【Go代码剖析与优化】:编写极致高效代码的秘诀
发布时间: 2024-10-23 06:39:29 阅读量: 31 订阅数: 36 
# 1. Go语言基础和编译原理
Go语言,又称Golang,是由Google开发的一种静态类型、编译型、并发型,并具有垃圾回收功能的编程语言。Go语言的基础语法简洁,易于学习,这使得它在短时间内迅速获得了广泛的关注和应用。
Go语言的编译过程包括词法分析、语法分析、类型检查、语义分析、中间代码生成、机器代码生成和链接等步骤。在这个过程中,编译器将源代码转换为计算机能够理解的机器代码。这个过程的深入理解,可以帮助我们更好地优化我们的代码,提高程序的运行效率。
本章我们将首先介绍Go语言的基本语法,然后深入探讨其编译过程,帮助读者理解Go语言的工作原理,为进一步的并发模型学习和性能优化打下坚实的基础。
# 2. Go语言的并发模型和性能优化
## 2.1 Go语言的并发模型
### 2.1.1 Goroutine的基本概念和使用
Go语言的并发模型基于CSP(Communicating Sequential Processes)理论,其中Goroutine是Go语言并发编程的核心。Goroutine是一种轻量级线程,由Go运行时管理。与操作系统线程相比,Goroutine的创建和销毁成本较低,它们的内存占用也较少,这使得在Go程序中可以轻松创建数以千计甚至更多的并发任务。
在Go中,启动一个Goroutine非常简单,只需在调用函数前加上`go`关键字。例如,以下代码段展示了如何启动一个Goroutine来执行函数`hello`:
```go
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
go hello() // 在后台运行hello函数
fmt.Println("Hello main!")
}
```
这段代码会几乎同时输出两行内容,因为`hello()`函数被封装在一个Goroutine中并异步运行。主函数`main()`的执行不会等待`hello()`的完成。
### 2.1.2 Channel的使用和原理
Channel是Go语言并发模型中用于进行Goroutine间通信的同步原语。通过Channel,Goroutines可以安全地共享数据,并且保证数据的一致性和线程安全。
创建Channel使用`make`函数,如`ch := make(chan int)`。发送和接收数据通过`<-`操作符完成,例如:
```go
ch := make(chan int)
ch <- 100 // 向channel发送数据
value := <-ch // 从channel接收数据
```
Channel可以是无缓冲的,也可以是有缓冲的。无缓冲的Channel在发送和接收数据时,必须有另一个Goroutine在等待的对端进行配合,否则会阻塞。有缓冲的Channel则允许在缓冲区未满时进行发送,未空时进行接收,减少了Goroutine的等待时间。
### 2.1.3 Sync包的使用和注意事项
`sync`包提供了互斥锁(`sync.Mutex`)、读写锁(`sync.RWMutex`)、信号量(`sync.WaitGroup`)等多种同步机制,用于在并发环境中保护共享资源,避免竞态条件。
- `sync.Mutex`和`sync.RWMutex`用于控制对共享资源的互斥访问。`sync.Mutex`提供了锁定和解锁功能,而`sync.RWMutex`提供了读写锁功能,允许多个Goroutine同时读取共享资源。
- `sync.WaitGroup`用于等待一组Goroutine完成执行。通过调用`WaitGroup.Add()`方法来声明需要等待的Goroutine数量,每个Goroutine执行完毕后通过`WaitGroup.Done()`来通知,主Goroutine通过`WaitGroup.Wait()`方法等待所有Goroutine完成。
使用这些同步原语时,需要特别注意避免死锁和资源竞争。死锁通常是由于锁的顺序不一致,或者在持有锁时进行阻塞操作而产生。资源竞争则是由于多个Goroutine同时对同一资源进行读写而引起的。
## 2.2 Go语言的性能优化
### 2.2.1 内存优化方法
Go语言运行时对内存管理做了很多优化,比如高效的内存分配器、垃圾回收机制等。即便如此,在高性能场景下,开发者仍需注意内存使用情况,以提高程序性能。
内存优化通常包括减少内存分配、减少内存碎片和优化数据结构等方面:
- 减少内存分配可以使用`sync.Pool`来重用临时对象,或者尽量使用指针避免拷贝。
- 减少内存碎片可以通过合理设置`runtime.GOMAXPROCS`参数来减少线程的数量,降低内存使用频率。
- 在数据结构优化方面,可以使用内联结构体、利用切片的容量避免不必要的内存拷贝等方式。
### 2.2.2 CPU优化方法
CPU优化主要目标是减少计算延迟和提高CPU利用率。在Go语言中,一些常见的CPU优化方法包括:
- 并行执行:对于可以独立计算的多个任务,可以使用`runtime.GOMAXPROCS`和`runtime.NumCPU`来控制并行执行的Goroutines数量,充分利用CPU资源。
- 循环优化:优化循环中的条件判断,减少分支预测失败的概率,例如使用循环展开技术来减少循环次数。
- 利用Go编译器优化:Go编译器会进行一系列优化,如死码消除、常量折叠等。合理编写代码,可以充分利用编译器优化。
### 2.2.3 并发优化方法
Go语言的并发性能十分优秀,但开发者仍然需要理解并发模型,并做出相应的性能优化:
- 控制并发粒度:通过设置`runtime.GOMAXPROCS`来控制同时运行的Goroutine数量,平衡并发和上下文切换成本。
- 使用Channel避免锁:在多Goroutine间使用Channel进行通信,比直接使用锁更为高效。
- 使用并发原语:合理使用`sync.WaitGroup`、`sync.Mutex`等并发原语,避免因等待阻塞而浪费CPU资源。
## 2.3 Go语言并发模型的性能测试与分析
为了更好地理解Go语言并发模型的性能,我们需要执行一系列的测试。我们可以通过并发执行大量任务,比较在不同并发级别下的执行效率。这可以通过创建不同数量的Goroutine来模拟并发,并使用`sync.WaitGroup`同步它们的完成。
测试时,我们可以使用Go的`testing`包来编写基准测试,它提供了一系列用于性能测试的工具。此外,使用`pprof`包可以对运行中的程序进行性能分析,识别性能瓶颈。通过这些性能测试和分析,我们可以得出并发模型在实际场景中的效率表现,并据此进行优化。
下面是一个简单的基准测试示例,用于比较不同并发级别下的执行效率:
```go
func BenchmarkGoroutine(b *testing.B) {
for i := 0; i < b.N; i++ {
// 创建多个goroutine并发执行任务
go func() {
// 执行一些任务
}()
}
}
```
在基准测试结果中,我们需要关注的主要指标包括执行时间、内存分配和CPU占用等,这些指标将帮助我们评估并发模型的性能,并指导我们做出相应的优化。
通过性能测试,我们可以发现,增加Goroutine数量会提升并发处理能力,但当Goroutine的数量超过CPU核心数时,由于上下文切换的开销,性能可能开始下降。因此,合理控制并发级别是优化性能的关键。
通过本章节的介绍,我们详细探讨了Go语言的并发模型及其性能优化方法。在下一章节中,我们将进一步深入探讨Go语言的高级特性,如反射机制、接口以及错误处理等,并分析它们在实际应用中的性能影响与优化策略。
# 3. Go语言的高级特性
## 3.1 Go语言的反射机制
### 3.1.1 反射的基本概念和使用
在Go语言中,反射(Reflection)是一种强大的机制,它允许程序在运行时检查、修改和动态调用变量和函数的能力。这种特性对于那些需要在运行时解析类型信息的场景特别有用,例如处理不同的数据格式、编写通用的数据处理代码等。
反射的主要用途在于,当类型信息在编译时是未知的,或者类型信息经常变化时,我们可以通过反射来编写更加灵活的代码。反射包(reflect)是Go语言标准库的一部分,它提供了访问和修改运行时类型信息的能力。
反射包中最为关键的两个类型是`reflect.Type`和`reflect.Value`。其中`reflect.Type`代表类型,而`reflect.Value`代表可以设置和获取值的变量。
使用反射,我们可以通过`reflect.TypeOf()`函数获取一个值的类型信息,通过`reflect.ValueOf()`函数获取该值的`reflect.Value`表示。例如:
```go
package main
import (
"fmt"
"reflect"
)
func main() {
var x float64 = 3.4
t := reflect.TypeOf(x)
v := reflect.ValueOf(x)
fmt.Println("type:", t)
fmt.Println("value:", v)
}
```
以上代码将

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Go性能优化技巧》专栏旨在为Go开发者提供全面的性能优化指南。从入门到精通,专栏涵盖了Go语言性能优化的各个方面,包括并发编程、垃圾回收、编译器优化、性能测试、网络编程、数据结构选择、运行时性能分析、异步编程、锁机制、错误处理、代码剖析、反射开销、内联优化、热代码路径优化、异步IO操作、尾递归优化、逃逸分析和堆内存优化。通过深入的分析、实用技巧和最佳实践,该专栏帮助开发者打造极致高效的Go程序,提升应用程序性能,并充分利用Go语言的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
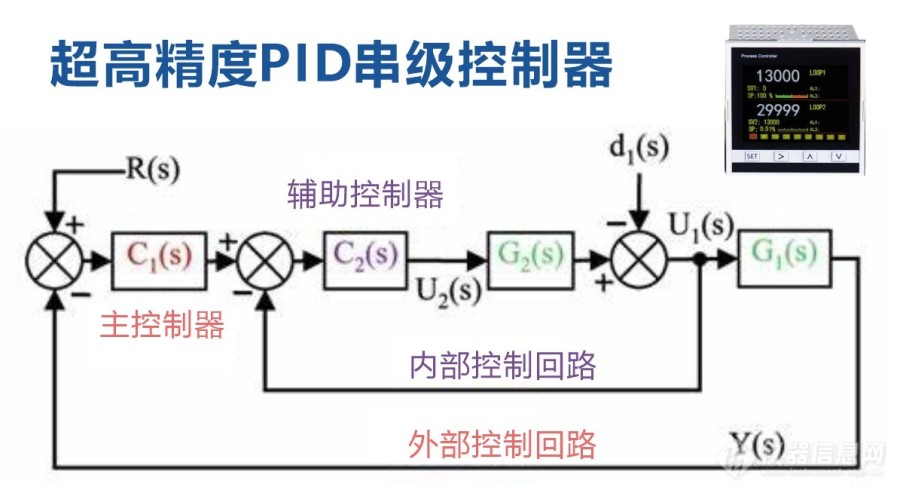
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )