Redis集群搭建与配置
发布时间: 2024-02-23 07:07:43 阅读量: 55 订阅数: 36 

Redis总结配置文件说明,集群搭建
# 1. Redis集群概述
## 1.1 Redis集群的优势
Redis集群具有以下优势:
- **高性能**:集群可以通过多个节点并行处理请求,提高了整体性能。
- **高可用性**:节点间可以相互备份,一旦某个节点宕机,集群仍然可以继续工作。
- **横向扩展**:可以轻松地向集群中增加新的节点,以支持更大的数据量和更高的并发请求。
## 1.2 Redis集群的应用场景
Redis集群适用于以下场景:
- **大规模数据缓存**:适用于需要快速读写大规模数据的场景,例如电商网站、社交媒体等。
- **实时分析**:支持实时分析大规模数据流,例如统计分析、实时监控等。
- **会话存储**:适用于需要快速存取会话信息的场景,例如在线游戏、即时通讯等。
## 1.3 Redis集群架构和原理
Redis集群采用主从复制和数据分片的方式进行架构,其中包括以下要点:
- **主从复制**:实现数据的备份和读写分离,提高了系统的可用性和性能。
- **数据分片**:将数据分散存储在多个节点上,实现了数据的横向拓展和负载均衡。
- **故障转移**:集群中的Sentinel或Cluster可以自动进行故障转移和节点恢复,保障了系统的稳定运行。
以上是关于Redis集群概述的相关内容,接下来我们将深入介绍Redis集群的搭建与配置。
# 2. 环境准备与部署
在搭建Redis集群之前,我们首先需要进行环境准备与部署工作。这包括服务器准备与配置、安装Redis并进行基本配置,以及准备集群所需的工具与资源。
### 2.1 服务器准备与配置
在搭建Redis集群之前,需要准备适当数量的服务器作为节点。通常,一个最小的Redis集群需要包含至少3个主节点。在实际部署中,可以选择虚拟机或物理机作为Redis节点,确保服务器有足够的内存和磁盘空间,并且具备良好的网络连接。
在选择服务器时,需要考虑以下因素:
- 服务器性能:包括CPU、内存、磁盘等硬件配置
- 网络环境:保证服务器之间的网络延迟和带宽
- 可用性:部署在不同的机架或数据中心,确保高可用性
### 2.2 安装Redis并进行基本配置
选择好服务器后,需要在每台服务器上安装Redis,并进行基本的配置。这包括设置Redis的监听地址、端口、数据持久化方式等。以下是一个简单的示例,假设我们使用的是Ubuntu操作系统:
```bash
# SSH登录到目标服务器
ssh user@hostname
# 安装Redis
sudo apt update
sudo apt install redis-server
# 配置Redis
sudo vim /etc/redis/redis.conf
```
在`redis.conf`中,可以设置Redis的监听地址和端口等配置项,根据具体的需求进行调整。
### 2.3 准备集群所需的工具与资源
搭建Redis集群还需要准备一些工具和资源,以便后续的操作和管理。这些工具可能包括:
- Redis客户端:用于连接和操作Redis集群
- 监控工具:用于实时监控集群状态和性能指标
- 故障处理工具:用于处理集群节点的故障和异常情况
此外,还需要考虑集群的安全策略、数据备份方案等,确保Redis集群的稳定运行和安全性。
以上是环境准备与部署的基本工作,接下来我们将进入第三章,详细讨论Redis集群的搭建方法及具体步骤。
# 3. 搭建Redis集群
在这一章中,我们将详细介绍如何搭建Redis集群。Redis提供了多种搭建集群的方法,其中比较常用的包括使用Redis Sentinel和使用Redis Cluster。接下来我们将逐步介绍这两种方法的具体步骤和操作。
#### 3.1 Redis集群的搭建方法比较
在搭建Redis集群时,我们可以选择使用Redis Sentinel或Redis Cluster。Redis Sentinel通过监控Master和Slave节点的健康状况,实现自动故障迁移和节点配置更新;而Redis Cluster则是Redis官方提供的分布式集群解决方案,具有自动分片、数据复制和故障恢复的功能。下面我们将分别介绍这两种方法的搭建步骤。
#### 3.2 使用Redis Sentinel搭建集群
Redis Sentinel是一种高可用性解决方案,可以监控Redis实例的运行状况,实现自动的故障转移和故障恢复。以下是使用Redis Sentinel搭建集群的简要步骤:
1. 配置多个Redis实例,包括Master和Slave节点。
2. 启动Redis Sentinel,并配置监控的Master实例。
3. 监控Master实例的健康状况,当Master节点宕机时,自动选举新的Master节点。
4. 将Client连接到Sentinel提供的服务端口,Sentinel会将Client重定向到正确的Master节点上。
```python
# Python示例:使用redis-py库连接到Redis Sentinel
import redis
sentinel = redis.StrictRedisSentinel([('sentinel_host1', 26379), ('sentinel_host2', 26379)], socket_timeout=0.1)
master = sentinel.master_for('mymaster', socket_timeout=0.1)
# 写入数据
master.set('key1', 'value1')
# 读取数据
print(master.get('key1'))
```
**代码说明:**
- 通过redis-py库连接到Redis Sentinel,配置Sentinel节点的地址和端口。
- 获取Master节点的连接实例,并进行数据的读写操作。
- 使用Sentinel实现了Master节点的自动故障转移,确保高可用性。
#### 3.3 使用Redis Cluster搭建集群
Redis Cluster是Redis官方提供的分布式集群解决方案,具有自动分片、数据复制和故障恢复的功能。以下是使用Redis Cluster搭建集群的简要步骤:
1. 配置多个Redis实例作为Cluster的节点,并启动各个节点。
2. 使用redis-cli工具创建Redis Cluster,并将各个节点加入到Cluster中。
3. 进行数据的读写操作,Redis Cluster会自动进行数据分片和负载均衡。
4. 监控Cluster节点的运行状态,及时处理故障和扩缩容操作。
```java
// Java示例:使用Jedis连接到Redis Cluster
JedisCluster jedisCluster = new JedisCluster(new HostAndPort("127.0.0.1", 6379));
// 写入数据
jedisCluster.set("key1", "value1");
// 读取数据
String value = jedisCluster.get("key1");
System.out.println(value);
```
**代码说明:**
- 使用Jedis连接到Redis Cluster,指定任一Cluster节点的地址和端口。
- 通过JedisCluster实例进行数据的读写操作,Redis Cluster会自动处理数据的分片和路由。
- 可以通过监控Cluster的运行状态,实现集群的管理和维护。
通过以上代码示例和操作步骤,我们可以清晰地了解如何使用Redis Sentinel和Redis Cluster搭建Redis集群,实现数据的高可用和分布式存储。
# 4. 集群节点的配置与管理
在搭建好Redis集群之后,我们需要进行集群节点的配置和管理,以确保集群的稳定运行和高效管理。本章将介绍如何配置Redis节点,并对集群节点的监控、故障处理、扩容与缩减进行详细说明。
#### 4.1 配置Redis节点
配置Redis节点是保证Redis集群正常运行的重要环节,我们需要关注以下几点:
- 节点配置文件:每个Redis节点都有自己的配置文件,需要确保配置文件的正确性,包括端口、日志路径、持久化配置等。
- IP绑定和端口:确保每个节点的IP地址和端口配置正确,以便节点能够相互通信。
- 集群槽分配:通过命令为每个节点分配正确的槽(slot),确保数据在集群中的正确分布。
```python
# Python 示例代码
# 配置Redis节点
import redis
# 连接到Redis节点
r = redis.StrictRedis(host='localhost', port=6379, db=0)
# 手动分配槽(slot)
# cluster addslots <slot> [<slot> ...]
r.execute_command('cluster', 'addslots', 0)
r.execute_command('cluster', 'addslots', 1)
# ... 其他槽的分配
# 检查槽分配情况
# cluster nodes
print(r.execute_command('cluster', 'nodes'))
```
**代码总结:** 以上示例中使用Python连接到Redis节点,并手动为节点分配槽(slot),然后检查槽的分配情况。
**结果说明:** 执行以上代码后,可以通过`cluster nodes`命令查看节点信息,确保槽分配正确。
#### 4.2 集群节点的监控与故障处理
监控Redis集群节点的健康状态是非常重要的,及时发现故障并进行处理可以确保集群的高可用性。
- 使用Redis Sentinel进行监控:配置并启动Redis Sentinel来监控集群中的节点,及时发现主节点故障并进行自动故障转移。
- 处理故障节点:当节点出现故障时,及时进行故障处理,可以是手动或自动的方式来恢复节点的正常运行。
```java
// Java 示例代码
// 集群节点监控与故障处理
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import redis.clients.jedis.exceptions.JedisConnectionException;
// 使用Jedis Sentinel进行监控
JedisSentinelPool sentinelPool = new JedisSentinelPool("mymaster", "sentinel1:26379");
try (Jedis jedis = sentinelPool.getResource()) {
// 监控节点健康状态
String info = jedis.info("sentinel");
System.out.println(info);
} catch (JedisConnectionException e) {
// 处理故障节点
System.out.println("节点故障:" + e.getMessage());
}
```
**代码总结:** 上述Java示例代码演示了如何使用Jedis Sentinel进行节点监控,并在发现故障时进行相应的处理。
**结果说明:** 当节点正常运行时,监控信息会输出到控制台,当节点发生故障时,会捕获到JedisConnectionException异常。
#### 4.3 Redis集群的扩容与缩减
随着业务的扩展或收缩,可能需要对Redis集群进行节点的扩容或缩减,以满足业务需求。
- 扩容:向集群中添加新的节点,并将部分槽分配给新节点,确保数据在集群中的平衡分布。
- 缩减:从集群中移除节点,并将节点上的槽重新分配给其他节点,确保数据不会丢失并且保持平衡。
```go
// Go 示例代码
// Redis集群的扩容与缩减
package main
import "github.com/go-redis/redis"
func main() {
client := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{"node1:6379", "node2:6379"},
})
// 扩容:添加新节点
client.AddClusterNode("newnode:6379")
// 缩减:移除节点
client.RemoveClusterNode("removenode:6379")
}
```
**代码总结:** 以上Go示例代码演示了如何使用go-redis包实现对Redis集群的扩容和缩减操作。
**结果说明:** 根据实际情况执行扩容或缩减操作,确保集群的稳定和平衡运行。
以上是关于Redis集群节点的配置与管理的内容,通过本章节的学习,可以更好地了解如何对Redis集群进行节点的配置和管理,以及应对节点故障和扩容缩减的操作。
# 5. 数据持久化与备份
在Redis集群中,数据的持久化和备份是非常重要的,可以保证数据的安全性和可靠性。本章将介绍Redis集群中数据持久化与备份的策略和实践。
#### 5.1 Redis数据持久化配置
在Redis集群中,可以通过配置持久化方式来保证数据在重启或故障时不会丢失。Redis支持的持久化方式包括RDB快照和AOF日志。
##### 场景
假设我们需要配置Redis集群的数据持久化方式为AOF日志模式,以保证数据在每个写操作发生时都能被持久化到磁盘。
##### 代码
```shell
# 进入Redis集群配置文件目录
cd /etc/redis
# 编辑redis.conf文件,设置AOF持久化模式
vi redis.conf
```
在`redis.conf`文件中找到如下配置,并修改为AOF模式:
```shell
appendonly yes
```
保存并退出文件,然后重启Redis集群使配置生效:
```shell
# 重启Redis服务
redis-server /etc/redis/redis.conf
```
##### 代码总结
通过修改`redis.conf`配置文件,将`appendonly`选项设置为`yes`,即可启用AOF持久化模式。
##### 结果说明
此时Redis集群已经配置为AOF持久化模式,保证了数据每次写入都会被持久化到磁盘中,提高了数据的安全性和可靠性。
#### 5.2 Redis集群的数据备份策略
除了数据持久化,数据备份也是非常重要的,能够在灾难发生时快速恢复数据。
##### 场景
我们将介绍如何使用Redis的`bgsave`命令进行集群数据的备份。
##### 代码
```shell
# 进入任意一台Redis集群节点服务器
ssh redis_node1
# 启动bgsave备份
redis-cli bgsave
```
##### 代码总结
通过SSH登录到Redis集群节点服务器,然后使用`redis-cli bgsave`命令,可以在后台异步进行数据备份。
##### 结果说明
当备份完成后,Redis会在当前数据目录生成`dump.rdb`文件,该文件即为Redis集群的完整数据备份。可以将该文件拷贝到其他安全存储设备中,以便在需要时进行数据恢复。
#### 5.3 数据恢复与灾备
在面临数据灾难时,能够快速恢复数据是至关重要的。本节将介绍如何在Redis集群中进行数据恢复和灾备。
##### 场景
假设我们需要从备份文件恢复Redis集群数据,并确保Redis集群正常工作。
##### 代码
```shell
# 将备份文件拷贝到指定Redis节点服务器的数据目录
scp /path/to/dump.rdb redis_node1:/var/lib/redis/
scp /path/to/dump.rdb redis_node2:/var/lib/redis/
# 在Redis节点服务器上,启动Redis服务
systemctl start redis
```
##### 代码总结
将备份的`dump.rdb`文件通过`scp`命令拷贝到各个Redis节点的数据目录下,然后通过启动Redis服务,即可完成数据恢复。
##### 结果说明
经过数据恢复后,Redis集群将恢复到备份文件所对应的状态,确保数据完整性和可用性。
以上是关于Redis集群中数据持久化与备份的配置和实践,通过合理的持久化策略和灾备措施,可以确保Redis集群的数据安全和可靠性。
# 6. 性能优化与安全策略
在Redis集群的运维过程中,性能优化和安全策略是非常重要的环节。通过合理的性能调优和严密的安全措施可以保障Redis集群的稳定运行和数据安全。本章将介绍如何进行性能优化以及制定安全策略。
#### 6.1 Redis集群的性能优化
在实际应用中,Redis的性能优化至关重要。以下是一些常见的性能优化措施:
- **合理选择数据结构**:根据实际场景选择合适的数据结构,如string、hash、set、zset等,以提高操作效率。
- **合理设置过期时间**:对于不需要持久保存的数据,可以设置适当的过期时间,避免数据堆积,节省内存空间。
- **批量操作和Pipeline**:尽量减少网络通信开销,可以使用Pipeline一次性发送多个命令,减少网络延迟。
- **使用连接池**:维护连接池可以减少每次建立连接和断开连接的开销,提高性能。
- **集群分片**:合理设置数据分片,避免单个节点负载过高,提高整个集群的处理能力。
- **避免频繁的大key操作**:大key操作会阻塞Redis服务器,影响整个集群性能,需要谨慎使用。
- **开启AOF持久化**:AOF持久化可以避免数据丢失,保证数据的安全性,但会对性能产生一定影响,可以根据实际情况进行配置。
```python
import redis
# 创建Redis连接
r = redis.Redis(host='localhost', port=6379)
# 设置key-value
r.set('mykey', 'Hello Redis!')
# 获取value
value = r.get('mykey')
print(value)
```
**代码总结**:以上代码演示了如何使用Python的redis库连接Redis并进行简单的set和get操作。
**结果说明**:执行上述代码后,会在Redis中设置一个key为"mykey",值为"Hello Redis!",然后再获取该key的值并打印输出。
#### 6.2 集群的安全配置与策略
保障Redis集群的数据安全是至关重要的,以下是一些安全配置和策略的建议:
- **访问控制**:通过密码认证或者IP白名单的方式控制访问权限,避免未授权访问。
- **持久化和备份**:定期进行数据备份,保障数据不会因意外丢失,同时设置持久化机制保证数据的持久性。
- **监控和告警**:建立监控系统,监控Redis集群的运行状态,及时发现并解决问题。
- **定期安全审计**:定期对Redis集群进行安全审计,发现潜在安全风险并加以修复。
- **定时更新和漏洞修复**:及时更新Redis版本,修复已知漏洞,提高系统的安全性。
- **SSL加密传输**:如果数据传输过程中涉及敏感信息,可以考虑使用SSL加密传输,确保数据安全。
综上所述,性能优化和安全策略是保障Redis集群稳定运行和数据安全的重要手段,运维人员需要结合实际情况不断优化和完善。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODB++数据结构深度剖析:揭秘其在PCB设计中的关键作用

# 摘要
本文系统介绍了ODB++数据结构的理论基础及其在PCB设计中的应用,并对其在实际案例中的效果进行了分析。首先,概述了ODB++数据结构的发展历程,阐述了其数据模型的核心构成及其优势与挑战。随后,深入探讨了ODB++在PCB设计中如何管理设计数据、集成制造信息,以及其在供应链中的作用。通过比较ODB++与其他数据格式,分析了其在设计流程优化、效率提升及问题解决策略中的应用。最后,
激光对刀仪工作原理全解析:波龙型号深度剖析

# 摘要
本文详细介绍了激光对刀仪的工作原理、结构与功能以及维护与校准方法,并通过案例分析展示了其在制造业和高精度加工中的应用。文章首先概述了激光对刀仪的基本概念及其工作原理,包括激光技术基础和对刀仪的测量机制。随后,文章深入探讨了波龙型号激光对刀仪的结构设计特点和功能优势,并对日常维护和精确校准流程进行了阐述。通过实际应用案例,本文分析了波龙型号在
【文档转换专家】:掌握Word到PDF无缝转换的终极技巧
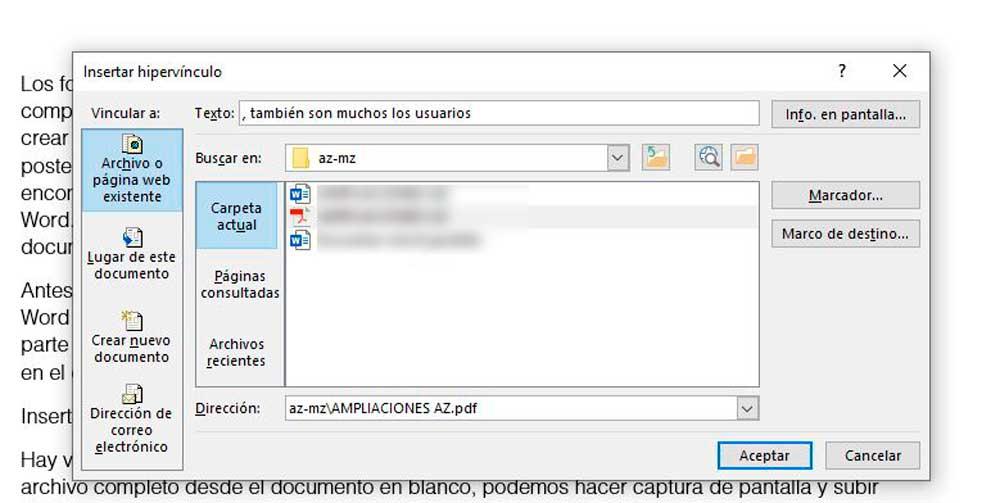
# 摘要
文档转换是电子文档处理中的一个重要环节,尤其是从Word到PDF的转换,因其实用性广泛受到关注。本文首先概述了文档转换的基础知识及Word到PDF转换的必要性。随后,深入探讨了转换的理论基础,包括格式转换原理、Word与PDF格式的差异,以及转换过程中遇到的布局、图像、表格、特殊字符处理和安全可访问性挑战。接着,文章通过介绍常用转换工具,实践操作步骤及解决
【揭秘MTBF与可靠性工程】:掌握MIL-HDBK-217F核心标准的终极指南(附10个行业案例分析)
# 摘要
本文系统阐述了MTBF(平均无故障时间)在可靠性工程中的核心地位,并深入分析了MIL-HDBK-217F标准。文中不仅详细介绍了MTBF的定义、计算方法及修正因子,还探讨了该标准下可靠性预测模型的构建与应用。进一步地,本文展示了MTBF在产品设计、生产监控以及售后服务与维护中的具体运用,并通过电子、航空航天以及汽车制造业等行业案例,分析了MTBF的实践成效与挑战。在展望未来趋势时,本文探讨了新技术如人工智能与物联网设备对MTBF预测的影响,以及全球范围内可靠性工程的标准化进程。最后,专家视角章节总结了MTBF在不同行业中的作用,并提出了提升整体可靠性的策略建议。
# 关键字
MTB
Fluent UDF实战速成:打造你的第一个用户自定义函数

# 摘要
Fluent UDF(User Defined Functions)为流体仿真软件Fluent提供了强大的自定义能力,使用户能够扩展和定制仿真功能以满足特定需求。本文旨在为初学者提供
【通达信公式深度解析】:数据结构与市场分析,专家带你深入解读
# 摘要
通达信公式作为股票市场分析中的重要工具,其基础知识、数据结构以及应用是投资者和技术分析师必须掌握的关键技能。本文全面介绍了通达信公式的基础知识,深入分析了其数据结构,包括数据类型、数组、链表和树等,以及数据操作如增加、删除、查找和排序等。文章进一步探讨了通达信公式在市场趋势分析和交易策略中的应用,阐述了如何基于公式生成交易信号,评估和控制交易风险。此外,本文还
计算机二级Python编程实践:字符串处理与案例深度分析

# 摘要
字符串处理是编程中的基础且关键技能,尤其在数据处理和文本分析中占据重要地位。本文从基础理论入手,深入介绍了字符串的基本操作、高级应用及正则表达式在字符串处理中的作用。通过对Python中字符串处理实践的探讨,展现了字符串方法在文本分析、网络数据处理以及数据清洗方面的具体应用。本文还详细分析了字符串处理
查找表除法器设计原理与实践:Verilog中的高效实现方法

# 摘要
本文详细探讨了查找表除法器的设计原理及其在硬件描述语言Verilog中的实现。首先,从查找表除法器的设计原理入手,概述了其工作机制和构建方法。随后,深入到Verilog语言的基础知识,包括语法、模块设计、数值表示、运算方法,以及代码仿真与测试。在实现技巧章节中,本文详细介绍了提高查找表效率的优化技术,如数据结构优化和分配策略,并对查找表除法器的性能进行了评估。文章还提供了查找表除法器在
NetMQ在Unity中的部署与管理:通信协议详解及案例分析
# 摘要
本文全面介绍NetMQ在Unity游戏开发环境中的应用,包括基础概念、部署、高级应用、案例研究以及问题诊断与解决方案。首先,文章提供了NetMQ和Unity的简介,然后详细说明了NetMQ在Unity环境中的安装、配置和基本通信协议。接着,文章探讨了NetMQ在Unity中的高级应用,包括场景间通信、性能优化和多线程技术。案例研究章节通过实时多人游戏通信和物联网项目,展示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )