【数据驱动测试艺术】:Python自动化测试中的用例与数据分离秘籍
发布时间: 2024-12-06 21:05:09 阅读量: 19 订阅数: 12 

利用Python如何实现数据驱动的接口自动化测试
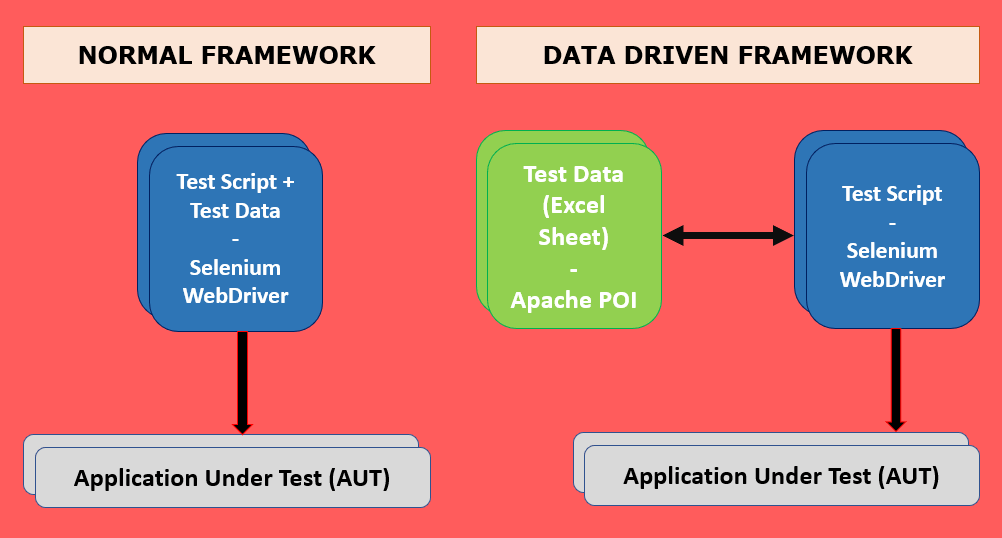
# 1. 数据驱动测试的基本概念和重要性
数据驱动测试(Data-Driven Testing, DDT)是一种测试方法,它将测试输入数据和预期结果存储在数据源中,允许测试用例从这些数据源读取信息来执行测试。这种模式的核心优势在于其高复用性和可维护性,测试人员可以仅通过改变输入数据来测试软件的不同行为,而不需要频繁修改测试脚本本身。这对于经常变化的测试需求或是高度参数化的应用场景尤其重要,如电子商务网站的商品价格变动测试、银行系统的不同账户交易流程验证等。
在自动化测试领域,数据驱动测试提升了测试脚本的灵活性与可扩展性,使得测试过程能够更好地应对复杂多变的应用场景,以及大规模的测试需求。通过分离测试逻辑与数据,测试团队可以更加专注于测试脚本的设计,同时将测试数据的管理和维护交给专门的数据管理工具或人员,从而提高测试的整体效率和覆盖率。
数据驱动测试的引入,使得软件测试过程从手工重复性劳动转向了更加智能化、自动化的方向,这对于提高测试质量和效率具有革命性的意义。随着自动化测试框架和数据管理工具的发展,数据驱动测试已逐渐成为测试行业内的标准实践之一。下一章我们将深入了解Python自动化测试中的数据分离技术,探讨如何通过Python实现高效的数据驱动测试。
# 2. 理论基础:Python自动化测试中的数据分离
## 2.1 数据驱动测试理论
### 2.1.1 定义和核心思想
数据驱动测试(Data-Driven Testing,DDT)是一种将测试数据与测试脚本分离的测试方法。其核心思想是测试数据独立于测试脚本,测试脚本可以不加修改地使用不同的数据集来执行多次。这种分离简化了测试脚本的维护和扩展,使得测试人员可以更加专注于测试数据的维护和分析。
在DDT中,测试数据通常存储在外部数据源中,如数据库、Excel文件、CSV文件等。测试工具或脚本在执行时,从数据源中读取测试数据,动态地应用到测试用例中。这种方法特别适合那些测试输入和预期结果变化频繁的场景,比如功能测试、兼容性测试和回归测试等。
### 2.1.2 数据驱动测试的优势和应用场景
数据驱动测试的优势在于:
1. **提高效率**:只需编写一次测试脚本,就可以使用不同的测试数据集进行多次测试,大大减少了重复工作量。
2. **灵活性高**:数据源的更新或变更不会影响到测试脚本,易于扩展和维护。
3. **易于实现复杂的测试逻辑**:可以通过组合不同的测试数据实现复杂的测试场景。
4. **方便生成报告和分析**:因为测试逻辑和测试数据是分离的,可以根据测试结果生成更详尽的报告。
数据驱动测试的应用场景包括但不限于:
- **多数据输入的测试**:当需要测试软件对不同输入数据的响应时,如各种用户输入、配置选项、接口参数等。
- **业务流程测试**:针对复杂的业务流程,通过数据驱动测试可以覆盖所有可能的业务路径。
- **参数化测试**:软件功能可能依赖于多种输入参数的组合,数据驱动测试可以对每一种参数组合进行测试。
- **多环境测试**:需要在不同的环境下运行相同的测试用例,如不同的浏览器、操作系统版本等。
## 2.2 Python与数据分离
### 2.2.1 Python在自动化测试中的应用
Python作为一门简洁且功能强大的编程语言,在自动化测试领域中得到了广泛应用。它的语法简单直观,易于学习,同时提供了丰富的库和框架来支持自动化测试。例如,Selenium用于Web自动化测试,unittest和pytest用于编写测试用例,requests用于API测试等。
Python之所以在自动化测试中受到青睐,还因为它的跨平台特性以及强大的社区支持。Python社区提供了大量的开源工具和库,可以简化测试框架的搭建和测试用例的编写。Python的易读性和代码复用特性也使得维护和更新测试脚本更加容易。
### 2.2.2 数据分离在Python测试中的重要性
在Python中实现数据分离,可以显著提高测试脚本的可维护性和可重用性。数据分离使得测试人员可以将测试数据从测试脚本中剥离出来,存储在外部数据源中。这样,测试脚本的逻辑就可以更加聚焦于测试过程,而数据的变更不会影响测试逻辑的实现。
例如,使用Excel或CSV文件存储测试数据,可以轻松地通过Python的pandas库读取数据并应用到测试用例中。这样做的好处在于,当测试数据需要更新或调整时,无需修改Python代码本身,只需更新数据文件即可。这对于执行重复性测试或维护多个测试场景特别有效。
## 2.3 数据驱动框架的选择和搭建
### 2.3.1 常见数据驱动框架对比
在选择数据驱动框架时,需要考虑多个方面,包括框架的灵活性、易用性、社区支持程度以及与现有工具的兼容性等。常见的Python数据驱动测试框架包括:
- **unittest**:Python标准库中的单元测试框架,提供了丰富的测试用例结构,易于实现数据驱动测试。
- **pytest**:是一个更加灵活的测试框架,支持插件机制,可以轻松地实现数据驱动测试,同时支持丰富的断言和报告格式。
- **Behave**:基于行为驱动开发(BDD)的Python测试框架,允许以自然语言描述测试用例,非常适合业务驱动的测试场景。
对比这些框架,pytest因其简洁的语法和强大的功能而受到测试人员的广泛欢迎。而Behave则提供了另一种测试角度,适合那些希望将测试用例与业务需求直接关联的场景。
### 2.3.2 搭建自定义数据驱动框架的步骤
搭建自定义数据驱动框架通常包括以下步骤:
1. **定义测试数据源**:确定数据源的格式,比如CSV、Excel、JSON等,并创建测试数据文件。
2. **实现数据读取机制**:编写代码以读取外部数据源,并将数据映射到测试用例中。
3. **设计参数化测试用例**:创建测试用例模板,使其可以接收外部传入的数据参数。
4. **执行测试并记录结果**:运行数据驱动的测试用例,并将测试结果存储到报告或日志中。
5. **结果分析和反馈**:分析测试结果,提供反馈,帮助改进软件质量。
在Python中,可以使用pandas来读取Excel文件,使用openpyxl或xlrd来处理CSV文件,使用json模块来处理JSON文件。而unittest和pytest等测试框架提供了内置或插件机制来支持数据驱动测试的实现。
### 代码块展示
下面是一个使用pytest实现数据驱动测试的简单示例:
```python
import pytest
# 读取测试数据
def read_test_data():
# 使用pandas读取Excel文件
import pandas as pd
return pd.read_excel("test_data.xlsx")
# 参数化测试用例
@pytest.mark.parametrize("data", read_test_data().itertuples(index=False, name=None))
def test_example(data):
# 这里写入测试逻辑
assert data == "expected_result"
# 测试函数将接收来自test_data.xlsx文件中的每一行数据
```
在这个例子中,我们首先定义了`read_test_data`函数来从一个Excel文件中读取测试数据。然后我们使用`pytest.mark.parametrize`装饰器将测试数据动态地应用到`test_example`测试用例中。每个数据项将作为参数传递给测试函数,使得测试可以针对不同的数据输入执行。
### 总结
在本节中,我们深入了解了数据驱动测试的理论基础,并探索了Python在自动化测试中的应用。通过实现数据分离,我们能够显著提高测试脚本的可维护性和可重用性。我们比较了不同数据驱动框架,并概述了搭建自定义数据驱动框架的步骤。最后,通过实际的代码示例,我们展示了如何在Python中实现数据驱动测试。在下一章,我们将更深入地探讨如何在实践中应用用例与数据分离。
# 3. 实践应用:用例与数据分离的实现
在数据驱动测试的实践中,用例与数据的分离是核心环节,它允许测试者使用外部数据源来执行同样的测试逻辑,针对不同的数据输入进行测试。本章将详细探讨如何实现这一过程,包括选择合适的数据源、编写可参数化的测试用例以及测试数据的管理。
## 3.1 使用外部数据源
### 3.1.1 选择合适的数据源
数据驱动测试的一个显著优势是能够使用外部数据源,如CSV、Excel或JSON文件等。选择合适的外部数据源对测试的可维护性和扩展性至关重要。
- **CSV文件**:具有良好的兼容性,易于编辑和处理,适用于结构化数据。
- **Excel文件**:具有直观的用户界面,方便非技术人员操作,特别适用于测试数据量大且需要复杂数据关系的场景。
- **JSON文件**:近年来逐渐流行,适合存储复杂的层级结构数据,易于与Web应用程序集成。
选择哪种数据源依赖于项目的具体需求、测试数据的复杂性以及团队的偏好。例如,对于需要频繁修改的测试数据,使用Excel可能是更佳选择;而对于结构化的、数量庞大的测试数据,CSV可能会更加适合。
### 3.1.2 数据源的读取和解析方法
在确定数据源后,接下来需要编写代码来读取和解析这些数据。以下是使用Python语言来读取CSV文件中的测试数据示例:
```python
import csv
# 打开CSV文件
with open('test_data.csv', 'r') as file:
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 自动化测试的有效方法,涵盖了从框架选择到用例设计、Web 测试、数据驱动测试、脚本编写、异常处理、关键字驱动测试、报告生成、接口测试、安全性保障、并发测试、虚拟用户生成、代码维护、移动应用测试和错误处理等各个方面。通过对专业框架的对比、实战技巧的分享和最佳实践的讲解,本专栏旨在帮助读者掌握 Python 自动化测试的精髓,提升测试效率和质量,为构建可靠且可维护的自动化测试套件提供全面的指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CANape脚本技巧集】:掌握提高工作效率的10大快捷方法

参考资源链接:[CANape CASL:深入解析脚本语言](https://wenku.csdn.net/doc/6412b711be7fbd1778d48f92?spm=1055.2635.3001.10343)
# 1. CANape脚本概述
CANape作为汽车行业中广泛使用的测量和标定工具,其内置的脚本
【质谱分析深度解析】:MSFinder高级功能的幕后英雄
参考资源链接:[使用MS-FINDER进行质谱分析与化合物识别教程](https://wenku.csdn.net/doc/6xkmf6rj5o?spm=1055.2635.3001.10343)
# 1. 质谱分析与MSFinder简介
质谱分析是一种强大的化学分析技术,通过测量物质的质量与电荷比值来鉴定和量化样品中的
LinuxCNC实时内核调优:稳定性保障的专家级方法

参考资源链接:[LinuxCNC源程序入门指南:结构与功能概览](https://wenku.csdn.net/doc/6412b54abe7fbd1778d429fa?spm=1055.2635.3001.10343)
# 1. LinuxCNC实时内核调优概览
在现代工业自动化和机器人技术领域,LinuxCNC作为一款流行的开源CNC控制系统,对于其
MATLAB实现拉格朗日插值:5大优化技巧助你性能飞升
参考资源链接:[MATLAB实现拉格朗日插值法:代码、实例与详解](https://wenku.csdn.net/doc/5m6vt46bk8?spm=1055.2635.3001.10343)
# 1. MATLAB与拉格朗日插值简介
## 1.1 MATLAB概述
MATLAB是一个高性能的数值计算和可视化环境,广泛应用于工程计算、数据分析、算法开发等领域。MATLAB提
【Workbench DM 数据整合】:掌握高效集成策略与案例解析
参考资源链接:[ANSYS Workbench DM教程:使用DesignModeler进行3D建模](https://wenku.csdn.net/doc/5a18x88ruk?spm=1055.2635.3001.10343)
# 1. Workbench DM简介
在数字化转型的大潮中,企业需要高效地管理和利用数据资源,以便在激烈的市场竞争中保持优势。正是在这样的背景下,Workbench DM
中控ZKTime考勤数据库查询优化:【实战技巧大揭秘】

参考资源链接:[中控zktime考勤管理系统数据库表结构优质资料.doc](https://wenku.csdn.net/doc/2phyejuviu?spm=1055.2635.3001.10343)
# 1. 中控ZKTime考勤系统概述
中控ZKTime考勤系统作为企业日常管理中不可或缺的一部分,它通过现代信息技术确保企业员工的考勤记录准确无误。本章节将向您介绍考勤系统的功能与优势,以及它在企业管理
【SFP+高速通信兼容性】:SFF-8431规范确保高速数据通信无障碍
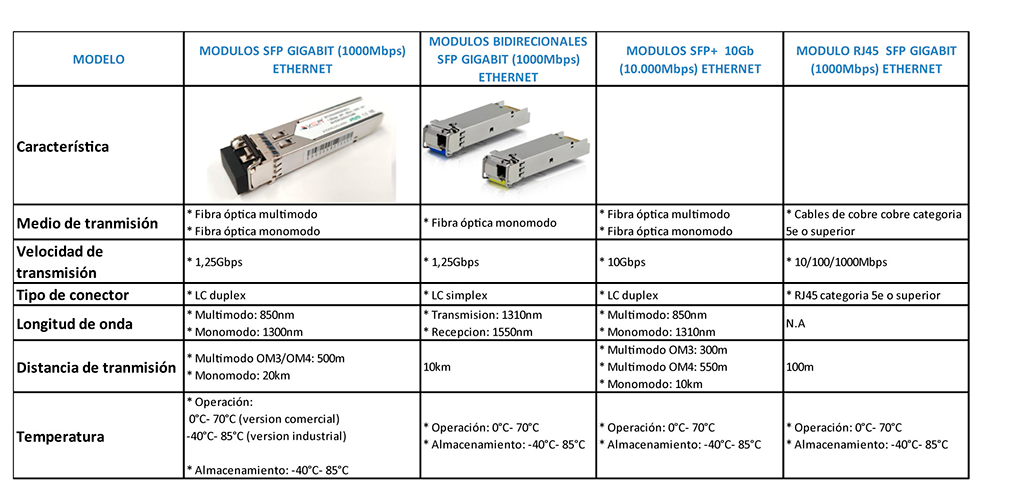
参考资源链接:[SFF-8431标准详解:SFP+光模块低速与高速接口技术规格](https://wenku.csdn.net/doc/3s3xhrwidr?spm=1055.2635.3001.10343)
# 1. SFP+高速通信兼容性的基础概念
## 1.1 SFP+技术的引入
串行千兆位光纤通道(SFP+)是一种
【FEKO软件全面掌握】:10个实用技巧助你从新手到仿真专家
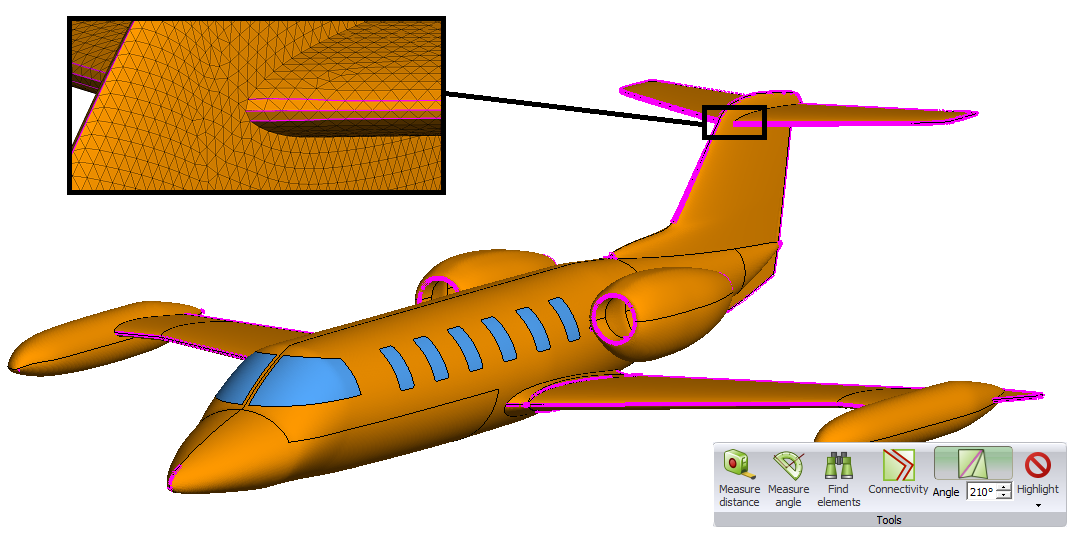
参考资源链接:[FEKO入门详解:电磁场分析与应用教程](https://wenku.csdn.net/doc/6h6kyqd9dy?spm=1055.2635.3001.10343)
# 1. FEKO软件简介与安装配置
## 1.1 FEKO软件简介
FEKO是一款在电磁领域广泛使用的仿真软件,它以高
CHEMKIN 4.0.1 快速上手:常用功能与快捷键的终极指南

参考资源链接:[CHEMKIN 4.0.1入门教程:软件安装与基础使用](https://wenku.csdn.net/doc/2uryprgu9t?spm=1055.2635.3001.10343)
# 1. CHEMKIN 4.0.1 基础介绍
## 1.1 CHEMKIN的历史与应用背景
CHEMKIN是化学反应动力学模拟的行业标准工具,自1980年代开发以来,它在化工、能源、航空航天等多个领域得到了广
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )