什么是Spring Data JPA?
发布时间: 2023-12-16 11:25:54 阅读量: 48 订阅数: 23 
# 1. 介绍Spring Data JPA
## 1.1 什么是Spring Data JPA?
Spring Data JPA是Spring框架的一部分,它提供了一种方便的方式来访问和操作数据库。它是基于JPA(Java Persistence API)标准的ORM(对象关系映射)工具,通过将数据库和Java对象之间的映射细节交给框架来处理,开发人员可以更专注于业务逻辑的实现。
## 1.2 JPA与Hibernate的关系
JPA是JavaEE的一部分,定义了一组规范接口,用于将Java对象持久化到数据库中。而Hibernate则是一个流行的实现JPA规范的ORM框架。Spring Data JPA底层使用了Hibernate,因此在使用Spring Data JPA时,可以享受到Hibernate提供的丰富功能和高性能。
## 1.3 Spring Data JPA的优点
- 简化开发:Spring Data JPA提供了一套简洁的API,使得开发人员可以更快速地进行数据访问和操作。不再需要手动编写大量的SQL语句,而是通过简单的方法调用来完成数据库操作。
- 提高可维护性:Spring Data JPA采用了面向对象的方式来进行数据访问,使得代码更加清晰和易于维护。同时,它也支持声明式事务管理,可以在方法或类级别上定义事务的边界,简化了事务管理的操作。
- 支持多种数据库:Spring Data JPA可以与多种数据库进行集成,包括常见的关系型数据库如MySQL、Oracle等,也可以与NoSQL数据库如MongoDB进行交互。这使得开发人员可以根据需求选择最适合的数据库。
- 强大的查询功能:Spring Data JPA提供了丰富的查询方法,包括基于方法命名的查询、使用查询注解、自定义查询等多种方式,使得开发人员能够灵活地进行数据查询和筛选。
## 2. 如何使用Spring Data JPA
在本章中,我们将学习如何使用Spring Data JPA来进行数据库操作。下面是使用Spring Data JPA的步骤:
### 2.1 添加Spring Data JPA依赖
首先,我们需要在项目的构建文件中添加Spring Data JPA的依赖。对于Maven项目,可以在`pom.xml`中添加以下依赖:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
```
对于Gradle项目,可以在`build.gradle`中添加以下依赖:
```groovy
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
```
### 2.2 配置数据源
接下来,我们需要配置数据源来连接数据库。在Spring Boot中,可以在`application.properties`或`application.yml`文件中添加数据库连接配置,例如:
```properties
spring.datasource.url=jdbc:mysql://localhost:3306/mydatabase
spring.datasource.username=root
spring.datasource.password=secret
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
```
### 2.3 创建实体类
在使用Spring Data JPA进行数据库操作之前,我们需要先定义实体类来映射数据库表。实体类应该使用`@Entity`注解,并且需要定义主键和属性与数据库表中列的映射关系。例如,我们创建一个`User`实体类:
```java
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
// getters and setters
}
```
### 2.4 定义Repository接口
最后,我们需要定义一个Repository接口来完成数据库的CRUD操作。Repository接口可以使用Spring Data JPA提供的默认方法,或者我们也可以自定义查询方法。
```java
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
// 可以通过查询方法自动生成SQL语句
List<User> findByName(String name);
}
```
在上面的例子中,我们定义了一个`UserRepository`接口,继承自`JpaRepository`接口,并指定了实体类`User`和主键类型`Long`。我们还定义了一个查询方法`findByName`,会自动生成查询语句。
至此,我们已经完成了Spring Data JPA的配置。在实际使用中,我们可以注入`UserRepository`,并调用其方法来进行数据库操作。
```java
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getAllUsers() {
return userRepository.findAll();
}
public User getUserById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new NoSuchElementException("User not found"));
}
public List<User> getUsersByName(String name) {
return userRepository.findByName(name);
}
public User saveUser(User user) {
return userRepository.save(user);
}
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}
```
在上面的例子中,我们使用`UserRepository`完成了常见的CRUD操作,并自定义了一个查询方法`findByName`。通过调用这些方法,我们可以完成对数据库的操作。
### 3. Spring Data JPA的常用功能
Spring Data JPA提供了许多常用的功能,使得操作数据库变得更加简单和高效。接下来我们将介绍一些常用的功能和操作方法。
#### - 基本的CRUD操作
在Spring Data JPA中,CRUD操作非常简单和直观。通过继承`CrudRepository`接口,我们可以直接使用`save()`、 `findAll()`、 `findById()`、 `delete()`等方法进行数据的增删改查操作,而无需编写复杂的SQL语句。
```java
public interface UserRepository extends CrudRepository<User, Long> {
// 自动继承了save(), findAll(), findById(), delete()等方法
}
```
#### - 使用查询方法
Spring Data JPA支持使用方法名来定义查询,只需按照约定命名方法即可实现简单的查询操作。例如,通过在Repository接口中定义方法名,就可以根据方法名自动生成查询语句。
```java
public interface UserRepository extends JpaRepository<User, Long> {
User findByUsername(String username);
List<User> findByAgeGreaterThan(int age);
}
```
#### - 分页和排序
Spring Data JPA还提供了对查询结果进行分页和排序的功能,通过`Pageable`和`Sort`接口可以轻松实现。
```java
Page<User> findAll(Pageable pageable);
List<User> findByAgeGreaterThan(int age, Sort sort);
```
#### - 使用动态查询
借助`Specification`接口和`CriteriaQuery`,Spring Data JPA支持动态组合条件进行查询,适用于复杂的查询场景。
```java
public List<User> findAllByCriteria(Specification<User> spec);
```
## 4. JPA实体关系映射
在本章中,我们将讨论JPA中实体之间的关系映射。JPA支持多种类型的实体关系映射,包括一对一关系映射、一对多关系映射、多对多关系映射以及实体继承关系映射。让我们逐个进行讨论。
### 一对一关系映射
```java
// 实体类User
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
@OneToOne
private UserProfile profile;
// 省略其他属性和方法
}
// 实体类UserProfile
@Entity
public class UserProfile {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String email;
// 省略其他属性和方法
}
```
在上面的示例中,我们展示了如何在JPA中进行一对一关系映射。在User实体类中使用@OneToOne注解来表示和UserProfile实体的关系。
### 一对多关系映射
```java
// 实体类Department
@Entity
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "department")
private List<Employee> employees;
// 省略其他属性和方法
}
// 实体类Employee
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "department_id")
private Department department;
// 省略其他属性和方法
}
```
上述代码展示了如何在JPA中进行一对多关系映射。在Department实体类中使用@OneToMany注解来表示和Employee实体的关系,在Employee实体类中使用@ManyToOne注解来表示和Department实体的关系。
### 多对多关系映射
```java
// 实体类Author
@Entity
public class Author {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany
@JoinTable(name = "author_book",
joinColumns = @JoinColumn(name = "author_id"),
inverseJoinColumns = @JoinColumn(name = "book_id"))
private List<Book> books;
// 省略其他属性和方法
}
// 实体类Book
@Entity
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@ManyToMany(mappedBy = "books")
private List<Author> authors;
// 省略其他属性和方法
}
```
在上面的示例中,我们展示了如何在JPA中进行多对多关系映射。在Author实体类中使用@ManyToMany注解来表示和Book实体的关系,在Book实体类中使用@ManyToMany注解并指定mappedBy来表示和Author实体的关系。
### 实体继承关系映射
```java
// 实体类Animal
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Animal {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 省略其他属性和方法
}
// 实体类Cat
@Entity
public class Cat extends Animal {
private String furColor;
// 省略其他属性和方法
}
// 实体类Dog
@Entity
public class Dog extends Animal {
private String breed;
// 省略其他属性和方法
}
```
在上述代码中,我们展示了如何在JPA中进行实体继承关系映射。通过使用@Inheritance注解来表示Animal实体作为父类,Cat和Dog实体作为子类,实现了继承关系映射。
### 5. 高级查询与复杂操作
在本章节中,我们将深入探讨如何使用Spring Data JPA进行高级查询与复杂操作。我们将讨论使用JPQL语句查询、使用Criteria API进行查询、使用原生SQL查询以及事务管理与并发控制等内容。让我们一起来看看吧!
1. 使用JPQL语句查询
- 示例场景:假设我们有一个名为`Customer`的实体类,我们想要通过JPQL语句查询出所有年龄大于18岁的顾客列表。
```java
@Repository
public interface CustomerRepository extends JpaRepository<Customer, Long> {
@Query("SELECT c FROM Customer c WHERE c.age > 18")
List<Customer> findAllAbove18();
}
```
- 代码解释:在`CustomerRepository`接口中,我们使用`@Query`注解并提供JPQL语句来定义查询方法,从而实现了根据年龄查询顾客列表的功能。
- 结果说明:调用`findAllAbove18()`方法将会执行JPQL语句查询,返回所有年龄大于18岁的顾客列表。
2. 使用Criteria API进行查询
- 示例场景:假设我们需要根据特定条件动态构建查询条件,可以使用Criteria API来实现。
```java
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Customer> query = cb.createQuery(Customer.class);
Root<Customer> root = query.from(Customer.class);
query.select(root).where(cb.gt(root.get("age"), 18));
List<Customer> resultList = entityManager.createQuery(query).getResultList();
```
- 代码解释:通过Criteria API,我们可以动态构建查询条件,并实现比如年龄大于18岁的顾客列表查询。
- 结果说明:执行以上代码会根据动态构建的查询条件,返回符合条件的顾客列表。
3. 使用原生SQL查询
- 示例场景:有时候,我们可能需要执行一些复杂的SQL查询,可以使用原生SQL查询来实现。
```java
@Query(value = "SELECT * FROM customers WHERE age > 18", nativeQuery = true)
List<Customer> findAllAbove18UsingNativeQuery();
```
- 代码解释:通过`@Query`注解的`nativeQuery`属性,可以指定使用原生SQL查询。
- 结果说明:调用`findAllAbove18UsingNativeQuery()`方法将会执行原生SQL查询,返回年龄大于18岁的顾客列表。
4. 事务管理与并发控制
- 示例场景:在涉及到复杂操作时,我们需要考虑事务管理与并发控制,以确保数据的一致性和并发操作的正确性。
```java
@Service
public class CustomerService {
@Autowired
private EntityManager entityManager;
@Transactional
public void updateCustomer(Customer customer) {
// 执行一些更新操作
entityManager.merge(customer);
}
}
```
- 代码解释:通过`@Transactional`注解来实现事务管理,确保`updateCustomer()`方法中的操作要么全部成功提交,要么全部回滚。
- 结果说明:使用事务管理可以保证在并发操作时,数据的一致性和并发操作的正确性。
### 6. Spring Data JPA的扩展与定制
Spring Data JPA提供了许多扩展和定制的功能,可以根据具体的需求定制Repository接口、查询方法和实体映射。下面将详细介绍如何扩展和定制Spring Data JPA。
#### 自定义Repository接口
在Spring Data JPA中,可以通过自定义Repository接口来添加自定义的数据访问方法。首先创建一个自定义的Repository接口,然后让实际的Repository接口继承自定义的Repository接口。
```java
public interface CustomizedUserRepository {
List<User> findUsersByCustomLogic();
}
public interface UserRepository extends JpaRepository<User, Long>, CustomizedUserRepository {
// 此处是自定义数据访问方法
}
```
#### 定制查询
除了使用Spring Data JPA提供的方法外,还可以通过@Query注解自定义查询方法。通过JPQL语句或者原生SQL语句来定义查询逻辑。
```java
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.email = :email")
User findByEmail(@Param("email") String email);
}
```
#### 定制实体映射
有时候需要定制实体类与数据库表之间的映射关系,可以使用@SecondaryTable、@PrimaryKeyJoinColumn等注解来定制实体映射。
```java
@Entity
@Table(name = "users")
@SecondaryTable(name = "user_details", pkJoinColumns = @PrimaryKeyJoinColumn(name = "user_id", referencedColumnName = "id"))
public class User {
// 实体属性
}
```
#### 添加自定义事务处理逻辑
在需要对事务进行特殊处理的情况下,可以使用@Transactional注解来定制事务管理。
```java
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional(propagation = Propagation.REQUIRED)
public void updateUserEmail(Long userId, String newEmail) {
User user = userRepository.findById(userId).orElse(null);
if (user != null) {
user.setEmail(newEmail);
// 其他业务逻辑处理
}
}
}
```
通过以上的方法,可以对Spring Data JPA进行灵活的扩展和定制,以满足特定的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏全面介绍了Spring Data JPA的核心概念与实际应用,内容涵盖了从基础知识到高级技术的全方位解析。首先详细解释了Spring Data JPA的概念和作用,接着对其简介及核心概念进行了深入解析,并介绍了如何使用Spring Data JPA进行简单的数据操作以及实体类映射与表结构设计原则。然后,重点阐述了复杂查询操作、排序、分页、限制结果集等实现方法,更深入地讲解了查询方法自动生成SQL语句和Spring Data JPA中的查询注解。在此基础上,专栏还介绍了使用命名查询提高查询的可读性与维护性,以及分步查询与延迟加载的最佳实践。此外,该专栏还探讨了Spring Data JPA实现多表关联查询、动态查询、事务管理、乐观锁、悲观锁等高级应用,还包括了数据库迁移、缓存与性能优化、预定义审计字段和全文搜索等实际案例分析。最后,还进一步讨论了Spring Data JPA与NoSQL数据库的集成,为读者提供了全面的学习和应用指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VC709开发板原理图进阶】:深度剖析FPGA核心组件与性能优化(专家视角)

# 摘要
本论文首先对VC709开发板进行了全面概述,并详细解析了其核心组件。接着,深入探讨了FPGA的基础理论及其架构,包括关键技术和设计工具链。文章进一步分析了VC709开发板核心组件,着重于FPGA芯片特性、高速接口技术、热管理和电源设计。此外,本文提出了针对VC709性能优化
IP5306 I2C同步通信:打造高效稳定的通信机制

# 摘要
本文系统地阐述了I2C同步通信的基础原理及其在现代嵌入式系统中的应用。首先,我们介绍了IP5306芯片的功能和其在同步通信中的关键作用,随后详细分析了实现高效稳定I2C通信机制的关键技术,包括通信协议解析、同步通信的优化策略以及IP5306与I2C的集成实践。文章接着深入探讨了IP5306 I2C通信的软件实现,涵盖软件架
Oracle数据库新手指南:DBF数据导入前的准备工作
# 摘要
本文旨在详细介绍Oracle数据库的基础知识,并深入解析DBF数据格式及其结构,包括文件发展历程、基本结构、数据类型和字段定义,以及索引和记录机制。同时,本文指导读者进行环境搭建和配置,包括Oracle数据库软件安装、网络设置、用户账户和权限管理。此外,本文还探讨了数据导入工具的选择与使用方法,介绍了SQL
FSIM对比分析:图像相似度算法的终极对决
# 摘要
本文首先概述了图像相似度算法的发展历程,重点介绍了FSIM算法的理论基础及其核心原理,包括相位一致性模型和FSIM的计算方法。文章进一步阐述了FSIM算法的实践操作,包括实现步骤和性能测试,并探讨了针对特定应用场景的优化技巧。在第四章中,作者对比分析了FSIM与
应用场景全透视:4除4加减交替法在实验报告中的深度分析
# 摘要
本文综合介绍了4除4加减交替法的理论和实践应用。首先,文章概述了该方法的基础理论和数学原理,包括加减法的基本概念及其性质,以及4除4加减交替法的数学模型和理论依据。接着,文章详细阐述了该方法在实验环境中的应用,包括环境设置、操作步骤和结果分析。本文还探讨了撰写实验报告的技巧,包括报告的结构布局、数据展示和结论撰写。最后,通过案例分析展示了该方法在不同领域的应用,并对实验报告的评价标准与质量提升建议进行了讨论。本文旨在
电子设备冲击测试必读:IEC 60068-2-31标准的实战准备指南
# 摘要
IEC 60068-2-31标准为冲击测试提供了详细的指导和要求,涵盖了测试的理论基础、准备策划、实施操作、标准解读与应用、以及提升测试质量的策略。本文通过对冲击测试科学原理的探讨,分类和方法的分析,以及测试设备和工具的选择,明确了测试的执行流程。同时,强调了在测试前进行详尽策划的重要性,包括样品准备、测试计划的制定以及测试人员的培训。在实际操作中,本
【神经网络】:高级深度学习技术提高煤炭价格预测精度

# 摘要
随着深度学习技术的飞速发展,该技术已成为预测煤炭价格等复杂时间序列数据的重要工具。本文首先介绍了深度学习与煤炭价格预测的基本概念和理论基础,包括神经网络、损失函数、优化器和正则化技术。随后,文章详细探讨了深度学习技术在煤炭价格预测中的具体应用,如数据预处理、模型构建与训练、评估和调优策略。进一步,本文深入分析了高级深度学习技术,包括卷积神经网络(CNN)、循环神经网络(RNN)和长
电子元器件寿命预测:JESD22-A104D温度循环测试的权威解读
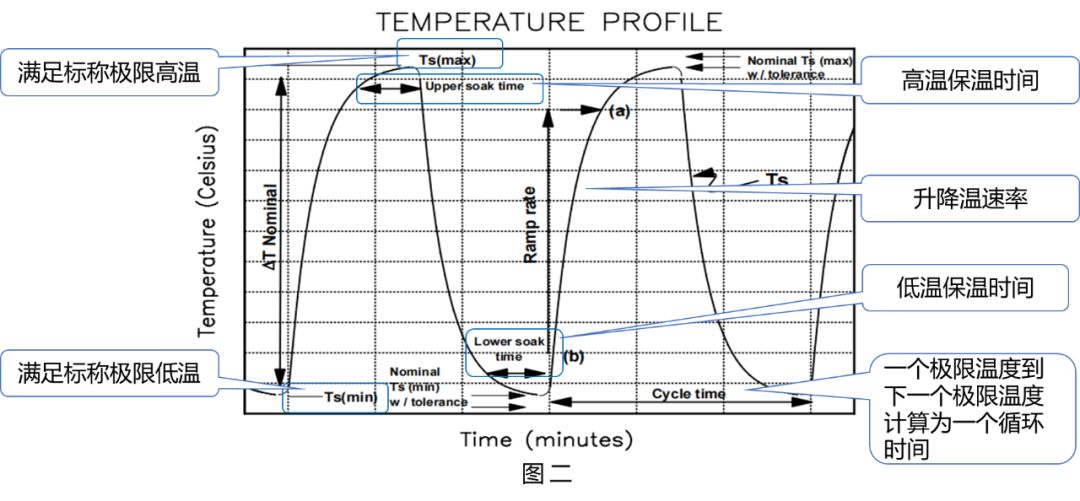
# 摘要
电子元器件在各种电子设备中扮演着至关重要的角色,其寿命预测对于保证产品质量和可靠性至关重要。本文首先概述了电子元器件寿命预测的基本概念,随后详细探讨了JESD22-A104D标准及其测试原理,特别是温度循环测试的理论基础和实际操作方法。文章还介绍了其他加速老化测试方法和寿命预测模型的优化,以及机器学习技术在预测中的应用。通过实际案例分析,本文深入讨论了预测模型的建立与验证。最后,文章展望了未来技术创新、行
【数据库连接池详解】:高效配置Oracle 11gR2客户端,32位与64位策略对比
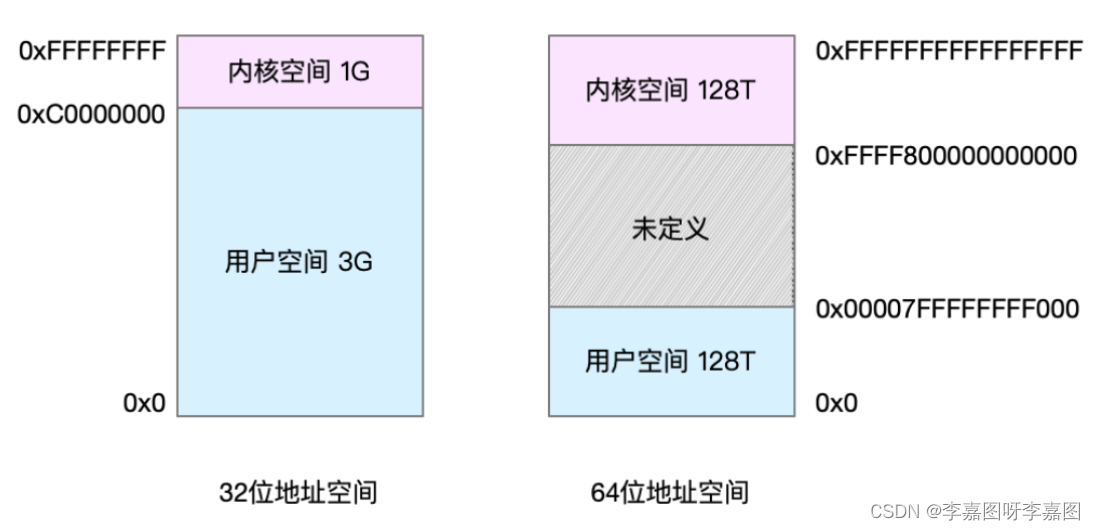
# 摘要
本文对Oracle 11gR2数据库连接池的概念、技术原理、高效配置、不同位数客户端策略对比,以及实践应用案例进行了系统的阐述。首先介绍了连接池的基本概念和Oracle 11gR2连接池的技术原理,包括其架构、工作机制、会话管理、关键技术如连接复用、负载均衡策略和失效处理机制。然后,文章转向如何高效配置Oracle 11gR2连接池,涵盖环境准备、安装步骤、参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )