Python库文件学习之Paste:高级技巧
发布时间: 2024-10-13 07:07:18 阅读量: 24 订阅数: 31 

python词汇.docx

# 1. Paste库的基本概念和安装
在本章中,我们将介绍Paste库的基本概念,并指导您如何安装它。Paste是一个轻量级的Python库,主要用于Web应用的开发。它是WSGI兼容的,因此可以与任何遵循WSGI标准的Web框架和服务器进行交互。
## Paste库的基本概念
Paste是一个基于Python的Web开发框架,它提供了许多工具来简化Web应用的开发和部署过程。它包括一个开发服务器、一个代理服务器,以及一些实用工具函数,如请求和响应对象的抽象、中间件支持等。
## 安装Paste库
安装Paste库非常简单,您可以使用pip工具进行安装。打开终端或命令提示符,然后输入以下命令:
```bash
pip install Paste
```
安装完成后,您就可以开始使用Paste库的功能了。在下一章中,我们将深入探讨Paste库的核心组件,包括Request和Response对象以及中间件的概念。
# 2. Paste库的核心组件
## 2.1 Paste库的Request对象
### 2.1.1 Request对象的创建和属性
在本章节中,我们将深入了解Paste库中的Request对象。Request对象是Paste库的核心组件之一,它代表了客户端的请求信息。我们可以通过创建Request对象来访问请求中的各种数据,例如请求头、请求体、查询参数等。
Request对象的创建通常是通过Paste的请求处理流程自动完成的,不需要手动创建。当一个HTTP请求到达Paste应用时,Paste会自动解析请求并创建一个Request对象,开发者可以直接在中间件或视图函数中接收这个对象。
Request对象包含许多属性,其中最重要的有以下几个:
- `environ`: 一个WSGI环境字典,包含了请求的所有信息。
- `path`: 请求的路径部分。
- `method`: 请求的方法,如`GET`或`POST`。
- `headers`: 请求头的字典。
- `body`: 请求体的内容。
### 2.1.2 Request对象的使用方法
在本章节介绍中,我们将通过示例代码展示如何使用Request对象的方法和属性。
#### 示例代码:使用Request对象
```python
from paste.request import Request
def my_view(request):
# 访问请求方法
method = request.method
# 访问请求路径
path = request.path
# 访问请求头
user_agent = request.headers.get('User-Agent')
# 访问请求体
body = request.body
# 打印请求信息
print(f"Method: {method}\nPath: {path}\nUser-Agent: {user_agent}\nBody: {body}")
# 假设这是WSGI环境
environ = {
'REQUEST_METHOD': 'GET',
'PATH_INFO': '/example',
'HTTP_USER_AGENT': 'Mozilla/5.0 (compatible; ExampleBot/1.0; +***',
'wsgi.input': StringIO('Hello, World!')
}
request = Request(environ)
my_view(request)
```
#### 参数说明
- `environ`: 一个WSGI环境字典,包含了请求的所有信息。
- `path`, `method`, `headers`, `body`: 分别代表请求的路径、方法、头部和请求体。
#### 代码逻辑解读
1. 我们首先从`paste.request`模块导入了`Request`类。
2. 定义了一个视图函数`my_view`,它接收一个Request对象作为参数。
3. 在函数内部,我们通过Request对象的属性访问了请求的方法、路径、用户代理和请求体。
4. 最后,我们将请求信息打印出来。
#### 执行逻辑说明
当你运行这段代码时,它会模拟一个简单的WSGI环境,并创建一个Request对象。然后,它将请求的信息打印到控制台。
#### 结构化内容展示
下面是一个表格,展示了Request对象的主要属性和方法:
| 属性/方法 | 描述 |
| --------- | ----------- |
| `environ` | WSGI环境字典,包含请求的所有信息 |
| `path` | 请求的路径部分 |
| `method` | 请求的方法,如`GET`或`POST` |
| `headers` | 请求头的字典 |
| `body` | 请求体的内容 |
| `.get_header(name)` | 获取指定名称的请求头 |
| `.cookie(name)` | 获取指定名称的Cookie |
通过本章节的介绍,你应该对Paste库中的Request对象有了基本的了解。在下一小节中,我们将探讨Response对象的创建和属性。
# 3. Paste库的高级应用
## 3.1 Paste库的路由功能
### 3.1.1 路由的基本概念和实现
路由是Web应用中用于处理客户端请求的机制。在Paste库中,路由功能允许开发者将不同的URL路径映射到相应的处理函数上。这一功能是通过创建路由规则实现的,这些规则指定了当收到特定路径的请求时,应该调用哪个函数来处理这些请求。
```python
from paste import httpserver
from paste.urlmap import URLMap
# 定义处理函数
def hello_world(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b"Hello, world!"]
# 创建URL映射规则
urlmap = URLMap()
urlmap.connect('root', '/', handler=hello_world, name='home')
# 启动服务器
httpserver.serve(urlmap, host='localhost', port='8080')
```
在上述代码中,我们定义了一个简单的处理函数`hello_world`,它会返回一个文本响应。然后我们创建了一个`URLMap`对象,并通过`connect`方法添加了一个路由规则,该规则将根URL(`'/'`)映射到`hello_world`函数。最后,我们启动了一个HTTP服务器,并将其与我们的路由规则关联。
### 3.1.2 路由的高级配置和优化
随着应用的复杂度增加,仅仅使用简单的路由规则可能不足以满足需求。Paste库提供了高级路由配置选项,包括正则表达式匹配、带变量的路由以及权重选择等。
```python
from paste import httpserver
from paste.urlmap import URLMap
from paste.urlmap import Rule
# 定义处理函数
def user_profile(environ, start_response):
user_id = environ['PATH_INFO'].strip('/')
start_response('200 OK', [('Content-Type', 'text/plain')])
return [f"Profile page for user {user_id}".encode()]
# 创建带有变量的URL映射规则
urlmap = URLMap()
urlmap.add(Rule(r'/user/(?P<user_id>\d+)/', handler=user_profile, name='profile'))
# 启动服务器
httpserver.serve(urlmap, host='localhost', port='8080')
```
在这个例子中,我们使用了正则表达式定义了一个带有变量的路由规则。`(?P<user_id>\d+)`是一个正则表达式,它匹配一个或多个数字并将它们作为`user_id`传递给`user_profile`函数。这种方式使得我们能够创建更加动态的URL模式。
### 3.1.3 路由的性能优化
路由性能优化通常涉及到减少查找时间和减少规则数量。在Paste库中,可以使用更高效的数据结构来存储路由规则,例如字典树(Trie)。
```python
from paste.urlmap import URLMap, Rule
# 创建一个字典树结构的路由映射
trie = URLMap()
# 添加规则到字典树结构的路由映射
# ... 添加规则的代码 ...
# 启动服务器
httpserver.serve(trie, host='localhost', port='8080')
```
在这个例子中,我们创建了一个使用字典树结构的`URLMap`对象。这可以显著提高查找路由规则的速度,特别是在有大量的路由规则时。
## 3.2 Paste库的模板引擎
### 3.2.1 模板引擎的基本原理和使用
模板引擎允许开发者将程序代码与HTML页面分离,使得Web页面的布局和逻辑可以被独立修改和维护。在Paste库中,模板引擎通常与路由功能结合使用,以生成动态响应内容。
```python
from paste import httpserver
from paste.templating import TemplatingMiddleware
# 定义一个模板文件
templating = TemplatingMiddleware(
template_dir='templates',
default_extension='.pt'
)
# 创建一个处理函数,使用模板引擎
def hello_template(environ, start_response):
output = templating.render('hello.pt',
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“Python库文件学习之Paste”专栏是一个全面的指南,深入探讨了Paste库及其在Python开发中的应用。从入门基础到高级技巧,该专栏涵盖了广泛的主题,包括:
* Paste的基础概念和实践
* 高级技巧和案例分析
* 最佳实践和性能优化
* 自动化测试和源码分析
* 与其他库的比较和企业级应用
* 定制化开发和模块化设计
* 性能分析和调优
* 网络编程和数据处理
该专栏旨在帮助Python开发者充分利用Paste库,提高代码效率和应用程序性能。通过深入的讲解和丰富的示例,读者可以掌握Paste库的各个方面,并将其应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java代码审计核心教程】:零基础快速入门与进阶策略
-Concept-in-Java.webp)
# 摘要
Java代码审计是保障软件安全性的重要手段。本文系统性地介绍了Java代码审计的基础概念、实践技巧、实战案例分析、进阶技能提升以及相关工具与资源。文中详细阐述了代码审计的各个阶段,包括准备、执行和报告撰写,并强调了审计工具的选择、环境搭建和结果整理的重要性。结合具体实战案例,文章
【Windows系统网络管理】:IT专家如何有效控制IP地址,3个实用技巧

# 摘要
本文主要探讨了Windows系统网络管理的关键组成部分,特别是IP地址管理的基础知识与高级策略。首先概述了Windows系统网络管理的基本概念,然后深入分析了IP地址的结构、分类、子网划分和地址分配机制。在实用技巧章节中,我们讨论了如何预防和解决IP地址冲突,以及IP地址池的管理方法和网络监控工具的使用。之后,文章转向了高级
【技术演进对比】:智能ODF架与传统ODF架性能大比拼

# 摘要
随着信息技术的快速发展,智能ODF架作为一种新型的光分配架,与传统ODF架相比,展现出诸多优势。本文首先概述了智能ODF架与传统ODF架的基本概念和技术架构,随后对比了两者在性能指标、实际应用案例、成本与效益以及市场趋势等方面的不同。智能ODF架通过集成智能管理系统,提高了数据传输的高效性和系统的可靠性,同时在安全性方面也有显著增强。通过对智能ODF架在不同部署场景中的优势展示和传统ODF架局限性的分析,本文还探讨
化工生产优化策略:工业催化原理的深入分析
# 摘要
本文综述了化工生产优化的关键要素,从工业催化的基本原理到优化策略,再到环境挑战的应对,以及未来发展趋势。首先,介绍了化工生产优化的基本概念和工业催化理论,包括催化剂的设计、选择、活性调控及其在工业应用中的重要性。其次,探讨了生产过程的模拟、流程调整控制、产品质量提升的策略和监控技术。接着,分析了环境法规对化工生产的影响,提出了能源管理和废物处理的环境友好型生产方法。通过案例分析,展示了优化策略在多相催化反应和精细化工产品生产中的实际应用。最后,本文展望了新型催化剂的开发、工业4.0与智能化技术的应用,以及可持续发展的未来方向,为化工生产优化提供了全面的视角和深入的见解。
# 关键字
MIPI D-PHY标准深度解析:掌握规范与应用的终极指南
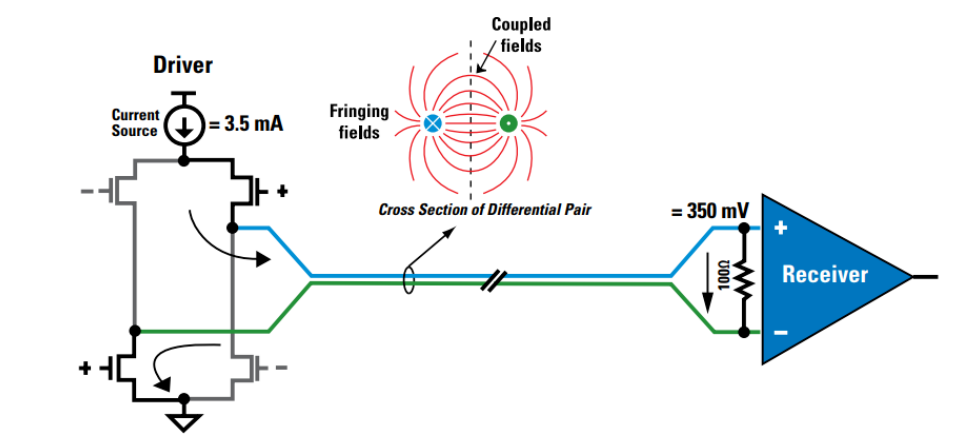
# 摘要
MIPI D-PHY作为一种高速、低功耗的物理层通信接口标准,广泛应用于移动和嵌入式系统。本文首先概述了MIPI D-PHY标准,并深入探讨了其物理层特性和协议基础,包括数据传输的速率、通道配置、差分信号设计以及传输模式和协议规范。接着,文章详细介绍了MIPI D-PHY在嵌入式系统中的硬件集成、软件驱动设计及实际应用案例,同时提出了性能测试与验
【SAP BASIS全面指南】:掌握基础知识与高级技能

# 摘要
SAP BASIS是企业资源规划(ERP)解决方案中重要的技术基础,涵盖了系统安装、配置、监控、备份、性能优化、安全管理以及自动化集成等多个方面。本文对SAP BASIS的基础配置进行了详细介绍,包括系统安装、用户管理、系统监控及备份策略。进一步探讨了高级管理技
【Talend新手必读】:5大组件深度解析,一步到位掌握数据集成
# 摘要
Talend是一款强大的数据集成工具,本文首先介绍了Talend的基本概念和安装配置方法。随后,详细解读了Talend的基础组件,包括Data Integration、Big Data和Cloud组件,并探讨了各自的核心功能和应用场景。进阶章节分析了Talend在实时数据集成、数据质量和合规性管理以及与其他工
网络安全新策略:Wireshark在抓包实践中的应用技巧

# 摘要
Wireshark作为一款强大的网络协议分析工具,广泛应用于网络安全、故障排除、网络性能优化等多个领域。本文首先介绍了Wireshark的基本概念和基础使用方法,然后深入探讨了其数据包捕获和分析技术,包括数据包结构解析和高级设置优化。文章重点分析了Wireshark在网络安全中的应用,包括网络协议分析、入侵检测与响应、网络取证与合规等。通过实
三角形问题边界测试用例的测试执行与监控:精确控制每一步

# 摘要
本文针对三角形问题的边界测试用例进行了深入研究,旨在提升测试用例的精确性和有效性。文章首先概述了三角形问题边界测试用例的基础理论,包括测试用例设计原则、边界值分析法及其应用和实践技巧。随后,文章详细探讨了三角形问题的定义、分类以及测试用例的创建、管理和执行过程。特别地,文章深入分析了如何控制测试环境与用例的精确性,并探讨了持续集成与边界测试整合的可能性。在测试结果分析与优化方面,本文提出了一系列故障分析方法和测试流程改进策略。最后,文章展望了边界
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )