【JSON_XML 数据处理秘籍】:DAHUA HTTP API 高级技巧解析
发布时间: 2024-12-16 20:44:12 阅读量: 4 订阅数: 3 

参考资源链接:[大华官方2018-11版HTTP接口协议CGI规范与安全建议](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483d5?spm=1055.2635.3001.10343)
# 1. JSON与XML数据格式概述
数据在现代信息技术领域中占有举足轻重的地位,而数据格式的选择直接影响着数据交换的效率和可靠性。JSON(JavaScript Object Notation)和XML(Extensible Markup Language)是目前最流行的两种轻量级数据交换格式,广泛应用于网络数据传输和存储。JSON以其轻便简洁,易于阅读和编写而备受欢迎,特别是与现代Web应用开发紧密相关。XML则以其强大的扩展性和灵活性被广泛用于复杂的数据交换场景,如企业级应用集成。本章节将介绍这两种数据格式的基本概念,以及它们在不同场景下的应用特点,为后续章节深入探讨JSON/XML数据处理奠定基础。
# 2. JSON/XML数据处理基础
## 2.1 JSON/XML数据结构解析
### 2.1.1 JSON数据的键值对和数组
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,并且是语言无关的,具有自我描述性以及易于阅读。JSON结构由键值对(key-value pairs)组成,这是JSON对象的核心构建块。每个键值对通常由一个字符串(key),后面跟着冒号,然后是值(value),值可以是字符串、数字、数组、布尔值、null或者其他JSON对象。
JSON中的数组是由一系列值(values)组成的有序列表,每个值可以是不同的数据类型。数组以方括号表示,值之间以逗号分隔。
例如,以下是一个包含数组的JSON对象示例:
```json
{
"company": "TechCorp",
"employees": [
{"name": "Alice", "age": 30},
{"name": "Bob", "age": 28},
{"name": "Charlie", "age": 35}
]
}
```
在这个例子中,`employees` 键关联一个数组,数组中包含三个对象,每个对象代表一个员工的简单信息。
### 2.1.2 XML的标签、属性和层级结构
XML(Extensible Markup Language)是一种标记语言,它定义了一套规则用于创建文档,使得这些文档可以由计算机读取,并且易于人类阅读。XML使用标签(tags)来定义元素,这些元素可以包含属性(attributes),并且能够表示层级结构。
- 标签:在XML中,元素由开始标签(start tag)和结束标签(end tag)界定,例如 `<element>...</element>`。标签可以包含文本内容和嵌套的元素。
- 属性:属性提供了关于XML元素的额外信息。它们总是在元素的开始标签内声明,并且以键值对的形式出现,如 `<element attribute="value">`。
XML文档的结构通常是层级化的,这意味着每个元素可以有子元素,而子元素又可以有自己的子元素,创建了一个树状结构。每个XML文档都有一个根元素,这是所有其他元素的容器。
例如,以下是一个简单的XML文档:
```xml
<company>
<name>TechCorp</name>
<employees>
<employee name="Alice" age="30"/>
<employee name="Bob" age="28"/>
<employee name="Charlie" age="35"/>
</employees>
</company>
```
在这个例子中,`company` 是根元素,它包含了两个子元素 `name` 和 `employees`。`employees` 元素又包含了三个 `employee` 子元素,每个子元素都有 `name` 和 `age` 属性。
## 2.2 数据解析工具与库的选择
### 2.2.1 常用的JSON解析库
为了在不同编程语言中处理JSON数据,开发者通常会依赖于各种库。以下是几种流行语言的JSON解析库:
- **Python**: `json`模块是Python的标准库之一,提供了简单的API来编码和解码JSON数据。
```python
import json
# JSON编码
data = {"name": "John", "age": 30}
json_data = json.dumps(data)
# JSON解码
data = json.loads(json_data)
```
- **Java**: `org.json`库和Google的`Gson`库是处理JSON数据的两个常见选择。
```java
import org.json.JSONObject;
import com.google.gson.Gson;
// 使用org.json
JSONObject obj = new JSONObject();
obj.put("name", "John");
obj.put("age", 30);
// 使用Gson
Gson gson = new Gson();
String json = gson.toJson(obj);
```
- **JavaScript**: 由于JSON是JavaScript的一部分,因此在JavaScript中可以直接使用JSON对象进行数据编码和解码。
```javascript
// JSON编码
var data = {name: "John", age: 30};
var jsonData = JSON.stringify(data);
// JSON解码
data = JSON.parse(jsonData);
```
### 2.2.2 常用的XML解析库
处理XML数据时,同样需要借助外部库来简化操作流程。下面是几种在不同编程语言中常见的XML解析库:
- **Python**: `xml.etree.ElementTree`模块提供了对XML文档的树形结构支持。
```python
import xml.etree.ElementTree as ET
tree = ET.parse('data.xml')
root = tree.getroot()
for child in root:
print(child.tag, child.attrib)
```
- **Java**: `javax.xml.parsers`包下提供了多种解析XML的工具,例如DOM解析器和SAX解析器。
```java
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse("data.xml");
// 获取根元素
Element root = doc.getDocumentElement();
```
- **JavaScript**: `DOMParser` API可以解析XML字符串或文档。
```javascript
var parser = new DOMParser();
var doc = parser.parseFromString('<data><item key="value">Content</item></data>', "application/xml");
var items = doc.getElementsByTagName("item");
for (var i = 0; i < items.length; i++) {
console.log(items[i].getAttribute("key") + ": " + items[i].childNodes[0].nodeValue);
}
```
## 2.3 编程语言中的数据处理
### 2.3.1 在Python中处理JSON/XML
Python 提供了非常直接的方式来处理JSON和XML数据。以下是一些常见的用法:
- JSON数据处理:
```python
import json
# JSON字符串转字典
json_str = '{"name": "John", "age": 30}'
json_dict = json.loads(json_str)
# 字典转JSON字符串
json_str = json.dumps(json_dict)
```
- XML数据处理:
```python
import xml.etree.ElementTree as ET
# 解析XML
tree = ET.parse('data.xml')
root = tree.getroot()
# 构建XML
root = ET.Element("root")
child = ET.SubElement(root, "child", attrib={"key": "value"})
child.text = "Content"
tree = ET.ElementTree(root)
tree.write('output.xml')
```
### 2.3.2 在Java中处理JSON/XML
Java中处理JSON和XML数据涉及到了解和使用相应的API,下面是一个简单的例子:
- JSON数据处理:
```java
import org.json.JSONObject;
import com.google.gson.Gson;
// 使用org.json创建JSON对象
JSONObject obj = new JSONObject();
obj.put("name", "John");
obj.put("age", 30);
// 使用Gson库进行序列化
Gson gson = new Gson();
String jsonOutput = gson.toJson(obj);
```
- XML数据处理:
```java
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
// 解析XML
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse("data.xml");
```
在接下来的章节中,我们将更深入地探讨JSON/XML数据处理的高级技巧以及在不同应用场景中的实际应用案例。通过这些深入的讨论和实践,读者将能够更好地理解和掌握JSON/XML数据的处理和应用。
# 3. DAHUA HTTP API接口简介
## 3.1 DAHUA HTTP API接口概念
### 3.1.1 API接口的功能和用途
DAHUA作为一家全球知名的视频监控设备制造商,其设备广泛应用于各类安全监控系统中。为了实现与第三方系统的集成以及提供更为丰富的功能扩展,DAHUA提供了HTTP API接口供开发者使用。API(Application Programming Interface,应用程序编程接口)是一系列预定义的函数、协议和工具,用于构建软件和应用程序。
DAHUA的HTTP API接口允许用户远程访问和控制其设备,例如获取实时视频流、配置设备参数、检索录像文件、管理用户权限等。通过这些接口,开发者可以在自己的应用中集成DAHUA设备的功能,从而实现定制化的解决方案,如安全监控、远程控制、智能分析等功能。
### 3.1.2 API接口的认证机制
为了确保安全性,DAHUA的HTTP API接口采用了基于HTTP的认证机制。在发起请求前,用户必须通过认证过程,通常是通过提供用户名和密码。在某些情况下,可能还需要提供一个API密钥(API Key)或者生成的令牌(Token)以验证请求的合法性。
DAHUA HTTP API的认证机制通常要求开发者在发送请求时,将认证信息放入HTTP请求头(Headers)中,例如使用`Authorization`字段。为了增强安全性,许多DAHUA设备还支持SSL/TLS加密,确保在传输过程中的数据安全,防止敏感信息泄露。
```mermaid
flowchart LR
A[开始认证] -->|提交用户名和密码| B{验证成功?}
B -->|是| C[生成Token]
B -->|否| D[拒绝访问]
C -->|将Token放入请求头| E[发送请求]
```
## 3.2 API请求的构建与发送
### 3.2.1 构建RESTful请求
构建DAHUA HTTP API的RESTful请求遵循通用的HTTP请求结构。开发者需要确定请求的类型(如GET、POST、PUT、DELETE等)、API的端点(Endpoint)、所需携带的参数(Query Strings或Body)以及认证信息。
以获取设备列表的请求为例,可以构造一个GET请求:
```http
GET /api/device/list HTTP/1.1
Host: dahua.example.com
Authorization: Basic [Base64EncodedUsernamePassword]
```
其中`/api/device/list`是请求的端点,表明请求的目标是获取设备列表。`Host`是目标服务器的域名。`Authorization`包含了经过Base64编码的用户名和密码。
### 3.2.2 处理API响应数据
DAHUA HTTP API接口的响应通常采用JSON或XML格式,包含操作的结果信息以及可能的数据内容。响应格式通常包括HTTP状态码、响应头以及响应体。状态码会表明请求的处理结果,例如200表示成功,401表示认证失败,403表示无权限访问等。
处理响应数据时,开发者需要根据响应体的内容进行解析和操作。以获取设备列表的响应为例,可能的JSON响应体如下:
```json
{
"status": "success",
"data": [
{ "id": "1", "name": "Front Door Camera" },
{ "id": "2", "name": "Back Door Camera" }
]
}
```
解析这个JSON响应时,开发者可以使用上一章节提到的JSON解析库,如Python的`json`库或Java的`org.json`包。
## 3.3 错误处理与日志记录
### 3.3.1 常见的API错误代码
在使用DAHUA HTTP API时,可能遇到各种错误。这些错误通过HTTP状态码反映给请求方。常见的错误代码包括:
- `400 Bad Request`:请求无效或格式错误。
- `401 Unauthorized`:认证失败,需提供正确的认证信息。
- `403 Forbidden`:请求被拒绝,没有足够的权限访问资源。
- `404 Not Found`:请求的资源不存在。
- `500 Internal Server Error`:服务器内部错误。
开发者需要对这些错误进行处理和响应。例如,可以通过重试机制、错误提示信息、用户通知等方式来应对。
### 3.3.2 实现日志记录的最佳实践
日志记录是任何应用程序中不可或缺的一部分,特别是在集成第三方API时。为了确保系统的稳定运行和问题的快速定位,开发者应该实现日志记录的最佳实践。这包括:
- 记录API请求和响应的详细信息。
- 记录API调用过程中的错误和异常。
- 使用结构化的日志格式,以便于检索和分析。
- 根据日志的重要性设置不同的日志级别,如DEBUG、INFO、WARN、ERROR。
在Python中,可以使用`logging`模块来实现日志记录:
```python
import logging
# 设置日志格式和级别
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
# 记录一条消息
logging.debug('This is a debug message')
```
通过日志记录,开发者不仅可以追踪系统的运行状态,还可以在出现问题时快速定位和解决问题,保证API接口的稳定使用。
在本章节中,我们详细介绍了DAHUA HTTP API接口的概念、认证机制、构建和发送请求的步骤,以及如何处理API的错误响应和实现日志记录的最佳实践。这些内容为开发者提供了集成和使用DAHUA设备的API接口所需的基础知识和技术细节,帮助他们更加高效地开发出稳定可靠的监控系统解决方案。
# 4. 高级JSON/XML处理技巧
## 数据转换与验证
### JSON/XML模式验证
JSON/XML数据在交换之前常常需要进行模式验证,确保数据的结构和类型符合预定的规范。例如,在接收第三方数据时,模式验证可以防止不合规范的数据进入系统,保证数据的完整性和安全性。在JSON中,常用的模式验证工具是JSON Schema。通过定义一个JSON Schema,可以对JSON数据进行结构和内容的验证。
下面是一个使用Python实现JSON模式验证的例子:
```python
import jsonschema
# 定义一个JSON Schema
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "integer"},
},
"required": ["name", "age"]
}
# 待验证的JSON数据
data = {
"name": "John Doe",
"age": 30
}
# 进行验证,如果不符合模式,则会抛出异常
try:
jsonschema.validate(instance=data, schema=schema)
print("The data is valid.")
except jsonschema.exceptions.ValidationError as e:
print("Validation error:", e.message)
```
在XML世界中,模式验证通常使用XML Schema Definition (XSD)。XSD定义了XML文档的结构、元素类型和属性等。可以使用像lxml这样的库来对XML数据进行XSD验证。
### 使用XSLT转换XML格式
XSLT(Extensible Stylesheet Language Transformations)是一种用于转换XML文档的语言。XSLT可以将XML文档转换成HTML、PDF、JSON或其他XML文档格式。这在需要将数据从一种格式转换到另一种格式时非常有用,尤其是在数据交换过程中。
下面是一个使用Python中的lxml库执行XSLT转换的例子:
```python
from lxml import etree
# XML输入
xml_input = """
<books>
<book>
<title>Learning XML</title>
<author>Erik T. Ray</author>
</book>
</books>
# XSLT样式表
xslt样式表 = """
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<head><title>Book List</title></head>
<body>
<h1>Book List</h1>
<xsl:for-each select="books/book">
<p>
<strong>Title:</strong>
<xsl:value-of select="title"/>
</p>
<p>
<strong>Author:</strong>
<xsl:value-of select="author"/>
</p>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
# 解析XML
xml_tree = etree.fromstring(xml_input)
# 解析XSLT样式表
xslt_tree = etree.fromstring(xslt样式表)
# 执行XSLT转换
transform = etree.XSLT(xslt_tree)
result = transform(xml_tree)
# 输出结果
print(etree.tostring(result, pretty_print=True).decode('utf-8'))
```
以上代码将XML数据转换为HTML格式,实现了从一种数据格式到另一种数据格式的转换。通过XSLT,开发者可以灵活地处理复杂的XML数据结构并转换为所需的格式。
## 复杂数据的序列化与反序列化
### 处理嵌套的JSON/XML结构
在处理JSON/XML数据时,经常遇到嵌套的数据结构,这些结构可能非常复杂,包含多层的嵌套和引用。正确处理这些结构对于提取和操作数据至关重要。
#### 示例:嵌套的JSON数据处理
假设有一个包含嵌套数组和对象的JSON数据,需要对其进行处理:
```json
{
"company": "TechCorp",
"locations": [
{
"name": "Headquarters",
"address": {
"street": "123 Main St",
"city": "Techville",
"country": "Techland"
}
},
{
"name": "R&D Center",
"address": {
"street": "456 Tech Blvd",
"city": "Innovasburg",
"country": "Techland"
}
}
]
}
```
为了处理这种嵌套结构,可以使用递归函数在Python中遍历并解析数据:
```python
def display_address(address):
for key, value in address.items():
if isinstance(value, dict):
display_address(value)
else:
print(f"{key}: {value}")
data = {
"company": "TechCorp",
"locations": [
{
"name": "Headquarters",
"address": {
"street": "123 Main St",
"city": "Techville",
"country": "Techland"
}
},
{
"name": "R&D Center",
"address": {
"street": "456 Tech Blvd",
"city": "Innovasburg",
"country": "Techland"
}
}
]
}
for location in data["locations"]:
print(location["name"])
display_address(location["address"])
print("\n")
```
这个例子中定义了一个辅助函数`display_address`来处理嵌套的地址信息,然后遍历`locations`数组中的每个位置信息。
### 数据的加密和解密
在处理敏感数据时,数据加密是必须的步骤,尤其是JSON/XML数据在网络上传输时。加密可以保护数据不被未授权访问,而解密则是在数据到达目的地后对数据进行还原的过程。
在Python中,可以使用标准库`cryptography`来进行数据的加密和解密。下面是一个简单的加密和解密过程的例子:
```python
from cryptography.fernet import Fernet
# 生成密钥并创建一个Fernet对象
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# 待加密的文本数据
data = {
"name": "Alice",
"address": {
"street": "123 Data Lane",
"city": "Cryptoville",
"country": "Secureland"
}
}
# 将JSON数据转换为字符串
data_json = json.dumps(data)
# 加密
encrypted_data = cipher_suite.encrypt(data_json.encode())
# 解密
decrypted_data = cipher_suite.decrypt(encrypted_data).decode()
# 将解密后的字符串转换回JSON数据
decrypted_json = json.loads(decrypted_data)
print("Original Data:", data)
print("Encrypted Data:", encrypted_data)
print("Decrypted JSON Data:", decrypted_json)
```
上述代码首先将JSON数据转换为字符串,然后使用Fernet密钥进行加密。加密后的数据是二进制格式的,可以安全传输。在接收端,使用相同的密钥进行解密,再将数据还原为可读的JSON格式。
## 高性能JSON/XML处理
### 流式解析技术
当处理大量数据时,如实时数据流或大型日志文件,全量解析技术可能会导致性能瓶颈,内存消耗也会急剧增加。为了解决这些问题,流式解析技术应运而生。这种技术允许对文档进行一次遍历,一边读取一边处理数据,从而显著减少内存的使用。
#### 示例:流式解析JSON数据
在Python中,可以使用`ijson`库进行流式解析JSON数据。下面是一个例子,展示了如何流式处理一个大型JSON文件:
```python
import ijson
# 假设有一个大型的JSON文件
large_json_file = 'large_dataset.json'
# 打开文件并创建一个流式解析对象
with open(large_json_file, 'rb') as f:
parser = ijson.parse(f)
# 遍历所有的company元素
for prefix, event, value in parser:
if (prefix, event) == ('item', 'map_key') and value == 'company':
company_name = next(parser)[2]
print(company_name)
```
在这个例子中,`ijson`库可以迭代地解析大型的JSON文件,避免一次性加载整个文件到内存中。这对于处理TB级别的文件特别有用。
### 优化数据处理的内存消耗
在处理大量JSON/XML数据时,内存消耗可能会迅速增加。为了优化内存使用,可以采取多种策略,比如使用生成器、使用高效的JSON/XML库、对数据进行分批处理等。
#### 示例:使用生成器优化内存使用
下面是一个使用生成器函数来分批处理JSON数据的例子:
```python
def parse_json_in_chunks(file_path, chunk_size=1024):
"""生成器函数,逐块读取和解析JSON文件"""
with open(file_path, 'rb') as file:
while True:
chunk = file.read(chunk_size)
if not chunk:
break
yield from ijson.items(chunk, 'item')
# 使用生成器处理数据
for item in parse_json_in_chunks('large_dataset.json'):
# 对每个item执行操作,例如:解析、转换、校验等
print(item)
```
在这个例子中,`parse_json_in_chunks`函数逐块读取一个大型JSON文件,并在每个块中返回解析的项。这样处理,内存中只保留当前处理的数据块,大大减少了内存使用。
## 总结
在本章节中,我们深入探讨了处理JSON/XML数据的高级技巧,包括数据转换与验证、处理复杂数据结构、以及优化性能的方法。通过模式验证和XSLT转换,确保了数据的正确性和适应性。对于复杂的嵌套结构和安全的数据传输,我们学习了递归函数和加密解密技术。最后,针对性能瓶颈,我们介绍了流式解析和内存优化技术。通过本章节内容的深入理解,我们可以更高效、更安全地处理大数据量的JSON/XML数据,提升应用程序的性能和扩展性。
# 5. 实践应用案例分析
## 5.1 集成DAHUA设备监控系统
### 5.1.1 监控系统的数据收集
在集成DAHUA监控系统时,首先面临的是从众多设备中收集数据的任务。DAHUA设备通常通过HTTP API接口提供数据,因此我们需要构建能够与这些接口交互的应用程序。在Python中,我们可以使用`requests`库来发送HTTP请求并收集数据。
```python
import requests
def collect_data_from_dahua(ip, port, username, password):
url = f'http://{ip}:{port}/Streaming/channels/1/packets'
response = requests.get(url, auth=(username, password))
if response.status_code == 200:
# 处理数据的逻辑...
pass
else:
print("Failed to collect data.")
collect_data_from_dahua('192.168.1.100', '80', 'admin', 'dahua123!')
```
### 5.1.2 实时数据的处理与展示
收集到的实时数据需要经过处理才能被有效展示。处理过程中,我们可能会涉及到JSON/XML数据格式的解析和转换。例如,如果数据以JSON格式返回,我们可以使用Python的`json`库来解析数据。
```python
import json
data = response.json() # 假设response包含了JSON数据
parsed_data = json.loads(data)
print(parsed_data)
```
展示处理后的数据,通常可以利用各种前端技术(如JavaScript和HTML/CSS)在网页上创建动态图表和仪表盘。
## 5.2 构建数据驱动的自动化脚本
### 5.2.1 自动化脚本的设计原则
自动化脚本的构建是提高工作效率的关键。一个良好的自动化脚本应该具备可读性、可维护性和可扩展性。在设计这样的脚本时,我们通常会遵循以下原则:
- 模块化:将脚本分为不同的模块或函数,每个部分负责一个特定的任务。
- 配置化:将可变的配置参数与代码逻辑分离,便于管理和调整。
- 日志记录:增加日志记录功能,便于跟踪脚本的执行过程和诊断问题。
### 5.2.2 实现API自动化测试案例
使用自动化脚本进行API测试可以显著提高测试效率。以下是一个使用Python的`pytest`和`requests`库来实现API测试的例子:
```python
import pytest
import requests
@pytest.mark.parametrize("ip, port, username, password, expected_status", [
('192.168.1.100', '80', 'admin', 'dahua123!', 200),
('192.168.1.101', '80', 'user', 'wrongpass', 401),
])
def test_dahua_api(ip, port, username, password, expected_status):
url = f'http://{ip}:{port}/Streaming/channels/1/packets'
response = requests.get(url, auth=(username, password))
assert response.status_code == expected_status
```
通过使用参数化测试,我们可以轻松地对多个API接口和参数组合进行测试。
## 5.3 大数据环境下的数据处理挑战
### 5.3.1 处理大规模JSON/XML数据流
在大数据环境下处理JSON/XML数据流时,常规的解析方法可能不再适用。为了应对这种挑战,我们可以使用流式解析技术来逐步处理数据,而不是一次性加载整个文档。
Python中的`xml.etree.ElementTree.iterparse`或`ijson`库可以用于处理大型XML或JSON文件:
```python
import ijson
with open('large_file.json', 'rb') as file:
parser = ijson.parse(file)
for prefix, event, value in parser:
if event == 'end_map':
print(value)
```
### 5.3.2 应对高并发数据请求的策略
高并发数据请求会给服务器造成巨大压力。为了应对这种压力,我们可以采取以下策略:
- 缓存:利用缓存来存储频繁请求的数据,减少对数据库的直接访问。
- 负载均衡:使用负载均衡技术分散请求到多个服务器,以避免单点过载。
- 异步处理:采用异步编程模型处理请求,提高服务器的响应能力和吞吐量。
以上实践案例分析展示了如何在具体的应用场景中,将JSON/XML数据处理技术和工具应用于实际问题解决,从而提升系统的性能与稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Romax载荷谱案例深度研究】:从实战中精通载荷谱分析技巧

参考资源链接:[Romax软件教程:DC1模块-载荷谱分析与处理](https://wenku.csdn.net/doc/4tnpu1h6n7?spm=1055.2635.3001.10343)
# 1. 载荷谱分析的基本原理
## 1.1 载荷谱的定义与重要性
载荷谱分析是结构工程和力学领域
【LTSPICE基础入门】:电子工程师的模拟电路仿真指南
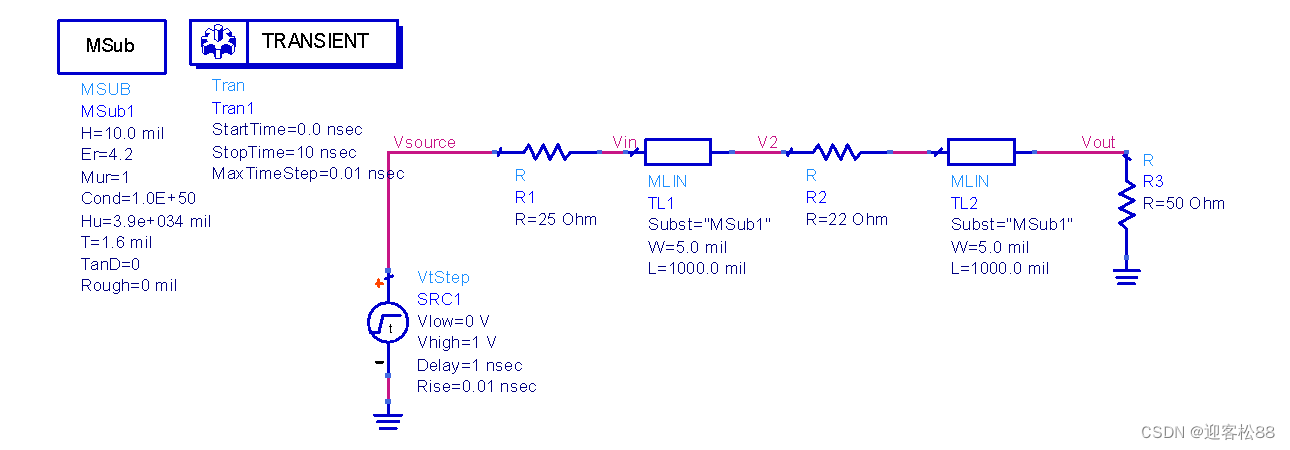
参考资源链接:[LTSPICE详尽教程:从入门到高级功能](https://wenku.csdn.net/doc/nqr8pvs0kw?spm=1055.2635.3001.10343)
# 1. LTSpice简介与安装
## LTSpice简介
LTSpice是一个高性能的SPICE仿真软件,由Linear Technology公司开发,广泛应用于电子电路设计和分析。它以其强大
图层混合模式全面解析:颜色互动的艺术
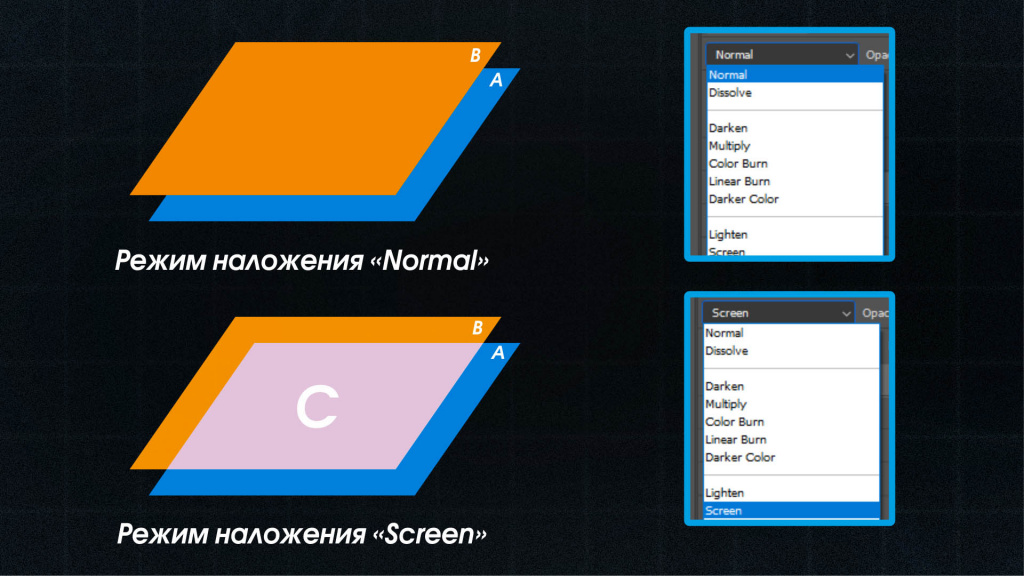
参考资源链接:[Origin8.5 图层管理教程:调整大小与位置](https://wenku.csdn.net/doc/38n32u79fn?spm=1055.2635.3001.10343)
# 1. 图层混合模式的基本概念
在数字图形编辑中,图层混合模式是一种用于图像合成的核心技术,它允许两个或更多图层的颜色和透明
S7-1200技术深究:BYTE转char转换的自动化实现与优化

参考资源链接:[S7-1200转换BYTE到char及Char_TO_Strg指令应用解析](https://wenku.csdn.net/doc/51pkntrszz?spm=1055.2635.3001.10343)
# 1. S7-1200 PLC与BYTE转char转换基础
在自动化控制系统中,西门子S7-1200 PLC
FOCAS工程管理手册:最佳实践与自动化测试集成

参考资源链接:[FANUC FOCAS函数API测试工程详解](https://wenku.csdn.net/doc/6412b4fbbe7fbd1778d41859?spm=1055.2635.3001.10343)
# 1. FOCAS工程管理概述
在当今快速发展的IT行业中,工程管理的效率直接影响项目交付的质量和速度。FOCAS工程管理作为一种现代化的管理方法,通过整合资源、优化流程和强化团队协作,
ImSL 7.0跨平台安装:Windows、Linux、macOS一步到位
参考资源链接:[IMSL7.0安装全攻略:Win10+VS2010+IVF2013](https://wenku.csdn.net/doc/6412b67abe7fbd1778d46df3?spm=1055.2635.3001.10343)
# 1. ImSL 7.0跨平台安装概述
欢迎来到探讨 ImSL 7.0 跨平台
Element-UI布局与数据可视化:打造直观且响应式的交互体验

参考资源链接:[Element-UI弹性布局教程:使用el-row和el-col实现自动换行](https://wenku.csdn.net/
ACS运动控制安全性指南:保障系统稳定的5项最佳实践
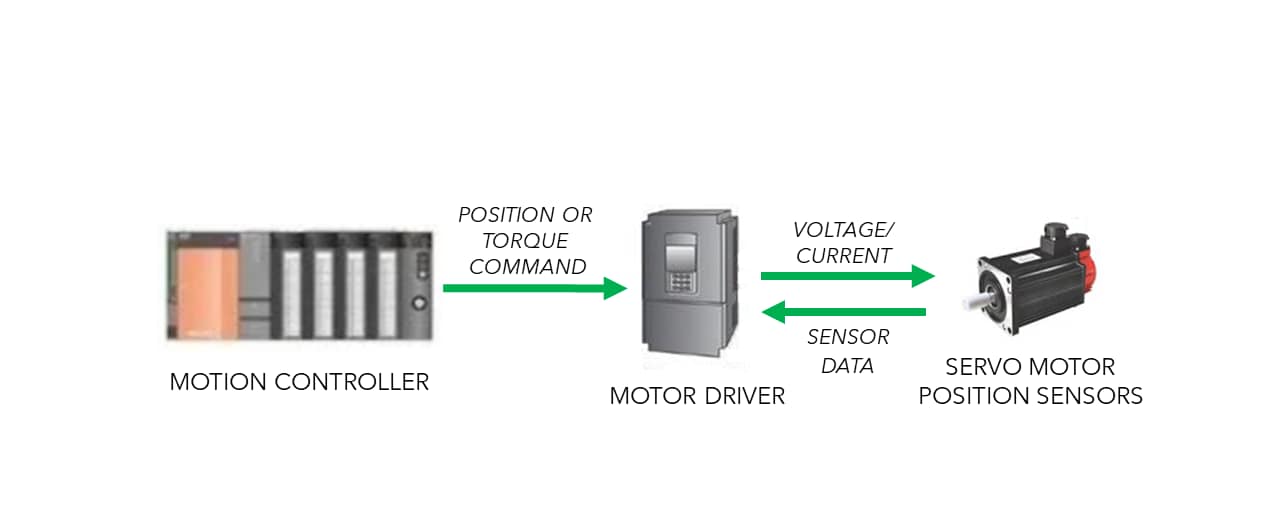
参考资源链接:[ACS运动控制快速调试指南](https://wenku.csdn.net/doc/6412b753be7fbd1778d49e42?spm=1055.2635.3001.10343)
# 1. 运动控制与安全性概述
在自动化技术飞速发展的当下,运动控制作为其中的核心组成部分,其在工业生产、机器人技术、航空航天等领域发挥着至关重要的作用。运动控制系统的安全性则是确保整个生产流程可靠、高效与无事故的关键。本
Python文件操作全攻略:提升数据读写效率的秘诀
参考资源链接:[传智播客&黑马程序员PYTHON教程课件汇总](https://wenku.csdn.net/doc/6412b749be7fbd1778d49c25?spm=1055.2635.3001.10343)
# 1. Python文件操作基础
在这一章节中,我们将介绍Python中最基本的文件操作。Python提供了丰富的内置函数,使得进行文件读写变得简单而高效。我们将从最基础
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )