Spring Cloud中的Eureka服务发现
发布时间: 2024-02-20 17:38:28 阅读量: 37 订阅数: 22 
# 1. 理解微服务架构
微服务架构是一种软件架构设计方式,将单一的应用拆分成多个小的服务单元,每个服务单元都独立部署、独立运行,并且通过轻量级通信机制相互配合。微服务架构的核心理念是将复杂的系统分解为小的、易于管理和维护的部分。
## 1.1 什么是微服务架构
微服务架构是一种基于分布式系统的架构风格,其主要特点是每个功能模块都是一个独立的服务单元,通过轻量级的通信协议进行通信。这种模块化的设计方式有利于系统的拓展、维护和升级,同时也提高了系统的弹性和灵活性。
## 1.2 微服务架构的优势和挑战
微服务架构的优势包括:
- **高内聚低耦合**:每个微服务模块独立开发、部署、扩展,相互之间耦合度低。
- **易于维护**:每个微服务都是小型服务单元,易于维护和更新。
- **弹性伸缩**:可以根据业务需求对每个微服务进行独立的水平扩展。
- **技术栈无关**:不同的微服务模块可以使用不同的技术栈。
微服务架构也面临一些挑战,如:
- **分布式系统复杂性**:微服务架构引入了分布式系统,带来了部署、调试、测试等方面的挑战。
- **服务治理**:需要有效管理大量微服务的注册、发现、调用、负载均衡等问题。
- **数据一致性**:微服务架构下的数据一致性难题需要仔细考虑和解决。
## 1.3 微服务架构中的服务注册与发现的重要性
在微服务架构中,服务的数量庞大且动态变化,需要一种机制来实现服务的自动注册和发现。服务注册与发现的重要性体现在:
- **动态性**:微服务的数量和位置可能经常变化,需要实时更新服务注册表。
- **负载均衡**:需要根据负载情况动态地调整请求的分发。
- **故障恢复**:当某个服务发生故障时,需要快速切换到其他可用服务上。
服务注册与发现的实现可以通过开源工具如Eureka、Consul、ZooKeeper等来简化系统的管理和维护。 Eureka是Netflix开源的一款服务发现工具,结合Spring Cloud可以方便地搭建微服务架构下的服务注册与发现系统。
# 2. 介绍Spring Cloud和Eureka
### 2.1 Spring Cloud简介
在微服务架构中,Spring Cloud 是一个重要的辅助工具,它提供了一系列的快速开发分布式系统需要的工具集。Spring Cloud基于Spring Boot,通过自动化配置和约定大于配置的原则,实现了快速构建分布式系统的能力。
### 2.2 Eureka服务发现的概念和作用
Eureka是Netflix开源的基于REST的服务发现组件,用于服务的注册和发现。它主要包括Eureka Server和Eureka Client两部分,Eureka Server用作服务注册中心,而Eureka Client用于向注册中心注册自身服务,并从注册中心获取其他服务的信息和实现负载均衡。
### 2.3 Spring Cloud中Eureka的定位和特点
在Spring Cloud中,Eureka作为服务注册中心,能够帮助实现微服务架构中的服务注册与发现、负载均衡、故障转移等功能。通过Eureka,我们可以很方便地扩展服务,实现动态的集群扩容和缩容,提高了系统的可用性和扩展性。
# 3. 搭建Eureka服务注册中心
在本章中,我们将介绍如何搭建Eureka服务注册中心,包括引入Spring Cloud Eureka依赖、编写Eureka服务注册中心的配置文件以及启动Eureka服务注册中心应用。
#### 3.1 在项目中引入Spring Cloud Eureka依赖
首先,我们需要在项目的Maven或Gradle配置文件中引入Spring Cloud Eureka的依赖。下面以Maven为例,在pom.xml文件中添加以下依赖:
```xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
```
#### 3.2 编写Eureka服务注册中心的配置文件
创建一个Spring Boot应用,并编写Eureka服务注册中心的配置文件,主要配置Eureka服务注册中心的端口号和服务名称。在application.properties(或application.yml)文件中添加以下配置:
```yml
server:
port: 8761
spring:
application:
name: eureka-server
eureka:
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://localhost:8761/eureka/
```
上面的配置中,定义了Eureka服务注册中心的端口号为8761,并且指定了Eureka的服务URL。
#### 3.3 启动Eureka服务注册中心应用
接下来,编写一个启动类,添加@EnableEurekaServer注解,用于启动Eureka服务注册中心应用。
```java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
```
运行启动类,控制台输出类似以下信息即表示Eureka服务注册中心启动成功:
```
2021-01-01 10:10:10.123 INFO 12345 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8761 (http) with context path ''
2021-01-01 10:10:10.127 INFO 12345 --- [ main] c.example.eurekaserver.EurekaServerApplication : Started EurekaServerApplication in 9.887 seconds (JVM running for 10.623)
```
至此,我们成功搭建了Eureka服务注册中心,并且可以通过http://localhost:8761访问Eureka的管理页面,查看注册的各个服务实例信息。
在这一章节中,我们详细介绍了如何搭建Eureka服务注册中心,包括依赖引入、配置文件编写和应用启动。在下一章节,我们将介绍如何注册微服务到Eureka中。
# 4. 注册微服务到Eureka
在这一章中,我们将学习如何将微服务注册到Eureka服务注册中心,实现服务的注册与发现。
#### 4.1 配置微服务模块注册到Eureka的相关信息
在微服务模块的配置文件(比如application.properties或者application.yml)中,我们需要添加以下Eureka相关的配置信息:
```yaml
spring:
application:
name: your-service-name
eureka:
client:
serviceUrl:
defaultZone: http://eureka-server-host:port/eureka/
```
- `spring.application.name`: 设置该微服务的名称,用于在Eureka服务注册中心进行标识
- `eureka.client.serviceUrl.defaultZone`: 设置Eureka服务注册中心的地址,格式为"http://eureka-server-host:port/eureka/"
#### 4.2 编写微服务的启动类并添加@EnableEurekaClient注解
在微服务的启动类上(Spring Boot Application主类)添加`@EnableEurekaClient`注解,以启用Eureka客户端功能,代码示例如下:
```java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
public class YourServiceApplication {
public static void main(String[] args) {
SpringApplication.run(YourServiceApplication.class, args);
}
}
```
#### 4.3 启动微服务应用,查看注册情况
启动配置好Eureka相关信息的微服务应用,可以在Eureka服务注册中心的Dashboard界面或者通过Eureka的REST API接口,查看该微服务模块是否成功注册到Eureka服务注册中心。
通过以上步骤,我们成功实现了将微服务注册到Eureka,并且Eureka服务注册中心成功发现和管理了该微服务。
# 5. 实现服务发现与负载均衡
在微服务架构中,服务的动态发现和负载均衡是非常重要的一环,而Spring Cloud中的Eureka和Ribbon就提供了这样的解决方案。接下来,我们将介绍如何通过Eureka服务注册中心实现服务发现,并结合Ribbon实现客户端负载均衡。
#### 5.1 通过Eureka服务注册中心实现服务发现
首先,我们需要确保我们的微服务已经成功注册到Eureka服务注册中心。通过Eureka的REST API可以轻松地实现服务的查找和发现。
```java
@RestController
public class ServiceDiscoveryController {
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping("/services")
public List<String> getAllServices() {
List<String> services = discoveryClient.getServices();
return services;
}
@GetMapping("/service/instances/{serviceName}")
public List<ServiceInstance> getServiceInstances(@PathVariable String serviceName) {
List<ServiceInstance> instances = discoveryClient.getInstances(serviceName);
return instances;
}
}
```
上面的代码演示了一个简单的Spring Boot控制器,通过注入DiscoveryClient来获取注册在Eureka服务注册中心的服务信息。`/services`接口返回所有已注册服务的列表,而`/service/instances/{serviceName}`接口则返回指定服务名的所有实例列表。
#### 5.2 使用Ribbon实现客户端负载均衡
Ribbon是一个负载均衡客户端,集成了在客户端的负载均衡算法。在Spring Cloud中,通过在RestTemplate中结合Ribbon的支持,可以实现对服务实例的负载均衡调用。下面是一个简单的使用示例:
```java
@RestController
public class LoadBalancerController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/call-service")
public String callService() {
String response = restTemplate.getForObject("http://SERVICE-PROVIDER/service", String.class);
return "Response from service: " + response;
}
}
```
在上面的示例中,我们通过RestTemplate向`SERVICE-PROVIDER`服务发送请求,通过Ribbon的负载均衡机制,会自动选择一个可用的服务实例进行调用。
#### 5.3 实现服务之间的调用与负载均衡效果验证
通过以上的代码示例,我们已经实现了服务发现和负载均衡的功能。接下来,启动Eureka注册中心、服务提供者和服务消费者应用,并调用`/call-service`接口进行测试,观察每次请求的服务实例情况,验证负载均衡效果的实现情况。
通过以上步骤,我们成功实现了服务发现与负载均衡功能,为微服务架构的稳定运行提供了有力保障。
# 6. 监控与容错
在微服务架构中,监控和容错是非常重要的环节。在Spring Cloud中,我们可以通过Eureka Dashboard来监控服务注册情况,并使用Hystrix来实现服务的熔断与容错。
6.1 使用Eureka Dashboard监控服务注册情况
在浏览器中访问Eureka Dashboard的地址,可以看到各个微服务实例的健康状态、服务数量以及其他相关信息。
```java
// 示例代码
// 访问Eureka Dashboard的地址
http://your_eureka_server:port
```
6.2 配置Hystrix实现服务熔断与容错
在微服务中引入Hystrix依赖,并在需要进行熔断与容错的方法上添加@HystrixCommand注解,当服务出现故障时,Hystrix会进行熔断和快速返回默认值或执行降级逻辑。
```java
// 示例代码
// 引入Hystrix依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
// 在需要进行熔断与容错的方法上添加@HystrixCommand注解
@HystrixCommand(fallbackMethod = "fallbackMethodName")
public String yourMethod() {
// 业务逻辑
}
// 定义熔断时的降级方法
public String fallbackMethodName() {
// 降级逻辑
}
```
6.3 分析监控数据和处理服务出现故障的情况
通过监控数据,我们可以分析服务的调用情况、熔断情况以及服务的健康状态,根据分析结果进行相应的优化和处理。当服务出现故障时,可以根据Hystrix的熔断策略进行快速的容错处理,保证整个系统的稳定性和可靠性。
以上就是在Spring Cloud中实现监控与容错的方法,通过Eureka Dashboard实现对服务的监控,并通过Hystrix实现对服务的熔断与容错。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Eureka服务注册与发现"为主题,系统性地介绍了在Spring Cloud中如何使用Eureka进行服务注册和发现。从Eureka健康检查的实现与机制、负载均衡策略、客户端自定义的注册与发现,到服务失效处理机制,全面深入地剖析了Eureka的各项功能及其实现机制。同时,通过与Zookeeper、Consul、Kubernetes等服务注册比较的深入探讨,为读者提供了更多选择方案的对比和参考。此外,还详细介绍了Spring Cloud中Eureka客户端的使用、负载均衡的实现以及服务版本控制等实际应用。本专栏内容丰富、实用性强,适合想要深入了解Eureka服务注册与发现的开发人员和架构师阅读参考。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【刷机安全教程】:如何安全地刷Kindle Fire HDX7 三代
# 摘要
本文旨在提供关于刷机操作的全面基础知识与实践指南。从准备刷机工作环境的细节,如设备兼容性确认、软件获取和数据备份,到详细的刷机流程,包括Bootloader解锁、刷机包安装及系统引导与设置,本文深入讨论了刷机过程中的关键步骤和潜在风险。此外,本文还探讨了刷机后的安全加固、性能调优和个性化定制,以及故障诊断与恢复方法,为用户确保刷机成功和设备安全性提供了实用的策略和技巧。
# 关键字
刷机;设备兼容性;数据备份;Bootloader解锁;系统引导;故障诊断
参考资源链接:[Kindle Fire HDX7三代救砖教程:含7.1.2刷机包与驱动安装](https://wenku.cs
【RN8209D电源管理技巧】:打造高效低耗的系统方案

# 摘要
本文综合介绍RN8209D电源管理芯片的功能与应用,概述其在不同领域内的配置和优化实践。通过对电源管理基础理论的探讨,本文阐释了电源管理对系统性能的重要性,分析了关键参数和设计中的常见问题,并给出了相应的解决方案。文章还详细介绍了RN8209D的配置方
C#设计模式:解决软件问题的23种利器
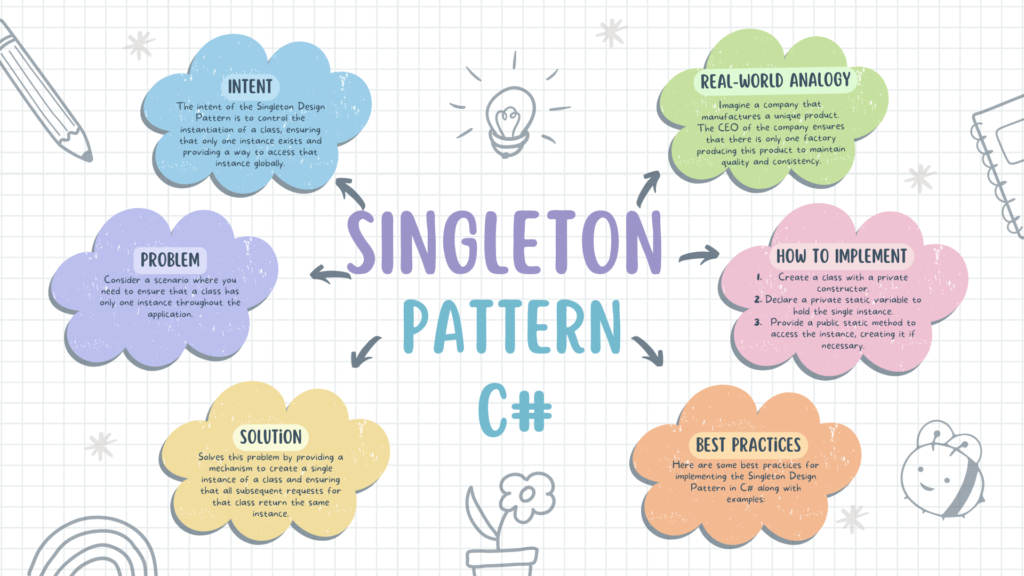
# 摘要
设计模式作为软件工程中的一种重要方法论,对于提高代码的可重用性、可维护性以及降低系统的复杂性具有至关重要的作用。本文首先概述了设计模式的重要性及其在软件开发中的基础地位。随后,通过深入探讨创建型、结构型和行为型三种设计模式,本文分析了每种模式的理论基础、实现技巧及其在实际开发中的应用。文章强调了设计模式在现代软件开发中的实际应用,如代码复用、软件维护和架构设计,并提供了相关模式的选择和运用策略
【性能基准测试】:极智AI与商汤OpenPPL在实时视频分析中的终极较量

# 摘要
实时视频分析技术在智能监控、安全验证和内容分析等多个领域发挥着越来越重要的作用。本文从实时视频分析技术的性能基准测试出发,对比分析了极智AI和商汤OpenPPL的技术原理、性能指标以及实践案例。通过对关键性能指标的对比,详细探讨了两者的性能优势与劣势。文章进一步提出了针对两大技术的性能优化策略,并预测了实时视频分析技术的未来发展趋势及其面临的挑战。研究发现,硬件加速技术和软件算法优化是提升实时视频
【24小时精通安川机器人】:新手必读的快速入门秘籍与实践指南

# 摘要
安川机器人作为自动化领域的重要工具,在工业生产和特定行业应用中发挥着关键作用。本文首先概述了安川机器人的应用领域及其在不同行业的应用实例。随后,探讨了安川机器人的基本操作和编程基础,包括硬件组成、软件环境和移动编程技术。接着,深入介绍了安川机器人的高级编程技术,如数据处理、视觉系统集成和网络通信,这些技术为机器人提供了更复杂的功能和更高的灵活性。
【定时器应用全解析】:单片机定时与计数,技巧大公开!

# 摘要
本文深入探讨了定时器的基础理论及其在单片机中的应用。首先介绍了定时器的基本概念、与计数器的区别,以及单片机定时器的内部结构和工作模式。随后,文章详细阐述了单片机定时器编程的基本技巧,包括初始化设置、中断处理和高级应用。第四章通过实时时钟、电机控制和数据采集等实例分析了定时器的实际应用。最后,文章探讨了定时器调试与优化的方法,并展望了定时器技术的未来发展趋势,特别是高精度定时器和物联网应用的可能性
【VIVADO逻辑分析高级应用】:掌握高级逻辑分析在VIVADO中的技巧
# 摘要
本文旨在全面介绍VIVADO逻辑分析工具的基础知识与高级应用。首先,概述了VIVADO逻辑分析的基本概念,并详细阐述了其高级工具,如Xilinx Analyzer的界面操作及高级功能、时序分析与功耗分析的基本原理和高级技巧。接着,文章通过实践应用章节,探讨了FPGA调试、性能分析以及资源管理的策略和方法。最后,文章进一步探讨了
深度剖析四位全加器:计算机组成原理实验的不二法门

# 摘要
四位全加器作为数字电路设计的基础组件,在计算机组成原理和数字系统中有广泛应用。本文详细阐述了四位全加器的基本概念、逻辑设计方法以及实践应用,并进一步探讨了其在并行加法器设
高通modem搜网注册流程的性能调优:影响因素与改进方案(实用技巧汇总)

# 摘要
本文全面概述了高通modem搜网注册流程,包括其技术原理、性能影响因素以及优化实践。搜网技术原理的深入分析为理解搜网流程提供了基础,而性能影响因素的探讨涵盖了硬件、软件和网络环境的多维度考量。理论模型与实际应用的差异进一步揭示了搜网注册流程的复杂性。文章重点介绍了性能优化的方法、实践案例以及优化效果的验证分析。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )