Teambition个性化设置技巧:打造属于自己的工作空间
发布时间: 2023-12-31 05:53:41 阅读量: 31 订阅数: 32 
# 一、 Teambition个性化设置的重要性
## 二、如何定制个性化工作空间?
在团队协作中,个性化的工作空间设置可以帮助我们更好地处理任务、管理日程以及获取及时通知。Teambition作为一款强大的团队协作工具,提供了丰富的个性化设置功能,使得每个人都能根据自己的工作习惯进行定制化操作。
### 2.1 设置个人工作空间主题
#### 场景描述
小明作为软件开发团队的一员,希望能够将工作空间的主题设置成他钟爱的暗黑风格,以提升自己的工作情绪和效率。
#### 代码示例
```python
from teambition import Workspace
def set_workspace_theme(workspace_id, theme):
workspace = Workspace(workspace_id)
workspace.set_theme(theme)
if __name__ == "__main__":
workspace_id = "xxxxxx" # 工作空间 ID
theme = "dark" # 主题设置为暗黑风格
set_workspace_theme(workspace_id, theme)
```
代码解释:
首先,我们引入了Teambition的Workspace类,以便进行个人工作空间的设置。然后,我们定义了一个名为`set_workspace_theme`的函数,函数参数为工作空间的ID和要设置的主题。在函数内部,我们通过Workspace类的`set_theme`方法将工作空间的主题设置为指定的值。
#### 代码总结
通过以上代码示例,我们演示了如何使用Teambition的API来设置个人工作空间的主题。这样的设置可以让每个成员根据自己的喜好来调整工作环境,提高工作效率。
### 2.2 自定义工作空间布局
#### 场景描述
小红希望能够通过自定义工作空间布局,将最常用的功能和页面组织在一起,以便快速访问和操作。
#### 代码示例
```java
import com.teambition.ApiClient;
import com.teambition.models.Layout;
public class WorkspaceLayout {
public static void customizeLayout(String workspaceId, Layout layout) {
ApiClient apiClient = new ApiClient();
apiClient.setToken("xxxxxxxx"); // 设置API访问令牌
apiClient.setWorkspaceLayout(workspaceId, layout);
}
public static void main(String[] args) {
String workspaceId = "xxxxxx"; // 工作空间 ID
Layout layout = Layout.builder()
.addToSidebar("tasks")
.addToSidebar("calendar")
.addToMainArea("inbox")
.build();
customizeLayout(workspaceId, layout);
}
}
```
代码解释:
首先,我们创建一个`WorkspaceLayout`类,在该类中定义了一个`customizeLayout`方法,方法参数为工作空间的ID和要设置的布局对象。在方法内部,我们使用Teambition提供的Java SDK,创建一个`ApiClient`实例,并设置API访问令牌。然后,我们调用`setWorkspaceLayout`方法,将工作空间的布局设置为我们指定的值。
#### 代码总结
通过以上Java代码示例,我们展示了如何使用Teambition的Java SDK来定制个人工作空间的布局。这样的设置可以让每个成员根据自己的需求进行个性化调整,方便快捷地访问和操作不同的功能和页面。
### 三、 个性化任务管理:让工作更高效
在Teambition中,个性化任务管理是非常重要的,它可以让每个成员根据自己的工

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《Teambition》涵盖了Teambition项目协作管理工具的各个方面,从基本功能介绍到高级技巧应用。首先介绍了项目协作管理工具的基本功能,以及在团队中设置权限和角色的指南。随后详细解析了日程、任务管理以及文件共享和在线讨论等功能,并提供了移动应用和个性化设置的技巧。此外,还包括了日报周报功能、第三方应用集成、团队统计与报表、桌面端插件等内容,以及敏捷项目管理、团队知识库等高级功能的详细介绍。最后,涉及了实时通知功能、API开发、大数据分析工具甚至人工智能技术的实践与应用。本专栏旨在帮助读者全面了解和高效使用Teambition,为他们的团队协作管理提供丰富而实用的技巧和指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
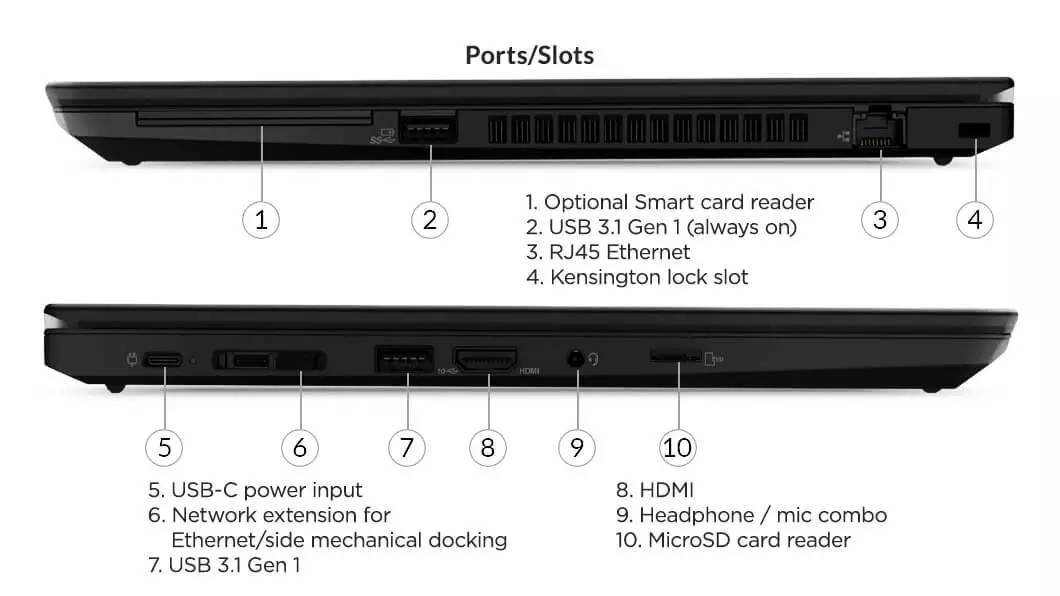
【IBM X230主板维修宝典】:故障诊断与解决策略大揭秘
# 摘要
本文旨在全面探讨IBM X230主板的结构、故障诊断、检测与修复技巧。首先,概述了IBM X230主板的基本组成与基础故障诊断方法。随后,深入解析了主板的关键组件,如CPU插槽、内存插槽、BIOS与CMOS的功能,以及电源管理的故障分析。此外,本文详细介绍了使用硬件检测工具进行故障检测的技巧,以及在焊接技术和电子元件识别与更换过程中需要遵循的注意事项。通过对维修案例的分析,文章揭示了
ELM327中文说明书深度解析:从入门到精通的实践指南
# 摘要
ELM327设备是一种广泛应用于汽车诊断和通讯领域的接口设备,本文首先介绍了ELM327的基本概念和连接方法,随后深入探讨了其基础通信协议,包括OBD-II标准解读和与车辆的通信原理。接着,本文提供了ELM327命令行使用的详细指南,包括命令集、数据流监测与分析以及编程接口和第三方软件集成。在高级应用实践章节中,讨论了自定义脚本、安全性能优化以及扩展功能开发。最后,文章展望了ELM327的未来发展趋势,特别是在无线技术和智能汽车时代中的潜在应用与角色转变。
# 关键字
ELM327;OBD-II标准;数据通信;故障诊断;安全性能;智能网联汽车
参考资源链接:[ELM327 OBD
QNX任务调度机制揭秘:掌握这些实践,让你的应用性能翻倍

# 摘要
本文详细探讨了QNX操作系统中任务调度机制的理论基础和实践应用,并提出了一些高级技巧和未来趋势。首先概述了QNX任务调度机制,并介绍了QNX操作系统的背景与特点,以及实时操作系统的基本概念。其次,核心原理章节深入分析了任务调度的目的、要求、策略和算法,以及任务优先级与调度器行为的关系。实践应用章
CANOE工具高效使用技巧:日志截取与分析的5大秘籍
# 摘要
本文旨在提供对CANoe工具的全面介绍,包括基础使用、配置、界面定制、日志分析和高级应用等方面。文章首先概述了CANoe工具的基本概念和日志分析基础,接着详细阐述了如何进行CANoe的配置和界面定制,使用户能够根据自身需求优化工作环境。文章第三章介绍了CANoe在日志截取方面的高级技巧,包括配置、分析和问题解决方法。第四章探讨了CANoe在不同场景下的应用
【面向对象设计核心解密】:图书管理系统类图构建完全手册

# 摘要
面向对象设计是软件工程的核心方法之一,它通过封装、继承和多态等基本特征,以及一系列设计原则,如单一职责原则和开闭原则,支持系统的可扩展性和复用性。本文首先回顾了面向对象设计的基础概念,接着通过图书管理系统的案例,详细分析了面向对象分析与类图构建的实践步骤,包括类图的绘制、优化以及高级主题的应用。文中还探讨了类图构建中的高级技巧,如抽象化、泛化、关联和依赖的处理,以及约束和注释的应用。此外,本文将类图应用于图书管理
零基础到专家:一步步构建软件需求规格说明

# 摘要
软件需求规格说明是软件工程中的基
【操作系统电梯调度算法】:揭秘性能提升的10大策略和实现

# 摘要
电梯调度算法作为智能建筑物中不可或缺的部分,其效率直接影响乘客的等待时间和系统的运行效率。本文首先探讨了电梯调度算法的基础理论,包括性能指标和不同调度策略的分类。随后,文章对实现基础和进阶电梯调度算法的实践应用进行了详细介绍,包括算法编码、优化策略及测试评估方法。进一
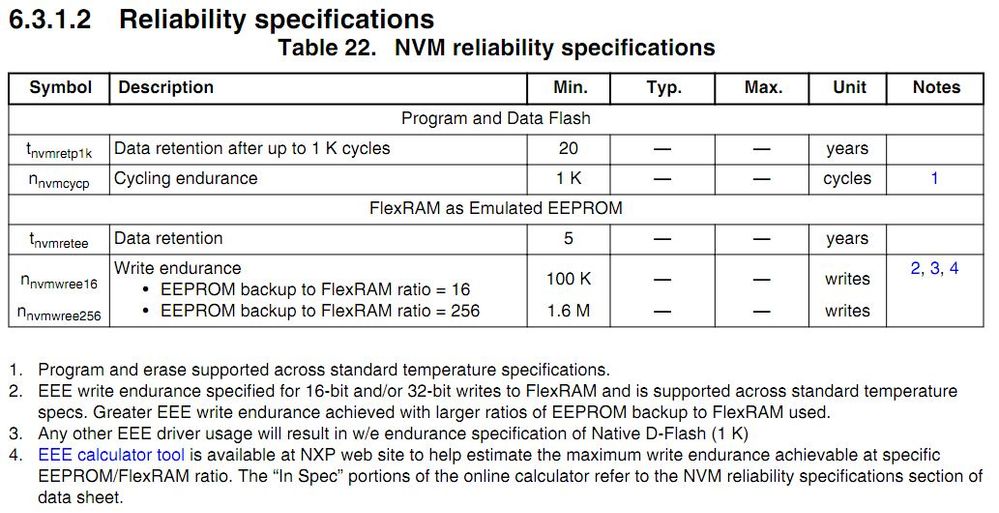
NAND Flash固件开发必读:专家级别的4个关键开发要点
# 摘要
NAND Flash固件开发是存储技术中的关键环节,直接影响存储设备的性能和可靠性。本文首先概述了NAND Flash固件开发的基础知识,然后深入分析了NAND Flash的存储原理和接口协议。特别关注了固件开发中的错误处理、数据保护、性能优化及高级功能实现。本文通过详细探讨编程算法优化、读写效率提升
【SSD技术奥秘】:掌握JESD219A-01标准的10个关键策略

# 摘要
本论文全面概述了固态驱动器(SSD)技术,并深入探讨了JESD219A-01标准的细节,包括其形成背景、目的、影响、关键性能指标及测试方法。文章还详细讲解了SSD的关键技术要素,例如NAND闪存技术基础、SSD控制器的作用与优化、以及闪存管理技术。通过分析标准化的SSD设计与测试,本文提供了实践应用案例,同时针对JESD219A-01标准面临的挑战,提出了相应的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )