【Redis内存管理】
发布时间: 2024-12-07 10:14:57 阅读量: 28 订阅数: 16 

查看Redis内存信息的命令
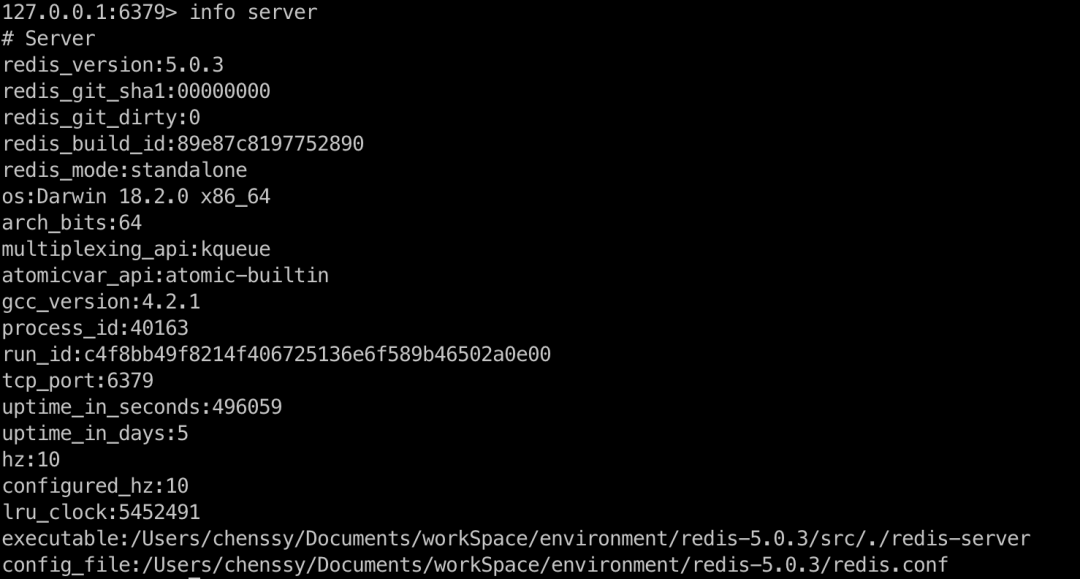
# 1. Redis内存管理概述
在本章节中,我们将对Redis内存管理进行一个基础而全面的概览。Redis作为一个高性能的内存数据库,在数据的存储、处理和维护上都有其独特之处。理解Redis的内存管理,不仅有助于我们优化性能,也对保证数据的完整性和响应速度至关重要。
Redis的内存管理涉及到了数据结构的内存布局,内存分配和回收策略,以及内存监控与优化等多个层面。我们将逐一探讨这些关键部分,让读者对Redis内存管理有更深入的理解,并能够有效地应用于实际的系统优化中。
以下章节将分别详细探讨Redis内存中数据结构的存储方式,内存分配与回收机制,监控与优化手段,以及持久化和高可用性设置对内存管理的影响。接下来的每一部分,都将在本章概述的基础上,做进一步的深入分析和讨论。
# 2. Redis内存数据结构
## 2.1 内存中的数据结构类型
### 2.1.1 字符串(String)的存储
字符串是最基础的Redis数据结构类型,它可以存储文本、数字等数据。在Redis中,字符串数据的存储通过SDS(Simple Dynamic String)实现。SDS除了保存数据外,还包含了两个额外的空间,分别用于记录字符串的长度和未使用的空间。这种设计相比传统的C语言字符串有以下优势:
- **时间复杂度的优化:**SDS获取字符串长度的时间复杂度是O(1),而传统C语言为O(n)。
- **内存安全的保护:**SDS会自动防止缓冲区溢出,因为其预先分配了足够的空间。
- **空间预分配策略:**当字符串长度增加时,SDS会重新分配内存,并且根据需要预留空间,这减少了内存重新分配的次数。
下面是一个SDS结构的示例代码:
```c
struct sdshdr {
int len; // 记录buf数组中已使用字节的数量
int free; // 记录buf数组中未使用字节的数量
char buf[]; // 字节数组,用于保存字符串
};
```
在使用Redis时,开发者通过字符串操作相关命令来实现对数据的操作。例如:
```bash
SET key value
```
这个命令会创建一个新的字符串对象,并在内存中分配足够的空间来保存`value`。
### 2.1.2 列表(List)的存储机制
Redis中的列表是通过链表实现的,但在某些情况下,比如在列表的两端进行操作时,Redis使用了双端链表。这种结构允许在常数时间内进行插入和删除操作。然而,当列表中的元素数量较多时,链表的性能下降,此时Redis会使用压缩列表(ziplist)来优化内存使用。
压缩列表是一个经过特殊编码的双向链表,它能够减少内存使用,提高空间利用率。当列表中所有数据项的大小都小于一定阈值时,Redis就会选择使用压缩列表。不过,压缩列表的缺点是,当数据项大小增加时,节点之间的移动将会更频繁,这会降低性能。
列表操作示例:
```bash
RPUSH list "one"
RPUSH list "two"
```
这些命令将字符串"one"和"two"推入名为`list`的列表的右侧。如果列表元素数量不多,这些操作将非常高效。
### 2.1.3 集合(Set)的内存表现
集合(Set)在Redis中是无序集合,它存储的元素没有重复。集合的存储主要通过两种数据结构实现:
- **整数集合(intset):**当集合中全部是整数且元素数量不多时,Redis会使用整数集合来存储集合元素。
- **哈希表:**当集合元素不能存储为整数或者元素数量较大时,Redis使用哈希表存储。
整数集合是一种特殊的数组,它会根据集合中元素的类型进行自我升级。例如,当集合中首次插入一个64位整数时,整数集合会自动升级到64位。
使用集合时,我们可以通过类似以下命令来操作:
```bash
SADD set "one"
SADD set "two"
```
这些命令分别添加字符串"one"和"two"到名为`set`的集合中。如果集合中的元素是整数且数量不多,整数集合提供了一种高效的存储方式。
## 2.2 高级数据结构
### 2.2.1 哈希表(Hash)内存使用
哈希表在Redis中用于存储键值对集合,适用于存储对象属性等场景。它通过哈希函数将键映射到表中的某个位置来快速检索数据。
Redis的哈希表实现了渐进式扩容和收缩,这表示在进行大量键值对插入或删除操作时,可以动态调整哈希表的大小。这有助于在执行操作时平衡内存使用和性能。
哈希表的数据结构定义如下:
```c
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestroy)(void *privdata, void *key);
void (*valDestroy)(void *privdata, void *obj);
} dictType;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
```
哈希表操作包括HSET、HGET等,例如:
```bash
HSET hash "field1" "value1"
```
这个命令设置`hash`中的`field1`字段为`value1`。如果`hash`内部是一个哈希表,那么存储将非常高效。
### 2.2.2 有序集合(Sorted Set)的内存管理
有序集合类似于集合,但是每个元素都有一个分数(score),并且集合中的元素根据分数有序。Redis通过跳表(skiplist)和哈希表的组合来实现有序集合。
跳表是一个具有多个层的有序链表,它能够提供快速的搜索、插入和删除操作。哈希表则是用于快速检索元素的分数,这样可以实现对元素的快速访问。
有序集合的内存管理对性能和空间效率有很高的要求,因为每个元素都需要同时存储在跳表和哈希表中。当元素被添加或删除时,相关的跳表和哈希表结构也需要相应地更新。
操作示例:
```bash
ZADD sorted_set 1 "one"
ZADD sorted_set 2 "two"
```
上述命令将"one"和"two"以分数1和2添加到`sorted_set`中。由于有序集合在内部使用了跳表和哈希表,即使元素数量较多,这些操作也能保持较高的性能。
### 2.2.3 位图和超级日志的内存模型
位图(Bitmap)是一种特殊的数据结构,它使用字符串作为底层数据结构来实现位操作。位图在内存中存储时非常高效,因为它可以将数以万计的布尔值压缩到很小的空间中。
超级日志(HyperLogLog)是Redis中用于统计唯一元素数量的数据结构,它的内存使用非常节省,即使在处理大量数据的情况下,也只需要很小的内存空间。
位图和超级日志的内存模型都依赖于Redis的字符串实现,但这两种数据结构针对不同的使用场景进行了优化。
位图操作示例:
```bash
SETBIT bitmap 1 1
GETBIT bitmap 1
```
第一个命令将`bitmap`中的第一个位设置为1,第二个命令则获取`bitmap`中第一个位的值。这些操作在内存中是非常快速的。
超级日志操作示例:
```bash
PFADD hyperloglog element1 element2 ...
PFCOUNT hyperloglog
```
`PFADD`命令添加新的元素到超级日志中,而`PFCOUNT`命令则返回估计的唯一元素数量。超级日志在内存中只保存一组概率位,以此来估算唯一值的数量。
## 2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了MySQL与Redis的结合应用,全面介绍了Redis的缓存机制、内存管理和持久化机制。专栏还提供了MySQL+Redis的集成实践指南,包括数据缓存模式、数据交互和缓存策略优化。此外,专栏深入分析了MySQL和Redis的交互,探讨了Redis作为MySQL二级缓存的应用,以及Redis与MySQL的异步通信。最后,专栏还提供了Redis监控与维护的最佳实践,帮助读者充分利用MySQL和Redis的优势,提升数据库性能和应用程序响应速度。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Ubuntu中文环境配置秘籍】:从入门到精通,打造完美中文环境
# 摘要
本文全面探讨了在Ubuntu操作系统中搭建和优化中文环境的全过程。首先强调了中文环境的重要性,然后详细介绍了基础环境搭建的步骤,包括系统安装、软件仓库配置和系统更新。接着,本文重点阐述了中文环境配置的各个方面,包括语言包安装、中文字体配置以及输入法设置。此外,还探讨了中文环境的个性化优化,例如图形界面主题设置和常用软件的中文支持。文章还覆盖了高级应用,如编程时的中文编
车载传感器安全机制:8项关键技术保障车辆安全运行

# 摘要
车载传感器安全机制是保障现代智能交通系统中车辆数据安全、有效性和用户隐私的关键因素。本文对车载传感器的基础理论与技术进行了概述,并深入探讨了传感器安全技术的理论基础,包括数据加密与认证技术以及安全协议和标准。通过分析安全监测与报警系统的实践应用,本文进一步阐述了数据加密实践和用户隐私保护策略。此外,本文还研究了加密算法和密钥管理、安全协议实现与优化等关键技术在车载传感器安全中的应用。最后,本文展望了车载传感器安全机制的未来发展趋势,包括新兴技术的融合
RT-LAB高效使用:脚本编写与自定义功能扩展的秘籍
# 摘要
RT-LAB作为一种实时仿真软件,广泛应用于多个行业,其脚本编写是实现高效自动化和数据分析的关键技术。本文全面介绍了RT-LAB的基本概念、应用环境及其脚本编写基础,包括脚本语言特性、结构化编程、流程控制、错误处理、调试、性能优化等方面。通过实战演练,本文展示了RT-LAB脚本在数据采集与分析、自动化测试、故障诊断及用户自定义功能开发中的应用。同时,本文还
AI在企业中的力量:构建并部署高效的机器学习模型

# 摘要
随着企业数字化转型的不断推进,人工智能(AI)的应用已成为提升竞争力的关键。本文首先探讨了AI在企业中的必要性及其多样化应用领域,随后详细阐述了机器学习模型的理论基础,包括不同学习模型的选择、数据预处理、特征工程和评价指标。在实践过程中,本文指导如何使用Pytho
TC5000通讯协议安全性深度剖析:弱点与对策
# 摘要
本文首先概述了TC5000通讯协议的基本架构和功能,随后对协议中常见的安全漏洞类型及其影响进行了分析,并探讨了这些漏洞的成因和触发条件。通过实例分析,文章揭示了漏洞的具体表现和可能带来的启示。针对这些安全问题,本文提出了基于原则和策略的安全防护对策,并介绍了具体的技术和管理措施。接着,文章设计并实施了一系列安全性实验,对TC5000通讯协议的安全性能进行了评估。最终,展望了TC5000通讯协议未来的发展和安全性提升的可能方向,给出了技术与管理层面的建议。
# 关键字
TC5000通讯协议;安全漏洞;安全防护;实例分析;实验评估;安全性展望
参考资源链接:[营口天成CRT通讯协议
PLC与传感器协同:饮料灌装流水线的自动化新境界

# 摘要
本文详细探讨了PLC(可编程逻辑控制器)与传感器技术在饮料灌装流水线中的协同工作原理及其应用。通过分析PLC控制系统的硬件组成、程序逻辑以及与HMI(人机界面)的集成,阐述了其在实现灌装流程自动化控制和质量监测中的核心作用。同时,针对传感器技术在饮料灌装中的应用,讨论了传感器的选择、布局和数据处理技术,以及传感器与PLC
F3飞控电路故障快速诊断与排除:专家级解决方案
# 摘要
F3飞控电路作为航空控制系统的关键组成部分,其稳定性和故障排除技术对于飞行安全至关重要。本文首先介绍了F3飞控电路的基础知识和常见故障类型,随后深入探讨了故障诊断的理论和实践方法,包括使用专业工具和故障定位技术。接着,文章阐述了高级故障排除技术,如微处理器和固件的诊断与修复,以及整合外部资源和专家支持的策略。此外,详细介绍了维修和组件替换过程,强调精准操作和材料选择的重要性。最后,本文提出长期监测与优化的必要性,以及通过专业培训和知识传承来提高维修团队的能力,确保电路性能和飞行安全。本文旨在为F3飞控电路的维护和故障处理提供全面的技术参考。
# 关键字
飞控电路;故障诊断;维修实践
揭秘SAP计划策略:5大误区与10个优化技巧
# 摘要
SAP计划策略是企业资源规划的核心组成部分,它直接影响到企业的生产效率和市场响应能力。本文针对SAP计划策略的常见误区进行了深入探讨,并从理论和实践两个维度提出了优化技巧。文章首先指出了过度依赖自动化、忽略数据时效性以及缺少灵活性和可扩展性等误区,并分析了如何在SAP环境中平衡这些因素。接着,文章基于资源优化理论、供应链协同效应和库存管理理论,提供了SA
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )