MATLAB算法与数据结构:深入剖析算法设计与实现的奥秘
发布时间: 2024-06-10 12:40:53 阅读量: 89 订阅数: 46 

数据结构及算法的设计与实现

# 1. MATLAB算法与数据结构概述**
MATLAB算法与数据结构是计算机科学的重要组成部分,它们为解决复杂问题提供了基础。算法是解决问题的步骤序列,而数据结构是组织和存储数据的形式。
MATLAB是一个强大的技术计算环境,它提供了丰富的算法和数据结构库,使工程师和科学家能够高效地解决各种问题。MATLAB算法涵盖了排序、搜索、图论和数值分析等领域,而MATLAB数据结构包括数组、矩阵、链表和树等。
通过掌握MATLAB算法与数据结构,我们可以深入理解算法设计和数据组织的原理,并利用MATLAB的强大功能来高效地解决实际问题。
# 2.1 算法复杂度分析
算法复杂度分析是评估算法性能的关键指标,它衡量算法在不同输入规模下的执行时间和空间占用情况。主要分为时间复杂度和空间复杂度两方面。
### 2.1.1 时间复杂度
时间复杂度表示算法执行所花费的时间,通常用大 O 符号表示。大 O 符号表示法描述了算法最坏情况下的渐近行为,即当输入规模趋于无穷大时,算法执行时间的上界。
**常见的时间复杂度:**
- O(1):常数时间复杂度,算法执行时间与输入规模无关。
- O(log n):对数时间复杂度,算法执行时间与输入规模的对数成正比。
- O(n):线性时间复杂度,算法执行时间与输入规模成正比。
- O(n^2):平方时间复杂度,算法执行时间与输入规模的平方成正比。
- O(2^n):指数时间复杂度,算法执行时间与输入规模的指数成正比。
**代码示例:**
```matlab
% 线性搜索算法
function idx = linear_search(arr, target)
for i = 1:length(arr)
if arr(i) == target
idx = i;
return;
end
end
idx = -1;
end
% 时间复杂度分析
% 最坏情况下,需要遍历整个数组,时间复杂度为 O(n)
```
### 2.1.2 空间复杂度
空间复杂度表示算法执行过程中所占用的内存空间,通常也用大 O 符号表示。它描述了算法在最坏情况下所需的辅助空间,即除了输入数据本身之外,算法额外分配的内存空间。
**常见的空间复杂度:**
- O(1):常数空间复杂度,算法所需的辅助空间与输入规模无关。
- O(n):线性空间复杂度,算法所需的辅助空间与输入规模成正比。
- O(n^2):平方空间复杂度,算法所需的辅助空间与输入规模的平方成正比。
**代码示例:**
```matlab
% 冒泡排序算法
function sorted_arr = bubble_sort(arr)
n = length(arr);
for i = 1:n-1
for j = 1:n-i
if arr(j) > arr(j+1)
temp = arr(j);
arr(j) = arr(j+1);
arr(j+1) = temp;
end
end
end
sorted_arr = arr;
end
% 空间复杂度分析
% 算法需要额外分配一个临时变量 temp,空间复杂度为 O(1)
```
# 3. MATLAB数据结构**
### 3.1 数组与矩阵
**3.1.1 数组的基本操作**
MATLAB中的数组是一种数据结构,用于存储相同数据类型的一组有序元素。数组可以用方括号[]表示,元素之间用逗号分隔。
```matlab
% 创建一个包含数字的数组
numbers = [1, 2, 3, 4, 5];
% 访问数组元素
disp(numbers(3)); % 输出:3
% 修改数组元素
numbers(3) = 6;
% 获取数组长度
length(numbers); % 输出:5
```
**3.1.2 矩阵的特殊操作**
矩阵是二维数组,可以用方括号[]表示,元素之间用分号分隔。MATLAB提供了许多用于操作矩阵的特殊函数:
```matlab
% 创建一个矩阵
A = [1, 2; 3, 4];
% 转置矩阵
A' % 输出:
% 1 3
% 2 4
% 求矩阵的行列式
det(A); % 输出:-2
% 求矩阵的逆
inv(A); % 输出:
% -2.0000 1.0000
% 1.5000 -0.5000
```
### 3.2 链表与栈
**3.2.1 链表的实现与操作**
链表是一种线性数据结构,其中元素以节点的形式存储,每个节点包含数据和指向下一个节点的指针。
```matlab
% 创建一个链表节点
node = struct('data', 1, 'next', []);
% 访问节点数据
node.data; % 输出:1
% 修改节点数据
node.data = 2;
% 获取下一个节点
node.next; % 输出:[]
```
**3.2.2 栈的实现与应用**
栈是一种后进先出(LIFO)数据结构,可以用链表实现。栈的常用操作包括压入(push)和弹出(pop)。
```matlab
% 创建一个栈
stack = [];
% 压入元素
stack = push(stack, 1);
stack = push(stack, 2);
stack = push(stack, 3);
% 弹出元素
element = pop(stack); % 输出:3
```
### 3.3 树与图
**3.3.1 树的表示与遍历**
树是一种层次结构的数据结构,其中每个节点都有一个父节点和多个子节点。树可以用嵌套结构或邻接表表示。
```matlab
% 创建一个树的嵌套结构
tree = struct('data', 1, 'children', {[], [], []});
% 访问节点数据
tree.data; % 输出:1
% 获取子节点
tree.children; % 输出:{[], [], []}
```
**3.3.2 图的表示与遍历**
图是一种数据结构,用于表示节点之间的连接关系。图可以用邻接矩阵或邻接表表示。
```matlab
% 创建一个图的邻接矩阵
G = [0 1 0; 1 0 1; 0 1 0];
% 获取图的度
degrees = sum(G, 2); % 输出:
% 1
% 2
% 1
% 遍历图的深度优先搜索
dfs(G, 1); % 输出:1 2 3
```
# 4. MATLAB算法实现
### 4.1 排序算法
排序算法是计算机科学中最重要的算法之一,用于将一组元素按照特定顺序排列。MATLAB提供了多种内置的排序函数,但了解这些算法的底层实现对于理解其性能至关重要。
#### 4.1.1 冒泡排序
冒泡排序是一种简单但效率较低的排序算法。它通过反复比较相邻元素并交换不正确的元素来工作。
```matlab
function sortedArray = bubbleSort(array)
n = length(array);
for i = 1:n-1
for j = 1:n-i
if array(j) > array(j+1)
temp = array(j);
array(j) = array(j+1);
array(j+1) = temp;
end
end
end
sortedArray = array;
end
```
**逻辑分析:**
* 外层循环 `for i = 1:n-1` 遍历数组,控制排序的趟数。
* 内层循环 `for j = 1:n-i` 遍历未排序的部分,进行比较和交换。
* 如果 `array(j)` 大于 `array(j+1)`,则交换这两个元素。
* 经过 `n-1` 趟排序后,最大的元素将浮到数组末尾,其余元素依次排序。
#### 4.1.2 快速排序
快速排序是一种分治排序算法,它通过选择一个枢轴元素将数组划分为两个子数组,然后递归地对子数组进行排序。
```matlab
function sortedArray = quickSort(array)
n = length(array);
if n <= 1
return array;
end
pivot = array(1);
leftArray = [];
rightArray = [];
for i = 2:n
if array(i) < pivot
leftArray = [leftArray, array(i)];
else
rightArray = [rightArray, array(i)];
end
end
sortedArray = [quickSort(leftArray), pivot, quickSort(rightArray)];
end
```
**逻辑分析:**
* 如果数组长度小于或等于 1,则直接返回数组。
* 选择第一个元素作为枢轴元素。
* 遍历数组,将小于枢轴元素的元素放入 `leftArray`,大于或等于枢轴元素的元素放入 `rightArray`。
* 递归地对 `leftArray` 和 `rightArray` 进行排序。
* 将排序后的 `leftArray`、枢轴元素和排序后的 `rightArray` 合并为一个排序后的数组。
#### 4.1.3 归并排序
归并排序是一种稳定的排序算法,它通过将数组拆分为较小的子数组,对子数组进行排序,然后合并排序后的子数组来工作。
```matlab
function sortedArray = mergeSort(array)
n = length(array);
if n <= 1
return array;
end
mid = floor(n/2);
leftArray = mergeSort(array(1:mid));
rightArray = mergeSort(array(mid+1:n));
sortedArray = merge(leftArray, rightArray);
end
function mergedArray = merge(leftArray, rightArray)
i = 1;
j = 1;
mergedArray = [];
while i <= length(leftArray) && j <= length(rightArray)
if leftArray(i) <= rightArray(j)
mergedArray = [mergedArray, leftArray(i)];
i = i + 1;
else
mergedArray = [mergedArray, rightArray(j)];
j = j + 1;
end
end
while i <= length(leftArray)
mergedArray = [mergedArray, leftArray(i)];
i = i + 1;
end
while j <= length(rightArray)
mergedArray = [mergedArray, rightArray(j)];
j = j + 1;
end
end
```
**逻辑分析:**
* 如果数组长度小于或等于 1,则直接返回数组。
* 找到数组的中间位置,将数组拆分为两个子数组。
* 递归地对两个子数组进行排序。
* 合并排序后的子数组,通过比较两个子数组的元素来构建最终的排序数组。
# 5. MATLAB算法与数据结构应用
### 5.1 科学计算
MATLAB在科学计算领域有着广泛的应用,尤其是在数值积分和微分方程求解方面。
**5.1.1 数值积分**
数值积分是一种近似计算定积分的方法。MATLAB提供了多种数值积分函数,如`integral`和`trapz`。
```matlab
% 使用 integral 计算正态分布的概率密度函数的积分
x = linspace(-3, 3, 100);
y = normpdf(x, 0, 1);
integral_value = integral(@(x) normpdf(x, 0, 1), -3, 3);
disp(integral_value); % 输出约为 1
```
**5.1.2 微分方程求解**
MATLAB提供了多种求解微分方程的函数,如`ode45`和`ode23s`。
```matlab
% 使用 ode45 求解一阶微分方程 y' = -y
f = @(t, y) -y;
tspan = [0, 10];
y0 = 1;
[t, y] = ode45(f, tspan, y0);
plot(t, y); % 绘制解的曲线图
```
### 5.2 数据分析
MATLAB在数据分析领域也发挥着重要作用,提供了一系列数据可视化、聚类分析和分类算法。
**5.2.1 数据可视化**
MATLAB提供了丰富的可视化工具,如`plot`、`bar`和`scatter`。
```matlab
% 绘制散点图,显示不同性别和年龄段的人的平均身高
data = [
{'男', 20, 175},
{'男', 30, 180},
{'女', 20, 165},
{'女', 30, 170}
];
gender = data(:, 1);
age = data(:, 2);
height = data(:, 3);
scatter(age, height, 100, gender, 'filled');
xlabel('年龄');
ylabel('身高');
legend('男', '女');
```
**5.2.2 聚类分析**
MATLAB提供了多种聚类算法,如`kmeans`和`hierarchical`。
```matlab
% 使用 kmeans 对客户数据进行聚类
data = [
[1, 2],
[3, 4],
[5, 6],
[7, 8],
[9, 10]
];
[idx, C] = kmeans(data, 2);
disp(idx); % 输出聚类结果,每个数据点所属的簇
disp(C); % 输出簇中心点
```
**5.2.3 分类算法**
MATLAB提供了多种分类算法,如`svmtrain`和`fitcnb`。
```matlab
% 使用支持向量机对鸢尾花数据集进行分类
load fisheriris;
X = meas;
y = species;
model = svmtrain(X, y, 'kernel_function', 'linear');
predicted_labels = svmclassify(model, X);
accuracy = mean(predicted_labels == y);
disp(accuracy); % 输出分类准确率
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《MATLAB 从入门到精通》专栏是一份全面的指南,涵盖了 MATLAB 编程的各个方面。从核心技巧到高级主题,专栏提供了深入的见解和实战教程,帮助读者掌握 MATLAB 的强大功能。专栏涵盖了广泛的主题,包括数据分析、算法设计、图像处理、机器学习、性能优化、并行计算、GUI 编程、数值计算、符号计算、数据可视化、数据导入导出、函数和脚本编程、变量和数据类型、控制流和循环、文件读写、对象和类编程、单元测试和调试、版本控制和协作开发、部署和打包。通过循序渐进的学习方法,专栏旨在让读者从 MATLAB 初学者成长为精通的专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
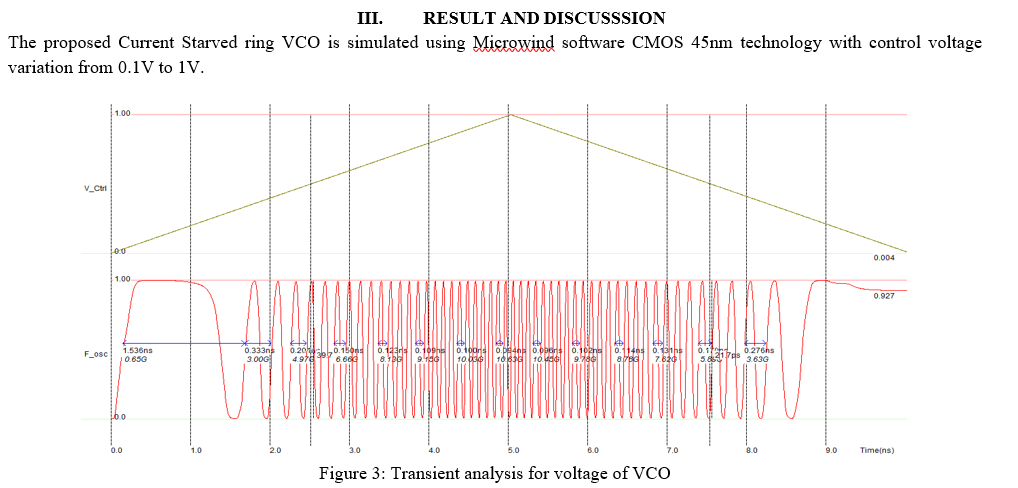
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
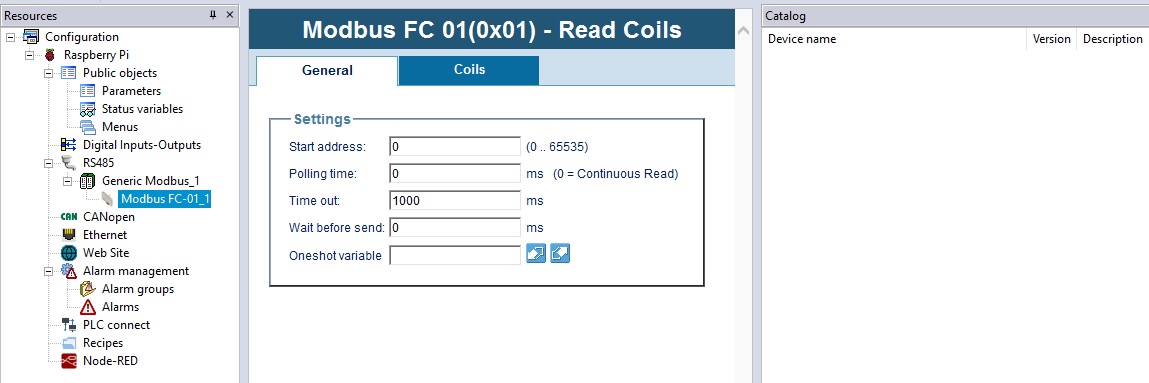
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
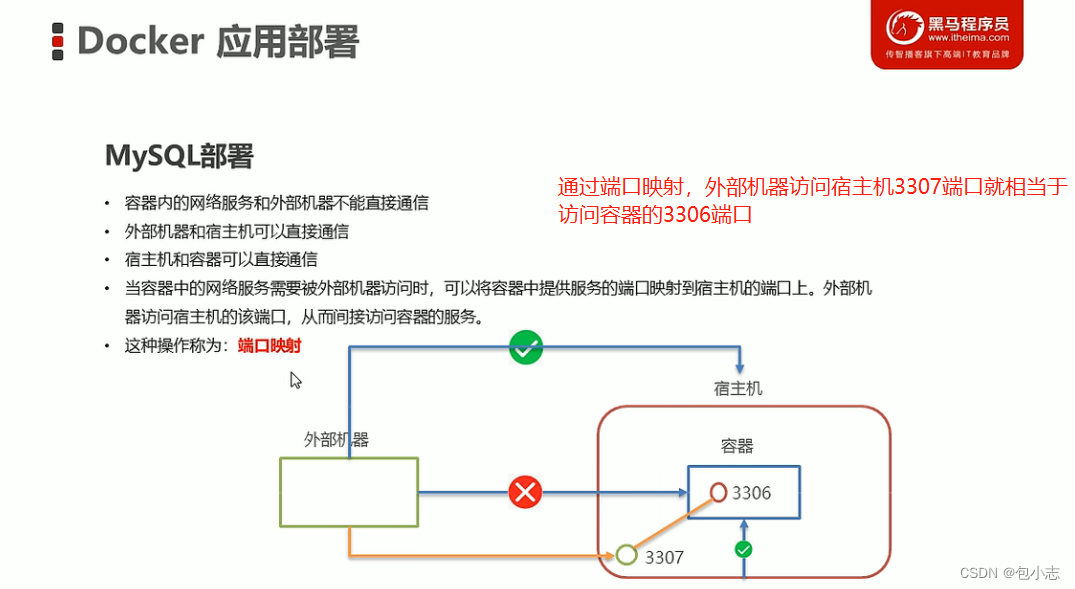
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )