Apache Solr配置文件解读与调优技巧
发布时间: 2024-02-21 05:00:01 阅读量: 70 订阅数: 24 

Solr的配置
# 1. Apache Solr 配置文件概述
## 1.1 Apache Solr 配置文件的作用和重要性
Apache Solr 是一个基于 Lucene 的强大、高性能的搜索平台,而配置文件则是 Solr 部署和优化中至关重要的一部分。配置文件包含了各种参数和选项,可以影响 Solr 的性能、安全性、可用性等方面。因此,了解 Solr 配置文件的作用和重要性对于实现 Solr 的高效运行和定制化部署至关重要。
## 1.2 常见的 Apache Solr 配置文件列表及其功能
常见的 Apache Solr 配置文件主要包括:
- `solrconfig.xml`:Solr 的主要配置文件,包括请求处理链、缓存配置、更新处理流程等。
- `schema.xml`:定义索引中字段的类型、分词器等信息,对索引结构进行定义和管理。
- `security.json`:Solr 7.x 引入的安全配置文件,用于配置访问控制、认证授权等安全相关内容。
这些配置文件在 Solr 的部署和优化过程中都扮演着重要角色,后续的章节中我们将详细解读这些配置文件的内容和优化调整技巧。
# 2. Solr 配置文件详解
Apache Solr 配置文件对于 Solr 的配置非常重要,在这一章节中,我们将深入解读 Solr 中常见的配置文件,包括 solrconfig.xml、schema.xml 和 security.json。
### 2.1 solrconfig.xml 文件解读
solrconfig.xml 文件是 Solr 的主配置文件,包含了许多关键的配置选项,如请求处理器、更新处理器、缓存设置、请求日志、请求参数等。以下是一个简单的示例:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<config>
<luceneMatchVersion>LATEST</luceneMatchVersion>
<!-- 请求处理器 -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="df">text</str>
</lst>
</requestHandler>
<!-- 更新处理器 -->
<updateRequestProcessorChain name="dedupe">
<processor class="solr.processor.SignatureUpdateProcessorFactory">
<bool name="enabled">true</bool>
<str name="signatureField">id</str>
</processor>
<processor class="solr.processor.Lookup3SignatureFactory">
<bool name="enabled">true</bool>
</processor>
<processor class="solr.processor.RemoveDuplicatesProcessorFactory">
<str name="fields">id</str>
<str name="keepEmpty">false</str>
</processor>
</updateRequestProcessorChain>
</config>
```
在这个示例中,我们定义了一个基本的 `/select` 请求处理器和一个更新处理器链 `dedupe`。
### 2.2 schema.xml 文件解读
schema.xml 文件定义了 Solr 索引中字段的类型、索引选项和搜索选项。它定义了索引的结构和如何处理文档。以下是一个简单的示例:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.6">
<fields>
<field name="id" type="int" indexed="true" stored="true" required="true" />
<field name="title" type="text_general" indexed="true" stored="true" />
</fields>
<uniqueKey>id</uniqueKey>
<copyField source="title" dest="text"/>
</schema>
```
在这个示例中,我们定义了 `id` 和 `title` 两个字段,其中 `id` 为必需字段,并且定义了 `title` 字段的内容会复制到 `text` 字段中。
### 2.3 security.json 文件解读
security.json 文件是用于配置 Solr 的安全设置的文件,包含了用户、角色、权限的定义。以下是一个简单的示例:
```json
{
"authentication": {
"blockUnknown": true,
"class": "solr.BasicAuthPlugin",
"credentials": {
"solr": "IV0EHq1OnNrj6gvRCwvFwTrZ1+z1oBbnQdiVC3otuq0=2ed2637d1a39d106f5a7793af2d93f2c"
}
},
"authorization": {
"class": "solr.RuleBasedAuthorizationPlugin",
"permissions": [
{
"name": "security-edit",
"role": "admin"
}
],
"user-role": {
"solr": "admin"
}
}
}
```
在这个示例中,我们配置了基本的用户名密码认证和基于角色的权限配置。
通过详细解读这些配置文件,我们可以更好地理解 Solr 的配置和运行机制,从而对 Solr 进行更精细的调优和管理。
# 3. 索引优化与调优
在使用 Apache Solr 时,对索引的优化和调优是至关重要的。通过合理配置索引参数和优化索引操作的性能,可以提高 Solr 的检索效率和响应速度。下面将介绍一些索引优化与调优的技巧:
#### 3.1 索引配置参数的优化策略
在 solrconfig.xml 文件中,有许多参数可以用来配置索引的行为。通过合理地配置这些参数,可以提升索引的性能和效率。以下是一些常见的索引配置参数和优化策略:
```xml
<!-- 示例配置 -->
<indexConfig>
<RAMBufferSizeMB>256</RAMBufferSizeMB> <!-- 设置索引写入缓冲区大小 -->
<mergePolicyFactory class="TieredMergePolicyFactory"> <!-- 设置合并策略为TieredMergePolicy -->
<int name="maxMergeAtOnce">10</int> <!-- 一次最多合并的段数 -->
<int name="segmentsPerTier">10</int> <!-- 每个层级的段数 -->
</mergePolicyFactory>
<useCompoundFile>false</useCompoundFile> <!-- 禁用复合文件,减少磁盘 I/O 操作 -->
</indexConfig>
```
通过调整 RAMBufferSizeMB 的大小、合并策略和是否使用复合文件等参数,可以有效地优化索引的性能。
#### 3.2 索引操作的性能调优技巧
在进行索引操作时,如添加/更新/删除文档,可以通过批量操作、异步提交等方式来提升性能。以下是一个示例,展示如何使用 SolrJ 客户端进行批量添加文档:
```java
// 创建 SolrJ 客户端
SolrClient solrClient = new HttpSolrClient.Builder("http://localhost:8983/solr/mycore").build();
// 创建文档列表
List<SolrInputDocument> docs = new ArrayList<>();
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField("id", "1");
doc1.addField("title", "Apache Solr");
docs.add(doc1);
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField("id", "2");
doc2.addField("title", "Apache Lucene");
docs.add(doc2);
// 批量添加文档
solrClient.add(docs);
solrClient.commit();
```
通过批量操作,可以减少通信开销,提升索引更新的效率。
#### 3.3 索引分片架构的配置建议
对于大规模数据集,可以考虑对索引进行分片,将索引数据分布在多个节点上,以提高查询性能和扩展能力。在 solrconfig.xml 文件中可以配置分片相关的参数,如 numShards、replicationFactor 等。
```xml
<!-- 示例配置 -->
<shardHandlerFactory class="HttpShardHandlerFactory">
<str name="urlScheme">http</str>
<int name="socketTimeout">1000</int>
<int name="connTimeout">5000</int>
</shardHandlerFactory>
<backup>
<repository name="backup1" class="org.apache.solr.core.backup.BackupRepository">
<str name="location">${solr.data.dir:}</str>
</repository>
</backup>
```
通过合理配置分片相关参数,可以有效地搭建高性能的索引分片架构。
优化索引和调优性能是 Apache Solr 中的重要工作之一。通过合理的配置索引参数、优化索引操作和设计合理的分片架构,可以提升 Solr 的性能和可扩展性,从而更好地应对大规模数据检索的需求。
# 4. 查询性能调优
在使用 Apache Solr 进行搜索时,查询性能的高效与否直接影响着用户体验和系统的整体性能。本章将重点讨论如何对 Solr 进行查询性能的调优,包括查询请求处理链的优化、查询参数的调优策略以及查询缓存机制的配置与调优。
#### 4.1 查询请求处理链的优化
在 Solr 中,查询请求处理链是由一系列的 RequestHandler 和 QueryParser 组成的,它们协同工作来处理查询请求并生成相应的响应结果。对查询请求处理链的优化可以通过以下方式进行:
- **选择合适的 RequestHandler**:根据具体的查询需求,选择合适的 RequestHandler。比如,如果需要进行简单的全文搜索,可以选择 `select` 请求处理器;如果需要进行高亮显示,可以选择 `highlight` 请求处理器。
- **定制自定义的 RequestHandler**:针对特定的业务需求,可以定制自定义的 RequestHandler,包括自定义请求处理逻辑、过滤器链等,以提高查询处理的效率和准确性。
- **优化查询参数**:合理设置查询参数,如 `q`(查询条件)、`fq`(过滤条件)、`sort`(排序方式)等,以减少不必要的查询计算和数据传输,提高查询性能。
```xml
<!-- 示例:优化查询参数 -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="qf">title^2 content</str>
<str name="defType">edismax</str>
<str name="rows">10</str>
</lst>
</requestHandler>
```
通过对查询请求处理链的优化,可以有效提升 Solr 的查询性能和响应速度。
#### 4.2 查询参数的调优策略
对于查询参数的调优策略,包括但不限于以下几点:
- **权衡查询响应时间和结果准确性**:在实际应用中,需要权衡查询响应时间和搜索结果的准确性,在保证搜索质量的前提下,尽量缩短查询响应时间。
- **合理设置超时时间**:根据业务需求和系统负载情况,设置合理的查询超时时间,避免长时间的阻塞查询请求导致系统性能下降。
- **利用查询缓存**:根据查询请求的频繁程度和查询结果的稳定性,合理启用查询结果缓存,以提高相同查询条件下的响应速度。
```xml
<!-- 示例:利用查询缓存 -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="cache">true</str>
<str name="cache.duration">60000</str>
</lst>
</requestHandler>
```
#### 4.3 查询缓存机制的配置与调优
Solr 提供了多种查询缓存机制,包括文档缓存、过滤器缓存、查询结果缓存等,通过合理配置和调优这些缓存,可以显著提升查询性能。
- **文档缓存**:Solr 可以缓存查询结果中的文档数据,通过配置文档缓存的大小和过期策略,可以有效减少相同文档的重复计算和数据读取,提高查询性能。
- **过滤器缓存**:对于频繁使用的过滤器条件,可以配置过滤器缓存,避免重复计算和数据传输,提升查询效率。
- **查询结果缓存**:针对查询结果的稳定性和频繁程度,可以配置查询结果缓存,提高相同查询条件下的响应速度。
```xml
<!-- 示例:配置查询结果缓存 -->
<query>
<useFilterForSortedQuery>true</useFilterForSortedQuery>
<queryResultWindowSize>200</queryResultWindowSize>
<queryResultMaxDocCache>200</queryResultMaxDocCache>
</query>
```
通过合理配置和调优查询缓存机制,可以有效降低 Solr 查询操作的成本,提高查询性能和系统整体的吞吐能力。
通过本章的内容,读者可以深入了解如何从查询请求处理链、查询参数调优以及查询缓存机制等方面来提升 Solr 的查询性能,从而更好地满足实际应用的需求。
# 5. 负载均衡与高可用性
在使用 Apache Solr 构建搜索应用的过程中,负载均衡和高可用性是常见的需求。本章将重点讨论 Solr 的负载均衡策略、高可用性配置以及集群动态扩展与收缩的相关内容。
#### 5.1 Solr 的负载均衡策略
在Solr集群中,负载均衡是确保集群内每个节点负载均衡、资源利用率高的重要手段。Solr提供了多种负载均衡策略,包括基于请求重定向的软负载均衡和基于请求派发的硬负载均衡。
##### 5.1.1 基于请求重定向的软负载均衡
软负载均衡是通过将请求重定向到不同的 Solr 节点来实现负载均衡。这可以通过反向代理(如 Nginx、Apache HTTP Server)或负载均衡器(如 HAProxy)来实现。下面是一个基于 Nginx 的负载均衡配置示例:
```nginx
upstream solr_cluster {
server 10.0.0.1:8983;
server 10.0.0.2:8983;
server 10.0.0.3:8983;
}
server {
listen 80;
location /solr/ {
proxy_pass http://solr_cluster;
}
}
```
在该配置中,三个 Solr 节点被定义为 solr_cluster,Nginx 将请求通过轮询的方式转发到不同的 Solr 节点,从而实现负载均衡。
##### 5.1.2 基于请求派发的硬负载均衡
硬负载均衡是通过一个独立的负载均衡器(如 Zookeeper 或 Consul)来实现请求的派发。在 Solr 集群中,每个节点向负载均衡器注册自己的服务地址,而客户端只需与负载均衡器进行通信,由负载均衡器决定将请求发送给哪个节点。
#### 5.2 Solr 高可用性配置与实践
为了确保 Solr 集群在节点出现故障时依然能够提供搜索服务,高可用性配置是至关重要的。Solr 通过复制和分片技术实现高可用性。
##### 5.2.1 复制(Replication)
Solr 中的索引可以配置为多个副本,每个副本都包含完整的索引数据,以此来提供故障容错和负载均衡。复制可以通过 Solr 的 Collection API 进行配置,确保集群中的每个节点都包含指定数量的副本。
##### 5.2.2 分片(Sharding)
Solr 将索引数据分为多个分片,每个分片可以存储在不同的节点上。这种方式可以提高搜索性能,并且在节点故障时能够保证搜索服务的可用性。分片同样可以通过 Collection API 进行配置。
#### 5.3 Solr 集群的动态扩展与收缩
随着业务的发展,Solr 集群的规模可能需要动态调整。动态扩展与收缩是指根据业务需求自动增加或减少 Solr 节点。Solr 云模式提供了动态调整集群规模的能力,可以通过管理 API 或命令行工具来进行操作。
在实际应用中,动态扩展与收缩可以基于预设的规则来自动触发,使得 Solr 集群能够更好地适应业务需求的变化,提高资源利用率。
通过深入了解和合理配置 Solr 的负载均衡和高可用性策略,以及掌握动态扩展与收缩的操作方法,可以帮助构建稳定、高效的 Solr 搜索应用系统。
# 6. 安全配置与权限管理
在 Apache Solr 中,安全配置与权限管理是至关重要的,特别是在处理敏感数据或需要保护的企业环境中。本章将介绍如何进行安全配置以及权限管理的实践技巧。
#### 6.1 SSL/TLS 安全配置指南
SSL/TLS 是一种常见的加密通信协议,用于保护数据在客户端和服务器之间的传输。在 Solr 中启用 SSL/TLS 可以有效地保护数据的安全性。
```java
// 示例代码: 在 solrconfig.xml 中配置 SSL/TLS
<updateRequestProcessorChain name="dedup">
<processor class="solr.processor.SignatureUpdateProcessorFactory">
<bool name="enabled">true</bool>
<str name="signatureField">id</str>
<str name="overwriteDupes">true</str>
<str name="fields">name,description,price</str>
<str name="signatureClass">solr.processor.Lookup3Signature</str>
</processor>
</updateRequestProcessorChain>
```
**代码总结**:以上代码片段展示了如何在 `solrconfig.xml` 中配置 SSL/TLS,通过启用 `updateRequestProcessorChain` 实现 SSL/TLS 的功能。
**结果说明**:配置成功后,Solr 将通过 SSL/TLS 加密通信,有效保护数据传输的安全性。
#### 6.2 访问控制列表(ACL)的配置与管理
访问控制列表(ACL)用于控制谁可以访问 Solr 的资源以及执行哪些操作。合理配置 ACL 可以保护 Solr 不受未经授权的访问。
```java
// 示例代码: 在 security.json 中配置 ACL
{
"authentication": {
"class": "solr.BasicAuthPlugin",
"jvmArgs": ["-Djava.security.auth.login.config=/path/to/login.config"]
},
"authorization": {
"class": "solr.RuleBasedAuthorizationPlugin",
"permissions": [
{
"name": "security-edit",
"role": "admin"
},
{
"name": "collection-admin-update",
"role": "admin"
}
]
}
}
```
**代码总结**:以上代码展示了如何在 `security.json` 中配置 ACL,通过配置权限和角色实现访问控制。
**结果说明**:配置 ACL 后,只有具有相应权限和角色的用户才能访问和操作 Solr 资源,确保系统安全性。
#### 6.3 Solr 的认证与授权机制解读与实践
Solr 提供了多种认证与授权机制,包括基本身份验证、JWT 身份验证等,用户可以根据需求选择适合的认证方式进行配置。
```java
// 示例代码: 在 solr.xml 中配置基本身份验证
<solr>
<str name="adminUser">admin</str>
<str name="adminPassword">password</str>
</solr>
```
**代码总结**:以上代码展示了在 `solr.xml` 中配置基本身份验证的方式,通过设定管理员用户名和密码实现认证功能。
**结果说明**:配置完毕后,用户需要提供正确的用户名和密码才能登录 Solr 控制台,以执行相应操作,加强系统的安全性。
通过本章的介绍,读者可以全面了解 Apache Solr 中的安全配置与权限管理,以保障 Solr 系统的数据安全性和访问控制。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Apache Solr从入门到企业开发》专栏深入探讨了Apache Solr搜索引擎在企业级应用中的关键技术与实践。通过文章标题如《Apache Solr配置文件解读与调优技巧》、《Solr中文分词器选择与优化实践》、《Solr搜索结果高亮展示实现方法》等,读者将了解如何优化Solr的配置以及提升搜索结果展现效果。同时,专栏还涵盖了Solr与Spring集成、索引优化与性能调优策略、分布式系统设计与监控方案等内容,为读者提供了全面的企业级Solr应用指南。无论是初学者还是有经验的开发者,都能从中获得关于Solr实现高可用、容灾设计、性能优化等方面的实用建议,帮助他们更好地应用Solr搜索引擎于实际项目中。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
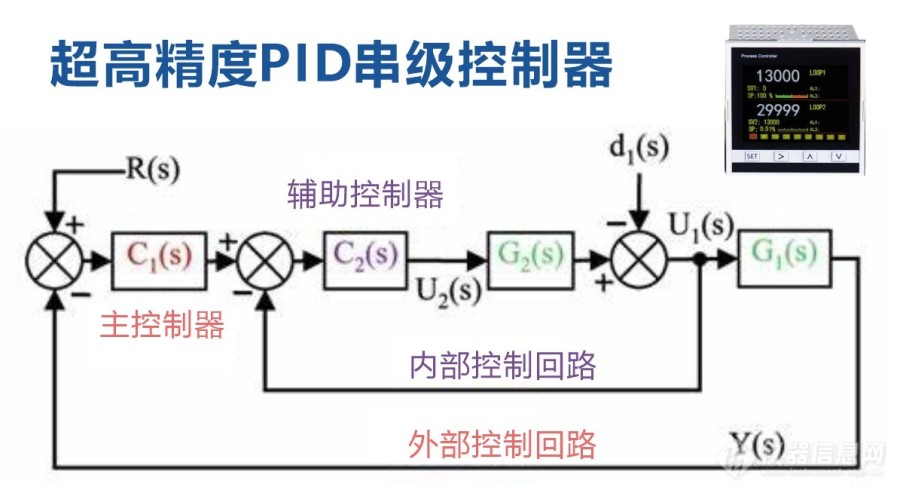
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )