




【国际化随机数生成】:应对文化差异的Python随机数处理策略

1. 随机数生成基础与文化差异概述
1.1 随机数的重要性与应用场景
随机数在软件开发、数据分析、游戏设计、安全加密等多个领域扮演着至关重要的角色。例如,密码学中的密钥生成、模拟测试中的数据构建、游戏中的事件触发等都离不开随机数。了解随机数的生成原理和应用方法,对于提高程序的健壮性和用户体验至关重要。
1.2 随机数的文化差异
不同文化背景下对随机性的看法不同,这些差异影响了随机数的生成和应用。例如,在西方文化中,随机可能意味着公平和机会均等;而在东方文化中,可能更强调循环和有序性。理解这些差异有助于开发者设计出更加贴合用户文化的软件产品。
1.3 随机数的类型和生成方法
随机数可分为真随机数和伪随机数。真随机数基于物理过程,如量子随机性;而伪随机数则通过算法生成,易于计算机处理。本章将简述随机数的基本概念,并探讨如何根据不同的需求选择合适的随机数类型和生成方法。
2. Python随机数库的理论与应用
2.1 Python内置随机数库概览
Python作为一门广泛使用的编程语言,内置的随机数库为开发者提供了丰富的工具来生成伪随机数。这些随机数在测试、模拟以及加密等众多应用场景中扮演着关键角色。
2.1.1 随机数库的安装与配置
Python的标准库中并没有专门的随机数生成库,但内置的random模块提供了生成随机数所需的大多数功能。在安装和配置方面,Python的随机数库使用起来相当简单,因为它是随Python解释器一起安装的。开发者无需进行额外的配置步骤,直接在Python环境中导入模块即可使用。
- import random
- # 测试随机数库是否正常工作
- random_number = random.random()
- print(random_number)
在上述代码中,random模块被导入,然后使用random()函数生成了一个[0, 1)范围内的随机浮点数。
2.1.2 常用随机数函数及用法
Python内置的random模块提供了很多有用的函数,包括但不限于random(), randint(), uniform(), choice(), shuffle()等。我们可以通过这些函数生成不同类型的随机数,下面将逐一进行介绍。
random(): 生成一个[0, 1)范围内的随机浮点数。randint(a, b): 生成一个指定范围[a, b]内的随机整数。uniform(a, b): 生成一个指定范围[a, b)内的随机浮点数。choice(seq): 从非空序列seq中随机选择一个元素。shuffle(seq[, random]): 将序列seq中的元素随机打乱位置。
2.1.3 代码逻辑的逐行解读分析
以choice()函数为例,下面是对该函数使用方法的逐行解读:
- import random
- # 创建一个字符串列表
- my_list = ['apple', 'banana', 'cherry', 'date']
- # 使用choice函数随机选择列表中的一个元素
- selected_element = random.choice(my_list)
- print(selected_element)
在这段代码中,首先导入了random模块,然后创建了一个包含水果名称的列表my_list。接着使用choice()函数从中随机选择了一个元素,并将其存储在变量selected_element中,最后将选中的元素打印出来。
每个函数在使用时都有其特定的用途和适用场景,因此理解它们的不同特性对于生成满足特定需求的随机数至关重要。
2.2 随机数生成算法详解
随机数生成库虽然方便易用,但它们背后的算法对于生成什么样的随机数以及如何高效生成有着决定性的影响。
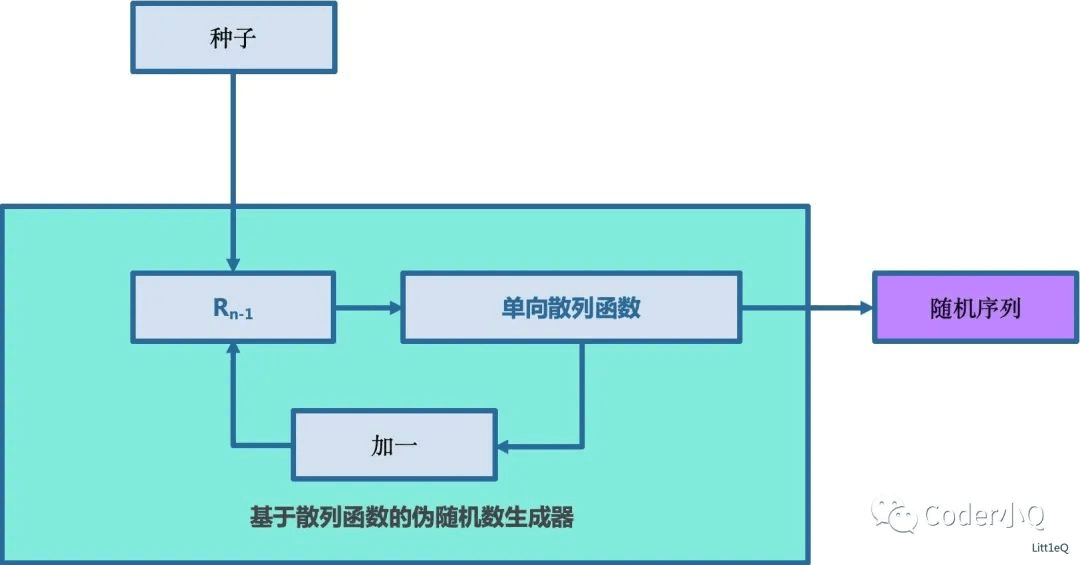
2.2.1 线性同余生成器
线性同余生成器是一种常用的伪随机数生成算法。其核心公式为:X_(n+1) = (a * X_n + c) mod m。其中,X代表序列中的数值,m、a、c是算法参数。线性同余生成器的特点是简单且速度快,但周期较短且随机性有限。
2.2.2 梅森旋转算法
梅森旋转算法(Mersenne Twister)是一种特别的伪随机数生成算法,其周期极长(2^19937-1),并且在统计测试中表现出色。Python中的random模块实际上就是基于改进的梅森旋转算法实现的。
- import random
- # 生成一个随机整数
- random_integer = random.randint(0, 1000000)
- print(random_integer)
上述代码展示了如何使用random.randint函数生成一个指定范围内的随机整数,该函数内部使用的就是梅森旋转算法。
2.3 随机数生成的国际化问题
国际化是软件开发中一个重要的概念,它意味着软件产品需要能够适应不同地区、不同语言和文化的需求。
2.3.1 文化差异对随机数的影响
在某些应用场景中,生成的随机数可能需要符合特定文化的习惯或者特定语言环境。例如,在生成随机日期时可能需要考虑到当地节假日的影响,或是生成随机姓名时需符合当地的命名习惯。
2.3.2 国际化随机数生成的需求分析
对于涉及国际化处理的随机数生成,需要对库函数进行扩展,以便适应不同国家和地区用户的需求。例如,可以设计可配置的随机数生成器,它允许用户指定日期范围、文化习惯等参数,以生成符合当地习惯的随机数。
总结
在本章节中,我们深入探讨了Python内置随机数库的基础知识、使用方法、常用函数以及其背后的重要算法。同时,我们也分析了国际化对于随机数生成的影响以及如何应对国际化需求,为下一章的实践技巧和高级应用打下坚实的基础。在接下来的章节中,我们将更具体地探索在不同场景下如何应用国际化随机数生成器,以及如何通过高级技术提升随机数生成的效率和安全性。
3. 国际化随机数生成实践技巧
3.1 处理日期和时间的随机数生成
3.1.1 日期时间格式的国际化处理
在生成国际化随机数时,日期和时间的处理尤为重要。不同地区和文化对于日期和时间的表示方式存在差异,例如,美国通常使用月/日/年(MM/DD/YYYY)格式,而欧洲大多数国家则使用日/月/年(DD/MM/YYYY)格式。为了生成符合国际化标准的随机日期和时间,我们需要考虑以下几点:
- 使用国际标准日期时间格式 ISO 8601 (YYYY-MM-DD)。
- 考虑时区差异,确保生成的时间戳在不同地区都有效。
- 使用Python的
datetime和pytz库处理日期时间和时区。
下面是一个示例代码,展示如何在Python中生成国际化随机日期时间:

3.1.2 时间戳随机生成的实践案例
时间戳通常用于表示特定时刻,适用于需要精确到秒甚至毫秒的场景。在Python中,我们可以使用random和datetime库生成时间戳。例如,以下代码生成了一个符合特定时区范围内的随机时间戳:
- from datetime import datetime, timedelta
- import random
- import pytz
- # 假设我们需要生成2020年1月1日至2023年12月31日之间的时间戳
- def random_timestamp_in_range(start, end, timezone='UTC'):
- # 随机选择一天
- random_day = start + timedelta(days=random.randint(0, (end - start).days))
- # 随机选择一个时间点,以秒为单位
- random_seconds = random.randint(0, 24*60*60-1)
- # 组合成随机时间戳
- random_datetime = ***bine(random_day, timedelta(seconds=random_seconds))
- # 根据时区进行本地化
- tz = pytz.timezone(timezone)
- localized_datetime = tz.localize(random_datetime)
- #

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
信息安全管理体系持续改进:实用策略与高效实践
【专家揭秘】Office自动判分系统与竞品的比较分析
技术选型比较:不同自动应答文件开发框架的深度剖析
【量化分析】:分子动力学模拟的量化分析:实用方法与技巧
Zynq-7000 SoC高速接口设计:PCIe与HDMI技术详解
【版本更新与维护】:DzzOffice小胡版onlyoffice插件的持续升级策略
【T-Box开发速成课】:一步步教你从零构建稳定系统
Fluentd在大规模环境中的生存指南:挑战与应对策略全解析
深入探索戴尔笔记本BIOS高级设置:性能与安全的双赢策略
电源设计与分析:3D IC设计中的EDA工具高级技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















