【Linux文本筛选艺术】:grep的高级模式匹配技巧与案例分析
发布时间: 2024-12-12 13:36:18 阅读量: 7 订阅数: 11 

Linux系统 grep命令用法详解.doc
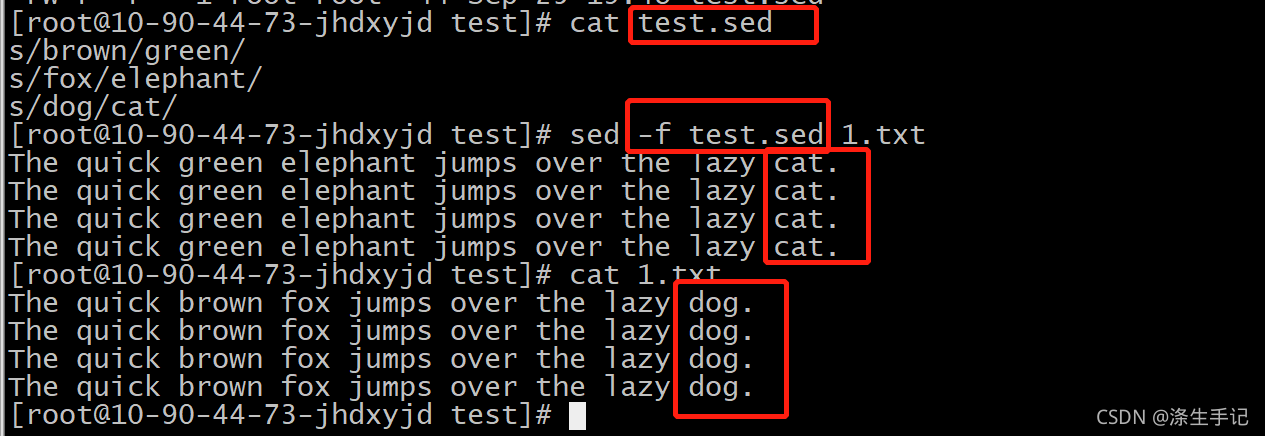
# 1. Linux文本筛选艺术:grep简介
Linux系统的文本处理能力强大,其中grep命令作为文本搜索工具的代表,已经成为了每一个IT从业者的必备技能之一。它能够在一个或多个文件中执行文本搜索,并将匹配特定模式的字符串行输出。从简单的一行搜索,到复杂的多行复合模式匹配,grep均能提供高效而精确的筛选能力。掌握grep,对于进行系统管理、开发调试、日志分析等工作流程来说,不仅能够提升工作效率,还能在关键时刻快速定位问题。本章节将带你走进grep的世界,了解它的基本概念、应用场景,并为后续章节的深入学习打下坚实基础。
# 2. grep的基础用法与模式匹配原理
在探索文本处理的世界中,`grep` 是一个不可或缺的强大工具。作为一个Linux和Unix系统上广泛使用的命令行工具,`grep` 用于搜索文本并匹配特定模式。它的强大之处在于其灵活性和对正则表达式的支持。在这一章节中,我们将深入探究`grep`的基础用法,模式匹配原理,并了解其核心模式匹配技术。
## 2.1 grep的基本命令结构
### 2.1.1 grep命令的基本组成
`grep` 命令的基本结构由三部分组成:要搜索的模式(pattern),要搜索的文件(file),以及可选的命令行选项(option)。其通用形式如下:
```bash
grep [options] pattern [file...]
```
- `pattern`:是需要在文件中搜索的文本模式。它可以是普通的文本字符串,也可以是复杂的正则表达式。
- `[file...]`:是目标文件的列表。如果不提供文件名,`grep` 将从标准输入读取数据。
- `[options]`:是可选的命令行参数,用于调整`grep`的行为。常见的参数包括`-i`(忽略大小写)、`-r`(递归搜索)、`-v`(反向选择,即只显示不匹配的行)等。
### 2.1.2 正则表达式基础
在使用`grep`之前,掌握正则表达式的基础是至关重要的。正则表达式是一种特殊的字符串模式,用于描述一组匹配某个句法规则的字符串。以下是几个基本的正则表达式元字符和概念:
- `.`:匹配任意单个字符(除了换行符)。
- `*`:匹配前一个字符0次或多次。
- `[]`:字符集,匹配指定范围内的任意单个字符。
- `^`:匹配行的开始。
- `$`:匹配行的结束。
### 2.2 grep的核心模式匹配技术
#### 2.2.1 简单文本搜索
`grep` 最基本的用法是进行简单的文本搜索,这不需要复杂的正则表达式,只需要指定要搜索的字符串即可。例如,以下命令将在`example.txt`文件中查找包含字符串“error”的行:
```bash
grep "error" example.txt
```
#### 2.2.2 基本的正则表达式元字符使用
在搜索更复杂的模式时,就需要借助正则表达式的元字符了。使用元字符可以实现模式的灵活匹配。例如,如果我们想匹配以"err"开头的单词,我们可以使用如下命令:
```bash
grep "^err" example.txt
```
## 2.3 grep的高级模式匹配特性
### 2.3.1 扩展正则表达式元字符
为了应对更复杂的匹配需求,`grep` 支持扩展正则表达式,这需要使用`-E`选项。扩展正则表达式支持`?`、`+`、`|`以及括号用于捕获组等元字符。例如,要匹配两个单词“error”或“success”,可以使用如下命令:
```bash
grep -E "error|success" example.txt
```
### 2.3.2 使用grep进行逻辑组合匹配
通过使用正则表达式的逻辑操作符,`grep`可以实现复杂的条件组合。例如,要匹配以“error”结尾或包含“warning”的行,可以结合逻辑“或”操作:
```bash
grep -E "error$|warning" example.txt
```
以上是对`grep`命令基础用法和模式匹配原理的概述。随着学习的深入,我们将继续探索`grep`如何在更高级的应用中发挥作用,以及如何通过高级模式匹配特性来提升文本处理的效率和准确性。接下来,我们将深入了解`grep`在文本处理中的高级应用。
# 3. grep在文本处理中的高级应用
## 3.1 grep与文件操作
### 3.1.1 对多个文件进行搜索
在处理文本时,常常需要对多个文件执行搜索操作,以找到特定的信息。使用grep结合通配符可以实现这一功能,通配符可以是星号(*)匹配任意多个字符,问号(?)匹配任意单个字符。
例如,要搜索当前目录下所有`.txt`文件中包含单词“error”的行,可以执行:
```sh
grep "error" *.txt
```
此外,如果需要对多个目录下的所有文件执行搜索,可以使用递归选项`-r`或`-R`。这会使得grep遍历指定目录及其子目录,搜索所有匹配的文本行。
```sh
grep -r "error" /path/to/directory/
```
如果要排除某些特定文件或目录,可以结合使用`grep`和`find`命令。例如,搜索某个目录下除了某个文件的所有`.txt`文件:
```sh
find /path/to/directory/ -type f -name "*.txt" | grep -v excluded_file.txt
```
上述命令使用`find`来列出所有`.txt`文件,并通过`grep -v`(显示不包含模式的行)排除掉不需要搜索的文件。
### 3.1.2 排除特定文件或目录
在搜索文件时,我们经常会遇到需要忽略某些文件或目录的情况。比如,我们可能不需要搜索二进制文件、临时文件或版本控制系统的目录等。
假设我们想搜索特定目录下所有`.txt`文件,但需要排除所有的`.bak`备份文件和`node_modules`目录。我们可以使用`-v`选项来反转匹配模式,以及`-r`来递归地搜索目录。
```sh
grep -r "pattern" /path/to/directory/ | grep -v ".bak$" | grep -v "node_modules"
```
此命令首先递归地搜索包含"pattern"的行,然后排除所有以`.bak`结尾的文件,并排除包含`node_modules`目录的行。
## 3.2 grep在系统日志分析中的应用
### 3.2.1 筛选关键系统日志信息
系统日志文件包含了大量关于系统运行状态的信息,这些信息对于诊断问题和系统监控至关重要。grep可以高效地帮助我们从这些日志中筛选出关键信息。
比如,如果我们想要查看所有关于磁盘空间不足的警告信息,可以在日志文件中搜索特定的错误代码或消息。
```sh
grep "WARNING: No space left on device" /var/log/syslog
```
如果日志中包含时间戳,我们可以结合使用`grep`和`date`命令,来筛选出特定时间范围的日志记录。
```sh
grep "WARNING: No space left on device" /var/log/syslog | grep "$(date +%F -d 'last week')"
```
上述命令将输出上一周内所有相关的警告信息。
### 3.2.2 结合其他命令处理日志数据
为了更全面地分析日志数据,我们通常需要结合使用多个命令。例如,可以使用`awk`来解析日志文件中的时间戳,结合`sort`和`uniq`来统计错误信息的出现频率。
```sh
grep "ERROR" /var/log/syslog | awk '{print $4}' | sort | uniq -c
```
这个命令链首先通过`grep`筛选出包含"ERROR"的行,然后使用`awk`提取第四列(通常是时间戳),接着使用`sort`对提取的时间戳进行排序,最后使用`uniq -c`来计数并输出各个错误的出现次数。
## 3.3 grep的输出控制
### 3.3.1 高亮显示匹配行
对于大型文本文件,高亮显示匹配到的行可以提高可读性和易用性。许多版本的`grep`支持`--color`选项或`-P`选项来开启高亮模式。
```sh
grep --color=auto "pattern" filename
```
使用`--color=always`会一直让匹配的文本高亮显示,而不会因为输出重定向到文件而失效。
### 3.3.2 控制输出行数和上下文
有时,我们可能希望查看匹配行周围的内容,以便更好地理解上下文。`-C`选项允许我们指定要显示的上下文行数。
```sh
grep -C 2 "pattern" filename
```
这个命令将输出匹配"pattern"的行以及前后各2行的内容。
同时,使用`-B`和`-A`选项可以分别控制匹配行之前的行数和之后的行数。
```sh
grep -A 3 -B 1 "pattern" filename
```
此命令输出匹配"pattern"的行以及其之前1行和之后3行的内容。
在一些复杂的使用场景下,我们可能需要对输出进行进一步的处理和分析。例如,使用`awk`、`sed`等工具结合`grep`来处理特定行或列数据。
```sh
grep "pattern" filename | awk '{print $2}' | sort | uniq -c
```
这个例子中,我们首先使用`grep`找出包含"pattern"的行,然后通过管道传递给`awk`提取每行的第二个字段,接着使用`sort`排序和`uniq -c`统计每个唯一行的出现次数。
这样,通过组合使用`grep`的输出控制选项以及与其它文本处理工具的整合,我们可以实现对文本数据的深入分析。
# 4. grep的进阶技巧与案例分析
在前三章中,我们探讨了Linux文本处理工具grep的方方面面,从基础知识到高级用法,再到在特定场景下的应用。本章将深入探究grep的进阶技巧,并通过案例分析,展示grep在实际项目中的强大能力。
## 4.1 使用grep进行复杂的文本模式匹配
随着对grep使用的逐步深入,我们经常会遇到需要进行复杂模式匹配的情况。这通常涉及到正则表达式的高级特性,如捕获组、反向引用和复杂的逻辑条件匹配。
### 4.1.1 捕获组和反向引用
在正则表达式中,捕获组是将一个正则表达式的一部分括在括号内,以便后续可以引用。这可以用于提取匹配特定模式的文本部分。
假设我们需要从一个文件中提取所有具有特定格式的电子邮件地址。我们可以通过以下命令实现:
```bash
echo "Contact us at admin@example.com or support@example.com" | grep -oP '(?<= Contact us at )\w+@\w+\.\w+'
```
- `-o` 参数使grep仅输出匹配的部分。
- `-P` 参数允许我们使用Perl兼容的正则表达式(PCRE),这包括了特殊的模式匹配构造,比如后向断言。
- `\w+@\w+\.\w+` 是一个正则表达式,它匹配邮箱地址的结构。
让我们逐行解释这段代码:
- `(?<= Contact us at )` 是一个正向后查找,它要求所匹配的文本前面必须有" Contact us at "。这样我们可以确保只匹配该字符串后面的邮箱地址。
- `\w+` 匹配一个或多个字母数字字符,等同于`[a-zA-Z0-9]+`。
- `@` 是字面意义上的"@"符号。
- `\.\w+` 匹配点号后面跟着的一个或多个字母数字字符。
这个模式非常有用,特别是在处理日志文件、代码库或者任何包含大量文本数据的文件时。
### 4.1.2 嵌套条件与复杂模式的匹配
有时候,我们需要匹配的文本模式可能涉及到多层次的条件判断。这通常需要结合使用不同的正则表达式元字符。
例如,假设我们需要在日志文件中找到所有连续三次登录失败的事件。我们可以使用如下命令:
```bash
grep -P 'Failed to login \w+ times in a row' file.log
```
在这个例子中,我们使用了`\w+`来匹配一个或多个单词字符,代表次数,这个模式会匹配所有包含"Failed to login"后面跟着一个或多个单词字符,然后是"times in a row"的行。
嵌套条件和复杂模式的匹配增加了文本筛选的灵活性和深度,但也需要我们对正则表达式有更深入的理解。
## 4.2 grep的性能优化策略
在面对大量数据时,grep的性能会受到极大的考验。本节将探讨如何优化grep命令的性能,以及了解grep内部工作机制的重要性。
### 4.2.1 优化grep命令参数
优化grep性能的一个常见方法是合理使用命令参数。例如,`-m 1`参数可以在找到第一个匹配行后就停止处理,这对于只需要第一条匹配项的场景非常有用:
```bash
grep -m 1 "pattern" filename
```
另一个常见的优化参数是`-s`,它会抑制错误消息,比如文件不存在的消息,这对于处理大量文件时尤其有用。
### 4.2.2 理解grep的内部工作机制
深入理解grep的工作机制可以帮助我们更好地优化其性能。grep在处理文本时,会逐行读取文件内容,并将每一行与提供的正则表达式进行匹配。如果正则表达式过于复杂,或者文件非常大,这会导致明显的性能下降。
为了提高性能,我们可以:
- 使用简单的正则表达式,并尽量避免不必要的捕获组。
- 将大文件分割成小文件进行搜索。
- 如果可能的话,预先编译正则表达式,尤其是在需要多次使用同一模式时。
下面的mermaid流程图表示了grep工具的基本工作流程:
```mermaid
graph LR
A[开始] --> B[读取文件内容]
B --> C{匹配正则表达式}
C -->|是| D[输出匹配行]
C -->|否| B
D --> E[结束]
```
在理解了这些基本原理后,我们可以根据具体的任务需求和环境对grep命令进行针对性的优化。
## 4.3 案例研究:在实际项目中应用grep
本节将通过具体案例来研究grep如何在实际项目中发挥重要的作用。
### 4.3.1 大型代码库的搜索与维护
在开发大型项目时,经常需要在大量的代码中搜索特定的函数调用、变量声明或字符串模式。grep在此场景下,不仅可以提高我们的工作效率,还可以帮助我们快速定位潜在的问题。
例如,假设我们需要在JavaScript代码库中找到所有使用了某个特定API调用的文件,可以使用如下命令:
```bash
grep -r --include='*.js' "apiCallName" .
```
- `-r` 参数让grep递归地搜索所有子目录。
- `--include='*.js'` 限制搜索仅包括以.js结尾的文件。
### 4.3.2 文本自动化处理流程中的grep应用
文本自动化处理是日常运维和开发任务中的常见场景。grep可以与其他文本处理工具如awk、sed组合,形成强大的文本处理工作流。
例如,假设我们希望从服务器日志中筛选出访问量最高的10个IP地址,并输出每个IP的访问次数。我们可以结合使用grep、awk和sort:
```bash
grep "Access denied" logfile.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -n 10
```
这里:
- `grep "Access denied"` 查找所有包含"Access denied"的行。
- `awk '{print $1}'` 输出这些行的第一个字段,通常是访问者的IP地址。
- `sort` 对IP地址进行排序。
- `uniq -c` 统计每个IP出现的次数。
- `sort -nr` 对出现次数进行数值降序排序。
- `head -n 10` 输出前10行,即访问次数最高的10个IP。
通过这个例子,我们可以看到grep如何在复杂的文本处理场景中发挥关键作用,与其他工具一起形成了高效的工作流。
以上就是grep在实际项目中的应用案例。通过这些案例,我们可以看到grep的灵活性和强大功能,并理解其在各种不同环境下的适用性。
# 5. grep与其他文本工具的整合使用
在文本处理的世界里,grep并不是一座孤岛。它经常与诸如awk、sed等工具协同作战,形成强大的文本处理组合拳。本章节将探讨grep与其他文本工具如何整合使用,发挥它们的最大效能。
## 5.1 grep与awk的协同使用
### 5.1.1 当grep遇到awk:复杂文本分析
当我们面对复杂的文本分析任务时,grep的简单模式匹配可能不足以应对。这时,我们可以将grep的输出作为awk的输入,利用awk强大的文本处理能力进行进一步的分析。比如,我们想要从系统日志中找出所有在特定时间段内失败登录的用户:
```bash
grep 'Failed login' system.log | awk '{print $5}'
```
这里,grep首先筛选出包含"Failed login"的日志行,然后awk提取每行的第五个字段(通常是用户名称)。
### 5.1.2 优化处理流程:整合grep与awk
在整合grep与awk的使用时,我们可以先使用grep进行快速过滤,然后利用awk的详细字段解析和统计功能进行深度分析。例如,对于一个复杂的CSV文件,我们可以先用grep排除掉不需要处理的列,然后用awk进行数据处理:
```bash
grep ',^[^,]*,[^,]*,' large_data.csv | awk -F ',' '{...}'
```
在这个例子中,grep首先通过正则表达式排除掉我们不关心的列,然后awk按照逗号分隔符处理每行数据。
## 5.2 grep与sed的互补技巧
### 5.2.1 sed基础与文本编辑
sed是流编辑器,常用于对文本数据进行转换和编辑。当结合grep使用时,我们可以先用grep找出包含特定模式的行,然后用sed对这些行进行编辑。例如,我们想要修改所有包含特定错误信息的日志行:
```bash
grep 'Error' error.log | sed 's/ERROR/ERROR Fixed/'
```
这里,grep筛选出包含"Error"的日志行,然后sed将这些行中的"ERROR"替换为"ERROR Fixed"。
### 5.2.2 结合sed和grep进行多步骤文本处理
多步骤文本处理时,我们可能会将数据流在sed和grep之间来回传递多次。一个典型的用例是:首先使用sed进行初步的文本转换,然后利用grep进行模式匹配。例如,对日志文件进行过滤和数据提取:
```bash
sed -e '/ERROR/d' -e 's/:.*//' my_logs.log | grep -E 'Error|Warning'
```
在这个命令中,sed首先删除包含"ERROR"的行,并且去除冒号及其后的内容。之后,grep搜索包含"Error"或"Warning"的行。
## 5.3 其他文本处理工具的桥梁:grep的扩展功能
### 5.3.1 grep与find命令的结合
虽然grep本身不包含文件搜索功能,但我们可以轻松地与find命令结合,为grep提供搜索的文件列表。一个实用的例子是搜索特定模式的同时限定在特定类型的文件中:
```bash
find . -name "*.txt" -exec grep 'specific_pattern' {} +
```
这条命令会查找当前目录及子目录下所有.txt文件中包含"specific_pattern"的行。
### 5.3.2 利用grep进行管道文本流的过滤
管道是Unix/Linux中一种强大的文本处理机制,可以将一个命令的输出直接作为另一个命令的输入。grep可以作为这些文本流的过滤器,清除不需要的信息。例如,我们想要从复杂的文本数据流中筛选出所需信息:
```bash
some_command | grep -v unwanted_pattern | grep 'desired_pattern'
```
首先,`grep -v unwanted_pattern`将排除掉所有不想要的信息,然后`grep 'desired_pattern'`只保留包含所需信息的行。
通过这些整合使用技巧,我们可以将grep的文本搜索能力与其它工具的强大功能结合,实现更为高效和复杂的文本处理任务。这不仅提高了工作效率,也扩展了grep在文本处理方面的应用范围。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“Linux文本处理工具使用”是一份全面的指南,涵盖了Linux文本处理工具的各个方面,包括awk、sed、grep等。专栏深入探讨了这些工具的高级技巧和实际应用,从基础到高级,为读者提供了全面且实用的知识。专栏还包括案例分析、数据提取和清洗、文本分析工具对比、自动化脚本编写、正则表达式应用、日志文件处理、安全实践和专业技巧等主题,旨在帮助读者成为文本处理专家,有效地解决实际工作中的文本处理挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从0到1:打造SMPTE SDI视频传输解决方案,pg071-v-smpte-sdi应用实践揭秘

# 摘要
随着数字媒体技术的发展,SMPTE SDI视频传输技术已成为广播电视台和影视制作中心的重要标准。本文首先概述了SMPTE SDI技术的原理、标准及接口设备,其次详细分析了基于SMPTE SDI的视频传输解决方案的
【深入探究Word表格边框故障】:原因分析与对策
# 摘要
本论文专注于Word表格边框的构成、功能以及相关的故障类型与影响。通过对表格边框渲染机制和设计原则的理论分析,探讨了软件兼容性、硬件资源限制和用户操作习惯等因素导致的边框故障。提出了一套系统的故障诊断与解决方法,并通过案例分析展示了实际问题的解决过程。最后,论文详细论述了表格边框故障的预防与维护策略,包括建立
【物体建模进阶】:VB布尔运算技巧从入门到精通

# 摘要
本文综合探讨了布尔运算在物体建模领域的理论与实践应用。首先,介绍了布尔运算的基础理论,包括基本概念、规则和性质,并在三维空间中的应用进行了深入分析。其次,通过VB编程语言的实例展示了布尔运算的实现技巧,涵盖了语言基础、内置函数以及代码逻辑优化。文章进一步探讨了布尔运算在3D建模软件中的应用,分析了建模工具的实际案例,并提出了错误处理和优化建议。最后,本文探索了高级布尔建模技巧以及布尔运算在艺术创作中的
【Cortex-M4处理器架构详解】:从寄存器到异常处理的系统剖析
# 摘要
本文全面介绍了Cortex-M4处理器的架构、高级特性和编程技术。首先概述了处理器的核心组成及其基础架构,重点分析了内存管理单元(MMU)的工作原理和异常处理机制。接下来,文中深入探讨了Cortex-M4的高级特性,包括中断系统、调试与跟踪技术以及电源管理策略。然后,文章详细阐述了Cortex-M4的指令集特点、汇编语言编程以及性能优化方法。最后,本文针对Cortex-M4的硬件接口和外设功能,如总线标准、常用外设的控制和外设通信接口进行了分析,并通过实际应用案例展示了实时操作系统(RTOS)的集成、嵌入式系统开发流程及其性能评估和优化。整体而言,本论文旨在为工程师提供全面的Cort
【技术对比】:Flash vs WebGL,哪种更适合现代网页开发?

# 摘要
本文全面比较了Flash与WebGL技术的发展、架构、性能、开发实践以及安全性与兼容性问题,并探讨了两者的未来趋势。文章首先回顾了Flash的历史地位及WebGL与Web标准的融合,接着对比分析了两者在功能性能、第三方库支持、运行时表现等方面的差异。此外,文章深入探讨了各自的安全性和兼容性挑战,以及在现
零基础LabVIEW EtherCAT通讯协议学习手册:起步到精通
# 摘要
随着工业自动化和控制系统的不断发展,LabVIEW与EtherCAT通讯协议结合使用,已成为提高控制效率和精度的重要技术手段。本文首先介绍了LabVIEW与EtherCAT通讯协议的基础概念和配置方法,然后深入探讨了在LabVIEW环境下实现EtherCAT通讯的编程细节、控制策略以及诊断和错误处理。接下来,文章通过实际应用案例,分析了La
51单片机电子密码锁设计:【项目管理】与【资源规划】的高效方法
# 摘要
本文综述了51单片机电子密码锁的设计与实现过程,并探讨了项目管理在该过程中的应用。首先,概述了51单片机电子密码锁的基本概念及其在项目管理理论与实践中的应用。接下来,深入分析了资源规划的策略与实
【探索TouchGFX v4.9.3高级功能】:动画与图形处理的终极指南

# 摘要
TouchGFX作为一个面向嵌入式显示系统的图形库,具备强大的核心动画功能和图形处理能力。本文首先介绍了TouchGFX v4.9.3的安装与配置方法,随后深入解析了其核心动画功能,包括动画类型、实现机制以及性能优化策略。接着,文中探讨了图形资源管理、渲染技术和用户界面优化,以提升图形处理效率。通过具体案例分析,展示了TouchGFX
【Docker持久化存储】:阿里云上实现数据不丢失的3种方法
# 摘要
本文详细探讨了Docker持久化存储的概述、基础知识、在阿里云环境下的实践、数据持久化方案的优化与管理,以及未来趋势与技术创新。首先介绍了Docker卷的基本概念、类型和操作实践,然后聚焦于阿里云环境,探讨了如何在阿里云ECS、RDS和NAS服务中实现高效的数据持久化。接着,文章深入分析了数据备份与恢复策略,监控数据持久化状态的重要性以及性能优化与故障排查方法。最后,展望了
【编程进阶之路】:ITimer在优化机器人流程中的最佳实践

# 摘要
ITimer作为一种定时器技术,广泛应用于编程和机器人流程优化中。本文首先对ITimer的基础知识和应用进行了概述,随后深入探讨了其内部机制和工作原理,包括触发机制和事件调度中的角色,以及核心数据结构的设计与性能优化。文章进一步通过具体案例,阐述了ITimer在实时任务调度、缓存机制构建以及异常处理与恢复流程中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )