MongoDB数据建模:设计灵活且可扩展的文档结构
发布时间: 2023-12-14 00:35:02 阅读量: 39 订阅数: 21 

可扩展性数据库的架构设计
# 1. 简介
## 1.1 MongoDB简介
MongoDB是一种开源的文档数据库,采用分布式文件存储方式,旨在为应用开发人员提供简单、高效和灵活的数据存储解决方案。相比于传统的关系型数据库,MongoDB以其无模式(Schema-less)的特点而闻名。
## 1.2 数据建模概述
数据建模是数据库设计的关键步骤,它涉及到如何组织和表示数据以满足应用程序的需求。数据建模不仅决定了数据的存储结构和查询方式,还直接影响到数据的性能和可扩展性。
在MongoDB中,数据建模的思路与传统的关系型数据库有所不同。它以文档为基本单位,采用灵活的模式来表示和组织数据,使得开发人员可以更自由地调整数据结构和查询方式,适应应用程序的变化。
接下来的章节将介绍MongoDB的特点和优势,以及数据建模的基础知识,帮助读者理解和掌握MongoDB的数据建模技巧。
# 2. 文档数据库简介
文档数据库是一种非关系型数据库,在存储和操作数据时使用灵活的文档形式而不是表。MongoDB是目前最流行的文档数据库之一,它具有很多特点和优势。
### 2.1 文档数据库 vs 关系型数据库
在传统的关系型数据库中,数据被组织成表的形式,每个表包含多个行和列。而在文档数据库中,数据以类似JSON的文档结构进行存储,每个文档都可以有不同的结构,非常灵活。
与关系型数据库相比,文档数据库具有以下优势:
- 处理复杂数据结构更容易:文档数据库支持嵌套文档和多值属性,可以更方便地表示复杂的数据结构。
- 灵活的模式设计:文档数据库的模式是动态的,可以根据应用需求随时调整和扩展,而不需要事先定义严格的表结构。
- 更高的可扩展性:文档数据库采用分片策略,可以将数据水平划分到多台服务器上,提高读写吞吐量和存储能力。
- 更好的性能:文档数据库通过索引和缓存机制优化查询性能,对于某些查询场景可以比关系型数据库更高效。
### 2.2 MongoDB的特点和优势
MongoDB是一款开源的文档数据库,具有以下特点和优势:
- 灵活的数据建模:MongoDB的文档结构非常灵活,可以根据应用需求设计复杂的数据结构和关系模型。
- 高性能和可伸缩性:MongoDB支持水平扩展,可以在集群中添加更多的节点来增加容量和负载均衡。
- 强大的查询功能:MongoDB支持丰富的查询语法和索引机制,可以高效地执行复杂的查询操作。
- 自动化和易用性:MongoDB提供了丰富的管理工具和驱动程序,简化了数据库的部署、管理和开发工作。
- 可靠的数据存储:MongoDB具有数据冗余和故障恢复机制,可以保证数据的安全和可靠性。
总之,文档数据库的出现以及MongoDB的特点和优势为开发者提供了更灵活、高效和可扩展的数据存储解决方案。在接下来的章节中,我们将介绍如何进行MongoDB数据建模以及一些最佳实践和注意事项。
# 3. 数据建模基础知识
在使用MongoDB进行数据建模之前,有一些基础知识是非常重要的。本章节将介绍文档结构、集合和文档的关系以及MongoDB的数据类型。
#### 3.1 文档结构
MongoDB中的数据是以文档的形式存储的,文档是一组键值对的有序集合。文档类似于关系型数据库中的行,但更加灵活,可以包含不同数量和类型的字段。例如,下面是一个简单的MongoDB文档示例:
```javascript
{
_id: ObjectId("60a8c5b6c9e77cfc8d6d3d27"),
name: "John Doe",
age: 30,
email: "john.doe@example.com"
}
```
在MongoDB中,文档由键值对构成,键是字符串,值可以是各种不同的数据类型,包括文档、数组、字符串、数字、布尔值等。
#### 3.2 集合和文档的关系
在MongoDB中,文档被组织在集合(Collection)中。集合类似于关系型数据库中的表,但是没有固定的模式,可以容纳各种格式的文档。一个数据库可以拥有多个集合,每个集合可以包含多个文档。
#### 3.3 MongoDB的数据类型
MongoDB支持多种数据类型,包括字符串、整数、浮点数、日期、正则表达式、数组、文档等。这些数据类型可以嵌套在彼此中,从而构建复杂的数据结构。
```javascript
{
name: "John Doe",
age: 30,
hobbies: ["reading", "hiking"],
address: {
city: "New York",
zip: 10001
}
}
```
以上是一些基础概念,接下来我们将深入探讨如何利用这些基础知识进行数据建模和设计。
# 4. 设计灵活的文档结构
在MongoDB中,文档是数据的基本单元,每个文档都以BSON(Binary JSON)格式存储,它是一种类似于JSON的二进制编码。文档可以包含不同类型的字段,每个字段都有一个唯一的键,用于访问该字段的值。在设计文档结构时,我们需要考虑如何最大程度地利用MongoDB的灵活性和可扩展性,以适应不同的数据模型和查询需求。
#### 4.1 嵌套文档的设计与使用
MongoDB支持嵌套文档的概念,这意味着一个文档可以包含另一个文档作为其字段。嵌套文档的设计可以帮助我们更好地组织和表示数据层次结构。例如,假设我们有一个电影网站,我们可以使用嵌套文档来表示电影信息和演员信息。
```python
# 示例代码:使用嵌套文档的电影信息数据模型
{
"_id": ObjectId("603fc0fdac13ae1f8c4e23b4"),
"title": "The Shawshank Redemption",
"genre": "Drama",
"director": "Frank Darabont",
"actors": [
{
"name": "Tim Robbins",
"age": 62,
"character": "Andy Dufresne"
},
{
"name": "Morgan Freeman",
"age": 84,
"character": "Ellis Boyd 'Red' Redding"
}
]
}
```
上面的示例中,电影文档包含了一个嵌套的演员数组,每个演员又是一个嵌套文档,其中包含演员的姓名、年龄和饰演角色。这样的设计可以方便地查询某个电影的所有演员信息,同时也能够灵活地添加或删除演员。
#### 4.2 构建多值属性
在一些场景下,一个文档的某个字段可能包含多个值,这时我们可以使用数组来表示多个值的属性。例如,一个商品文档可以包含多个标签。
```java
// 示例代码:使用数组的商品文档数据模型
{
"_id": ObjectId("603fc2f1dbf2973fc0c34439"),
"name": "Smartphone",
"price": 999,
"tags": ["mobile", "electronics", "technology"]
}
```
上面的示例中,商品文档的"tags"字段是一个包含多个标签的数组。我们可以根据标签来查询商品,同时也可以轻松地添加或删除标签。
#### 4.3 引用关系的建模
在某些情况下,我们可能需要引用其他文档的数据,这时可以使用引用关系来建模。例如,在一个博客网站中,我们可以将博文和评论分别存储在不同的集合中,并通过引用关系建立它们之间的关联。
```javascript
// 示例代码:使用引用关系的博文和评论数据模型
// 文章集合
{
"_id": ObjectId("603fc48f1a38c7c0368ef027"),
"title": "Introduction to MongoDB",
"content": "MongoDB is a popular NoSQL database...",
"author": "John"
}
// 评论集合
{
"_id": ObjectId("603fc4a61a38c7c0368ef028"),
"postId": ObjectId("603fc48f1a38c7c0368ef027"),
"content": "Great article!",
"author": "Alice"
}
```
上面的示例中,评论文档中的"postId"字段使用ObjectId类型来存储关联的文章的_id。这样设计的好处是可以方便地根据文章ID查询其对应的评论。
通过合理地设计文档结构,使用嵌套文档、数组和引用关系等技巧,我们可以更好地组织和表示数据,在满足查询需求的同时提高数据的灵活性和可扩展性。但是在设计时也需要注意权衡数据的一致性和性能的考虑,避免过度嵌套或过多引用导致的查询复杂性和性能问题。
# 5. 可扩展性考虑
在设计MongoDB数据模型时,除了考虑数据结构的灵活性和合理性外,还需要考虑系统的可扩展性。MongoDB提供了一些特性来支持大规模数据的存储和查询,包括分片策略、数据分发和索引的优化。
### 5.1 分片策略和数据分发
分片是MongoDB用来支持超大规模数据的一种方式。通过分片,可以将数据分布到多个部署节点上,从而降低单个节点的负载压力,实现水平扩展。
分片的过程包括选择分片键、配置分片集群、管理数据分布等步骤。选择合适的分片键对数据库性能至关重要,需要根据应用的读写模式和数据访问方式来选择。通常情况下,选择高基数、均匀分布的字段作为分片键会获得更好的效果。
数据分发是指MongoDB如何将数据均匀地分布在各个分片上。MongoDB使用哈希分片和范围分片两种方式来实现数据的均匀分布。在实际应用中,需要根据数据的特点和访问模式来选择合适的数据分发方式。
### 5.2 使用索引提高查询性能
除了分片策略和数据分发外,索引也是提高MongoDB可扩展性的重要手段。通过合理的索引设计,可以加快查询的速度,并减小数据库的负载。
MongoDB支持各种类型的索引,包括单键索引、复合索引、文本索引、地理空间索引等。在实际应用中,需要根据数据库的访问模式和查询需求来选择合适的索引类型,并且需要定期进行索引的优化和维护,以确保查询性能的稳定和高效。
综合考虑分片策略、数据分发和索引的优化,可以使MongoDB的性能得到进一步的提升,从而更好地支持大规模数据的存储和查询。
以上内容为第五章节的大致框架,具体的代码和详细解释需要根据实际情况来编写。
# 6. 最佳实践和注意事项
在MongoDB数据建模过程中,有一些最佳实践和注意事项需要我们特别关注。下面将详细介绍这些内容。
#### 6.1 设计原则和良好的实践
在设计MongoDB文档结构时,需要遵循一些设计原则和良好的实践,比如避免过度嵌套文档、使用合适的数据类型、避免频繁更新嵌套的数组等。此外,还需要考虑数据一致性、可靠性和性能方面的平衡,确保设计的文档结构能够满足业务需求并且具有良好的性能表现。
```python
# 示例代码
# 避免过度嵌套文档
# 不推荐的过度嵌套
{
"_id": 1,
"name": "John",
"address": {
"city": "New York",
"street": "123 Main St"
}
}
# 推荐的扁平化结构
{
"_id": 1,
"name": "John",
"city": "New York",
"street": "123 Main St"
}
```
通过合理的设计原则和实践,可以避免潜在的性能问题,并使文档结构更加清晰和易于维护。
#### 6.2 数据迁移和版本控制
随着业务的发展,可能需要对现有的数据模型进行调整或扩展,因此数据迁移和版本控制变得尤为重要。在进行数据迁移时,需要考虑数据的一致性和迁移过程中的性能影响,同时确保在数据迁移完成后应用程序能够正常访问新的数据模型。
```java
// 示例代码
// 数据迁移示例
// 在集合中添加新字段
db.customers.updateMany({}, { $set: { "status": "active" } })
```
版本控制则可以帮助跟踪数据模型的变化,并对不同版本的数据模型进行管理和回滚。这对于系统升级和维护非常重要。
#### 6.3 如何处理复杂的查询需求
在实际业务中,复杂的查询需求时常会出现,这就需要我们对MongoDB的强大查询功能有所了解,并且能够灵活运用。合理地设计索引、利用聚合管道、理解查询性能优化等内容都是处理复杂查询需求的关键。
```javascript
// 示例代码
// 使用聚合管道处理复杂查询
db.orders.aggregate([
{ $match: { status: "shipped" } },
{ $group: { _id: "$customer", total: { $sum: "$amount" } } }
])
```
通过合理的查询设计和优化,可以快速、高效地满足各种复杂的查询需求。
通过上述最佳实践和注意事项的介绍,读者可以更好地理解MongoDB数据建模过程中需要注意的细节,并且能够在实际应用中有的放矢地进行数据建模和查询优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将从MongoDB的基础知识出发,深入探讨其数据建模、操作、优化和安全性等方面的内容。文章将介绍如何设计灵活且可扩展的文档结构,以及使用MongoDB进行数据插入、更新和查询操作的技巧。此外,还将重点讨论MongoDB索引优化和聚合管道的使用,以提高性能和查询效率,实现复杂数据分析。专栏还将深入探讨MongoDB的复制集和分片集群,以实现高可靠性、数据冗余、水平扩展和负载均衡。此外,专栏还会关注MongoDB的安全性,探讨如何保护数据免受潜在的威胁。最后,专栏将介绍使用MongoDB进行地理空间数据存储和查询的方法,并对MongoDB与关系型数据库进行比较,探讨迁移策略。通过本专栏的学习,读者将全面了解MongoDB的各项功能和使用技巧,为实际应用提供全面指导。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【HM-10蓝牙模块全攻略】:揭秘10大必学蓝牙通信技巧及应用案例

# 摘要
本文对HM-10蓝牙模块进行了全面的概述和分析,内容涵盖其简介、与蓝牙技术标准的关系,以及硬件连接方式。进一步,我们探讨了HM-10模块的通信基础,包括蓝牙技术的原理、协议栈、AT指令集的应用,以及配对与连接的流程。文章接着深入到编程与实践部分,介绍了HM-10模块的串口通信编程、智能设备接入方法和多设备通信策略。在高级应用技巧章节,重点讨论了安全通信机制、低功耗模式的应用以及物联网中的案例。最后,本文提供了故障诊断与
敏捷测试团队协作:沟通与流程的艺术,提升团队效率的秘诀
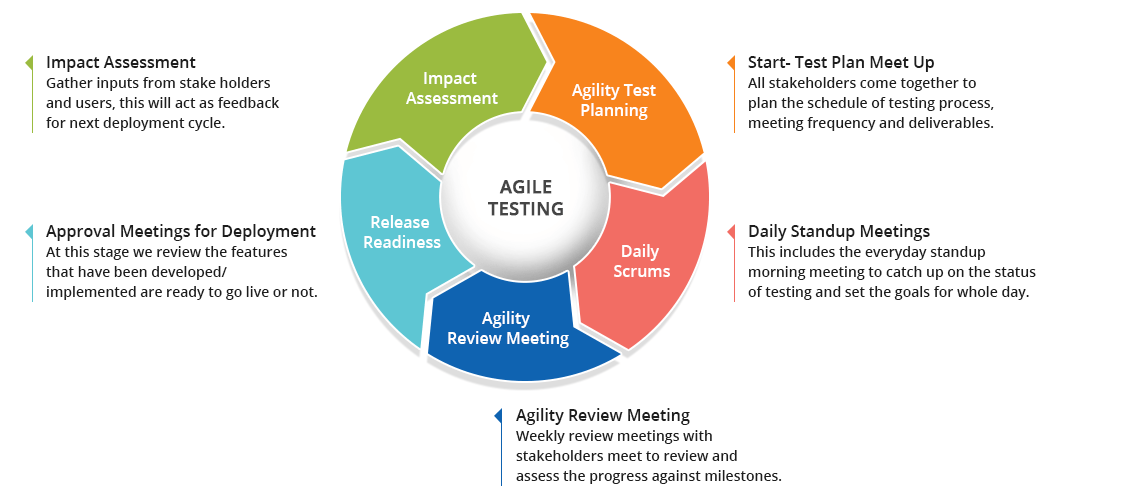
# 摘要
敏捷测试作为软件开发流程中的重要环节,要求团队成员之间高效沟通、持续改进测试流程,并采用适当工具以满足快速变化的需求。本文首先概述了敏捷测试的基本原则和沟通的艺术,强调了有效沟通在敏捷团队中的重要性。随后,文章探
ALCATEL交换机性能飙升:5大优化技术让你领先一步

# 摘要
本文综合阐述了ALCATEL交换机的性能优化和安全管理,从基础网络优化技术到高级性能调优技巧,再到交换机安全性能的提升,系统地介绍了交换机性能提升的方法与策略。文章深入分析了固件升级、端口配置、QoS配置、高可用性集群配置、负载均衡和性能监控工具使用等方面的细节,并探讨了访问控制列表(ACL)的深入应用、网络安全防御策略、端口安全与动态ARP检测等安
存储系统IOPS与带宽实战:专家教你如何平衡和优化
# 摘要
随着数据量的爆炸性增长,存储系统的性能优化已成为提升计算效率的关键因素。本文系统地介绍了存储系统IOPS与带宽的基础知识、理论以及优化实践,深入分析了影响IOPS与带宽的关键因素,并探讨了磁盘阵列配置、虚拟化环境以及云存储在性能优化中的应用。通过案例研究,本文展示了如何在生产环境中平衡IOPS与带宽,提出针对性的优化方案,并对优化效果进行了评估。研究结果表明,合理的配置优化和性能测试对于实现存储系统性能提升至关重要。
# 关键字
IOPS;带宽;性能优化;存储系统;虚拟化;云存储
参考资源链接:[IOPS与带宽:理解VNX中端存储的性能限制](https://wenku.csdn
【电路设计精进秘籍】
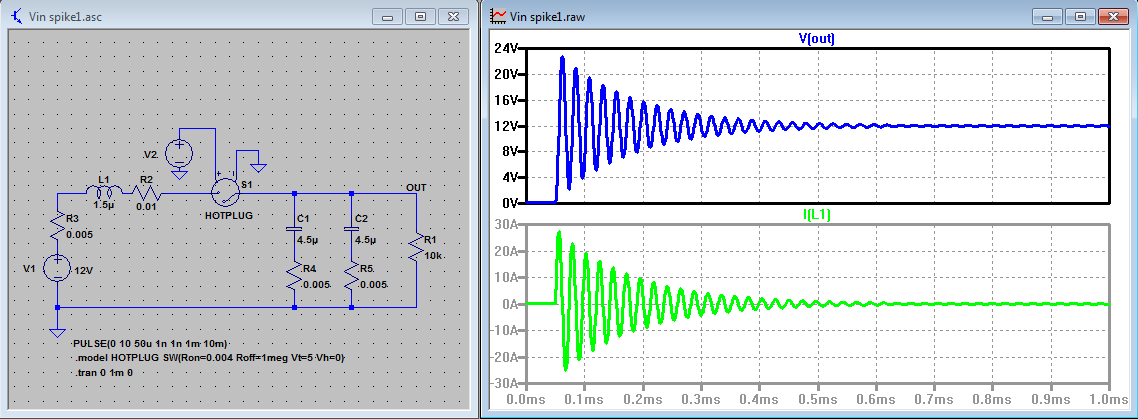
# 摘要
电路设计是电子工程领域的核心技能,涉及从基础理论到高级设计策略的广泛知识。本文深入探讨了电路设计的各个方面,包括基础理论、仿真分析、元件选型、PCB布局布线以及高级话题。文中第一章为电路设计提供了理论基础;第二章详述了电路仿真软件的选择与配置、常见分析方法以及仿真案例。第三章重
【Ajax进阶宝典】:动态构建省市区联动系统的秘诀

# 摘要
本文首先概述了Ajax技术的原理和应用,然后详细介绍了省市区联动系统的前后端实现,包括前端页面结构设计、JavaScript交
泛微E9表单API高级应用:15种实用技巧与实践案例

# 摘要
泛微E9表单API作为企业信息系统中重要的交互工具,其应用日益广泛。本文首先概述了泛微E9表单API的基础知识,随后深入探讨了掌握其核心技巧的方法,涵盖了数据交互原理、API构建与调用、身份认证机制及安全性等方面。进阶应用部分介绍了自定义表单字段、高级数据处理、以及工作流集成的高级技巧。通过实践案例分析,文章展示了API在业务流程自动化、系统集成和移动端应用中的实际应用,最后展望了企业级应用中
Oracle数据库深度应用解析:金融行业的成功案例
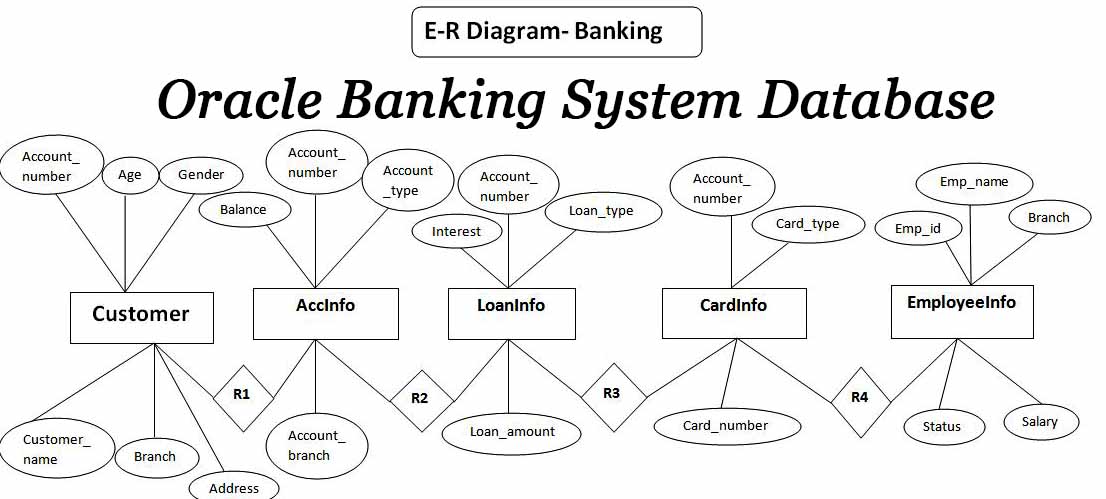
# 摘要
Oracle数据库作为金融行业的核心数据库管理系统,其在数据处理、存储及安全性方面发挥着不可替代的作用。本文首先概述了Oracle数据库的基础架构及其管理,包括内存和存储结构、进程模型、安装配置、认证授权以及安全策略。随后,文章深入探讨了性能优化和故障处理技术,涉及到性能监控工具、SQL调优、优化器策略以及故障预防和恢复措施。案例分析章节
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )