Go语言错误处理的微服务视角:分布式系统中高效错误管理的秘诀(高级指南)
发布时间: 2024-10-20 14:39:25 阅读量: 2 订阅数: 4 

# 1. 微服务架构与错误处理
在现代软件开发中,微服务架构已经成为构建大型复杂系统的一种流行方式。微服务通过将系统拆分成一系列小服务,为快速迭代、独立部署和扩展性提供了便利。然而,随着系统组件的增多,错误处理成为了维护系统稳定性的关键挑战之一。在本章中,我们将探讨微服务架构中的错误处理的重要性,分析常见的错误传播模式,并且提出有效的错误处理策略和最佳实践。此外,我们还将深入介绍Go语言在微服务错误处理领域的应用,包括其内建的错误处理机制以及在分布式系统中如何利用Go进行错误管理和监控。最终,我们将提出一些能够帮助IT专业人士提升其错误处理能力的高级技巧和策略。
# 2. Go语言错误处理机制
## 2.1 Go的错误模型
### 2.1.1 错误类型及其比较
Go语言中错误处理的一个核心概念是错误接口`error`,它是一个内置的接口类型,定义如下:
```go
type error interface {
Error() string
}
```
任何实现了`Error() string`方法的类型都可以被当作一个错误值。在Go的标准库和第三方库中,最常见的错误类型有:
- `fmt.Errorf`返回的格式化错误。
- `os.PathError`和`os.LinkError`,与系统调用有关的错误,包含错误发生时的路径或链接信息。
- `net.Error`,网络编程中使用的错误接口,用于提供关于网络故障的更多信息。
在Go中,错误通常用值比较来判断是否相等。例如,可以使用`errors.Is()`函数比较错误是否为特定类型,或者是否与特定错误值相等。
```go
import "errors"
// ...代码省略...
err := fmt.Errorf("some error")
if errors.Is(err, io.EOF) {
// 处理EOF错误
}
```
在错误比较时,有时候需要处理错误链中的错误,`errors.As()`函数可以帮助我们检查错误链中的错误是否为特定类型,这对于深入挖掘错误的原因非常有帮助。
### 2.1.2 错误处理的最佳实践
在Go中,错误处理遵循几个核心的最佳实践:
- **及时返回错误**:在函数中发现错误应立即返回,不要尝试继续执行可能受影响的后续操作。
- **不要忽略错误**:尤其是在重要的业务逻辑中,忽略错误可能会导致隐藏的bug和数据不一致。
- **提供有用的错误信息**:创建自定义错误时,确保错误信息能够说明问题所在,而不是仅仅返回一个模糊的错误字符串。
- **使用错误链**:将底层错误包装在更高级别的上下文中,例如使用`fmt.Errorf`时附加`%w`格式动词,以保持错误链的完整性。
```go
if err := someOperation(); err != nil {
return fmt.Errorf("operation failed: %w", err)
}
```
## 2.2 Go的panic和recover
### 2.2.1 panic的作用和使用场景
`panic`是Go中的一个内置函数,用于在程序中抛出一个运行时异常。它会立即停止当前函数的执行,并且沿着调用栈向上传播,直到遇到`recover`或者程序终止。通常,`panic`用于处理无法恢复的错误,如编程逻辑错误,或资源状态不允许继续操作的情况。
```go
func riskyOperation() {
panic("something went wrong")
}
func main() {
riskyOperation()
// 任何在此函数中的代码都不会执行
}
```
使用`panic`应当非常谨慎,它应当作为最后的手段,仅在发生不可修复的错误时使用。滥用`panic`会使程序难以调试和维护。
### 2.2.2 recover的机制与策略
`recover`是另一个Go的内置函数,用于恢复`panic`导致的程序崩溃。`recover`必须在被延迟执行的函数中调用,即`defer`语句中。如果在普通的执行路径中调用`recover`,它将返回`nil`并且没有任何效果。
```go
func main() {
defer func() {
if r := recover(); r != nil {
// 恢复后进行错误处理
log.Println("Recovered from panic:", r)
}
}()
riskyOperation()
fmt.Println("This line will not execute")
}
```
在实际的程序中,应当设计`recover`来处理特定的`panic`情况,而不是广泛地捕获所有可能的`panic`。合理的策略包括记录日志、进行资源清理等。
## 2.3 错误上下文的增强
### 2.3.1 错误信息的丰富和格式化
为了使错误信息更具上下文,可以在返回错误时附加更多有用的信息,以帮助定位问题。这可以通过组合错误值来完成,例如使用`fmt.Errorf`结合`%v`和`%w`格式动词,将信息与错误值一起返回。
```go
if err := validateInput(input); err != nil {
return fmt.Errorf("invalid input: %v, details: %w", input, err)
}
```
此外,可以使用第三方库如`***/pkg/errors`,它提供更丰富的错误处理功能,比如错误包装和错误堆栈。
### 2.3.2 栈追踪信息的提取和使用
Go提供了`runtime`包来提取和打印当前的调用栈信息。`runtime.Caller()`和`runtime.FuncForPC()`函数可以用来获取调用栈上的位置信息。这些功能对于调试和日志记录非常有用。
```go
import (
"runtime"
"log"
)
func printStack() {
pc, file, line, ok := runtime.Caller(1)
if !ok {
log.Fatal("Not able to get caller information")
}
funcDetails := runtime.FuncForPC(pc)
log.Printf("Function Name: %s File Name: %s Line Number: %d", funcDetails.Name(), file, line)
}
```
通过这种方式,可以在错误处理中加入栈追踪信息,帮助开发者快速定位问题源头。
这一章节中通过探讨Go的错误模型、panic和recover的正确使用,以及如何增强错误上下文信息,为读者呈现了Go语言错误处理的核心要素。接下来,章节将深入到分布式系统中错误处理的复杂性。
# 3. 分布式系统中的错误传播
在分布式系统中,错误传播是一个复杂的问题,因为系统由多个服务组成,这些服务可能会出现故障。正确处理错误传播不仅对于提高系统的可靠性至关重要,而且也是实现服务质量保证的基础。本章我们将探讨服务间错误传递的模式、跨服务错误日志追踪以及分布式事务与补偿机制。
## 服务间错误传递的模式
在微服务架构中,服务间通信是通过API或消息队列来实现的。如何在服务间正确传递错误信息对于整个系统的表现和用户的体验都有很大影响。
### HTTP状态码的使用
HTTP协议为错误处理提供了丰富的状态码来指示不同的错误类型。例如:
- `400 Bad Request`:客户端请求有语法错误,不能被服务器理解。
- `401 Unauthorized`:请求未经授权,需要提供认证信息。
- `403 Forbidden`:服务器理解请求但拒绝执行。
- `404 Not Found`:资源未找到。
- `500 Internal Server Error`:服务器遇到错误,无法完成请求。
服务之间应该约定一套清晰的状态码使用规则,以便于错误的传递和处理。例如,可以根据业务需求定义一系列的自定义状态码来表示特定的业务错误。
### 自定义错误响应的策略
除了标准的HTTP状态码之外,当遇到特定的业务错误时,可以使用自定义的错误响应。这通常包括错误代码、错误消息以及可能的解决方案或进一步的指导。
```json
{
"error": {
"code": 1001,
"message": "Invalid account number provided",
"suggestion": "Please check the account number and try again."
}
}
```
在上例中,我们定义了一个包含错误代码、消息和建议的JSON响应体。这样,客户端可以更准确地识别问题,并提供相应的用户反馈。
## 跨服务错误日志追踪
在微服务架构中,服务间往往通过消息队列或API网关进行通信。为了有效地诊断问题,需要跨服务进行错误日志追踪。
### 日志聚合与分布式追踪系统
日志聚合系统(如ELK Stack)可以帮助我们将分散在各个服务中的日志收集起来,进行统一管理和分析。然而,当服务数量增加时,传统的日志分析方法可能会变得低效。
分布式追踪系统(如Jaeger或Zipkin)能够提供请求的完整调用链路,帮助开发者了解请求在各个服务间的流转路径,以及在何处发生了错误。
### 实践:使用OpenTelemetry进行日志追踪
OpenTelemetry是一个开放源代码的观测性框架,用于收集分布式系统中的监控数据和日志。通过使用OpenTelemetry,开发者可以轻松地从服务中收集日志信息,并将其与其他观测数据关联起来。
```go
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp"
)
func main() {
// 初始化OpenTelemetry追踪器
exp, err := otlptracehttp.New(context.Background())
if err != nil {
log.Fatal(err)
}
otel.SetTracerProvider(otel.NewTracerProvider(
otel.
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Go 语言中的错误处理,提供了全面的指南和最佳实践。它涵盖了 error interface 的本质、错误链处理、异常处理策略、自定义错误类型、错误转换、边界情况、性能优化、最新特性、错误哲学、案例分析、模式、微服务视角、稀缺资源、测试和实用技巧。通过这些内容,读者可以全面了解 Go 语言的错误处理机制,并掌握构建清晰、健壮和可维护的代码所需的关键知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java枚举与泛型】:打造灵活可扩展的枚举类型
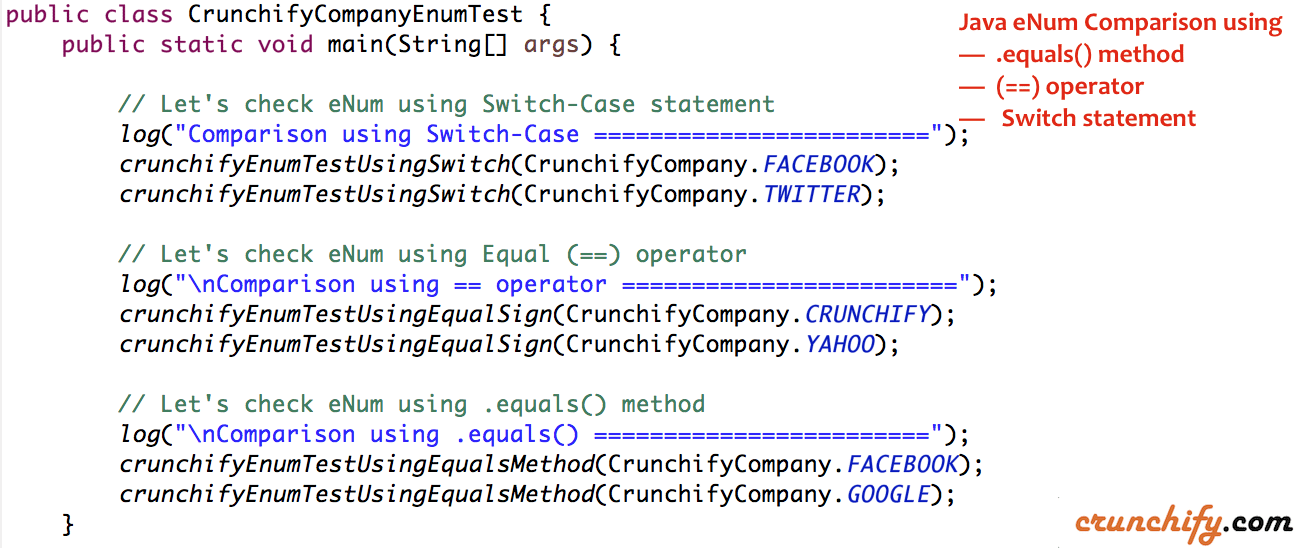
# 1. Java枚举与泛型基础
Java 枚举类型(enum)和泛型是语言中两种强大的特性,它们允许开发者以更加类型安全和可维护的方式来编写代码。在本章中,我们将首先探索枚举和泛型的基本概念,为深入理解它们在实际应用中的高级用法打下坚实的基础。
## 1.1 枚举和泛型的定义
枚举是
单页应用开发模式:Razor Pages SPA实践指南
# 1. 单页应用开发模式概述
## 1.1 单页应用开发模式简介
单页应用(Single Page Application,简称SPA)是一种现代网页应用开发模式,它通过动态重写当前页面与用户交互,而非传统的重新加载整个页面。这种模式提高了用户体验,减少了服务器负载,并允许应用以接近本地应用程序的流畅度运行。在SPA中,所有必要的数据和视图都是在初次加载时获取和渲染的,之后通过JavaScript驱动的单页来进行数据更新和视图转换。
## 1.2 SPA的优势与挑战
SPA的优势主要表现在更流畅的用户交互、更快的响应速度、较低的网络传输量以及更容易的前后端分离等。然而,这种模式也面临
Blazor第三方库集成全攻略
# 1. Blazor基础和第三方库的必要性
Blazor是.NET Core的一个扩展,它允许开发者使用C#和.NET库来创建交互式Web UI。在这一过程中,第三方库起着至关重要的作用。它们不仅能够丰富应用程序的功能,还能加速开发过程,提供现成的解决方案来处理常见任务,比如数据可视化、用户界面设计和数据处理等。Blazor通过其独特的JavaScript互操作性(JSInterop)功能,使得在.NET环境中使用JavaScript库变得无缝。
理解第三方库在Blazor开发中的重要性,有助于开发者更有效地利用现有资源,加快产品上市速度,并提供更丰富的用户体验。本章将探讨Blazor的
【C++编程高手之路】:从编译错误到优雅解决,SFINAE深入研究
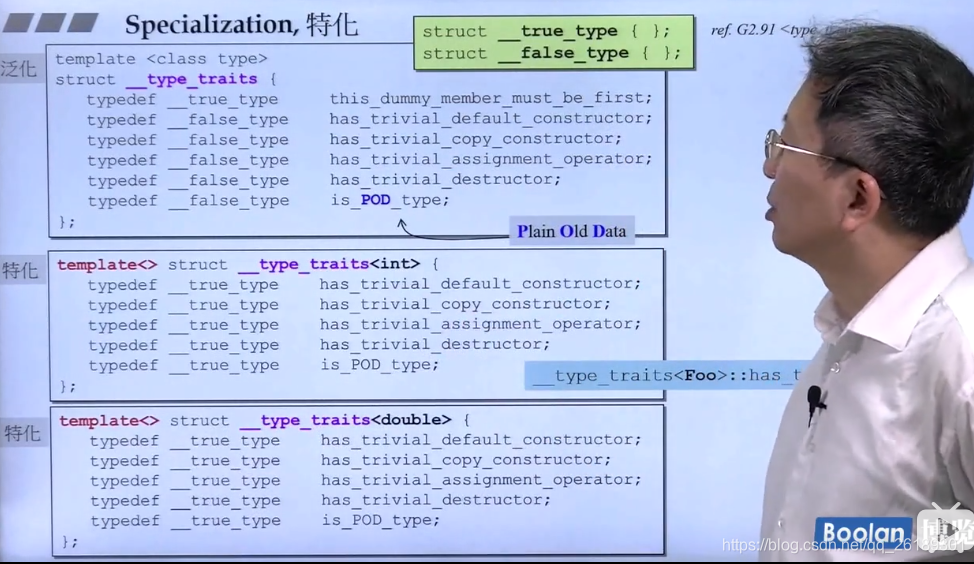
# 1. C++编译错误的剖析与应对策略
在深入探讨SFINAE之前,首先了解C++编译错误的剖析与应对策略是
构建高效率UDP服务器:Go语言UDP编程实战技巧与优化
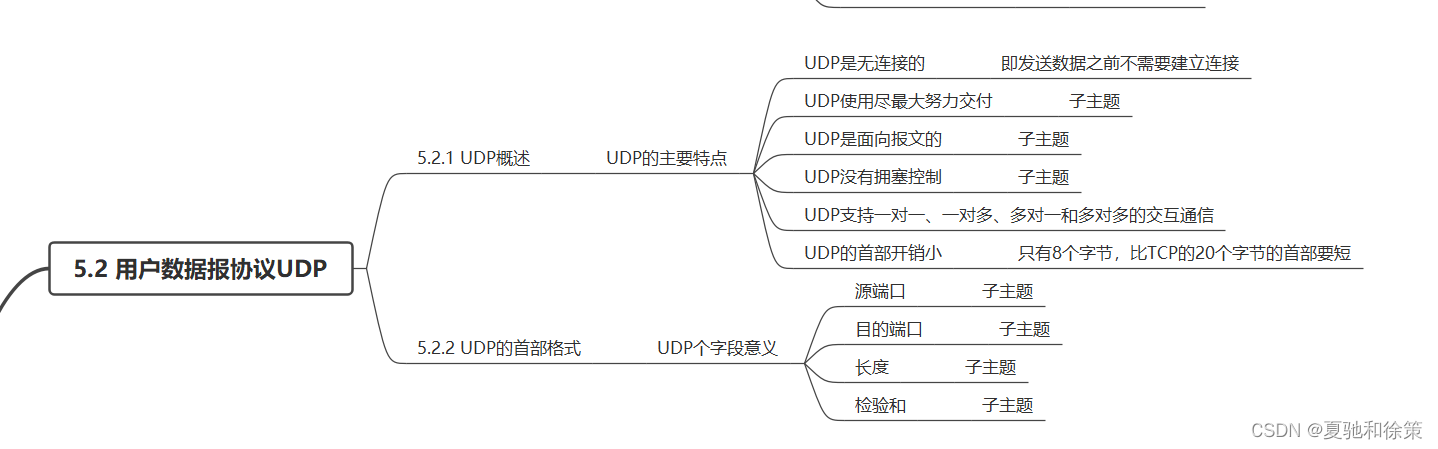
# 1. UDP服务器的基础概念与Go语言网络编程入门
## 1.1 互联网协议简介
在互联网中,数据传输是通过IP协议完成的,而UDP(User Datagram Protocol)是IP协议的上层协议之一。UDP是一种无连接的网络协议,它允许数据包在网络中独立传输,不保证顺序或可靠性。与TCP(Transmission Control Protocol)相比,UDP因其低延迟和低开销的特性,特别
深入探索C++模板:元编程中的编译器技巧与限制,破解编译时间的秘籍

# 1. C++模板与元编程概述
## 模板编程的起源与定义
C++模板编程起源于20世纪80年代,最初是为了实现泛型编程(generic programming)而设计的。模板作为一种抽象机制,允许开发者编写与数据类型无关的代码,即能够在编译时将数据类型作为参数传递给模板
Java Properties类:错误处理与异常管理的高级技巧
# 1. Java Properties类概述与基础使用
Java的`Properties`类是`Hashtable`的子类,它专门用于处理属性文件。属性文件通常用来保存应用程序的配置信息,其内容以键值对的形式存储,格式简单,易于阅读和修改。在本章节中,我们将对`Properties`类的基本功能进行初步探索,包括如何创建`Properties`对象,加载和存储
【Go网络编程高级教程】:net包中的HTTP代理与中间件

# 1. Go语言网络编程基础
## 1.1 网络编程简介
网络编程是构建网络应用程序的基础,它包括了客户端与服务器之间的数据交换。Go语言因其简洁的语法和强大的标准库在网络编程领域受到了广泛的关注。其`net`包提供了丰富的网络编程接口,使得开发者能够以更简单的方式进行网络应用的开发。
##
C++概念(Concepts)与类型萃取:掌握新接口设计范式的6个步骤

# 1. C++概念(Concepts)与类型萃取概述
在现代C++编程实践中,类型萃取和概念是实现高效和类型安全代码的关键技术。本章节将介绍C++概念和类型萃取的基本概念,以及它们如何在模板编程中发挥着重要的作用。
## 1.1 C++概念的引入
C++概念(Concepts)是在C++20标准中引入的一种新的语言特性,它允许程序员为模板参数定义一组需求,从而
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )