初识计算方法:从常见算法到数值计算基础
发布时间: 2024-03-02 05:20:00 阅读量: 64 订阅数: 23 

数值计算基础
# 1. 算法基础
### 1.1 算法的概念与分类
在计算机科学中,算法是指对特定问题求解步骤的准确而完整的描述,它是解决问题的方法。算法可以分为以下几类:
- **排序算法**:用于对一组数据进行排序,如冒泡排序、快速排序等。
- **查找算法**:用于在数据集中查找指定元素,例如线性查找、二分查找等。
- **动态规划**:通过拆分问题,将问题分解为更小的子问题来解决的算法。
### 1.2 常见算法的应用领域
常见算法在各个领域都有广泛应用:
- **图像处理**:算法用于图像压缩、图像识别等。
- **人工智能**:机器学习、深度学习等算法的应用。
- **网络安全**:密码学算法、加密解密算法等在网络安全中的应用。
在接下来的章节中,我们将深入探讨算法的具体内容及应用。
# 2. 基本数据结构
数据结构是计算机存储、组织数据的方式,对算法的设计和应用起着至关重要的作用。在计算方法中,常用到的基本数据结构包括数组、链表、栈和队列等,它们在问题求解过程中发挥着不可或缺的作用。接下来我们将分别介绍这些基本数据结构的特点及应用。
### 2.1 数组与链表
#### 数组(Array)
数组是一种线性表数据结构,它由一组连续的内存空间组成,并按照一定的规律排列元素。数组的特点包括:
- 支持随机访问:可以通过下标直接访问数组中的元素,时间复杂度为O(1)。
- 连续存储:数组中的元素在内存中是连续存储的,这也是支持随机访问的前提条件。
- 大小固定:数组在创建时需要指定大小,且大小通常是固定的。
在实际应用中,数组被广泛用于需要快速访问元素的场景,如排序算法、动态规划等。
```python
# Python示例:创建和访问数组
arr = [1, 2, 3, 4, 5]
print(arr[2]) # 输出:3
```
#### 链表(Linked List)
链表是一种非连续存储的数据结构,它由节点(node)构成,每个节点包含数据域和指针域。链表的特点包括:
- 插入与删除高效:在链表中插入和删除元素的时间复杂度为O(1)。
- 随机访问低效:链表不支持随机访问,需要从头节点逐个遍历到目标节点。
- 可动态扩展:链表的大小并不固定,可以根据需要动态增加节点。
链表常用于需要频繁插入和删除操作的场景,如LRU缓存淘汰算法、大整数运算等。
```java
// Java示例:创建和遍历链表
class Node {
int data;
Node next;
public Node(int data) {
this.data = data;
this.next = null;
}
}
Node head = new Node(1);
head.next = new Node(2);
head.next.next = new Node(3);
Node cur = head;
while (cur != null) {
System.out.println(cur.data);
cur = cur.next;
}
```
通过对数组与链表的介绍,我们深入了解了基本数据结构的特点及应用场景。在实际问题求解中,选择合适的数据结构可以提高算法效率,加快程序运行速度。
# 3. 常见算法介绍
在计算方法中,常见算法是非常重要的基础知识,能够帮助我们解决各种实际问题。下面将介绍一些常见的算法及其应用。
#### 3.1 排序算法
排序算法是计算机程序设计中的基本问题之一,它将一串数据按照特定的顺序进行排列。常见的排序算法包括冒泡排序、快速排序、归并排序、堆排序等。这些算法各有特点,适用于不同规模和特点的数据。
##### 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法,重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。代码示例(Python):
```python
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
sorted_arr = bubble_sort(arr)
print("冒泡排序结果:", sorted_arr)
```
**代码总结:** 冒泡排序通过相邻元素的比较和交换来进行排序,时间复杂度为O(n^2)。
**结果说明:** 上述代码对示例数组进行了冒泡排序,并输出排序结果。
##### 快速排序(Quick Sort)
快速排序使用分治法来把一个数组分成两个子数组,然后递归地对子数组进行排序。代码示例(Java):
```java
public class QuickSort {
public void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
int partition(int[] arr, int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
int temp = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp;
return i + 1;
}
// 测试
public static void main(String[] args) {
int[] arr = {64, 34, 25, 12, 22, 11, 90};
QuickSort qs = new QuickSort();
qs.quickSort(arr, 0, arr.length - 1);
System.out.println("快速排序结果:" + Arrays.toString(arr));
}
}
```
**代码总结:** 快速排序通过选择一个基准元素,将比基准元素小的放在左边,比基准元素大的放在右边,然后递归地对左右子数组进行排序,时间复杂度为O(nlogn)。
**结果说明:** 上述代码对示例数组进行了快速排序,并输出排序结果。
#### 3.2 查找算法
查找算法是指在一个数据集中查找特定元素的算法。常见的查找算法包括线性查找、二分查找等。
##### 线性查找(Linear Search)
线性查找是最简单的查找算法之一,它按顺序遍历数组,找到目标元素时返回其索引。代码示例(JavaScript):
```javascript
function linearSearch(arr, x) {
for (let i = 0; i < arr.length; i++) {
if (arr[i] === x) {
return i;
}
}
return -1;
}
// 测试
let arr = [64, 34, 25, 12, 22, 11, 90];
let index = linearSearch(arr, 22);
console.log("线性查找结果:元素 22 的索引为 " + index);
```
**代码总结:** 线性查找通过遍历数组来查找目标元素,时间复杂度为O(n)。
**结果说明:** 上述代码在示例数组中进行了线性查找,找到元素 22 的索引并进行了输出。
##### 二分查找(Binary Search)
二分查找要求在有序数组中查找目标元素,它通过比较中间元素和目标元素的大小,来决定下一步查找的区间。代码示例(Go):
```go
func binarySearch(arr []int, x int) int {
low := 0
high := len(arr) - 1
for low <= high {
mid := low + (high-low)/2
if arr[mid] == x {
return mid
} else if arr[mid] < x {
low = mid + 1
} else {
high = mid - 1
}
}
return -1
}
// 测试
arr := []int{11, 12, 22, 25, 34, 64, 90}
index := binarySearch(arr, 34)
fmt.Println("二分查找结果:元素 34 的索引为", index)
```
**代码总结:** 二分查找通过不断缩小查找区间来找到目标元素,时间复杂度为O(logn)。
**结果说明:** 上述代码在示例数组中进行了二分查找,找到元素 34 的索引并进行了输出。
通过以上介绍,我们了解了常见的排序算法和查找算法,它们在各种应用场景中发挥着重要作用。
希望这部分内容能给您带来一些帮助,接下来还有更多精彩的内容等着您。
# 4. 数值计算基础
数值计算是计算机科学中的重要分支,它主要关注如何利用计算机对数学问题进行数值求解。在本节中,我们将介绍数值计算的基础知识,包括浮点数表示与运算,误差分析与稳定性等内容。
#### 4.1 浮点数表示与运算
在计算机中,浮点数是一种用科学计数法表示的实数。常见的浮点数表示方式包括IEEE 754标准的单精度和双精度浮点数。在Python语言中,我们可以使用内置的`float`类型来表示浮点数,并进行常见的浮点数运算。
下面是一个简单的示例代码,演示了浮点数的表示与运算:
```python
# 浮点数表示与运算示例代码
# 定义两个浮点数
a = 0.1
b = 0.2
# 浮点数运算
c = a + b
d = a * b
# 打印结果
print("a + b =", c)
print("a * b =", d)
```
代码总结:以上代码演示了使用Python进行浮点数的表示与基本运算,包括加法和乘法。由于浮点数在计算机中以二进制形式表示,因此可能存在精度损失的问题。
结果说明:在打印结果时,可能会发现0.1 + 0.2的结果并不精确等于0.3,这是由于浮点数表示的精度限制所导致的。
#### 4.2 误差分析与稳定性
在数值计算中,误差分析是至关重要的。我们需要了解舍入误差、截断误差等各种误差来源,以便评估数值计算的准确性。同时,算法的稳定性也是需要考虑的因素,一个稳定的数值计算算法能够在输入数据发生小幅变化时依然保持良好的性能。
在Python中,可以通过一些库函数或者自定义函数来进行误差分析与稳定性的实践。例如,可以使用`numpy`库进行数值计算,进而分析某个算法的稳定性。
以上是数值计算基础的简要介绍,下面我们将进入下一节内容。
# 5. 迭代求解与数值逼近
在数值计算中,经常需要通过迭代求解来逼近复杂的数学问题,以下是两种常见的迭代求解方法:
#### 5.1 牛顿迭代法
牛顿迭代法是一种用于逼近方程根的迭代方法,通过不断用切线来逼近函数的根。其迭代公式如下所示:
```python
def newton_iteration_method(f, df, x0, tol, max_iter):
"""
牛顿迭代法求解方程根
:param f: 目标函数
:param df: 目标函数的导数
:param x0: 初值
:param tol: 容差
:param max_iter: 最大迭代次数
:return: 迭代逼近的根
"""
x = x0
for i in range(max_iter):
x_next = x - f(x) / df(x)
if abs(x_next - x) < tol:
return x_next
x = x_next
return x
```
**代码说明:**
- `f` 为目标函数,`df`为目标函数的导数
- `x0` 为初始值
- `tol` 为容差,控制迭代精度
- `max_iter` 为最大迭代次数,防止无限循环
#### 5.2 插值与拟合
在实际应用中,经常需要通过已知数据点来逼近函数的形式,常用的方法包括线性插值、多项式插值、最小二乘拟合等。
```python
import numpy as np
from scipy.interpolate import interp1d
import matplotlib.pyplot as plt
# 生成数据点
x = np.array([1, 2, 3, 4, 5])
y = np.array([4, 2, 1, 3, 7])
# 线性插值
linear_interp = interp1d(x, y, kind='linear')
x_new = np.linspace(1, 5, 100)
y_new = linear_interp(x_new)
# 绘制结果
plt.scatter(x, y, label='Data Points', color='r')
plt.plot(x_new, y_new, label='Linear Interpolation')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
```
**代码说明:**
- 使用 `numpy` 生成数据点 `x` 和 `y`
- 利用 `scipy` 中的插值函数 `interp1d` 进行线性插值
- 最后利用 `matplotlib` 绘制插值结果图表
以上是关于迭代求解与数值逼近的介绍,希望能够帮助您更深入地了解数值计算的基础知识。
# 6. 线性代数基础
线性代数在计算方法中扮演着至关重要的角色,涉及到诸多计算问题的解决。本章将介绍线性代数的基础知识,包括线性方程组的求解、特征值与特征向量的计算等内容。
### 6.1 线性方程组求解
线性方程组是线性代数中的基础问题,通常可以表示为矩阵乘以向量的形式。以下是一个简单的线性方程组求解的示例代码(使用Python语言):
```python
import numpy as np
# 定义系数矩阵A和常数向量b
A = np.array([[2, 1], [1, 1]])
b = np.array([3, 2])
# 使用numpy的线性代数模块求解线性方程组
x = np.linalg.solve(A, b)
print("线性方程组的解为:", x)
```
**代码总结:**
- 通过numpy库中的linalg.solve()函数可以方便地求解线性方程组。
- 数学上,线性方程组的解即为使得方程组成立的未知数取值。
**结果说明:**
在上述示例中,线性方程组的解为 x=[1, 1],即方程组2x1 + x2 = 3和x1 + x2 = 2的交点坐标为(1, 1)。
### 6.2 特征值与特征向量
求解特征值与特征向量是线性代数中的重要问题,它们在很多领域有着广泛的应用。下面是一个求解特征值与特征向量的示例代码(同样使用Python语言):
```python
import numpy as np
# 定义一个矩阵
A = np.array([[3, 1], [1, 3]])
# 求解特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
print("特征值为:", eigenvalues)
print("特征向量为:", eigenvectors)
```
**代码总结:**
- 使用numpy库中的linalg.eig()函数可以求解矩阵的特征值和特征向量。
- 特征值表示矩阵在特征向量方向上的缩放比例。
**结果说明:**
在给定矩阵A的情况下,求得的特征值为[4, 2],对应的特征向量分别为[1, 1]和[-1, 1]。
通过以上介绍,读者可以对线性代数基础有一个初步了解,随着深入学习与实践,将能更好地应用线性代数知识解决实际计算问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
【电能表软件更新完全手册】:系统最新状态的保持方法

# 摘要
电能表软件更新是确保电能计量准确性和系统稳定性的重要环节。本文首先概述了电能表软件更新的理论基础,分析了电能表的工作原理、软件架构以及更新的影响因素。接着,详细阐述了更新实践步骤,包括准备工作、实施过程和更新后的验证测试。文章进一步探讨了软件更新的高级应用,如自动化策略、版
全球视角下的IT服务管理:ISO20000-1:2018认证的真正益处
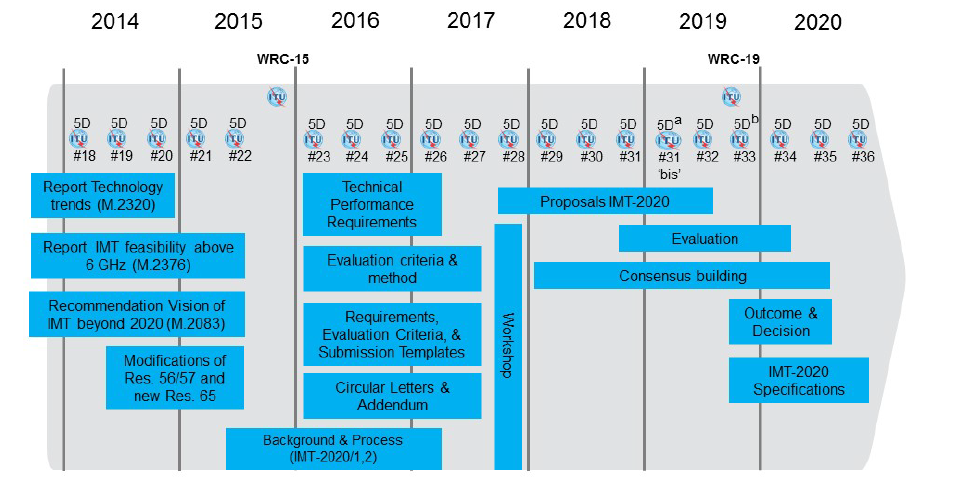
# 摘要
本文综述了IT服务管理的最新发展,特别是针对ISO/IEC 20000-1:2018标准的介绍和分析。文章首先概述了IT服务管理的基础知识,接着深入探讨了该标准的历史背景、核心内容以及与旧版标准的差异,并评估了这些变化对企业的影响。进一步,文章分析了获得该认证为企业带来的内部及外部益处,包括服务质量和客户满意度的提升,以及市场竞争力的增强。随后,
Edge与Office无缝集成:打造高效生产力环境
# 摘要
随着数字化转型的加速,企业对于办公生产力工具的要求不断提高。本文深入探讨了微软Edge浏览器与Office套件集成的概念、技术原理及实践应用。分析了微软生态系统下的技术架构,包括云服务、API集成以
开源HRM软件:选择与实施的最佳实践指南(稀缺性:唯一全面指南)

# 摘要
本文针对开源人力资源管理系统(HRM)软件的市场概况、选择、实施、配置及维护进行了全面分析。首先,概述了开源HRM软件的市场状况及其优势,接着详细讨论了如何根据企业需求选择合适软件、评估社区支持和技术实力、探索定制和扩展能力。然后,本文提出了一个详尽的实施计划,并强调
性能优化秘籍:提升Quectel L76K信号强度与网络质量的关键

# 摘要
本文首先介绍了Quectel L76K模块的基础知识及其性能影响因素。接着,在理论基础上阐述了无线通信信号的传播原理和网络质量评价指标,进一步解读了L76K模块的性能参数与网络质量的关联。随后,文章着重分析了信号增强技术和网络质量的深度调优实践,包括降低延迟、提升吞吐量和增强网络可靠性的策略。最后,通过案例研究探讨了L76K模块在不同实际应用场景中
【SPC在注塑成型中的终极应用】:揭开质量控制的神秘面纱
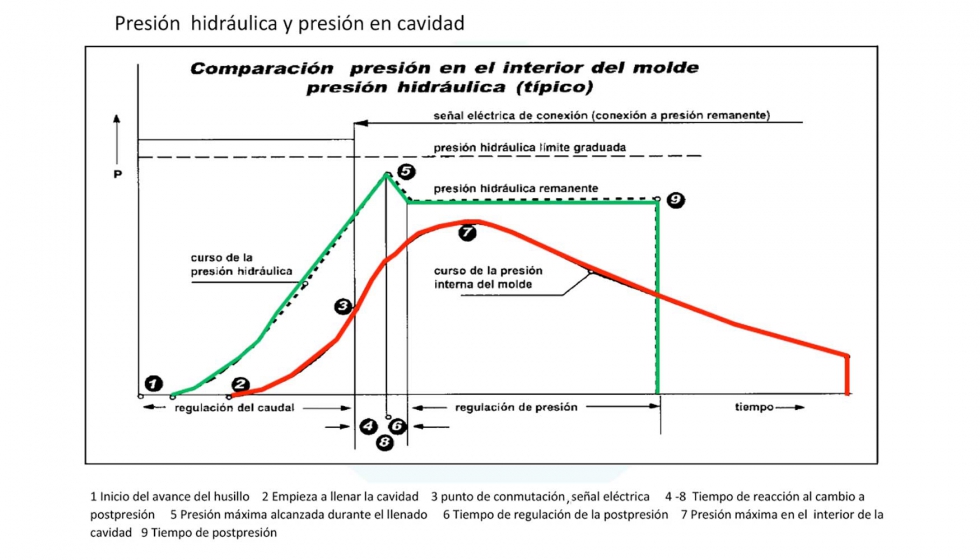
# 摘要
统计过程控制(SPC)是确保注塑成型产品质量和过程稳定性的关键方法。本文首先介绍了SPC的基础概念及其与质量控制的紧密联系,随后探讨了SPC在注塑成型中的实践应用,包括质量监控、设备整合和质量改进案例。文章进一步分析了SPC技术的高级应用,挑战与解决方案,并展望了其在智能制造和工业4.0环境下的未来趋势。通过对多个行业案例的研究,本文总结了SPC成功实施的关键因素,并提供了基于经验教训的优化策略。本文的研究强调了SPC在
YXL480高级规格解析:性能优化与故障排除的7大技巧

# 摘要
YXL480作为一款先进的设备,在本文中对其高级规格进行了全面的概览。本文深入探讨了YXL480的性能特性,包括其核心架构、处理能力、内存和存储性能以及能效比。通过量化分析和优化策略的介绍,本文揭示了YXL480如何实现高效能。此外,文章还详细介绍了YXL480故障诊断与排除的技巧,从理论基础到实践应用,并探讨了性能优化的方法论,提供了硬件与软
西门子PLC与HMI集成指南:数据通信与交互的高效策略

# 摘要
本文详细介绍了西门子PLC与HMI集成的关键技术和应用实践。首先概述了西门子PLC的基础知识和通信协议,探讨了其工作原理、硬件架构、软件逻辑和通信技术。接着,文章转向HMI的基础知识与界面设计,重点讨论了人机交互原理和界面设计的关键要素。在数据通信实践操
【视觉SLAM入门必备】:MonoSLAM与其他SLAM方法的比较分析

# 摘要
视觉SLAM(Simultaneous Localization and Mapping)技术是机器人和增强现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )