【Python数据压缩实战】:zlib库高级用法深度解析与优化策略
发布时间: 2024-10-11 17:59:33 阅读量: 40 订阅数: 30 

_三维电容层析成像组合电极激励测量模式.pdf

# 1. Python数据压缩的基本概念
在当今的数字化时代,数据量的爆炸性增长已经成为常态。无论是存储在物理介质上的大文件,还是通过网络传输的实时数据流,数据压缩技术都发挥着至关重要的作用。Python,作为一种功能强大的编程语言,其在数据压缩领域也有着广泛的应用。本章节我们将探究Python中数据压缩的基础知识,为后续章节深入探讨zlib库的工作原理和高级用法打下坚实的基础。
数据压缩,简单来说,就是利用一定的算法对数据进行编码,以减少其占用的存储空间或传输带宽。其原理是寻找数据中的冗余部分,并用更短的形式表示它们。根据压缩过程中是否可以完全恢复原始数据,数据压缩可分为无损压缩和有损压缩两大类。无损压缩保证了数据的完整性,常用于文本文件、程序代码或压缩软件中,而有损压缩则在压缩效率和数据完整性之间进行了妥协,广泛应用于多媒体数据的处理,比如图片、音频和视频。
Python的数据压缩库丰富多彩,zlib库是其中的佼佼者。它基于deflate算法,旨在提供一种压缩和解压数据的高效接口,适用于多种应用场景,包括网络通信和文件存储。本章将为读者简要介绍Python中实现数据压缩的基本工具和概念,为深入理解zlib库铺平道路。
# 2. 深入zlib库的内部工作机制
## 2.1 zlib库的数据压缩原理
### 2.1.1 压缩算法的理论基础
zlib库主要基于DEFLATE算法,这是一种广泛使用的数据压缩算法。其核心在于结合了Huffman编码和LZ77(Lempel-Ziv 1977)压缩算法。Huffman编码是一种变长编码技术,它通过为每个字符分配一个不等长的位串来减少数据冗余度;而LZ77算法则是一种基于字典的压缩方法,通过查找重复出现的字符串来减少数据冗余。
为了更深入理解DEFLATE算法,首先要了解几个核心概念:
- **Huffman编码**:根据字符出现的概率来构建最优的前缀编码,使得整体字符编码长度最小。
- **LZ77算法**:使用滑动窗口技术匹配并替换数据流中的重复子串。通过查找历史数据和当前位置的一个匹配串,来代替当前位置的原始数据。
- **固定哈希表**:在LZ77算法中,为了快速搜索到重复串,会建立一个固定大小的哈希表。
### 2.1.2 zlib的压缩流程详解
zlib的压缩流程可以用以下几个步骤概括:
1. **输入数据处理**:将输入数据分解为块(chunk),每块大小可由用户指定,或者使用默认大小。
2. **Huffman编码**:对块内的数据进行Huffman编码,生成Huffman树,然后根据Huffman树来为数据中的字符分配编码。
3. **LZ77压缩**:在Huffman编码的基础上,进一步对数据进行LZ77压缩处理,替换掉重复的序列。
4. **压缩数据输出**:将Huffman编码和LZ77压缩后的数据输出为zlib格式的压缩流。
以下是一段简化的示例代码,展示了如何使用zlib库进行数据压缩:
```python
import zlib
def compress_data(data):
# 压缩数据
compressed_data = ***press(data, level=zlib.Z_BEST_COMPRESSION)
return compressed_data
original_data = b"重复的字符串内容"
compressed_data = compress_data(original_data)
# 输出压缩后的数据
print(f"压缩后的数据: {compressed_data}")
```
在上述代码中,`***press`函数是压缩数据的入口,`level`参数指定了压缩级别。在默认情况下,zlib使用默认的压缩级别,这个级别是平衡速度和压缩效果的一个折衷。
## 2.2 zlib库的数据解压原理
### 2.2.1 解压缩算法的理论基础
数据解压过程则是压缩过程的逆向操作。它需要将zlib格式的压缩数据流还原为原始数据。这同样依赖于DEFLATE算法的逆运算:
- **Huffman解码**:根据存储在压缩流中的Huffman树信息,对Huffman编码进行解码。
- **LZ77解压缩**:对LZ77压缩的数据进行解压缩,将之前用指针替换的重复序列还原为原始数据序列。
- **数据块拼接**:将解压缩后的数据块进行拼接,得到完整的原始数据。
### 2.2.2 zlib的解压流程详解
zlib的解压流程与压缩流程相对应,具体可以分为以下步骤:
1. **读取压缩数据**:读取输入的zlib格式压缩数据。
2. **Huffman解码**:解析压缩数据中的Huffman树,根据树结构解码Huffman编码序列。
3. **LZ77解压缩**:使用解码后的数据和存储的偏移信息,通过LZ77算法还原重复的字符串序列。
4. **数据重组**:将解压缩的数据块重新组合,恢复为原始数据。
以下是一个简单的数据解压缩的示例代码:
```python
def decompress_data(compressed_data):
# 解压缩数据
decompressed_data = zlib.decompress(compressed_data)
return decompressed_data
# 使用之前压缩的数据
decompressed_data = decompress_data(compressed_data)
# 输出解压缩后的数据
print(f"解压缩后的数据: {decompressed_data}")
```
在上述代码中,`zlib.decompress`函数是解压缩操作的入口,它接受zlib格式的压缩数据流,然后进行解压缩,最终返回原始数据。
## 2.3 zlib库的压缩级别和内存管理
### 2.3.1 压缩级别的选择与影响
zlib提供了多个压缩级别,通过调整参数`level`,用户可以指定压缩算法的处理速度和压缩率之间的平衡。zlib定义了以下几种压缩级别:
- **zlib.Z_NO_COMPRESSION**:不压缩数据,速度最快,压缩率最低。
- **zlib.Z_BEST_SPEED**:以最快的速度压缩数据,压缩率较低。
- **zlib.Z_BEST_COMPRESSION**:以最高的压缩率压缩数据,速度较慢。
- **zlib.Z_DEFAULT_COMPRESSION**:默认压缩级别,介于速度和压缩率之间的折衷。
不同压缩级别对系统资源的消耗和压缩效率影响不同,具体选择需要根据应用场景来决定。例如,在网络传输中可能更倾向于速度,而在存储设备中则可能更倾向于压缩率。
### 2.3.2 内存使用优化策略
zlib的压缩和解压缩过程中,内存的使用主要受到几个因素的影响:
- **窗口大小(Window Bits)**:在LZ77算法中,窗口大小决定了查找历史数据的范围。窗口越大,查找匹配字符串的范围越广,但同时消耗的内存也越多。
- **压缩级别**:压缩级别越高,执行压缩操作时可能会使用更多的内存。
- **内部缓冲区**:zlib在内部使用缓冲区来临时存储压缩或解压缩过程中的数据,缓冲区的大小也会影响内存的使用。
为了优化内存使用,可以通过以下方式:
- 根据实际需要选择合适的压缩级别。如果内存非常紧张,可以选择`zlib.Z_BEST_SPEED`级别。
- 如果不需要特别大的窗口大小,可以使用`zlib.Z_MIN_WINDOWBITS`或`zlib.Z_MAX_WINDOWBITS`来限制窗口大小。
- 调整内部缓冲区大小,或者使用流式API以减少一次性内存占用。
以上就是深入zlib库内部工作机制的详细介绍。通过理解其压缩和解压的原理,以及如何选择合适的压缩级别和优化内存使用,你将能够更加高效地使用zlib库进行数据压缩与解压任务。在后续章节中,我们将进一步探讨zlib库的高级用法,并结合实战案例深入理解其在不同场景下的应用。
# 3. zlib库的高级用法
## 使用zlib进行流式压缩与解压
### 流式处理的基本概念
流式处理是指在数据到达时立即进行处理,而不是等待所有数据完全接收后才开始处理。这种处理方式在处理大量数据或需要实时响应的场景下非常有用,例如网络数据传输、大文件处理等。在数据压缩和解压的场景中,流式处理可以显著降低内存消耗,因为不需要一次性加载整个数据集到内存中。
### 流式压缩与解压的实现方法
使用zlib进行流式压缩与解压通常涉及到创建一个`zlib`对象,并在循环中逐步压缩或解压数据块。Python中的`zlib`模块提供了`ZlibFile`类,可以用于流式处理。以下是一个使用`ZlibFile`类进行流式压缩的示例代码:
```python
import zlib
# 假设我们有一个大文件,这里用一个生成器代替
def big_file_data():
# 生成器函数,用于模拟大文件数据流
for chunk in generate_large_file():
yield chunk
def stream_zlib_compression(input_stream):
# 创建一个压缩文件对象
compressed_file = zlib.ZlibFile('compressed_file.gz', 'w')
# 逐块读取原始数据并压缩
for data_chunk in input_stream:
compressed_data = ***press(data_chunk)
compressed_file.write(compressed_data)
# 关闭压缩文件
compressed_file.close()
# 使用流式压缩函数处理大文件
stream_zlib_compression(big_file_data())
```
在这个例子中,`big_file_data`函数模拟了一个大文件的数据流。`stream_zlib_compression`函数则负责打开一个压缩文件,逐块读取原始数据,使用`***press()`进行压缩,并将压缩后的数据写入文件。
流式解压可以使用相似的方法,不同之处在于使用`ZlibFile`的读取模式,并在每次读取时解压数据块。
## 多线程和异步IO中的zlib应用
### 多线程与zlib压缩的结合
多线程可以用来进一步提升流式处理的性能,特别是在多核处理器上。通过将数据流分配给不同的线程进行并行压缩或解压,可以显著提高效率。然而,多线程编程需要考虑线程同步和数据一致性的问题。
```python
import threading
import queue
def thread_worker(input_queue, output_queue):
while not input_queue.empty():
# 从队列中获取数据块
data_chunk = input_queue.get()
# 进行压缩
compressed_data = ***press(data_chunk)
# 将压缩后的数据放入输出队列
output_queue.put(compressed_data)
# 标记任务完成
input_queue.task_done()
def threaded_zlib_compression(input_stream, num_threads=4):
# 创建输入和输出队列
input_queue = queue.Queue()
output_queue = queue.Queue()
# 将数据流的块放入输入队列
for data_chunk in input_stream:
input_queue.put(data_chunk)
# 创建并启动线程
threads = []
for _ in range(num_threads):
thread = threading.Thread(target=thread_worker, args=(input_queue, output_queue))
thread.start()
threads.append(thread)
# 等待所有数据处理完成
input_queue.join()
# 从输出队列中获取压缩后的数据
compressed_data_chunks = []
while not output_queue.empty():
compressed_data_chunks.append(output_queue.get())
# 等待所有线程完成
for thread in threads:
thread.join()
return compressed_data_chunks
# 使用多线程进行流式压缩
threaded_zlib_compression(big_file_data())
```
### 异步IO与zlib压缩的结合
异步IO可以在不阻塞主线程的情况下进行I/O操作,特别适用于I/O密集型应用。在Python 3.5及以上版本中,可以使用`asyncio`库来实现异步编程。结合`zlib`库,可以实现高效的异步压缩和解压。
```python
import asyncio
import zlib
async def async_zlib_compression(input_stream):
compressor = ***pressobj(level=zlib.Z_BEST_COMPRESSION)
async for chunk in input_stream:
compressed_chunk = await loop.run_in_executor(None, ***press, chunk)
yield compressed_chunk
# 创建一个异步生成器,模拟异步读取数据流
async def async_big_file_data():
for chunk in big_file_data():
yield chunk
await asyncio.sleep(0) # 模拟异步操作
# 使用异步流式压缩函数处理数据
async def main():
async for compressed_chunk in async_zlib_compression(async_big_file_data()):
print(compressed_chunk)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
在上面的例子中,`async_zlib_compression`是一个异步生成器,它在异步循环中逐块处理数据,并使用`***pressobj()`进行压缩。我们用一个异步生成器`async_big_file_data`来模拟异步读取大文件。`main`函数中的异步循环负责调用`async_zlib_compression`函数,并逐块输出压缩后的数据。
## 错误处理与异常管理
### 常见的压缩与解压错误
在使用zlib进行压缩和解压的过程中,可能会遇到各种错误。常见的错误包括但不限于:
- `zlib.error`: 当遇到压缩或解压错误时,会抛出此异常。这可能是由于数据损坏或使用不当的压缩设置。
- `IOError`: 当读取或写入压缩数据时发生I/O错误。
- `EOFError`: 当尝试读取压缩流的尾部时,如果压缩流不完整,则会抛出此错误。
### 异常处理的最佳实践
为了编写健壮的压缩和解压代码,应当对可能出现的异常进行捕获和处理。以下是一些处理异常的建议:
1. **捕获和记录异常**: 使用try-except块捕获zlib异常,并将相关信息记录到日志文件中,以便于问题追踪和调试。
2. **提供用户反馈**: 如果异常在用户界面发生,应向用户提供清晰的错误信息,说明发生了什么问题以及如何解决。
3. **优雅地处理I/O错误**: 对于I/O错误,应当尝试重试操作,或者优雅地结束操作,并通知用户操作无法完成。
4. **检查压缩数据的完整性**: 在解压数据前,确保数据流是完整的,并且符合zlib流的格式规范。
5. **资源清理**: 当发生异常时,确保释放所有资源,比如关闭打开的文件句柄,清理临时文件等。
```python
try:
# 假设这里是压缩或解压的代码
pass
except zlib.error as e:
# 记录异常详情到日志文件
log_error(e)
# 向用户显示错误信息
print("压缩或解压时发生错误,请联系管理员。错误信息:", e)
except IOError as e:
# I/O错误的处理
print("发生I/O错误,请检查文件路径或网络连接。错误信息:", e)
except EOFError as e:
# 流不完整错误的处理
print("压缩流不完整,请检查压缩文件是否损坏。错误信息:", e)
finally:
# 释放资源和清理操作
clean_up_resources()
```
在上述代码段中,我们展示了如何使用异常处理来增强程序的健壮性。通过捕获特定异常并执行相应的处理,可以在遇到错误时保持程序的稳定性,并给用户提供有用的反馈。
# 4. ```
# 第四章:Python数据压缩实战案例
随着数字化信息的爆炸性增长,数据压缩已经成为现代软件开发中不可或缺的一部分。Python作为一种广泛使用的高级编程语言,提供了许多强大的数据压缩库,而zlib作为其中一个被广泛应用的库,尤其值得深入探讨。本章节将结合实际案例,深入讨论zlib在不同场景下的具体应用,帮助读者在实战中提升数据处理效率。
## 4.1 压缩大文件
处理大文件是数据压缩常见应用场景之一。在这里,我们将探讨如何利用zlib高效地压缩大文件,并对性能进行优化。
### 4.1.1 大文件处理的策略与方法
当处理大文件时,一次性读取整个文件到内存中进行压缩是不明智的选择,尤其是在内存资源有限的情况下。一个更好的策略是使用流式处理,即边读边写边压缩。这样可以在不消耗大量内存的前提下,逐步完成文件的压缩过程。
zlib库提供了对流式压缩与解压的支持,可以通过其压缩对象的`write`方法来实现。以下是使用zlib进行流式压缩的基本代码结构:
```python
import zlib
def stream_compression(input_file_path, output_file_path):
with open(input_file_path, 'rb') as f_in, \
open(output_file_path, 'wb') as f_out:
compressor = ***pressobj()
while True:
data = f_in.read(1024)
if not data:
break
compressed_data = ***press(data)
f_out.write(compressed_data)
compressed_data = compressor.flush()
f_out.write(compressed_data)
```
### 4.1.2 大文件压缩的性能优化
性能优化是提高大文件压缩效率的关键。其中,重要的优化策略之一是减少I/O操作的次数。在上述代码中,我们每次读取1024字节的数据进行压缩,这样可以有效减少对磁盘的操作次数,从而提高整体的压缩速度。
此外,还可以对压缩级别进行调整,压缩级别越高,压缩效果越好,但压缩所需时间也越长。选择合适的压缩级别是优化性能的关键。例如,可以尝试将压缩级别设置为9(最高压缩级别),并测试不同级别下的压缩性能。
```python
compressor = ***pressobj(level=zlib.Z_BEST_COMPRESSION)
```
在进行性能优化时,还需要考虑数据的特性。对于文本数据,通常可以得到更好的压缩效果;而针对压缩效果较差的二进制数据,可能需要考虑其他优化手段,如预处理数据,或者采用其他压缩算法。
## 4.2 网络传输中的数据压缩
网络传输数据压缩可以有效减少传输数据的大小,提高网络传输效率。本小节将探讨在网络传输中如何应用zlib进行数据压缩,以及如何实现一个高效的压缩方案。
### 4.2.1 网络传输压缩的需求与解决方案
在网络传输中,数据压缩需求主要体现在减少带宽消耗和提升传输速度上。zlib压缩可以被用来减少传输数据的大小,以适应网络带宽的限制,特别是在移动设备和网络条件不佳的情况下,其作用尤为明显。
一个简单的网络压缩解决方案是在服务器端对数据进行压缩,在客户端进行解压缩。这可以通过HTTP请求的`Content-Encoding`头部来实现。服务器端使用zlib进行数据压缩,客户端在接收到数据后,根据`Content-Encoding`头部的提示,使用zlib库对数据进行解压。
### 4.2.2 实现网络传输压缩的示例代码
以下示例代码展示了如何在Python中实现一个简单的HTTP服务器,该服务器对发送的响应数据进行zlib压缩,并通过HTTP头部通知客户端进行解压缩:
```python
import http.server
import socketserver
import zlib
class CompressHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
# 数据压缩
self.send_response(200)
self.send_header('Content-Encoding', 'deflate')
self.end_headers()
compressor = ***pressobj()
compressed_data = ***press(self.rfile.read())
compressed_data += compressor.flush()
self.wfile.write(compressed_data)
with socketserver.TCPServer(("", 8000), CompressHandler) as httpd:
print("serving at port", 8000)
httpd.serve_forever()
```
在客户端,需要确保接收到的响应数据通过zlib进行解压缩。这通常是由浏览器或网络库自动完成的。在某些情况下,可能需要手动处理压缩数据,可以使用类似服务器端的代码逻辑进行解压缩。
## 4.3 数据库存储优化
数据库存储优化是指通过减少存储空间来提高数据存储和查询效率,这对于提升数据库性能尤为重要。本小节将探索zlib在数据库存储中的应用和压缩策略。
### 4.3.1 数据库中存储压缩数据的优势
在数据库中存储压缩后的数据能够大幅度减少存储空间的使用。这样做不仅可以减少存储硬件的投入,还能提升查询性能,因为更少的数据意味着更快的读写速度。
然而,需要注意的是,压缩数据对CPU资源的需求较高。因此,在考虑是否压缩数据时,需要权衡存储空间节省与CPU性能损耗之间的关系。
### 4.3.2 数据库压缩策略的实现与优化
实现数据库压缩的策略通常涉及在数据库层面进行配置,以启用内置的压缩功能。在一些支持数据压缩的数据库管理系统中(如PostgreSQL和MySQL),可以通过配置参数来启用压缩,使得数据库自动对存储的数据进行压缩处理。
以下是一个示例,说明如何在PostgreSQL数据库中启用数据压缩:
```sql
ALTER TABLE your_table SET (parallel_workers = 8, autovacuum_enabled = false);
SELECT pg_relation_filenode('your_table');
```
在一些不支持内置压缩功能的数据库中,可以将压缩逻辑放在应用层。例如,在将数据写入数据库前,先使用zlib进行压缩,并在读取数据时进行解压。
```python
def compress_data(data):
compressed = ***press(data)
return compressed
def decompress_data(compressed_data):
return zlib.decompress(compressed_data)
# 数据库写入操作
compressed_data = compress_data(your_data)
write_to_database(compressed_data)
# 数据库读取操作
compressed_data = read_from_database()
your_data = decompress_data(compressed_data)
```
在实际应用中,还需要考虑数据压缩的维护和管理问题。例如,压缩数据的备份和恢复、压缩算法的选择和升级、以及压缩对数据库事务和锁的影响等。这些都需要在数据库设计阶段提前规划和考虑。
以上是第四章节的详尽内容,我们逐步深入到了实际应用案例,并提供了代码示例和具体的策略来帮助读者理解和应用Python数据压缩技术。
```
# 5. zlib库的性能优化与最佳实践
在实际应用中,随着数据量的增加,对性能的要求也越来越高。本章将重点介绍如何通过分析和理解压缩性能指标、优化zlib压缩的实用技巧以及分享最佳实践案例来提升zlib库的性能和使用效率。
## 5.1 分析和理解压缩性能指标
在深入到优化和最佳实践之前,我们需要了解和分析几个关键的性能指标,以便于我们有方向地进行性能优化。
### 5.1.1 常见的性能指标解读
- **压缩比**:压缩后的数据大小与原始数据大小之间的比率。一个较高的压缩比意味着更有效的数据压缩。
- **压缩速度**:单位时间内能够压缩多少数据,通常用MB/s(兆字节每秒)来衡量。
- **解压缩速度**:单位时间内能够解压多少数据,也通常用MB/s来衡量。
- **CPU使用率**:压缩或解压缩过程中CPU的占用情况,反映了算法对资源的消耗。
- **内存消耗**:在压缩和解压缩过程中,程序占用的内存大小。
### 5.1.2 压缩性能的测试方法
为了准确地获取上述性能指标,需要进行系统化的性能测试。常见的测试方法包括:
- **基准测试**:使用预先准备好的标准测试数据集进行性能测试。
- **真实数据测试**:使用实际应用中的数据集来测试性能。
- **压力测试**:在极限条件下测试系统的性能表现。
- **持续运行测试**:长时间运行程序,检测性能是否随时间下降或出现错误。
```bash
# 示例:使用Python内置的time模块进行简单的性能测试
import time
import zlib
data = b'...' # 需要测试的数据
# 记录压缩前的时间
start_time = time.time()
compressed_data = ***press(data)
end_time = time.time()
# 计算压缩时间
compression_time = end_time - start_time
print(f"压缩耗时:{compression_time}秒")
```
## 5.2 优化zlib压缩的实用技巧
优化工作可以从代码级别和系统级别两个维度进行。
### 5.2.1 代码级别的优化方法
- **预分配内存**:预先分配足够大的内存空间以存储压缩后的数据,避免在压缩过程中不断重新分配内存。
- **循环处理**:当处理大量数据时,采用循环分块处理的方式,而不是一次性处理,可以减少内存的使用。
- **多线程**:在CPU密集型操作中使用多线程可以显著提高效率,但需要注意线程安全问题和上下文切换开销。
```python
import threading
def compress_chunk(data_chunk):
***press(data_chunk)
# 示例:使用多线程对数据进行压缩
def threaded_compress(data, chunk_size):
threads = []
for i in range(0, len(data), chunk_size):
chunk = data[i:i + chunk_size]
t = threading.Thread(target=compress_chunk, args=(chunk,))
threads.append(t)
t.start()
for t in threads:
t.join()
data = b'...' # 需要压缩的数据
threaded_compress(data, 1024)
```
### 5.2.2 系统级别的优化配置
- **系统调优**:根据CPU的核数调整并发的线程数,充分使用多核CPU的优势。
- **压缩级别调整**:根据数据特点选择合适的压缩级别,平衡压缩比和速度。
- **优化文件存储**:如果使用zlib处理文件,考虑使用更快的磁盘I/O设备,比如SSD。
## 5.3 最佳实践案例分享
成功案例分析和实战经验教训对于理解性能优化和最佳实践至关重要。
### 5.3.1 成功案例分析
在一次大型日志文件处理项目中,通过以下策略显著提高了性能:
- **数据预处理**:将原始日志数据分为多个小块,每个小块单独进行压缩。
- **并行压缩**:使用多个线程同时对这些数据块进行压缩。
- **内存监控**:使用监控工具实时监控内存使用情况,及时调整内存分配策略。
### 5.3.2 实战中的经验教训
在另一项工作中,由于对压缩级别选择不当,导致在追求高压缩比的同时牺牲了压缩速度,最终影响了整体项目的效率。通过这个教训,我们了解到需要根据实际应用的场景需求,综合考虑压缩比、速度和资源消耗等因素,进行合理选择。
性能优化和最佳实践是持续的过程,需要不断地调整和测试,来达到最佳状态。通过本章的内容,我们希望读者能够掌握zlib库在不同场景下的优化方法和最佳实践技巧。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中强大的 zlib 库,旨在帮助开发人员掌握数据压缩和解压技术。通过一系列文章,专栏涵盖了 zlib 模块的高效使用技巧、高级用法、定制和扩展、最佳实践和性能调优策略。专栏还深入分析了 zlib 的原理、应用和优缺点,并提供了在自动化脚本、数据流处理和大数据处理中的实际压缩解决方案。通过对 zlib 的全面了解,开发人员可以优化其 Python 应用程序的性能,有效地处理和压缩数据。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据挖掘在医疗健康的应用:疾病预测与治疗效果分析(如何通过数据挖掘改善医疗决策)

# 摘要
数据挖掘技术在医疗健康领域中的应用正逐渐展现出其巨大潜力,特别是在疾病预测和治疗效果分析方面。本文探讨了数据挖掘的基础知识及其与医疗健康领域的结合,并详细分析了数据挖掘技术在疾病预测中的实际应用,包括模型构建、预处理、特征选择、验证和优化策略。同时,文章还研究了治疗效果分析的目标、方法和影响因素,并探讨了数据隐私和伦理问题,
PLC系统故障预防攻略:预测性维护减少停机时间的策略

# 摘要
本文深入探讨了PLC系统的故障现状与挑战,并着重分析了预测性维护的理论基础和实施策略。预测性维护作为减少故障发生和提高系统可靠性的关键手段,本文不仅探讨了故障诊断的理论与方法,如故障模式与影响分析(FMEA)、数据驱动的故障诊断技术,以及基于模型的故障预测,还论述了其数据分析技术,包括统计学与机器学习方法、时间序列分析以及数据整合与
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
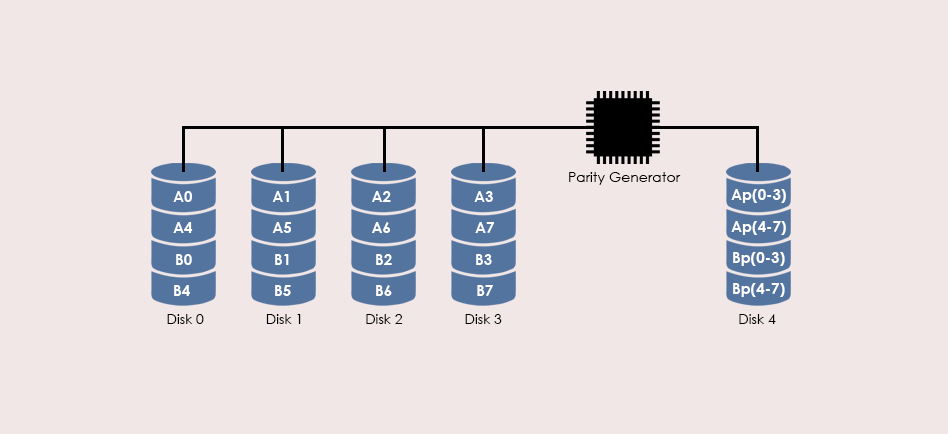
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
飞腾X100+D2000启动阶段电源管理:平衡节能与性能
# 摘要
本文旨在全面探讨飞腾X100+D2000架构的电源管理策略和技术实践。第一章对飞腾X100+D2000架构进行了概述,为读者提供了研究背景。第二章从基础理论出发,详细分析了电源管理的目的、原则、技术分类及标准与规范。第三章深入探讨了在飞腾X100+D2000架构中应用的节能技术,包括硬件与软件层面的节能技术,以及面临的挑战和应对策略。第四章重点介绍了启动阶
【软件使用说明书的可读性提升】:易理解性测试与改进的全面指南
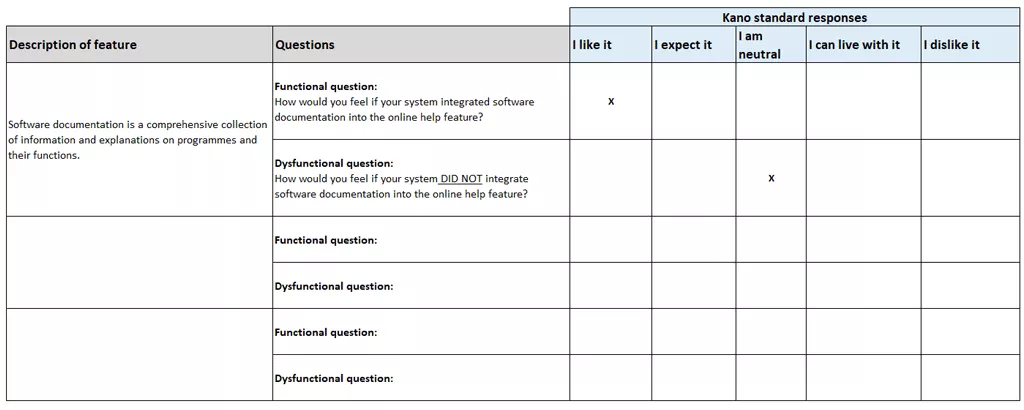
# 摘要
软件使用说明书作为用户与软件交互的重要桥梁,其重要性不言而喻。然而,如何确保说明书的易理解性和高效传达信息,是一项挑战。本文深入探讨了易理解性测试的理论基础,并提出了提升使用说明书可读性的实践方法。同时,本文也分析了基于用户反馈的迭代优化策略,以及如何进行软件使用说明书的国际化与本地化。通过对成功案例的研究与分析,本文展望了未来软件使用说明书设
多模手机伴侣高级功能揭秘:用户手册中的隐藏技巧
# 摘要
多模手机伴侣是一款集创新功能于一身的应用程序,旨在提供全面的连接与通信解决方案,支持多种连接方式和数据同步。该程序不仅提供高级安全特性,包括加密通信和隐私保护,还支持个性化定制,如主题界面和自动化脚本。实践操作指南涵盖了设备连接、文件管理以及扩展功能的使用。用户可利用进阶技巧进行高级数据备份、自定义脚本编写和性能优化。安全与隐私保护章节深入解释了数据保护机制和隐私管理。本文展望
【脚本与宏命令增强术】:用脚本和宏命令提升PLC与打印机交互功能(交互功能强化手册)
# 摘要
本文探讨了脚本和宏命令的基础知识、理论基础、高级应用以及在实际案例中的应用。首先概述了脚本与宏命令的基本概念、语言构成及特点,并将其与编译型语言进行了对比。接着深入分析了PLC与打印机交互的脚本实现,包括交互脚本的设计和测试优化。此外,本文还探讨了脚本与宏命令在数据库集成、多设备通信和异常处理方面的高级应用。最后,通过工业
【大规模部署的智能语音挑战】:V2.X SDM在大规模部署中的经验与对策

# 摘要
随着智能语音技术的快速发展,它在多个行业得到了广泛应用,同时也面临着众多挑战。本文首先回顾了智能语音技术的兴起背景,随后详细介绍了V2.X SDM平台的架构、核心模块、技术特点、部署策略、性能优化及监控。在此基础上,本文探讨了智能语音技术在银行业和医疗领域的特定应用挑战,重点分析了安全性和复杂场景下的应用需求。文章最后展望了智能语音和V2.X SDM
【音频同步与编辑】:为延时作品添加完美音乐与声效的终极技巧
# 摘要
音频同步与编辑是多媒体制作中不可或缺的环节,对于提供高质量的视听体验至关重要。本论文首先介绍了音频同步与编辑的基础知识,然后详细探讨了专业音频编辑软件的选择、配置和操作流程,以及音频格式和质量的设置。接着,深入讲解了音频同步的理论基础、时间码同步方法和时间管理技巧。文章进一步聚焦于音效的添加与编辑、音乐的混合与平衡,以及音频后期处理技术。最后,通过实际项目案例分析,展示了音频同步与编辑在不同项目中的应用,并讨论了项目完成后的质量评估和版权问题。本文旨在为音频技术人员提供系统性的理论知识和实践指南,增强他们对音频同步与编辑的理解和应用能力。
# 关键字
音频同步;音频编辑;软件配置;
【实战技巧揭秘】:WIN10LTSC2021输入法BUG引发的CPU占用过高问题解决全记录

# 摘要
本文对Win10 LTSC 2021版本中出现的输入法BUG进行了详尽的分析与解决策略探讨。首先概述了BUG现象,然后通过系统资源监控工具和故障排除技术,对CPU占用过高问题进行了深入分析,并初步诊断了输入法BUG。在此基础上,本文详细介绍了通过系统更新
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )