Sharding-JDBC: 分布式主键生成器的实现与选用
发布时间: 2024-02-16 13:31:54 阅读量: 56 订阅数: 23 

Sharding-JDBC分布式事务应用
# 1. 引言
### 1.1 什么是Sharding-JDBC
Sharding-JDBC是一款开源的分布式数据库中间件,它提供了基于Java的分库分表功能。通过将数据分散到多个数据库中,可以提高数据库的扩展性和性能。Sharding-JDBC通过透明化的方式实现了分片策略,对上层应用来说,使用起来非常方便。
### 1.2 分布式主键生成器的重要性
在分布式系统中,生成唯一的主键是非常重要的。主键的唯一性保证了数据的正确性和一致性,而主键的生成速度则影响了系统的性能。由于分布式系统的特点,通常需要考虑高并发的场景,因此分布式主键生成器的性能和并发能力尤为重要。
在传统的关系型数据库中,通常使用自增主键来生成唯一的主键。但在分布式系统中,直接使用自增主键会有一些问题,比如并发量过高会导致锁竞争,自增ID可能会有重复,不同数据库之间的自增ID不同步等。因此,我们需要一种分布式主键生成器来解决这些问题。
# 2. 分布式主键生成器的常见需求
在分布式系统中,对于主键的生成有一些常见的需求,下面将介绍其中两个主要需求。
#### 2.1 高并发场景下的主键生成问题
在高并发场景下,多个请求同时访问数据库并生成主键时会出现竞争问题。如果使用传统的数据库自增主键,每个请求都要等待前一个请求生成主键后才能获取到下一个主键,这会导致性能瓶颈和请求延迟增加。
针对这个问题,可以采用分布式主键生成器来解决,通过将主键生成的工作分摊到多个节点上,每个节点独立生成主键,避免竞争,从而提高性能和并发能力。
#### 2.2 分布式系统中主键的唯一性问题
在分布式系统中,由于存在多个节点,每个节点都可能生成主键,需要确保生成的主键唯一性。如果使用传统的数据库自增主键,多节点同时生成主键时存在重复的可能性。
为了解决这个问题,可以使用全局唯一的分布式主键生成器,可以基于时间戳、机器ID等信息生成唯一的主键。这样即使在多个节点上生成主键,也能保证主键的唯一性。
以上是分布式主键生成器的两个常见需求,接下来将介绍分布式主键生成的几种实现方式。
# 3. 分布式主键生成的实现原理
分布式主键生成是分布式系统中的一个关键问题,通常需要保证生成的主键在分布式环境下是唯一的,同时在高并发场景下也需要保证生成的性能和效率。下面我们将详细介绍几种常见的分布式主键生成方式的实现原理。
#### 3.1 基于数据库自增主键的实现方式
在传统的关系型数据库中,可以通过数据库自增主键来生成唯一的主键。在分布式环境下,可以通过数据库集群来实现分布式的自增主键生成。每个数据库实例维护一个独立的自增主键,通过数据库集群的负载均衡来实现主键的唯一性和高可用性。
```java
// Java 示例代码
public class DatabaseIdGenerator {
private static DataSource dataSource; // 数据源
public long generateId() {
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
stmt.execute("UPDATE id_generator SET id=LAST_INSERT_ID(id+1)");
ResultSet rs = stmt.executeQuery("SELECT LAST_INSERT_ID()");
if (rs.next()) {
return rs.getLong(1);
}
} catch (SQLException e) {
// 异常处理
}
return -1;
}
}
```
#### 3.2 基于雪花算法的实现方式
雪花算法是Twitter开源的一种分布式唯一ID生成算法,可以在分布式环境下生成全

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Sharding-JDBC分库分表深入剖析专栏涵盖了关于Sharding-JDBC数据库分片技术的全面解析和应用实践。该专栏包括了Sharding-JDBC的基础知识、原理解析及使用入门,以及水平分片与垂直分片的区别与选择等方面内容。此外,该专栏还深入讨论了自动分表策略与手动分表策略的比较、分布式主键生成器的实现与选用等技术问题。除此之外,专栏还探讨了数据分片算法的详解与自定义、多数据源配置与管理、心跳检测与故障转移的处理等话题。同时,该专栏还介绍了与Sharding-JDBC相关的连接池配置与优化、分布式事务的实现与一致性保障、高可用与性能优化等内容。此外,还提供了监控与性能调优、常见问题解答与排错指南以及与Spring Boot、MyBatis和JPA的集成与最佳实践相关的文章。通过该专栏,读者可以全面了解Sharding-JDBC分库分表技术,并掌握其在实际应用中的最佳实践方法。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【单片机手势识别终极指南】:从零基础到项目实战
# 摘要
本文对单片机手势识别系统进行了全面的探讨,从基础理论到实践应用,涵盖了手势识别技术的原理、系统硬件配置、编程基础、算法实现以及系统集成与测试。重点分析了传感器技术、图像处理、机器学习模式识别在手势识别中的应用,并对单片机的选择、编程要点、硬件和软件集成技术进行了详细介绍。通过多个实战应用案例,本文展示了手势识别技术在智能家居、交互式娱乐以及工业自动化等领域的潜力与挑战,为相关领域的研究和开发提供了宝贵的参考和指导。
# 关键字
手势识
【圆周率的秘密】:7种古法到现代算法的演进和Matlab实现
# 摘要
圆周率是数学和科学领域中基础而关键的常数,历史上不断推动计算技术的发展。本文首先回顾了圆周率的历史和古代计算方法,包括阿基米德的几何逼近法、中国古代的割圆术以及古代印度和阿拉伯的算法。接着,本文探讨了现代算法,如无穷级数方法、随机算法和分数逼近法,及其在Matlab环境下的实现。文章还涵盖了Matlab环境下圆周率计算的优化与应用,包括高性能计算的实现、圆周率的视觉展示以及计算误差分析。最后,本文总结了圆周率在现代科学、工程、计算机科学以及教育中的广泛应用,展示了其跨学科的重要性。本文不仅提供了圆周率计算的历史和现代方法的综述,还强调了相关技术的实际应用和教育意义。
# 关键字
圆
RESURF技术深度解析:如何解决高压半导体器件设计的挑战
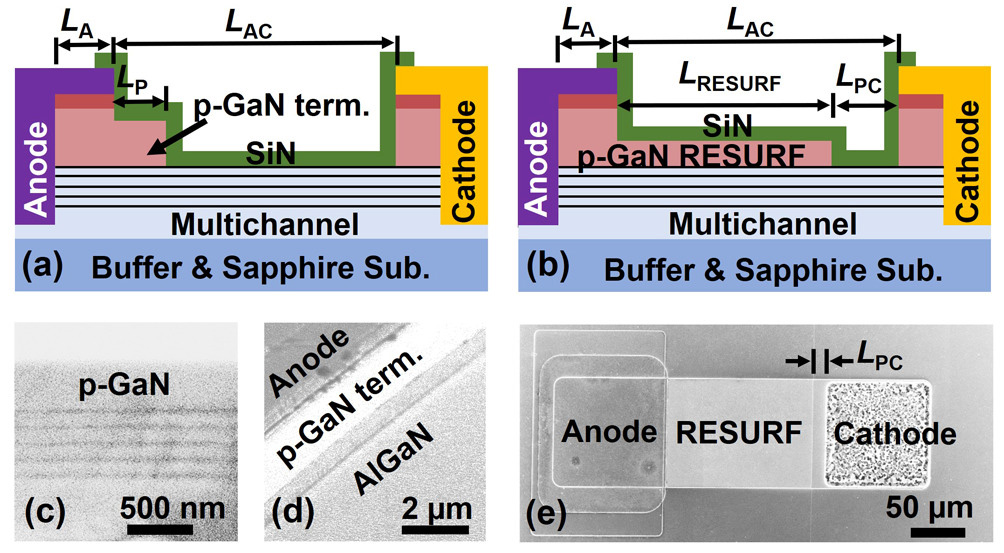
# 摘要
RESURF(Reduced Surface Field)技术作为提高高压器件性能的关键技术,在半导体物理学中具有重要的地位。本文介绍了RESURF技术的基础原理和理论基础,探讨了其物理机制、优化设计原理以及与传统高压器件设计的对比。通过对RESURF技术在高压器件设计中的应用、实践挑战、优化方向以及案例研究进行分析,本文阐述了RESURF技术在设计流程、热管理和可靠性评估中的
LDPC码基础:专家告诉你如何高效应用这一纠错技术
# 摘要
低密度奇偶校验(LDPC)码是一种高效的纠错码技术,在现代通信系统中广泛应用。本文首先介绍了LDPC码的基本原理和数学模型,然后详细探讨了LDPC码的两种主要构造方法:随机构造和结构化构造。随后,文章深入分析了LDPC码的编码和译码技术,包括其原理和具体实施方法。通过具体应用实例,评估了LDPC码在通信系统和其他领域的性能表现。最后,文章展望了LDPC码未来的发展方向和面临的挑战,强调了技术创新和应用领域拓展的重要性。
# 关键字
LDPC码;纠错原理;码字结构;编码技术;译码技术;性能分析
参考资源链接:[硬判决与软判决:LDPC码译码算法详解](https://wenku.c
【POS系统集成秘籍】:一步到位掌握收银系统与小票打印流程
# 摘要
本文综合介绍了POS系统集成的全面概述,涵盖了理论基础、实践操作及高级应用。首先,文中对POS系统的工作原理、硬件组成、软件架构进行了详细分析,进而探讨了小票打印机制和收银流程的逻辑设计。其次,作者结合具体实践,阐述了POS系统集成的环境搭建、功能实现及小票打印程序编写。在高级应用方面,文章重点讨论了客户管理、报表系统、系统安全和异常处理。最后,本文展望了未来POS系统的发展趋势,包括
【MinGW-64终极指南】:打造64位Windows开发环境的必备秘籍

# 摘要
本文详细介绍了MinGW-64及其在64位Windows操作系统中的应用。文章首先概述了MinGW-64的基本概念和它在现代软件开发中的重要作用。随后,文章指导读者完成MinGW-64的安装与配置过程,包括系统要求、环境变量设置、编译器选项配置以及包和依赖管理。第三章深入探讨了如何使用MinGW-64进行C/C++的开发工作,包括程序编写、编译、项目优化、性能分析及跨平台开发
【爱普生L3110驱动秘密】:专业技术揭秘驱动优化关键

# 摘要
本文对爱普生L3110打印机驱动进行了全面分析,涵盖了驱动概述、优化理论基础、优化实践、高级应用以及未来展望。首先介绍了驱动的基本概念和优化的重要性,接着深入探讨了驱动程序的结构和优化原则。在实践章节中,本文详细阐述了安装配置、性能调优及故障诊断的技巧。此外,还讨论了驱动的定制化开发、与操作系统的兼容性调整以及安全性的加固。最后,文章展望了驱动技术的发展趋势,社区合作的可能性以及用户体验的
DSP6416编程新手指南:C语言环境搭建与基础编程技巧

# 摘要
本文详细介绍了DSP6416平台的基础知识与C语言实践技巧,包括环境搭建、基础语法、硬件接口编程以及性能优化与调试方法。首先,本文概述了DSP6416平台特性,并指导了C语言环境的搭建流程,包括交叉编译器的选择和配置、开发环境的初始化,以及如何编写并运行第一个C语言程序。随后,深入探讨了C语言的基础知识和实践,着重于数据类型、控制结构、函数、指针以及动态内存管理。此外,
深入理解Lingo编程:@text函数的高级应用及案例解析

# 摘要
Lingo编程语言作为一种专业工具,其内置的@text函数在文本处理方面具有强大的功能和灵活性。本文首先概述了Lingo编程语言及其@text函数的基础知识,包括定义、功能、语法结构以及应用场景。接着,深入探讨了@text函数的高级特性,例如正则表达式支持、多语言国际化处理以及性能优化技巧。通过案例分析,展示了@text函数在数据分析、动态文本生成及复杂文本解析中的实际应用。此外,文章还研究了@text函数与其他编程语言的集成方法,
Keil环境搭建全攻略:一步步带你添加STC型号,无需摸索

# 摘要
本文旨在介绍Keil开发环境的搭建及STC系列芯片的应用。首先,从基础角度介绍了Keil环境的搭建,然后深入探讨了STC芯片的特性、应用以及支持的软件包。随后,详细描
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )