Zookeeper入门指南:什么是Zookeeper及其应用
发布时间: 2023-12-08 14:12:06 阅读量: 73 订阅数: 41 
### 第一章:Zookeeper简介
Zookeeper是一个开源的分布式协调服务,旨在为分布式应用程序提供高性能、高可用性的共享配置和服务。它通过提供简单的接口和强大的一致性保证,使得开发人员可以更加轻松地构建分布式系统。
#### 1.1 什么是Zookeeper?
Zookeeper可以被看作是分布式系统中的一个文件系统,它采用树形结构来存储数据,类似于Unix文件系统。每个节点都可以存储数据,并且可以有子节点,这样就形成了一个层级化的命名空间。除了数据存储外,Zookeeper还为开发人员提供了一系列的特性,比如监听、通知和锁等,以解决分布式应用中的一致性、可用性和复杂性问题。
#### 1.2 Zookeeper的历史和发展
Zookeeper最初是由雅虎公司开发的,并于2010年成为Apache的顶级项目。自那时起,Zookeeper一直是许多大型分布式系统的核心组件,如Hadoop、Kafka等。随着分布式系统的发展和应用场景的不断增多,Zookeeper的重要性也变得愈发突出。
#### 1.3 Zookeeper的特点和优势
Zookeeper具有以下特点和优势:
- 顺序一致性:Zookeeper保证了对于特定节点的更新操作将按照顺序被应用,且全局有序。
- 可靠性:Zookeeper采用了领导者选举机制和数据复制机制来确保系统的高可用性。
- 实时性:针对特定节点的读操作能够保证最终一致性和及时性。
- 简单性:Zookeeper提供了简洁的文件系统模型和监听机制,使用起来相对简单。
- 可扩展性:Zookeeper的设计允许用户在不需要停机的情况下动态扩展集群规模。
### 第二章:Zookeeper的基本概念
在本章中,我们将介绍Zookeeper的基本概念,包括其数据模型、节点类型以及数据一致性保证。
#### 2.1 Zookeeper数据模型
Zookeeper的数据模型是一个基于树形结构的命名空间,每个节点可以存储数据并且具有唯一的路径。这个树形命名空间被称为ZNode,类似于文件系统中的目录和文件。ZNode可以被动态创建和销毁,同时支持监控和监听机制。
#### 2.2 Zookeeper节点类型
Zookeeper中的节点类型主要包括持久节点(Persistent)、临时节点(Ephemeral)、持久顺序节点(Persistent Sequential)和临时顺序节点(Ephemeral Sequential)。持久节点在创建后会一直存在,直到显式删除;临时节点在创建节点的client会话结束后被自动删除;顺序节点会在节点名后自动增加一个序号,以确保全局的顺序性。
#### 2.3 Zookeeper的数据一致性保证
Zookeeper提供了针对分布式应用实现一致性的保证,这种一致性是指一旦客户端对ZNode进行了写操作,那么所有客户端都将能够读取到这一变更。而且,Zookeeper保证了数据的最终一致性,即在一定时间内所有的读请求都将返回最新的写操作结果。
## 第三章:Zookeeper的使用场景和应用
Zookeeper作为一个高性能的分布式协调服务,在分布式系统中有着广泛的应用场景。接下来我们将重点介绍Zookeeper的使用场景和应用。
### 3.1 分布式协调
在分布式系统中,不同节点之间需要进行协调和通信,以保证系统的一致性和可靠性。Zookeeper通过提供一致的数据模型和监听机制,可以用来实现分布式协调,比如选举算法、领导者选举、分布式队列等功能。
```java
import org.apache.zookeeper.*;
import java.io.IOException;
public class ZookeeperDistributedCoordinator implements Watcher {
private static final String CONNECT_STRING = "localhost:2181";
private static final int SESSION_TIMEOUT = 5000;
private ZooKeeper zooKeeper;
public void connect() throws IOException {
this.zooKeeper = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, this);
}
public void process(WatchedEvent event) {
if (event.getState() == Event.KeeperState.SyncConnected) {
// 连接成功后的处理逻辑
}
}
public void close() throws InterruptedException {
this.zooKeeper.close();
}
}
```
上面是一个简单的使用Zookeeper实现分布式协调的Java代码示例,通过Zookeeper的Java客户端可以实现节点的监听和数据的协调。
### 3.2 服务发现与管理
在微服务架构中,服务发现和管理是非常重要的一环。通过Zookeeper的节点注册和监听机制,可以实现微服务的注册与发现,以及对服务的健康状态进行管理。
```python
from kazoo.client import KazooClient
zk = KazooClient(hosts='localhost:2181')
zk.start()
# 注册服务
zk.create("/services/service-1", b"127.0.0.1:8080", ephemeral=True, sequence=True)
# 发现服务
services = zk.get_children("/services")
for service in services:
data, stat = zk.get("/services/" + service)
print("Service address: %s" % data.decode("utf-8"))
zk.stop()
```
上面是一个用Python语言实现的服务注册与发现的示例,通过Kazoo库可以轻松地实现服务的注册和发现。
### 3.3 分布式锁
在分布式系统中,可能会出现多个节点竞争同一资源的情况,这时就需要使用分布式锁来保证资源的互斥访问。Zookeeper可以通过临时节点和顺序节点特性来实现分布式锁。
```javascript
const zookeeper = require('node-zookeeper-client');
const lockPath = '/locks/lock-1';
const client = zookeeper.createClient('localhost:2181');
client.once('connected', function () {
client.create(lockPath, zookeeper.CreateMode.EPHEMERAL_SEQUENTIAL, function (error, path) {
if (error) {
console.log('Failed to create lock node: %s due to: %s.', lockPath, error);
} else {
client.getChildren('/locks', function (error, children) {
if (error) {
console.log('Failed to list children of %s due to: %s.', lockPath, error);
} else {
const sortedChildren = children.sort();
if (path.endsWith(sortedChildren[0])) {
console.log('I got the lock');
// Do something
} else {
console.log('I didn\'t get the lock, should release the resources and quit');
}
}
});
}
});
});
```
上面是一个使用Node.js实现的分布式锁示例,通过创建临时顺序节点,并结合节点监听机制,实现了分布式环境下的锁机制。
### 3.4 分布式配置管理
在分布式系统中,配置管理是一个很常见的需求。Zookeeper提供了节点数据的存储和监听机制,可以用来实现分布式配置的管理和更新。
```go
package main
import (
"fmt"
"github.com/samuel/go-zookeeper/zk"
"time"
)
func main() {
c, _, err := zk.Connect([]string{"localhost:2181"}, time.Second)
if err != nil {
panic(err)
}
defer c.Close()
// 创建节点
path := "/config/app-1"
value := []byte("{'key': 'value'}")
_, err = c.Create(path, value, 0, zk.WorldACL(zk.PermAll))
if err != nil {
panic(err)
}
// 监听节点变化
for {
data, stat, ch, err := c.GetW(path)
if err != nil {
panic(err)
}
fmt.Printf("Config value: %s\n", data)
evt := <-ch
fmt.Printf("Config updated, new version: %d\n", stat.Version)
}
}
```
上面是一个使用Go语言实现的分布式配置管理示例,通过zk库可以实现对节点数据的监听和配置更新。
### 4. 第四章:Zookeeper的安装与配置
Zookeeper的安装和配置是使用Zookeeper的重要步骤,正确的安装和配置可以保证Zookeeper集群的稳定和高效运行。本章将介绍Zookeeper的安装和配置过程,并提供常见问题的解决方案。
#### 4.1 环境准备
在安装Zookeeper之前,需要准备好以下环境:
- 硬件:确保服务器硬件符合Zookeeper的要求,并且具有良好的网络连接。
- 操作系统:Zookeeper支持多种操作系统,包括Linux、Windows和Mac OS等。
- Java环境:Zookeeper是基于Java开发的,因此需要安装JDK。
#### 4.2 安装Zookeeper
安装Zookeeper的步骤如下:
1. 下载Zookeeper:从官方网站下载最新稳定版本的Zookeeper压缩包。
2. 解压缩:将压缩包解压到指定的安装目录。
3. 配置环境变量:将Zookeeper的bin目录添加到系统的Path环境变量中,方便在任何地方使用Zookeeper命令。
#### 4.3 配置Zookeeper集群
配置Zookeeper集群需要注意以下几个重要参数:
- `dataDir`:指定Zookeeper数据存储目录。
- `dataLogDir`:指定Zookeeper事务日志的存储目录。
- `clientPort`:指定Zookeeper客户端与服务器交互的端口号。
- `tickTime`:指定Zookeeper中基本的时间单位,以毫秒为单位。
- `initLimit`和`syncLimit`:用于配置选举和同步的相关参数。
#### 4.4 常见问题与解决方案
在安装和配置Zookeeper的过程中,可能会遇到一些常见问题,例如端口冲突、配置错误等。针对这些问题,可以通过检查日志、查阅官方文档或在相关社区寻求帮助来解决。
希望上述安装和配置过程对您有所帮助,在配置Zookeeper集群时,请务必仔细阅读官方文档并遵循最佳实践指南。
### 5. 第五章:Zookeeper的基本操作与集群管理
在本章中,我们将深入探讨Zookeeper的基本操作和集群管理,包括Zookeeper客户端连接、数据节点的操作、观察者和通知以及集群状态查看与管理。
#### 5.1 Zookeeper客户端连接
Zookeeper提供了多种客户端库,使得开发者可以使用Java、Python、Go等多种编程语言与Zookeeper集群进行交互。
在本节中,我们将以Python语言为例,演示如何连接Zookeeper集群,并进行一些基本的操作。
```python
from kazoo.client import KazooClient
# 连接Zookeeper集群
zk = KazooClient(hosts='127.0.0.1:2181')
zk.start()
# 创建节点
zk.create("/test", b"Hello, Zookeeper!")
# 读取节点数据
data, stat = zk.get("/test")
print("Node data: %s, version: %s" % (data.decode("utf-8"), stat.version))
# 关闭连接
zk.stop()
```
代码解释:
- 首先导入KazooClient类,用于连接Zookeeper集群。
- 使用KazooClient连接到Zookeeper集群,并创建一个名为"/test"的节点,设置节点数据为"Hello, Zookeeper!"。
- 通过get方法读取"/test"节点的数据,并打印出节点数据和版本信息。
- 最后关闭与Zookeeper集群的连接。
#### 5.2 数据节点的操作
Zookeeper提供了丰富的API来操作数据节点,包括节点的创建、删除、读取、更新等操作。开发者可以根据具体的业务需求,灵活运用这些API。
下面是一个Java语言示例,演示如何使用ZooKeeper API来操作节点:
```java
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
public class ZookeeperDemo {
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 3000, watchedEvent -> {
// 监听器逻辑
});
// 创建节点
String path = zooKeeper.create("/test", "Hello, Zookeeper!".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 读取节点数据
Stat stat = new Stat();
byte[] data = zooKeeper.getData("/test", false, stat);
System.out.println("Node data: " + new String(data) + ", version: " + stat.getVersion());
// 删除节点
zooKeeper.delete("/test", stat.getVersion());
zooKeeper.close();
}
}
```
在上面的示例中,我们使用Java语言连接到Zookeeper集群,并演示了节点的创建、读取和删除操作。
#### 5.3 观察者和通知
Zookeeper提供了观察者模式,允许客户端注册对特定节点的观察,当节点发生变化时,客户端将收到通知。
下面是一个基于JavaScript的示例,演示了如何使用Zookeeper的观察者功能:
```javascript
const zookeeper = require('node-zookeeper-client');
const client = zookeeper.createClient('127.0.0.1:2181');
client.connect();
client.once('connected', () => {
client.getData("/test", event => {
console.log("Node data changed:", event);
}, (error, data, stat) => {
console.log("Current data: ", data.toString('utf8'), ", version: ", stat.version);
});
});
```
在上面的示例中,我们使用Node.js语言连接到Zookeeper集群,并注册了对"/test"节点的观察。当"/test"节点的数据发生变化时,客户端将收到通知。
#### 5.4 集群状态查看与管理
除了节点级别的操作,Zookeeper还提供了API来查看和管理整个集群的状态。
以下是一个Go语言示例,演示了如何查看Zookeeper集群的健康状态:
```go
package main
import (
"fmt"
"github.com/samuel/go-zookeeper/zk"
"time"
)
func main() {
servers := []string{"127.0.0.1:2181"}
conn, _, err := zk.Connect(servers, time.Second*5)
if err != nil {
panic(err)
}
defer conn.Close()
children, _, err := conn.Children("/")
if err != nil {
panic(err)
}
fmt.Println("Zookeeper cluster nodes:")
for _, child := range children {
fmt.Println(child)
}
}
```
在上面的示例中,我们使用Go语言连接到Zookeeper集群,并获取了集群中所有节点的信息,并打印输出。这样的信息有助于了解集群的整体情况。
### 6. 第六章:Zookeeper的最佳实践和未来展望
在本章中,我们将探讨Zookeeper的最佳实践和未来发展趋势,以及对Zookeeper的展望。
#### 6.1 Zookeeper最佳实践
Zookeeper作为一个重要的分布式协调框架,有一些最佳实践可以帮助开发人员更好地利用它:
- **合理设计数据模型:** 在使用Zookeeper时,需要合理地设计数据模型,避免过于复杂的层级结构,以确保高效的数据访问和管理。
- **充分利用Watch机制:** Zookeeper提供了Watch机制用于通知客户端关于节点数据变化,充分利用这一特性可以减少不必要的轮询请求,提高系统性能。
- **合理设置超时时间:** 在Zookeeper的配置中,需要合理设置会话超时时间和连接超时时间,以确保系统的稳定性和可靠性。
- **定期维护和监控:** 对Zookeeper集群进行定期的维护和监控是非常重要的,包括节点状态、负载均衡、性能指标等。
- **处理好异常情况:** 在使用Zookeeper时,需要做好异常情况的处理,例如网络不稳定、节点宕机等,保证系统的可靠性和稳定性。
#### 6.2 Zookeeper未来发展趋势
随着大数据、云计算等技术的快速发展,Zookeeper作为分布式协调框架也将面临一些新的挑战和机遇:
- **更好的扩展性:** 随着数据规模和访问量的增大,Zookeeper需要更好的扩展性以支持更多的节点和更高的并发访问。
- **更丰富的功能特性:** 未来的Zookeeper可能会加入更丰富的功能特性,例如支持更多的节点类型、更灵活的数据存储模型等。
- **更好的与容器化技术集成:** 随着容器化技术如Kubernetes的兴起,Zookeeper需要更好地与这些容器化平台集成,以便更好地支持微服务和大数据应用场景。
- **更好的安全性和权限管理:** 随着安全性问题日益凸显,未来的Zookeeper需要提供更好的安全机制和权限管理,确保数据的安全可靠。
#### 6.3 结语
Zookeeper作为一个重要的分布式协调框架,在大数据、云计算、微服务等领域扮演着重要的角色。通过合理的最佳实践和不断的发展趋势,Zookeeper必将在未来发挥更加重要的作用,为分布式系统提供更好的支持。
希望通过本章内容的介绍,读者对Zookeeper的最佳实践和未来展望有了更深入的理解。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Zookeeper"为主题,旨在深入探讨这一分布式协调服务的核心工具。专栏以"Zookeeper入门指南"开始,介绍了Zookeeper的基本概念及应用场景;接着对Zookeeper的安装、配置进行了详细解析,并深入探讨了其原理与实现机制。随后,重点关注了Zookeeper集群的搭建、监控与调试技巧,以及基于Java的API开发和与各种主流技术的结合应用。最后,结合实践场景,延伸至Zookeeper在微服务架构、分布式事务处理、缓存系统、数据库等领域中的应用,并介绍了ZooInspector工具的使用指南。通过本专栏,读者将全面了解Zookeeper在分布式系统中的核心作用及其丰富的应用场景,为构建稳健、高可用的分布式系统提供有效的实践指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【交互细节实现】:从零开始学习Android事件处理机制
# 摘要
本文详细探讨了Android平台上的事件处理机制,包括其理论基础、实践应用以及深入剖析。首先概述了事件处理的基本概念和分类,重点介绍了事件监听器模式和回调函数的使用,随后深入研究了触摸事件的生命周期和分发机制。文章进一步阐述了在自定义View和手势识别中事件处理的实践应用,并提供了高级事件处理技巧和系统级事件响应方法。在深入剖析章节中,作者分析了事件处理的源码,并探讨了设计模式如
【FABMASTER教程高级篇】:深度掌握工作流优化,成为专家不是梦

# 摘要
工作流优化是提升企业效率和效能的关键环节,本文综合论述了工作流优化的理论基础和实践应用。首先,探讨了工作流自动化工具的选择与配置,以及工作流的设计、建模与执行监控方法。进阶策略包括优化性能、确保安全合规以及增强工作流的扩展性和灵活性。通过分析成功与失败案例,本文展示了优化实施的具体步骤和可能遇到的问题。
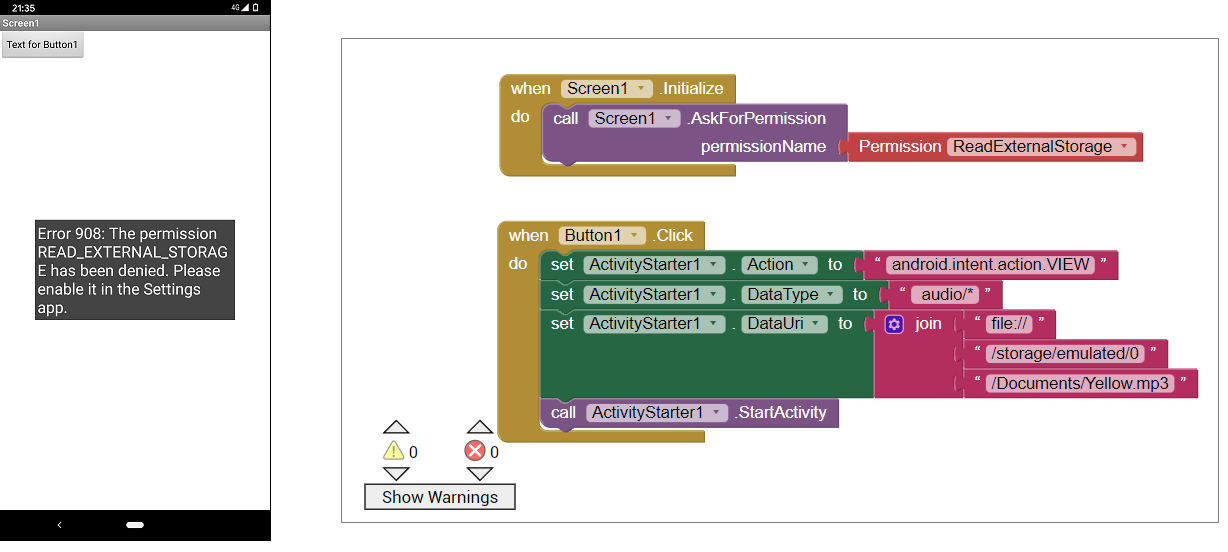
【安全播放的根基】:Android音乐播放器的权限管理全攻略
# 摘要
本文深入探讨了Android音乐播放器权限管理的关键要素,从权限管理的理论基础到实战应用,再到优化和隐私保护策略,系统性地分析了音乐播放器在权限管理方面的需求、流程、安全性和未来的发展趋势。文章首先介绍了Android权限模型的历史演进及机制,然后阐述了音乐播放器的权限需求与动态处理策略
【Mplus可视化操作】:图解Mplus 8界面,新手也能轻松上手

# 摘要
Mplus软件因其强大和灵活的数据分析功能而被广泛应用于社会科学研究。本文旨在为Mplus的新用户提供一套全面的安装指南和操作教程,并向有经验的用户提供高级可视化技巧和最佳实践。章节从基础操作与界面图解开始,逐步深入到可视化编程基础、高级可视化技巧以及在数据科学中的应用实例。最后,本文探讨了Mplus可视化操作中常见的问题和挑战,并展望了软件未来的发展趋势。通过实例分析和对高级主题的探讨,本文不仅帮助用户掌握Mplu
三菱IQ-R PLC的socket通信秘籍:从入门到企业级应用的全面指南

# 摘要
本文探讨了三菱IQ-R PLC与socket通信的全面概览和应用细节。首先,介绍了与socket通信相关的PLC网络设置和理论基础。其次,深入分析了数据传输过程中的设计、错误处理、连接管理和安全性问题,着重于数据封装、错误检测以及通信加密技术。实践应用案例部分,详细说明了数据采集、PLC远程控制的实现,以及企业级应用
数据库优化专家:大学生就业平台系统设计与实现中的高效策略
# 摘要
本文探讨了就业平台系统的数据库优化与系统实现,首先分析了系统的需求,包括用户需求和系统架构设计。接着,深入到数据库设计与优化环节,详细讨论了数据库的逻辑设计、性能优化策略,以及高效管理实践。文章还涉及系统实现和测试的全过程,从开发环境的搭建到关键模块的实现和系统测试。最后,基于当前就业市场趋势,对就业平台的未来展望和可能面临的
【深入掌握FreeRTOS】:揭秘内核设计与高效内存管理

# 摘要
FreeRTOS是一个流行的实时操作系统(RTOS),专为资源受限的嵌入式系统设计。本文首先介绍了FreeRTOS的核心概念,然后深入剖析了其内核架构,包括任务管理和时间管理的基本组件,以及调度器设计和上下文切换机制。接下来,探讨了FreeRTOS的内存管理机制,包括内存分配策略、优化技巧以及实践案例,以期提升系统性能和稳定性
VLISP与AutoCAD交互新高度:个性化工具打造实战指南

# 摘要
本文旨在介绍VLISP语言的基本概念、语法以及在AutoCAD中的应用,并探讨如何通过VLISP实现AutoCAD的自定义功能和自动化处理。文章首先概述VLISP语言及其在AutoCAD环境中的应用,随后详细解释了VLISP的基础语法、数据类型、控制结构、自定义函数以及编程技巧。进一步,文章深入探讨了VLISP如何与AutoCAD的内部对象模型和命令集交互,以
从零开始:Vue项目中的高德地图搜索功能集成全攻略

# 摘要
本文详细阐述了在Vue项目中集成高德地图搜索功能的全过程。从理论基础到实践应用,本文首先介绍了高德地图API的关键特点和搜索功能的核心原理,包括地理编码、关键字搜索机制以及智能提示等。随后,详细描述了集成高德地图Web服务SDK、嵌入地图组件以及实现搜索功能的具体步骤,重
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )