定制日志策略:提高系统安全性的syslog消息过滤与处理
发布时间: 2024-10-15 15:02:20 阅读量: 48 订阅数: 34 

操作系统安全:linux系统日志介绍.ppt
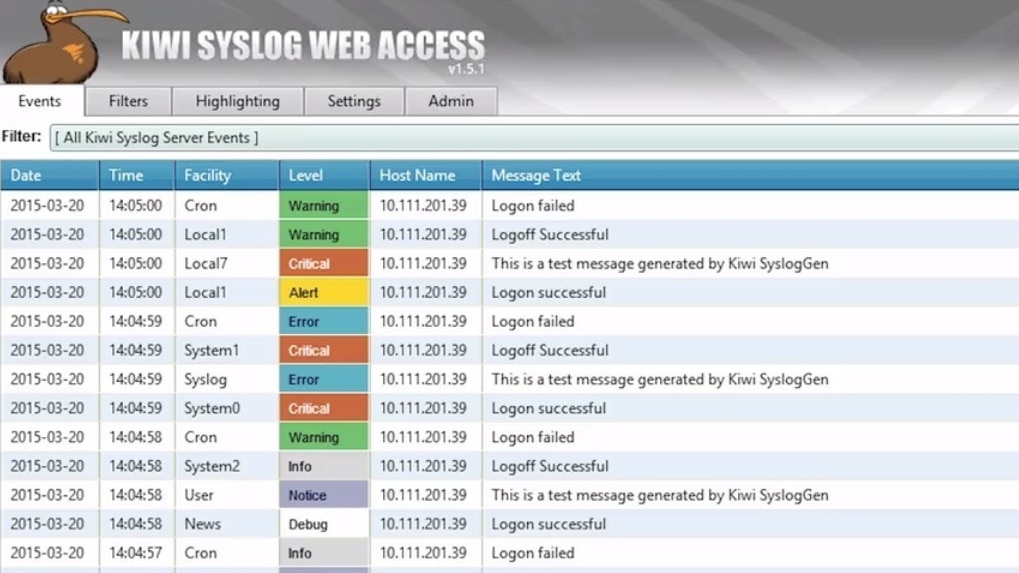
# 1. Syslog系统概述
Syslog是IT领域中广泛使用的一种协议,它主要用于收集和转发系统日志消息。这种协议被设计为跨平台使用,允许不同类型的设备和软件之间共享和记录消息。
## Syslog协议基础
Syslog协议最初在RFC 3164中定义,后来在RFC 5424中进行了更新,提供了更加丰富和灵活的消息格式。它使用UDP协议作为传输机制,尽管这不是唯一的方式。Syslog消息包含几个关键部分,包括设施代码(facility code)、严重性级别(severity level)和消息文本。
### 设施代码和严重性级别
设施代码用于指示消息的来源,如系统组件、安全机制或其他服务。严重性级别则表明事件的紧急程度,从0(紧急)到7(调试)不等。这些级别帮助管理员根据重要性对日志进行分类和优先级排序。
### 消息格式
一个典型的Syslog消息包含时间戳、主机名、应用名称、消息内容等信息。通过这些信息,管理员可以快速定位问题,分析事件发生的背景和影响。
```text
<13>Oct 11 22:14:*** su: 'su root' failed for user baduser on /dev/pts/1
```
在上述示例中,`<13>`是设施代码和严重性级别的组合,`Oct 11 22:14:15`是时间戳,`***`是发送消息的主机名,`su: 'su root' failed for user baduser on /dev/pts/1`是消息内容。
通过理解Syslog的基本概念和消息格式,管理员可以有效地利用Syslog进行事件监控和问题诊断。在接下来的章节中,我们将深入探讨Syslog消息的过滤和处理机制,以及如何在实践中应用这些知识。
# 2. Syslog消息过滤机制
Syslog作为IT行业中广泛使用的一种系统日志管理工具,其消息过滤机制是确保日志信息有效性和安全性的关键组成部分。本章节将深入探讨Syslog消息过滤机制的理论基础、实践应用以及高级策略,帮助读者构建和优化过滤规则,以适应不同场景的需求。
## 2.1 过滤规则的理论基础
### 2.1.1 过滤规则的作用与重要性
过滤规则是Syslog系统中用于选择性地记录日志信息的重要手段。它们允许管理员定义哪些日志消息应该被记录,哪些应该被忽略。这种机制不仅有助于减少日志存储空间的浪费,还能提高日志分析的效率和准确性。
过滤规则的重要性在于,它能够帮助系统管理员快速定位和响应关键事件,同时避免被大量无关信息干扰。例如,在安全性监测中,管理员可能只关心来自特定IP地址的登录失败尝试,而不关心正常的登录活动。
### 2.1.2 过滤规则的定义与配置方法
过滤规则通常由过滤器(filter)和动作(action)组成。过滤器定义了哪些日志消息符合过滤条件,而动作则定义了符合条件的这些消息将如何被处理,例如记录到特定文件、发送到远程服务器或直接丢弃。
在Syslog中,过滤规则可以在日志服务器端配置,也可以在客户端配置。以下是一个在Syslog-ng中配置过滤规则的简单示例:
```plaintext
filter f_syslog {
facility(user) and level(debug..warning);
};
destination d_syslog {
file("/var/log/syslog" perm(0640) owner(root) group(log));
};
log {
source(s_src);
filter(f_syslog);
destination(d_syslog);
};
```
在本示例中,过滤器`f_syslog`定义了只有来自`user`设施且优先级在`debug`到`warning`之间的消息会被处理。动作`d_syslog`定义了这些消息将被记录到`/var/log/syslog`文件中。
## 2.2 过滤策略的实践应用
### 2.2.1 实践案例:自定义过滤规则
在实际应用中,自定义过滤规则可以大幅提升Syslog系统的灵活性和效率。以下是一个更加复杂的示例,展示了如何配置Syslog-ng来过滤特定的网络连接日志。
```plaintext
filter f_network {
match("connected to" value("."));
};
filter f_level {
level(info..notice);
};
log {
source(s_src);
filter(f_network and f_level);
destination(d_syslog);
};
```
在这个例子中,`f_network`过滤器匹配包含`"connected to"`的日志消息,而`f_level`过滤器则限制日志消息的优先级为`info`到`notice`。这两个过滤器结合起来,意味着只有包含`"connected to"`且优先级在`info`到`notice`之间的消息会被记录。
### 2.2.2 过滤规则的测试与验证
在定义了过滤规则之后,需要进行测试以确保它们按预期工作。可以使用Syslog的测试工具,如`logger`命令在Linux系统中模拟日志消息,并检查它们是否被正确过滤。
```***
*** "This is a test message"
```
然后,检查`/var/log/syslog`文件中是否记录了正确的消息。
## 2.3 过滤规则的高级策略
### 2.3.1 利用正则表达式进行高级过滤
正则表达式提供了一种强大的方式来匹配复杂的文本模式。在Syslog过滤规则中,可以利用正则表达式进行更加灵活的匹配。
```plaintext
filter f_regex {
message(".*connection.*" flags(re));
};
```
在这个例子中,`f_regex`过滤器使用正则表达式`".*connection.*"`来匹配包含`"connection"`的所有消息。
### 2.3.2 复杂场景下的过滤策略优化
在复杂的网络环境中,可能需要根据多种条件进行过滤。这时,可以使用逻辑运算符来组合多个过滤器。
```plaintext
filter f_complex {
(program(syslogd) and facility(user))
or (program(kernel) and level(info));
};
```
在这个例子中,`f_complex`过滤器组合了两个条件:一是来自`syslogd`程序且属于`user`设施的消息,二是来自`kernel`程序且优先级为`info`的消息。
通过本章节的介绍,我们了解了Syslog消息过滤机制的理论基础,掌握了过滤规则的定义与配置方法,并通过实践案例学习了自定义过滤规则的创建和测试。在后续章节中,我们将继续探讨Syslog消息处理方法和安全性策略,以构建更加完善和安全的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中 syslog 模块的强大功能,涵盖了高级日志管理策略、跨平台集成技巧、自定义日志级别、性能优化、消息过滤和处理、故障排除、日志分析、网络功能、日志轮转、源码解读、分布式系统中的作用、扩展应用、安全实践、自定义处理、实时分析、调试技巧以及合规性遵循。通过一系列文章,该专栏旨在帮助读者充分利用 syslog 模块,以实现高效、可靠和安全的日志管理,从而增强应用程序的稳定性和可维护性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
东芝打印设备高效管理秘籍:配置与维护2523A-2829A的最佳实践
# 摘要
本文全面概述了东芝打印设备的管理和配置,从基础配置需求到高级配置技巧,再到维护与故障排除,为用户提供了系统性的指导。同时,详细介绍了东芝打印管理软件的应用,包括其功能特点、高级管理功能及自定义工作流程。通过案例研究与最佳实践分享,本文旨在为教育行业和企业级用户在配置、管理和维护东芝打印设备时提供实际帮助和参考。最后,本文展望了打印技术的未来发展趋势,以及可持续管理与环保的重要性。
# 关键字
东芝打印设备;设备配置;维护与故障排除;打印管理软件;性能监控与调优;教育行业应用
参考资源链接:[东芝2523A-2323AM-2823AM-2829A维修手册:故障代码与维修模式详解](
软件架构设计之MagicDraw 17指南:掌握最佳实践,洞悉案例分析
# 摘要
本文旨在提供MagicDraw 17这一专业UML建模工具的全面介绍,涵盖安装、界面布局、基础操作,以及基于其进行UML建模和高级应用的实践指导。文章首先介绍MagicDraw 17的基本使用,包括安装步骤和界面定制,然后深入讲解如何通过该工具进行UML图的创建和管理。接着,文章探讨了使用MagicDraw进行UML
CCES实战案例分析:揭开成功企业配置管理背后的秘密

# 摘要
随着信息技术的快速发展,CCES配置管理作为一种提高软件和系统开发效率、保证质量的重要实践,越来越受到业界的关注。本文首先介绍了CCES配置管理的基础知识和理论框架,重点阐述了配置管理的重要性、目标、最佳实践以及关键活动。随后,文章深入探讨了配置管理的实践技巧,包括配置项的识别与分类、状态报告与跟踪以及自动化管理的具体应用。通过案例实战分
【计数器逻辑快速构建】:Mixly实现1602液晶屏计数功能的秘诀
# 摘要
本文围绕Mixly编程环境和1602液晶屏展开介绍,并探讨了如何利用Mixly构建计数器的基本逻辑和实现其高级功能。首先,文章简要介绍Mixly和1602液晶屏的特性,并说明了如何在Mixly环境下
高级技巧:利用Python和OpenCV优化摄像头设置

# 摘要
随着数字监控系统的普及,摄像头设置优化和智能摄像头系统的构建变得日益重要。本文首先介绍摄像头设置优化的基础概念,并概述Python编程和OpenCV库的相关知识。接着,详细讨论了摄像头图像捕获与处理技术,包括流数据捕获和图像预处理。此外,本文还深入探讨了摄像头设置的高级调整,如调整参数、场景优化和图像质量增强。最后,通过实践项目
【HDMI 2.1背后的科学】:深入理解动态HDR和eARC如何带来视觉震撼

# 摘要
HDMI 2.1作为一种先进的多媒体接口技术,不仅增强了原有HDMI标准的特性,还在动态HDR、eARC音频传输等方面引入了创新。本文首先概述了HDMI 2.1的技术背景及其理论基础,然后深入探讨了其在实际应用中的配置、优化以及对显示和音频效果的提升。通过分析动态HDR和eARC的实际效果,本文展示了HDMI 2.1如何提供前所未有的视觉和听觉体验。最后
DLT645-1997兼容性探析:确保通讯协议无缝对接

# 摘要
DLT645-1997协议作为电力行业广泛使用的通信协议,其稳定性和互操作性对智能电网数据交换至关重要。本文首先概述了DLT645-1997协议的基本概念和理论基础,分析了其协议结构、数据封装机制和应用层交互方式。接着,文章深入探讨了兼容性实践应用,包括测试环境的搭建、案例分析以及调试和优
【Turbo PMAC2软件配置实战手册】:掌握软件设置与调试的秘诀

# 摘要
本文系统地介绍了Turbo PMAC2软件的安装、配置、调试、自定义开发、网络通信设置以及维护与故障排除等方面的详细步骤和技巧。通过对硬件接口、软件参数、运动控制、通讯调试、安全特性、用户程序编写、网络通信安全等关键功能的深入分析,为自动化控制领域的专业人员提供了一套完整的指导方案。文中还提供了实际应用案例,帮助读者更好地理解理论与实践的结合,同时提供了故障诊断和排
H3C R4900G3服务器故障诊断大全:硬件篇快速解决方案
# 摘要
本文深入探讨了H3C R4900G3服务器的硬件架构及其故障诊断与维护策略。首先对服务器硬件进行了概览,包括硬件架构和常见组件的详细介绍。接着详细分析了硬件故障的分类、识别和诊断流程,提供了基于实践的案例分析,揭示了内存、CPU等常见故障的诊断和处理方法。此外,文章还强调了硬件维护的最佳实践和优化措施,旨在提升服务器稳定性和性能。最后,文章总结了故障诊断的技巧,并展望了未来服务器硬件技术的发展趋势,特别是新技术的应用和挑战。
# 关键字
服务器硬件架构;硬件故障诊断;故障维护;性能优化;硬件升级;技术趋势
参考资源链接:[H3C R4900G3服务器用户手册:安装与维护指南](h
系统部署高效化:AMI BIOS网络引导设置策略

# 摘要
随着信息技术的不断进步,AMI BIOS作为计算机系统的基础组件,在网络引导技术中的作用日益凸显。本文全面介绍了AMI BIOS网络引导的原理、基础设置、高级策略、实践应用及进阶定制。详细解读了BIOS基础配置、网络引导选项以及预启动执行环境(PXE)的配置方法,并深入探讨了网络引导的安全机制、多环境管理、故障排除与调试。通过系统部
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )