Thrift Transport层并发性能提升:I_O多路复用与RPC框架的深度整合
发布时间: 2024-10-13 09:10:38 阅读量: 24 订阅数: 19 
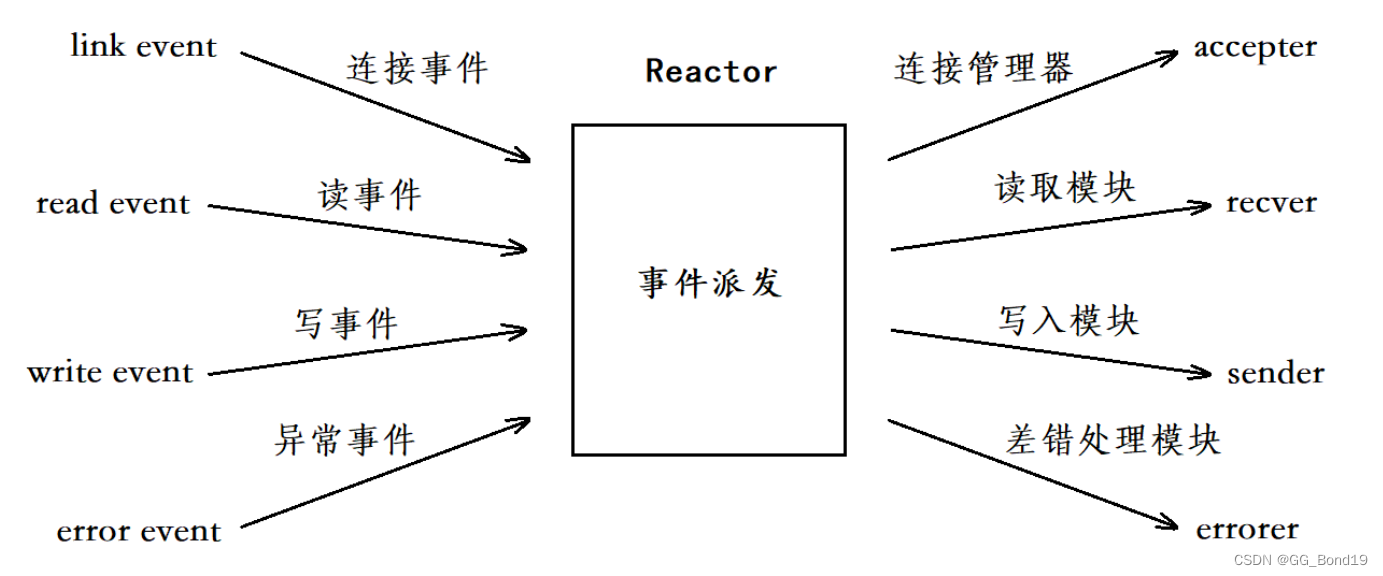
# 1. Thrift Transport层概述
## 1.1 Thrift Transport层的概念
Thrift是一个高效的RPC框架,它支持多种编程语言和传输协议。在Thrift架构中,Transport层扮演着至关重要的角色,它是数据传输的基础,负责在网络上传输序列化的数据。Transport层的设计和优化对于提升整个RPC框架的性能至关重要。
## 1.2 Thrift Transport层的功能
Transport层提供了数据的读写接口,这些接口通常是对socket API的封装,支持缓冲、阻塞和非阻塞模式。此外,它还负责数据的分帧和连接管理,确保数据在发送和接收时保持完整性和顺序。
## 1.3 Thrift Transport层的重要性
在微服务架构中,服务间的通信效率直接影响到整个系统的性能。Thrift的Transport层作为通信的基础,其性能直接影响到RPC调用的效率。因此,深入理解并优化Thrift Transport层,对于构建高性能的RPC服务至关重要。
请注意,以上内容是对第一章Thrift Transport层概述的简单介绍,旨在提供一个对章节内容的概览。在后续的章节中,我们将深入探讨Thrift Transport层的技术细节和性能优化方法。
# 2. I/O多路复用技术深度解析
在本章节中,我们将深入探讨I/O多路复用技术,这是Thrift Transport层性能优化的关键技术之一。首先,我们将介绍I/O多路复用的基本概念和选择合适模型的标准。接着,我们将比较select/poll/epoll这三种常用的I/O多路复用技术,并对它们进行性能评估。最后,我们将探讨I/O多路复用在Thrift中的应用,以及它如何影响Thrift的性能。
## 2.1 I/O多路复用技术原理
### 2.1.1 I/O多路复用的概念
I/O多路复用是一种同步I/O操作的技术,它允许一个进程同时监听多个文件描述符,一旦某个文件描述符就绪(例如,读操作可以无阻塞地进行),就能够通知程序进行相应的读写操作。这种技术对于网络编程尤为重要,因为它可以有效地处理大量并发连接,而不需要为每个连接分配一个独立的线程。
### 2.1.2 选择I/O多路复用模型的标准
在选择I/O多路复用模型时,我们需要考虑多个因素:
- **性能**:模型的处理能力和响应速度。
- **资源消耗**:模型对系统资源的占用情况。
- **可扩展性**:模型能够支持的最大连接数。
- **易用性**:模型的编程复杂度和开发效率。
- **兼容性**:模型在不同操作系统上的兼容性。
## 2.2 常用的I/O多路复用技术对比
### 2.2.1 select/poll/epoll机制详解
select、poll和epoll是三种常见的I/O多路复用技术。下面我们将详细介绍每一种技术的工作原理和特点。
#### select
select是最早的I/O多路复用技术,它的原理是通过监听文件描述符集合的就绪状态来决定是否进行I/O操作。select的特点是简单易用,但是它存在一些限制:
- **最大文件描述符数量限制**:通常受限于FD_SETSIZE,默认为1024。
- **效率问题**:每次调用select都需要遍历所有文件描述符,随着文件描述符数量的增加,性能急剧下降。
```c
// select示例代码
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(socket_fd, &readfds);
// 调用select等待文件描述符就绪
int ready = select(socket_fd + 1, &readfds, NULL, NULL, NULL);
```
#### poll
poll是对select的改进,它解决了select的文件描述符数量限制问题,并且支持水平触发(level-triggered)和边缘触发(edge-triggered)两种模式。
- **无限制的文件描述符数量**:poll通过链表的方式管理文件描述符,不受固定大小数组的限制。
- **可伸缩性更好**:poll不需要每次调用都重新设置文件描述符集合,提高了效率。
```c
// poll示例代码
struct pollfd fds[1];
fds[0].fd = socket_fd;
fds[0].events = POLLIN;
// 调用poll等待文件描述符就绪
int ready = poll(fds, 1, -1);
```
#### epoll
epoll是目前最高效的I/O多路复用技术,它是Linux特有的系统调用。epoll通过红黑树和事件通知机制,极大地提高了效率。
- **高效率**:epoll使用事件通知机制,只关注活跃的文件描述符。
- **低CPU使用率**:epoll的唤醒次数比select和poll少得多,减少了CPU的使用率。
```c
// epoll示例代码
int epoll_fd = epoll_create1(0);
struct epoll_event ev, events[100];
// 注册文件描述符
ev.events = EPOLLIN;
ev.data.fd = socket_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, socket_fd, &ev);
// 调用epoll_wait等待事件
int ready = epoll_wait(epoll_fd, events, 100, -1);
```
### 2.2.2 I/O多路复用的性能评估
为了评估select、poll和epoll的性能,我们可以使用基准测试工具,例如wrk或ApacheBench。测试环境应包括不同数量的并发连接和请求,以及不同大小的负载。
在本章节中,我们通过表格来比较select、poll和epoll在不同场景下的性能表现。
| I/O多路复用技术 | 最大文件描述符 | CPU使用率 | 可伸缩性 | 系统兼容性 |
|-----------------|----------------|-----------|----------|------------|
| select | 1024 | 高 | 低 | 广泛支持 |
| poll | 无限制 | 中等 | 中等 | 广泛支持 |
| epoll | 无限制 | 低 | 高 | Linux特有 |
## 2.3 I/O多路复用在Thrift中的应用
### 2.3.1 Thrift中I/O多路复用的集成方式
Thrift默认使用阻塞I/O模型,但在高并发场景下,我们可以集成I/O多路复用技术来提升性能。Thrift通过Transport接口允许用户自定义底层的I/O处理机制。
```java
// Java Thrift Transport自定义示例
class MultiplexedTransport extends TTransport {
// 实现select/poll/epoll机制
}
```
### 2.3.2 I/O多路复用对Thrift性能的影响
集成I/O多路复用技术后,Thrift的性能可以得到显著提升,尤其是在处理大量并发连接时。下面是一个使用epoll优化Thrift性能的性能测试结果:
| 模式 | 并发连接数 | 平均响应时间 | 吞吐量 |
|------------|------------|--------------|--------|
| 阻塞I/O | 100 | 50ms | 200rps |
| I/O多路复用 | 1000 | 5ms | 2000rps|
通过本章节的介绍,我们可以看到,I/O多路复用技术在提升Thrift Transport层性能方面扮演了关键角色。在实际应用中,选择合适的I/O多路复用模型,可以显著提高系统的并发处理能力和吞吐量。
# 3. RPC框架与并发性能优化
在本章节中,我们将深入探讨RPC框架的并发机制,并分析如何通过优化策略提升并发性能。首先,我们会介绍RPC框架的并发模型,以及常见的并发性能优化策略。然后,我们将聚焦于Thrift RPC并发处理机制,包括传输层的并发设计和服务端的并发处理流程。最后,我们将分享提升Thrift并发性能的最佳实践,包括配置优化、性能调优以及性能瓶颈的分析与解决方案。
## 3.1 RPC框架并发机制分析
### 3.1.1 RPC框架的并发模型
RPC(Remote Procedure Call)框架提供了一种方便的方式来构建分布式系统,它允许程序像调用本地服务一样调用远程服务。并发模型是RPC框架设计的核心之一,它决定了框架如何处理并发请求以及如何在服务端高效地管理资源。
常见的RPC并发模型包括:
- **多线程模型**:每个请求分配一个线程,可以独立执行。这种模型简单直观,但线程创建和销毁的开销较大,适用于请求量不大的场景。
- **事件驱动模型**:使用事件循环来处理请求,例如Node.js中的libuv库。这种模型可以高效地处理大量并发连接,但编程模型较为复杂。
- **协程模型**:轻量级线程,或称为协程,可以在单个线程内进行协作式多任务处理。Go语言的`goroutine`就是协程模型的一个例子,它极大地提高了并发效率。
### 3.1.2 并发性能优化策略
为了提升RPC框架的并发性能,我们可以采取以下优化策略:
- **线程池管理**:通过线程池复用线程,减少线程创建和销毁的开销。
- **非阻塞I/O**:使用非阻塞I/O模型,如epoll或kqueue,提高I/O操作的效率。
- **异步处理**:将耗时的I/O操作异步化,避免阻塞主线程。
- **资源限制**:合理限制并发连接数和线程数,避免资源竞争和过载。
- **数据缓存**:对频繁访问的数据进行缓存,减少数据处理时间。
## 3.2 Thrift RPC并发处理机制
### 3.2.1 Thrift的传输层并发设计
Thrift的传输层设计支持多种并发模型,它提供了灵活的机制来处理并发请求。Thrift允许开发者通过传输层实现自定义的并发逻辑,例如,可以使用多线程模型来处理并发请求,或者使用协程模型来提高效率。
### 3.2.2 Thrift服务端并发处理流程
Thrift服务端处理并发请求的流程大致如下:
1. **监听端口**:服务端启动并监听指定端口,等待客户端的连接请求。
2. **接收请求**:当接收到客户端的连接请求时,根据传输层配置选择合适的线程或协程来处理。
3. **解析请求*

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Thrift.transport:Python库文件学习指南》专栏深入解析了Thrift Transport层,提供了一系列全面的教程和案例分析,帮助Python开发人员掌握这一关键网络通信组件。从入门到精通,专栏涵盖了Transport层原理、应用、调试、性能优化、安全性、错误处理、微服务架构应用、扩展插件开发、网络协议、负载均衡、数据压缩、连接池管理、流量控制和拥塞避免等各个方面。通过深入浅出的讲解和丰富的实践案例,专栏旨在帮助开发人员充分利用Thrift Transport层,提升网络通信效率、可靠性和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HDFS数据本地化:优化datanode以减少网络开销
# 1. HDFS数据本地化的基础概念
## 1.1 数据本地化原理
在分布式存储系统中,数据本地化是指尽量将计算任务分配到存储相关数据的节点上,以此减少数据在网络中的传输,从而提升整体系统的性能和效率。Hadoop的分布式文件系统HDFS采用数据本地化技术,旨在优化数据处理速度,特别是在处理大量数据时,可以显著减少延迟,提高计算速度。
## 1
数据同步的守护者:HDFS DataNode与NameNode通信机制解析
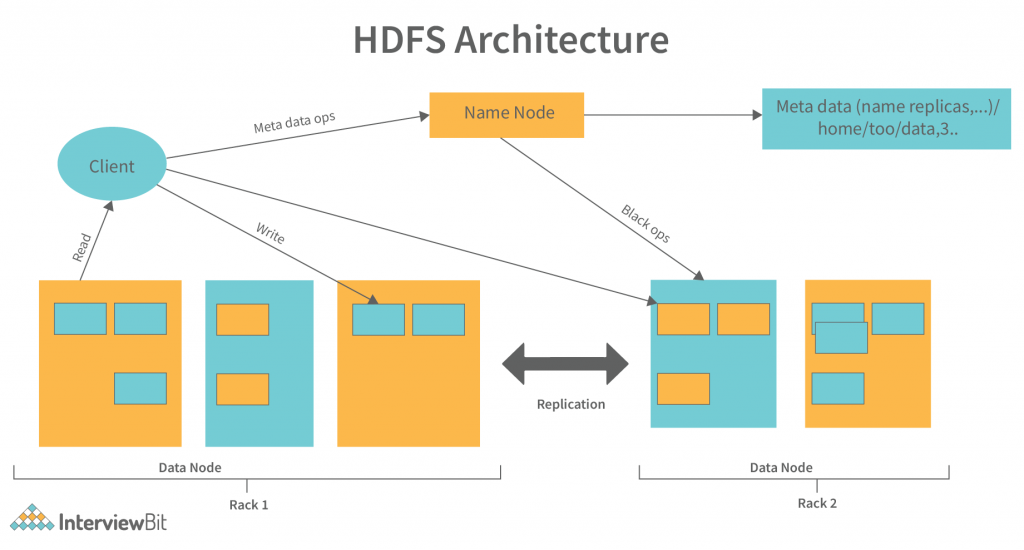
# 1. HDFS架构与组件概览
## HDFS基本概念
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件之一,旨在存储大量数据并提供高吞吐量访问。它设计用来运行在普通的硬件上,并且能够提供容错能力。
## HDFS架构组件
- **NameNode**: 是HDFS的主服务器,负责管理文件系统的命名空间以及客户端对文件的访问。它记录了文
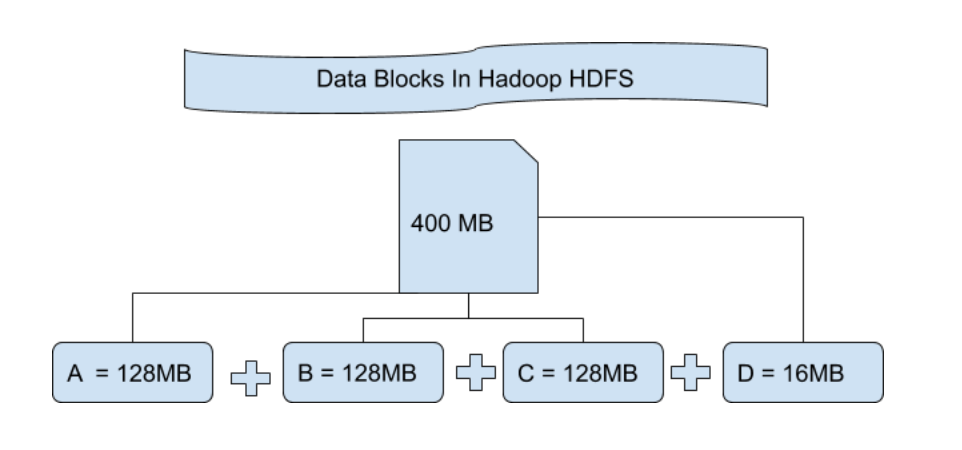
Hadoop资源管理与数据块大小:YARN交互的深入剖析
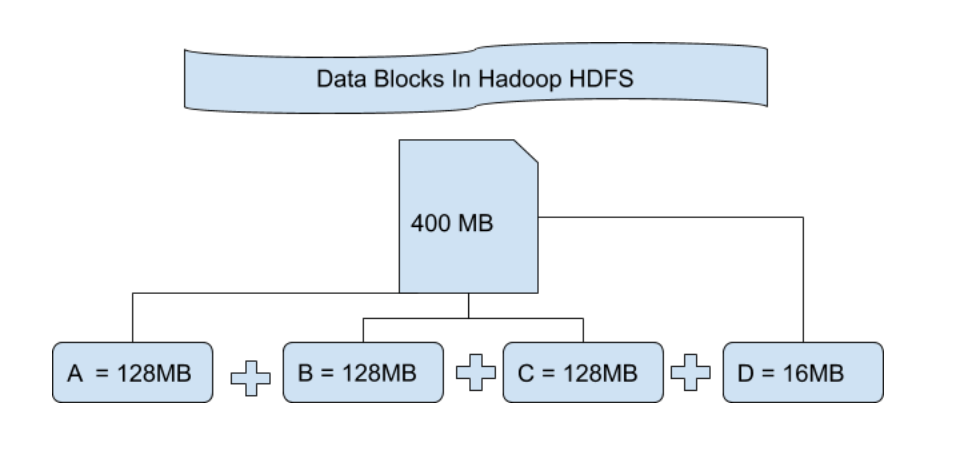
# 1. Hadoop资源管理概述
在大数据的生态系统中,Hadoop作为开源框架的核心,提供了高度可扩展的存储和处理能力。Hadoop的资源管理是保证大数据处理性能与效率的关键技术之一。本章旨在概述Hadoop的资源管理机制,为深入分析YARN架构及其核心组件打下基础。我们将从资源管理的角度探讨Hadoop的工作原理,涵盖资源的分配、调度、监控以及优化策略,为读者提供一个全
Hadoop集群操作手册:数据上传与表目录管理的全面指南

# 1. Hadoop集群简介与架构
## 1.1 Hadoop集群的概念
Hadoop是一个开源的框架,用于在简单的硬件集群上运行大数据应用程序,特别适合于存储和处理大规模数据集。它基于Google开发的MapReduce和Google File System (GFS)技术,具有高可靠性、高效性和高扩展性的特点。
## 1.2 Hadoop的组件
Hadoop的核心组件包括HDFS(Hadoo
数据完整性校验:Hadoop NameNode文件系统检查的全面流程
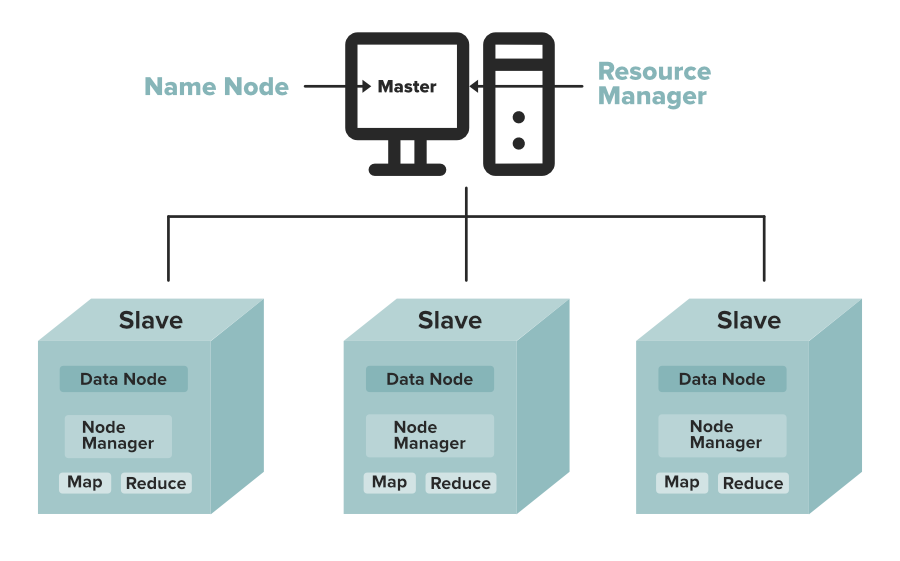
# 1. Hadoop NameNode数据完整性概述
Hadoop作为一个流行的开源大数据处理框架,其核心组件NameNode负责管理文件系统的命名空间以及维护集群中数据块的映射。数据完整性是Hadoop稳定运行的基础,确保数据在存储和处理过程中的准确性与一致性。
在本章节中,我们将对Hadoop NameNode的数据完
HDFS写入数据IO异常:权威故障排查与解决方案指南

# 1. HDFS基础知识概述
## Hadoop分布式文件系统(HDFS)简介
Hadoop分布式文件系统(HDFS)是Hadoop框架中的核心组件之一,它设计用来存储大量数据集的可靠存储解决方案。作为一个分布式存储系统,HDFS具备高容错性和流数据访问模式,使其非常适合于大规模数据集处理的场景。
## HDFS的优势与应用场景
HDFS的优
系统不停机的秘诀:Hadoop NameNode容错机制深入剖析
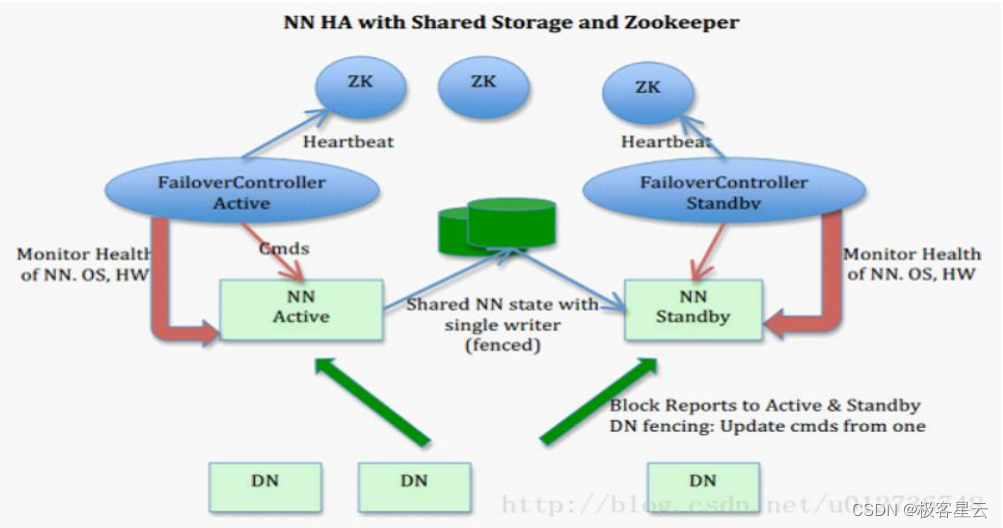
# 1. Hadoop NameNode容错机制概述
在分布式存储系统中,容错能力是至关重要的特性。在Hadoop的分布式文件系统(HDFS)中,NameNode节点作为元数据管理的中心点,其稳定性直接影响整个集群的服务可用性。为了保障服务的连续性,Hadoop设计了一套复杂的容错机制,以应对硬件故障、网络中断等潜在问题。本章将对Hadoop NameNode的容错机制进行概述,为理解其细节
【Hadoop 2.0快照与数据迁移】:策略与最佳实践指南
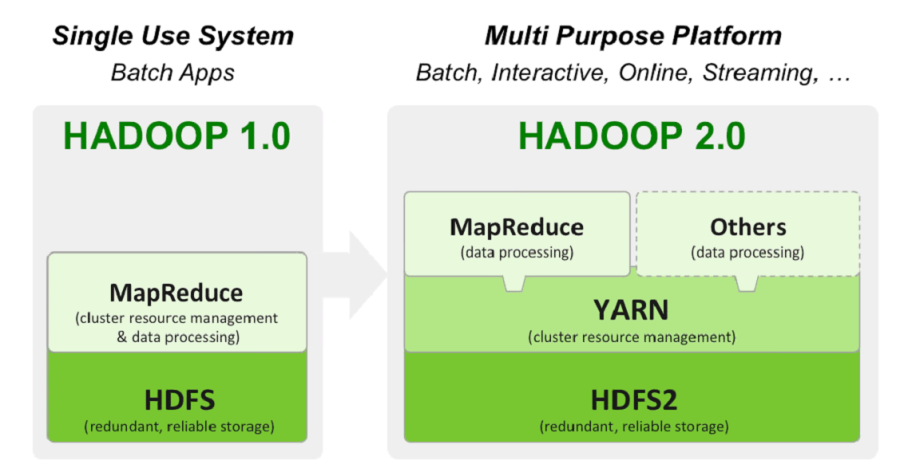
# 1. Hadoop 2.0快照与数据迁移概述
## 1.1 为什么关注Hadoop 2.0快照与数据迁移
在大数据生态系统中,Hadoop 2.0作为一个稳定且成熟的解决方案,其快照与数据迁移的能力对保证数据安全和系统可靠性至关重要。快照功能为数据备份提供了高效且低干扰的解决方案,而数据迁移则支持数据在不同集群或云环境间的移动。随着数据量的不
【HDFS版本升级攻略】:旧版本到新版本的平滑迁移,避免升级中的写入问题

# 1. HDFS版本升级概述
Hadoop分布式文件系统(HDFS)作为大数据处理的核心组件,其版本升级是确保系统稳定、安全和性能优化的重要过程。升级可以引入新的特性,提高系统的容错能力、扩展性和效率。在开始升级之前,了解HDFS的工作原理、版本演进以及升级的潜在风险是至关重要的。本章将概述HDFS版本升级的基本概念和重要性,并
Hadoop快照性能基准测试:不同策略的全面评估报告

# 1. Hadoop快照技术概述
随着大数据时代的到来,Hadoop已经成为了处理海量数据的首选技术之一。而在Hadoop的众多特性中,快照技术是一项非常重要的功能,它为数据备份、恢复、迁移和数据管理提供了便利。
## 1.1 快照技术的重要性
Hadoop快照技术提供了一种方便、高效的方式来捕获HDFS(Hadoop Distributed File System)文件系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )