PyCharm新手入门秘籍:搭建你的第一个数据处理项目
发布时间: 2024-12-12 03:23:57 阅读量: 5 订阅数: 12 

firstDemo:第一个演示

# 1. PyCharm简介及安装配置
PyCharm是由JetBrains公司开发的一款功能强大的Python IDE,它为用户提供了智能代码补全、代码分析、单元测试、调试等功能,深受Python开发者的喜爱。安装配置PyCharm是一个简单而直接的过程,但掌握一些高级技巧可以更好地提升开发效率。
## 1.1 PyCharm简介
PyCharm被设计为符合Python开发者的使用习惯,它的界面清晰、操作流畅,并集成了对现代开发工具链的支持。它包括社区版和专业版,社区版是开源免费的,而专业版则需要购买许可证,提供了数据库支持、Web开发框架支持等高级功能。
## 1.2 安装PyCharm
在安装PyCharm之前,需确保系统满足运行该软件的基本要求。通常情况下,PyCharm支持的操作系统包括Windows、macOS和Linux。以下是在Windows系统上安装PyCharm的基本步骤:
1. 访问PyCharm官网下载页面,选择对应的版本下载安装包。
2. 运行下载的安装包,根据安装向导的指示完成安装。
3. 安装过程中,可以选择安装社区版或专业版,并设置安装路径。
安装完成后,首次启动PyCharm会提示进行初始设置,包括导入设置、选择主题等。
## 1.3 PyCharm配置
安装完成后,接下来是基本的配置,包括配置Python解释器以及安装插件等:
```markdown
1. **设置Python解释器:** 在PyCharm中,进入 `File` -> `Settings` (或使用快捷键 `Ctrl+Alt+S`)。在设置窗口中选择 `Project: YourProjectName` -> `Python Interpreter`,这里可以选择系统已安装的解释器,或点击右侧的齿轮图标,选择 `Add` 来安装一个新的Python解释器。
2. **插件安装:** 在PyCharm中安装插件能大大提升工作效率。进入 `File` -> `Settings` -> `Plugins`,在Marketplace中搜索并安装需要的插件,例如:`Git`,`Docker`等。
```
在完成这些步骤后,你将拥有一个准备就绪的PyCharm开发环境,可以开始进行Python项目开发了。
# 2. 数据处理项目的基础建设
在本章中,我们将深入探讨如何构建数据处理项目的基础结构,确保从项目启动阶段就奠定了坚实的基础。我们将回顾Python的核心语法,设置项目所需的环境,并组织项目文件,使其易于维护和扩展。
### 2.1 Python基础语法回顾
#### 2.1.1 变量、数据类型与操作
Python是一种高级编程语言,它易于阅读和理解。在进行数据处理之前,我们需要掌握一些基础知识,包括变量的使用、数据类型以及常见的操作符。
Python中的变量是存储信息的容器,不需要显式声明类型。我们可以直接给一个变量赋值,Python会根据数据类型自动确定变量类型。
```python
# 变量示例
age = 25
name = "Alice"
is_student = True
```
Python支持多种数据类型,包括但不限于整数、浮点数、字符串、布尔值、列表、元组、字典和集合。每种类型都有其特定的用途和操作方式。
```python
# 数据类型操作示例
age = age + 1 # 整数加法
salary = 3000.00 # 浮点数赋值
greeting = "Hello, " + name # 字符串拼接
is_worker = not is_student # 布尔值取反
fruits = ["apple", "banana", "cherry"] # 列表定义
```
理解数据类型和操作符对于高效的数据处理至关重要,因为数据类型决定了数据的表示和操作方式。在处理数据时,合理选择数据类型和操作符可以提高代码的执行效率和可读性。
#### 2.1.2 控制流语句与函数定义
控制流语句是程序执行中根据条件改变执行路径的语句。在Python中,控制流语句包括`if`, `for`, `while`, `break`, `continue`, `else`等。正确使用这些语句可以编写出逻辑清晰、执行高效的代码。
```python
# 控制流示例
if age > 18:
print("Adult")
elif age > 12:
print("Teenager")
else:
print("Child")
for fruit in fruits:
print(fruit)
index = 0
while index < len(fruits):
print(fruits[index])
index += 1
```
函数是组织代码的一种方式,它允许将一段代码封装起来,并可以多次调用,提高代码的复用性。定义函数使用`def`关键字,函数可以有参数和返回值。
```python
# 函数定义示例
def add_numbers(a, b):
return a + b
result = add_numbers(5, 3)
print("Sum:", result)
```
函数还可以通过默认参数或关键字参数简化函数调用。合理地使用函数可以使代码更加模块化,易于理解和维护。
### 2.2 环境配置与虚拟环境
#### 2.2.1 设置Python解释器
在开始编写Python项目之前,我们需要确保有一个合适的工作环境。Python解释器是Python代码的运行时环境,可以是内置的CPython解释器,也可以是PyPy等其他替代实现。
为了保持开发环境的一致性,并与生产环境相隔离,我们推荐使用虚拟环境来管理项目依赖。Python提供了`virtualenv`工具来创建隔离的Python环境。
```bash
# 创建虚拟环境
virtualenv venv
# 激活虚拟环境(Windows)
.\venv\Scripts\activate
# 激活虚拟环境(Unix/Linux/MacOS)
source venv/bin/activate
```
#### 2.2.2 使用虚拟环境管理项目依赖
在虚拟环境中,我们可以使用`pip`来安装和管理项目依赖的包。为了保持依赖的一致性,我们推荐使用`requirements.txt`文件来记录所有依赖包及其版本。
```bash
# 安装依赖
pip install -r requirements.txt
# 保存当前环境依赖到requirements.txt
pip freeze > requirements.txt
```
通过使用虚拟环境和依赖管理,我们可以确保项目的依赖关系清晰,并且在不同环境之间具有很好的可移植性。
### 2.3 项目结构与文件组织
#### 2.3.1 创建项目目录结构
良好的项目结构对于团队协作、代码维护以及项目扩展都是十分重要的。一个典型的Python项目目录结构可能包括如下内容:
```mermaid
graph TB
project_folder --> src_folder
project_folder --> tests_folder
project_folder --> docs_folder
project_folder --> requirements_txt
src_folder --> main_script
src_folder --> modules_folder
tests_folder --> unit_tests
docs_folder --> readme_md
```
#### 2.3.2 编写入口文件与模块化设计
入口文件通常是一个Python脚本,它定义了程序的启动点。模块化设计可以将程序分割成多个文件,每个文件实现特定的功能。这样的设计不仅有助于代码的重用,还可以提高代码的可读性和可维护性。
```python
# main_script.py示例
import modules.module1
import modules.module2
if __name__ == "__main__":
modules.module1.function1()
modules.module2.function2()
```
在编写模块时,每个模块应该有自己的责任范围,尽量避免模块间的直接依赖。通过使用导入语句来引入其他模块的功能,我们可以构建出一个功能强大且组织良好的应用程序。
通过本章节的介绍,我们已经为数据处理项目打下了坚实的基础。接下来的章节中,我们将深入实践数据采集与预处理的技巧,并将逐步将所学知识应用到数据处理项目中。
# 3. 数据处理项目实战演练
## 3.1 数据采集与预处理
### 3.1.1 爬取网页数据
网页数据爬取是数据分析的第一步,我们通常使用`requests`库来获取网页内容,并使用`BeautifulSoup`或`lxml`进行解析。以下是使用这些库的基本步骤:
1. 安装必要的库,如果尚未安装,请使用pip进行安装:
```bash
pip install requests beautifulsoup4 lxml
```
2. 使用`requests`获取网页内容:
```python
import requests
from bs4 import BeautifulSoup
# 设置请求头部,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
url = "http://example.com"
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
page_content = response.text
else:
print(f"请求失败,状态码:{response.status_code}")
```
3. 使用`BeautifulSoup`解析网页内容:
```python
soup = BeautifulSoup(page_content, 'lxml')
# 解析页面中的特定元素,例如获取所有的文章标题
titles = soup.find_all('h2')
for title in titles:
print(title.get_text())
```
### 3.1.2 数据清洗与格式化
数据清洗是确保数据质量的重要步骤。数据清洗的常见任务包括去除重复项、处理缺失值、规范化文本格式等。以下是数据清洗的基本流程:
1. 去除重复数据:
```python
import pandas as pd
# 假设有一个DataFrame df,其中可能包含重复行
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Alice', 'Dave'],
'Age': [24, 42, 24, 29]
})
# 去除重复项
df_unique = df.drop_duplicates()
print(df_unique)
```
2. 处理缺失值:
```python
# 用均值填充缺失的年龄值
df['Age'].fillna(df['Age'].mean(), inplace=True)
print(df)
```
3. 规范化文本格式:
```python
# 将名字统一转换为大写
df['Name'] = df['Name'].str.upper()
print(df)
```
### 3.1.3 数据集创建与数据导入
完成数据清洗后,需要将清洗后的数据保存为特定格式,以便于后续的分析和处理。常用的数据格式包括CSV、Excel、JSON等。以下是使用Pandas导出数据的示例:
```python
# 将清洗后的数据保存为CSV文件
df.to_csv('cleaned_data.csv', index=False)
# 将清洗后的数据保存为Excel文件
df.to_excel('cleaned_data.xlsx', index=False)
# 从CSV文件读取数据
df = pd.read_csv('cleaned_data.csv')
```
### 3.1.4 数据预处理的进阶技巧
在实际操作中,数据预处理可能更加复杂。例如,文本数据需要进行分词、去除停用词、词干提取等NLP处理。图像数据需要进行裁剪、缩放、归一化等预处理步骤。针对这些高级需求,可以使用如`nltk`、`scikit-image`等专业库来处理。
1. 文本数据处理示例:
```python
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
nltk.download('punkt')
nltk.download('stopwords')
# 假设有一个文本字符串text
text = "The quick brown fox jumps over the lazy dog."
# 分词
tokens = word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word not in stop_words]
# 词干提取
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(word) for word in filtered_tokens]
print(stemmed_tokens)
```
2. 图像数据预处理示例:
```python
from skimage import io, transform
# 读取图像
image = io.imread('path_to_image.jpg')
# 缩放图像
resized_image = transform.resize(image, (150, 150))
# 归一化
normalized_image = resized_image / 255.0
# 保存处理后的图像
io.imsave('normalized_image.jpg', normalized_image)
```
### 3.1.5 使用Pandas进行数据预处理
Pandas是一个强大的数据处理库,提供了丰富的数据结构和操作方法,能够帮助我们高效地完成数据预处理工作。Pandas中常用的功能包括数据合并、数据重塑、数据分组等。
1. 数据合并:
```python
# 假设有两个DataFrame df1 和 df2
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [0, 1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'D', 'E'], 'value': [4, 5, 6, 7]})
# 合并两个DataFrame
merged_df = pd.merge(df1, df2, on='key')
print(merged_df)
```
2. 数据重塑:
```python
# 将宽格式数据转换为长格式数据
df_pivot = df.pivot(index='Name', columns='Date', values='Score')
print(df_pivot)
# 将长格式数据转换为宽格式数据
df_wide = df_pivot.reset_index().melt(id_vars='Name', var_name='Date', value_name='Score')
print(df_wide)
```
3. 数据分组:
```python
# 根据某列值进行分组,并计算每组的统计值
grouped = df.groupby('Name')['Age'].mean()
print(grouped)
```
### 3.1.6 使用Numpy进行数学运算
Numpy是Python中进行科学计算的基础库,它提供了高性能的多维数组对象和这些数组的操作工具。对于复杂的数值计算,Numpy可以大大简化代码。
```python
import numpy as np
# 创建一个Numpy数组
array = np.array([1, 2, 3, 4, 5])
# 计算数组的平方和立方
squares = np.square(array)
cubes = np.cube(array)
print("Squares:", squares)
print("Cubes:", cubes)
# 使用Numpy进行矩阵运算
matrix1 = np.array([[1, 2], [3, 4]])
matrix2 = np.array([[5, 6], [7, 8]])
# 矩阵乘法
product = np.dot(matrix1, matrix2)
print("Matrix Product:\n", product)
```
在数据处理项目中,Numpy常被用于执行数值计算、线性代数运算等,它提供的功能可以加快数据处理速度,并提供与其他科学计算库的接口。
## 3.2 数据分析与可视化
### 3.2.1 使用Pandas进行数据分析
在本节中,我们将讨论如何使用Pandas库进行数据分析,并展示数据的统计特征、数据分布情况等。
### 3.2.2 使用Matplotlib进行数据可视化
Matplotlib是Python中最常用的绘图库之一,它可以生成高质量的图表和可视化。在本节中,我们将学习如何使用Matplotlib来创建各种类型的图表,例如条形图、折线图、散点图等。
### 3.2.3 使用Seaborn增强可视化效果
Seaborn是建立在Matplotlib之上,并提供了一种更高级的绘图接口。它支持更多的图形类型,并且易于定制。我们将展示Seaborn如何使图表更加美观和信息丰富。
### 3.2.4 交互式数据可视化
在某些情况下,我们可能需要创建交互式的图表,以允许用户探索数据集的不同方面。我们将探索如何使用Plotly和Dash框架来创建交互式数据可视化。
## 3.3 数据存储与管理
### 3.3.1 数据存储方案概述
在本节中,我们将介绍常见的数据存储方案,包括关系型数据库、NoSQL数据库、文件存储等,并讨论各自的优势和使用场景。
### 3.3.2 实现数据的导入导出功能
接下来,我们将讨论如何使用Python与不同的数据存储方案交互。这包括使用SQLAlchemy连接和操作数据库,使用Pandas进行文件的读写操作等。
### 3.3.3 数据库查询与更新操作
在本节中,我们重点学习如何使用SQL语言进行数据库的查询和更新操作。此外,还会介绍Pandas的`read_sql_query`和`to_sql`方法,它们可以在Pandas DataFrame和SQL数据库之间轻松迁移数据。
### 3.3.4 优化数据库性能
数据库性能优化对于大数据分析至关重要。我们将会介绍一些优化策略,包括使用索引、编写高效的查询语句、合理设计数据库结构等。
# 4. PyCharm高级功能应用
## 4.1 调试与测试
在本章中,我们将深入了解PyCharm的高级功能,包括调试、测试、版本控制、插件使用等,这些功能将帮助开发者更有效地编写、测试和优化代码。
### 4.1.1 使用PyCharm的调试工具
PyCharm的调试功能为开发者提供了一个强大的界面,用以检查程序的执行流程和变量状态。启动调试会话非常简单,只需点击PyCharm工具栏上的“Debug”按钮,或者使用快捷键Shift+F9。
调试过程可以利用断点,断点是代码中我们希望程序暂停执行的特定位置。在PyCharm中,您可以通过双击编辑器左边的边界栏来设置断点。当程序执行到断点时,PyCharm会暂停,让您检查调用堆栈、变量值以及程序的当前状态。
PyCharm提供了一组调试视图窗口,包括变量监视窗口、表达式窗口、调用堆栈窗口和断点窗口。利用这些工具,您可以在程序的不同层次和视图之间导航,进行更复杂的调试任务。
**代码块示例**:
```python
# sample.py
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
```
在上述代码中,我们可以设置一个断点在`return n * factorial(n-1)`这行代码上,然后运行程序进入调试模式。程序会在计算`factorial(5)`时暂停,您可以在变量监视窗口中查看变量`n`的值,并逐步执行下一行代码。
### 4.1.2 编写单元测试与测试驱动开发
单元测试是软件开发中不可或缺的组成部分,PyCharm支持单元测试的编写和运行。在PyCharm中,我们可以使用Python内置的`unittest`模块或第三方测试库如`pytest`来编写测试用例。
PyCharm集成了一个测试运行器,该运行器可以运行当前项目的所有测试,也可以运行特定的测试用例或测试文件。要运行测试,请右键点击测试文件或测试方法,并选择“Run 'pytest in sample'”。
**代码块示例**:
```python
# test_factorial.py
import unittest
from sample import factorial
class TestFactorial(unittest.TestCase):
def test_factorial(self):
self.assertEqual(factorial(1), 1)
self.assertEqual(factorial(2), 2)
self.assertEqual(factorial(5), 120)
self.assertEqual(factorial(0), 1) # test special case
if __name__ == '__main__':
unittest.main()
```
在测试代码中,我们编写了一个测试类`TestFactorial`,继承自`unittest.TestCase`,并为`factorial`函数编写了四个测试用例。运行该测试文件将验证`factorial`函数的正确性。如果函数中存在逻辑错误,测试用例将显示失败信息,并有助于我们快速定位和修复问题。
## 4.2 版本控制集成
### 4.2.1 配置Git版本控制
PyCharm对版本控制系统有着出色的集成支持,特别是对Git。配置Git的过程很简单,首先您需要确保已经安装了Git。
打开PyCharm,从顶部菜单选择“File”->“Settings”(在Mac上是“PyCharm”->“Preferences”),然后在弹出的窗口中选择“Version Control”并选择“+”号添加一个新的Git仓库。
**步骤说明**:
1. 打开PyCharm。
2. 进入“File”->“Settings”(或Mac上的“PyCharm”->“Preferences”)。
3. 点击“Version Control”选项。
4. 点击“+”号,然后选择“Git”。
5. 选择包含Git可执行文件的路径,通常PyCharm会自动检测。
6. 点击“OK”,完成Git的集成配置。
完成这些步骤后,PyCharm将能够跟踪和管理使用Git进行版本控制的项目。
### 4.2.2 利用Git进行代码版本管理
在集成Git之后,PyCharm提供了所有常用的版本控制功能,如提交、推送、拉取、分支管理、合并冲突解决等。利用PyCharm的图形用户界面,这些操作都变得直观而简单。
PyCharm将Git操作集成到编辑器中,比如您可以直接在文件上右键点击,选择“Git”菜单项,即可对特定文件执行提交、查看差异、添加到暂存区等操作。
**操作步骤**:
1. 在PyCharm中打开项目。
2. 点击底部的“Version Control”窗口。
3. 在此窗口中,您可以查看提交历史、创建分支、合并请求等。
4. 当您准备提交更改时,在编辑器中右键点击文件,并选择“Git”->“Commit Directory”,填写提交信息,并提交更改。
5. 如果需要更新本地代码库,可以点击“Git”->“Pull”。
6. 若要将更改推送到远程仓库,点击“Git”->“Push”。
PyCharm中的版本控制功能是帮助开发者高效管理代码变更的强有力工具。
## 4.3 插件与扩展使用
### 4.3.1 探索PyCharm的插件市场
PyCharm的插件市场提供了许多扩展,可以增强或添加新的功能,如支持不同的开发框架、提供额外的代码分析工具以及增强代码编辑器的功能等。
访问插件市场很简单,只需选择顶部菜单栏中的“File”->“Settings”(或Mac上的“PyCharm”->“Preferences”),然后点击左侧的“Plugins”。在插件市场中,您可以搜索和安装想要的插件。
**操作说明**:
1. 打开PyCharm,选择“File”->“Settings”(或Mac上的“PyCharm”->“Preferences”)。
2. 在设置窗口中选择“Plugins”。
3. 您可以浏览推荐插件,或在搜索框中输入插件名查找。
4. 选中想要安装的插件,然后点击“Install”。
5. 安装完成后,重启PyCharm以使插件生效。
### 4.3.2 安装与配置有用的数据处理插件
数据处理是一个广泛的主题,PyCharm社区提供了许多帮助数据处理的插件。例如,对于使用Pandas的用户,有一个名为“pandas support”的插件,它为Pandas提供了代码补全和文档提醒功能。
另一个流行的插件是“Jupyter”,它允许您在PyCharm内部创建和运行Jupyter Notebook。它是一个非常有用的工具,特别是对于那些需要进行数据分析并创建交互式报告的开发者。
**安装步骤**:
1. 打开PyCharm,选择“File”->“Settings”(或Mac上的“PyCharm”->“Preferences”)。
2. 选择“Plugins”部分。
3. 使用搜索功能找到“Jupyter”插件。
4. 点击“Install”按钮,然后等待安装完成。
5. 安装完成后,重启PyCharm。
**配置步骤**:
1. 重启PyCharm后,在“Tools”菜单中选择“Jupyter”,然后选择“Create New Notebook”。
2. 选择一个合适的内核,并为Notebook命名。
3. 创建后,您可以在Notebook中编写Python代码,并直接执行每一条语句,看到输出结果。
以上步骤展示了如何利用PyCharm的插件市场来安装和配置数据处理相关的插件,以增强PyCharm的功能,使其更加适合开发数据处理项目。
通过以上章节的探讨,我们已经了解了PyCharm中一些非常有用的高级功能,包括调试、测试、版本控制和插件扩展。这些功能使PyCharm成为了一个功能完备的集成开发环境,不仅适合于日常的编码工作,还可以显著提高开发效率和代码质量。接下来,我们将探讨项目优化与部署,这是任何项目开发周期中不可或缺的最后阶段。
# 5. 项目优化与部署
在IT行业中,将一个项目从开发环境顺利过渡到生产环境,往往需要经过精心的优化与部署策略。优化能够提高应用的性能和稳定性,而部署则确保了应用的可用性和可维护性。本章节将深入探讨代码优化、项目打包分发以及云端部署等关键技术环节。
## 5.1 代码优化与重构
代码的性能并非一蹴而就,随着项目的不断迭代,可能会累积许多冗余代码、效率低下的算法以及不合理的架构设计。代码优化和重构成为了提升性能和可维护性的必经之路。
### 5.1.1 代码审查与重构技巧
- **代码审查(Code Review)** 是团队协作中提高代码质量的重要环节。通过同行评审,可以尽早发现潜在的bug,共享最佳实践,并提高团队整体的代码风格一致性。
- **重构(Refactoring)** 是指在不改变软件外部行为的前提下,对内部结构进行修改以提高代码质量的过程。重构技巧包括但不限于:
- 提取方法或函数以减少代码重复。
- 使用设计模式来改善设计架构。
- 优化数据库查询语句,减少不必要的数据加载。
- 利用多线程或异步编程来提高并发处理能力。
### 5.1.2 提高代码效率的方法
- **算法优化**:采用时间复杂度和空间复杂度更低的算法。例如使用哈希表快速访问数据,减少排序操作等。
- **代码层面优化**:减少不必要的循环,使用局部变量代替全局变量,减少函数调用开销等。
- **性能分析工具**:利用Python的性能分析工具如cProfile来找出性能瓶颈并进行针对性优化。
- **编译优化**:在一些高性能场景下,可以考虑使用Cython将Python代码转换成C语言来提高性能。
## 5.2 项目打包与分发
项目开发完毕后,需要打包成一个可执行的应用程序,然后进行分发。这样用户在不需要安装Python环境的情况下也能运行程序。
### 5.2.1 打包Python应用程序
- **PyInstaller**:PyInstaller是一个流行的工具,可以将Python程序打包成独立的可执行文件。它支持Windows、Linux和Mac OS X等多个平台。
- **cx_Freeze**:这是一个将Python脚本捆绑到可执行文件的工具,通常用于生成跨平台的Windows程序。
- **创建打包脚本**:通常创建一个setup.py文件,使用setuptools进行打包,然后用pip安装。打包脚本可以定义项目信息、依赖、入口等。
### 5.2.2 分发项目与用户部署
- **PyPI(Python Package Index)**:是Python的官方包索引,发布自己的包到PyPI使得别人可以通过pip进行安装。
- **虚拟环境**:推荐用户使用虚拟环境安装,这样可以避免系统环境的污染。
- **文档**:提供清晰的安装指南和使用说明,帮助用户快速上手。
## 5.3 云端部署与自动化运维
随着云计算技术的普及,将应用部署到云端成为了新的趋势。云服务提供了弹性、可扩展的计算资源,而自动化运维则大大减少了日常的手动工作。
### 5.3.1 云服务基础与应用选择
- **选择云服务提供商**:目前市面上主要的云服务提供商有Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)和阿里云等。
- **理解不同云服务类型**:云服务分为IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)。
- **云服务的特性**:包括但不限于资源的弹性扩展、多租户隔离、按需计费、高可用性设计等。
### 5.3.2 实现项目自动化部署与运维监控
- **自动化部署工具**:比如Ansible、Chef、Puppet等,通过编写脚本实现自动化部署流程。
- **持续集成/持续部署(CI/CD)**:例如Jenkins、GitLab CI/CD等工具,可以自动化测试、部署等流程,提升开发效率。
- **监控工具**:云平台通常会提供监控工具,例如AWS CloudWatch、Azure Monitor等,用于监控应用状态和性能指标。
本章节重点介绍了项目优化与部署的多个方面,从代码审查到打包分发,再到云端部署和自动化运维,每一步都是为了让项目更加稳定高效,更容易被维护和使用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏详细介绍了使用 PyCharm 进行数据处理项目的具体步骤,从项目设置到数据加载和处理。此外,还深入探讨了 PyCharm 的单元测试功能,重点介绍了如何使用它来确保数据处理代码的质量。通过遵循本专栏的指导,读者将掌握在 PyCharm 中有效管理和测试数据处理项目的技能,从而提高代码可靠性和项目成功率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
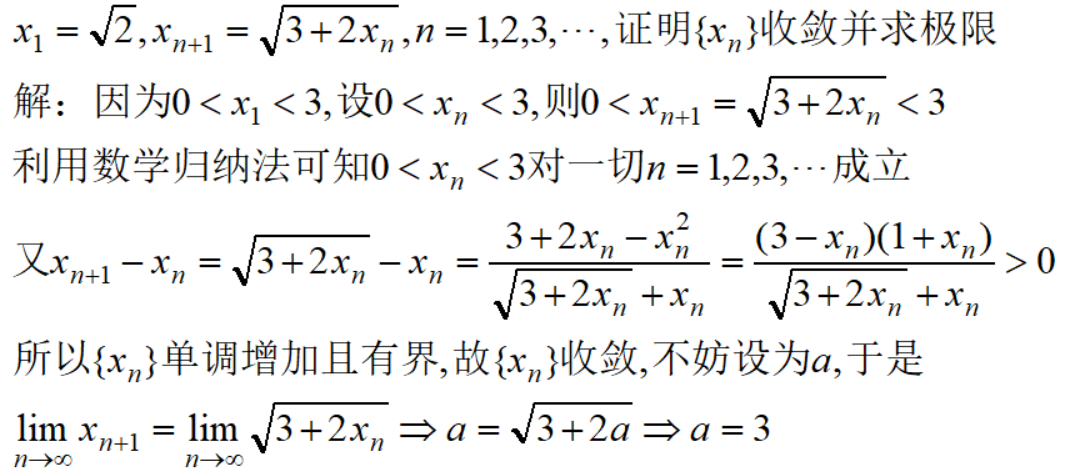
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
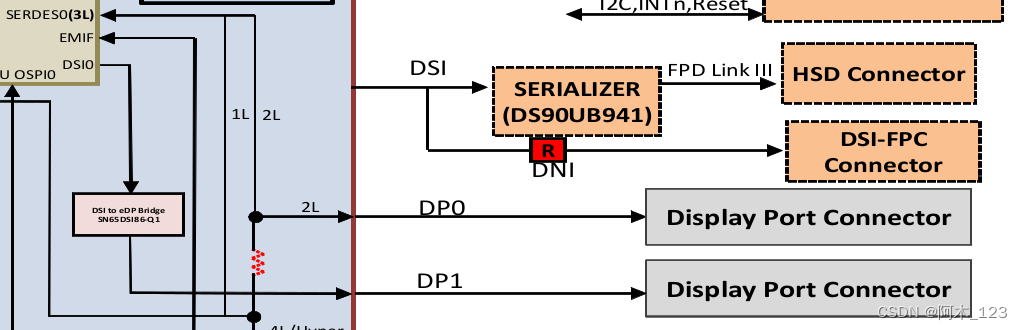
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )