助读者全面掌握Pycharm的使用,特
【ArcEngine进阶攻略】:实现高级功能与地图管理(专业技能提升)

# 摘要
本文深入介绍了ArcEngine的基本应用、地图管理与编辑、空间分析功能、网络和数据管理以及高级功能应用。首先,本文概述了ArcEngine的介绍和基础使用,然后详细探讨了地图管理和编辑的关键操作,如图层管理、高级编辑和样式设置。接着,文章着重分析了空间分析的基础理论和实际应用,包括缓冲区分析和网络分析。在此基础上,文章继续阐述了网络和数据库的基本操作
【VTK跨平台部署】:确保高性能与兼容性的秘诀

# 摘要
本文详细探讨了VTK(Visualization Toolkit)跨平台部署的关键方面。首先概述了VTK的基本架构和渲染引擎,然后分析了在不同操作系统间进行部署时面临的挑战和优势。接着,本文提供了一系列跨平台部署策略,包括环境准备、依赖管理、编译和优化以及应用分发。此外,通过高级跨平台功能的
函数内联的权衡:编译器优化的利与弊全解
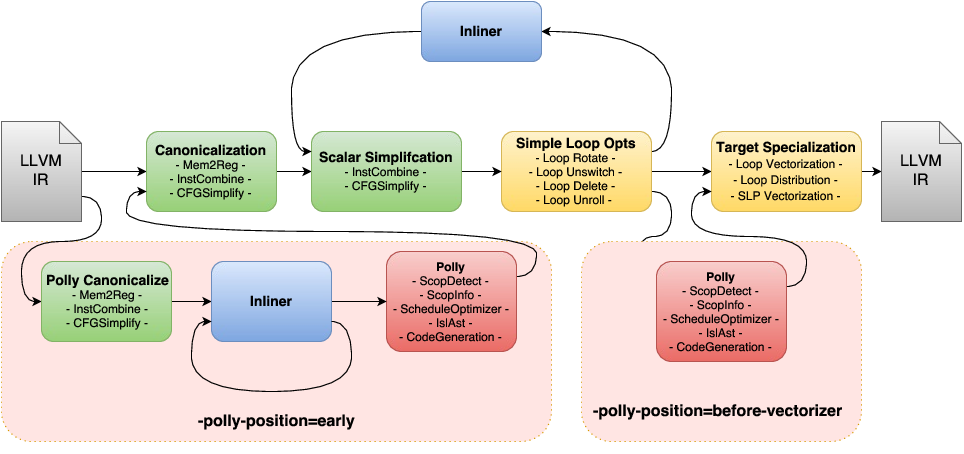
# 摘要
函数内联是编译技术中的一个优化手段,通过将函数调用替换为函数体本身来减少函数调用的开销,并有可能提高程序的执行效率。本文从基础理论到实践应用,全面介绍了函数内联的概念、工作机制以及与程序性能之间的关系。通过分析不同编译器的内联机制和优化选项,本文进一步探讨了函数内联在简单和复杂场景下的实际应用案例。同时,文章也对函数内联带来的优势和潜在风险进行了权衡分析,并给出了相关的优化技
【数据处理差异揭秘】

# 摘要
数据处理是一个涵盖从数据收集到数据分析和应用的广泛领域,对于支持决策过程和知识发现至关重要。本文综述了数据处理的基本概念和理论基础,并探讨了数据处理中的传统与现代技术手段。文章还分析了数据处理在实践应用中的工具和案例,尤其关注了金融与医疗健康行业中的数据处理实践。此外,本文展望了数据处理的未来趋势,包括人工智能、大数据、云计算、边缘计算和区块链技术如何塑造数据处理的未来。通过对数据治理和
C++安全编程:防范ASCII文件操作中的3个主要安全陷阱

# 摘要
本文全面介绍了C++安全编程的核心概念、ASCII文件操作基础以及面临的主要安全陷阱,并提供了一系列实用的安全编程实践指导。文章首先概述C++安全编程的重要性,随后深入探讨ASCII文件与二进制文件的区别、C++文件I/O操作原理和标准库中的文件处理方法。接着,重点分析了C++安全编程中的缓冲区溢出、格式化字符串漏洞和字符编码问题,提出相应的防范
时间序列自回归移动平均模型(ARMA)综合攻略:与S命令的完美结合
# 摘要
时间序列分析是理解和预测数据序列变化的关键技术,在多个领域如金融、环境科学和行为经济学中具有广泛的应用。本文首先介绍了时间序列分析的基础知识,特别是自回归移动平均(ARMA)模型的定义、组件和理论架构。随后,详细探讨了ARMA模型参数的估计、选择标准、模型平稳性检验,以及S命令语言在实现ARMA模型中的应用和案例分析。进一步,本文探讨了季节性ARMA模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )