互联网上常见的Python多线程应用场景与案例
发布时间: 2023-12-19 20:16:22 阅读量: 18 订阅数: 19 
# 1. 引言
## 1.1 互联网时代的需求与挑战
在当今互联网时代,各行各业都面临着巨大的需求和挑战。随着互联网技术的不断革新和发展,人们对于高效、快速、稳定的技术解决方案的需求也越来越迫切。特别是在大数据时代的到来,处理海量数据和复杂计算任务对传统的串行计算方式提出了更高的要求。
## 1.2 Python多线程的概念与优势
Python作为一种高级编程语言,具有简洁、易学、可读性强等特点,成为了开发者心目中的首选语言之一。而多线程作为Python提供的并发编程方式之一,具有以下优势:
- **提高程序运行效率**:使用多线程可以充分利用机器的多核处理器,同时执行多个任务,从而加快程序的执行速度。
- **提升用户体验**:通过多线程处理耗时操作,可以大大减少用户等待时间,提高程序的响应速度。
- **增加代码复用性**:多线程编程可以将不同的任务拆分为独立的线程,有利于代码模块的重用,提高代码的可维护性和可扩展性。
在本篇文章中,我们将深入探讨并发编程的基础知识,并结合实际应用场景和经典案例,介绍Python多线程的实践与优化技巧,帮助读者更好地理解和应用多线程编程。
# 2. 并发编程基础知识
### 2.1 进程与线程的概念
在计算机科学中,进程指的是正在运行的一个程序的实例。每个进程都有自己的地址空间、内存、数据栈以及其他用于跟踪程序执行的辅助数据。而线程则是进程中的实际执行单元,一个进程可以包含多个线程,它们共享进程的资源。
### 2.2 多线程编程的基本原理
多线程编程利用CPU分时技术,让多个线程交替地运行,从而实现多任务并发执行。多线程编程的基本原理主要包括线程的创建、启动、暂停、终止以及多线程之间的同步与通信。在实际应用中,通过合理地利用多线程,可以提高程序的执行效率和响应速度。
通过以上基础知识的学习,我们可以进一步深入理解Python多线程的应用场景以及实际案例。接下来,我们将重点介绍Python多线程在不同领域的应用,并结合实际案例进行演示和分析。
# 3. Python多线程的应用场景
Python作为一种功能强大且易于使用的编程语言,广泛应用于各种领域,尤其在并发编程方面表现突出。下面将介绍Python多线程在不同应用场景下的具体应用。
#### 3.1 网络爬虫
在网络爬虫应用中,Python多线程可以大大提高爬取页面的效率。通过多线程并发地请求和解析网页内容,可以加快爬取速度,提高爬虫的效率和性能。下面是一个简单的网络爬虫示例:
```python
import requests
from bs4 import BeautifulSoup
import threading
class SpiderThread(threading.Thread):
def __init__(self, url):
super(SpiderThread, self).__init__()
self.url = url
def run(self):
response = requests.get(self.url)
content = response.text
soup = BeautifulSoup(content, 'html.parser')
# 在这里可以对网页内容进行解析和提取需要的信息
# 定义要爬取的网页链接
urls = ['http://example.com/page1', 'http://example.com/page2', 'http://example.com/page3']
# 创建并启动多个线程进行爬取
threads = []
for url in urls:
thread = SpiderThread(url)
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
# 处理爬取结果
# ...
```
#### 3.2 并发下载器
在需要大量下载文件的场景下,Python多线程可以用来实现并发下载器,通过多线程同时下载不同的文件,可以显著提高下载速度和效率。下面是一个简单的并发下载器示例:
```python
import requests
import threading
class DownloadThread(threading.Thread):
def __init__(self, url, filename):
super(DownloadThread, self).__init__()
self.url = url
self.filename = filename
def run(self):
response = requests.get(self.url)
with open(self.filename, 'wb') as f:
f.write(response.content)
# 定义要下载的文件链接和保存的文件名
downloads = [('http://example.com/file1', 'file1.txt'), ('http://example.com/file2', 'file2.txt'), ('http://example.com/file3', 'file3.txt')]
# 创建并启动多个线程进行下载
threads = []
for url, filename in downloads:
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏《Python多线程编程》是一本全面介绍Python多线程编程的指南。从入门到深入,通过多个文章标题,专栏涵盖了Python多线程编程的各个方面,包括创建和管理多个线程、线程同步与互斥、线程间通信、线程池编程、解决死锁问题、线程优先级调度、全局解释器锁的作用、多线程与多进程的比较与选择、并发与并行的应用、异步编程与多线程结合等。此外,还涵盖了IO密集型和CPU密集型任务的并行化技巧、线程安全与不安全操作、常见的多线程应用场景与案例、性能优化技巧、生产者-消费者模式、异常处理与调试技巧以及并发网络编程的最佳实践。对于想要在Python中进行多线程编程的开发者来说,这本专栏将提供宝贵的知识和实践经验,帮助他们更好地应对多线程编程的挑战。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python enumerate函数在医疗保健中的妙用:遍历患者数据,轻松实现医疗分析

# 1. Python enumerate函数概述**
enumerate函数是一个内置的Python函数,用于遍历序列(如列表、元组或字符串)中的元素,同时返回一个包含元素索引和元素本身的元组。该函数对于需要同时访问序列中的索引
【进阶篇】数据可视化互动性:Widget与Interactivity技术

# 2.1 Widget的类型和功能
Widget是数据可视化中用于创建交互式图形和控件的组件。它们可以分为以
云计算架构设计与最佳实践:从单体到微服务,构建高可用、可扩展的云架构

# 1. 云计算架构演进:从单体到微服务
云计算架构经历了从单体到微服务的演进过程。单体架构将所有应用程序组件打
Python在Linux下的安装路径在机器学习中的应用:为机器学习模型选择最佳路径
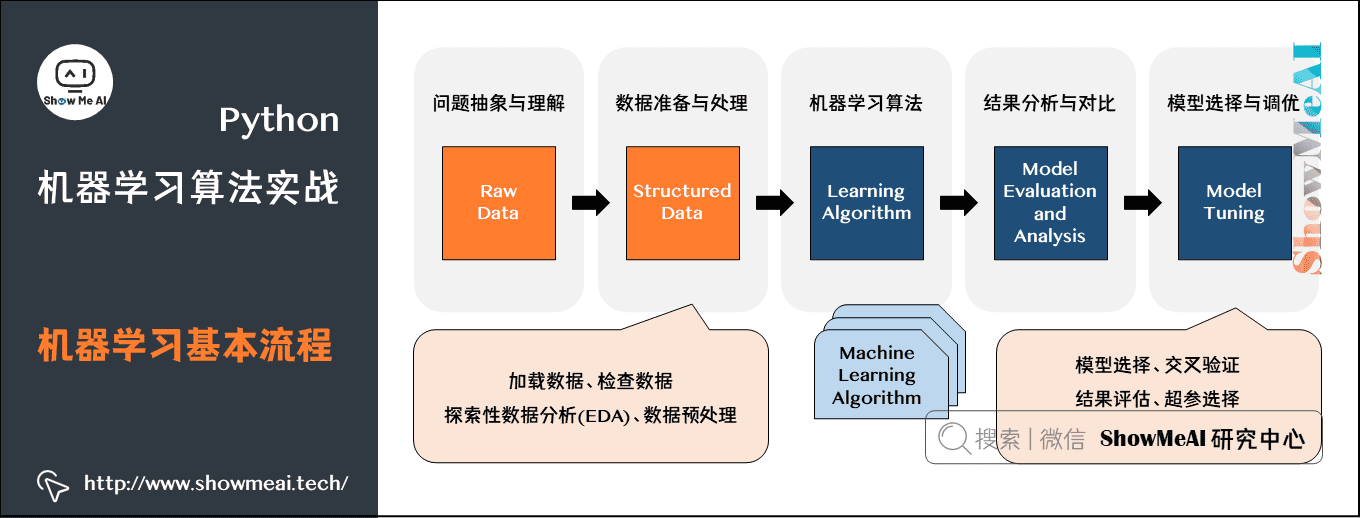
# 1. Python在Linux下的安装路径
Python在Linux系统中的安装路径是一个至关重要的考虑因素,它会影响机器学习模型的性能和训练时间。在本章中,我们将深入探讨Python在Linux下的安装路径,分析其对机器学习模型的影响,并提供最佳实践指南。
# 2. Python在机器学习中的应用
### 2.1 机器学习模型的类型和特性
Python连接MySQL数据库:区块链技术的数据库影响,探索去中心化数据库的未来

# 1. 区块链技术与数据库的交汇
区块链技术和数据库是两个截然不同的领域,但它们在数据管理和处理方面具有惊人的相似之处。区块链是一个分布式账本,记录交易并以安全且不可篡改的方式存储。数据库是组织和存储数据的结构化集合。
区块链和数据库的交汇点在于它们都涉及数据管理和处理。区块链提供了一个安全且透明的方式来记录和跟踪交易,而数据库提供了一个高效且可扩展的方式来存储和管理数据。这两种技术的结合可以为数据管
揭秘MySQL数据库性能下降幕后真凶:提升数据库性能的10个秘诀

# 1. MySQL数据库性能下降的幕后真凶
MySQL数据库性能下降的原因多种多样,需要进行深入分析才能找出幕后真凶。常见的原因包括:
- **硬件资源不足:**CPU、内存、存储等硬件资源不足会导致数据库响应速度变慢。
- **数据库设计不合理:**数据表结构、索引设计不当会影响查询效率。
- **SQL语句不优化:**复杂的SQL语句、
MySQL数据库在Python中的最佳实践:经验总结,行业案例
# 1. MySQL数据库与Python的集成**
MySQL数据库作为一款开源、跨平台的关系型数据库管理系统,以其高性能、可扩展性和稳定性而著称。Python作为一门高级编程语言,因其易用性、丰富的库和社区支持而广泛应用于数据科学、机器学习和Web开发等领域。
将MySQL数据库与Python集成可以充分发挥两者的优势,实现高效的数据存储、管理和分析。Python提
Python连接PostgreSQL机器学习与数据科学应用:解锁数据价值

# 1. Python连接PostgreSQL简介**
Python是一种广泛使用的编程语言,它提供了连接PostgreSQL数据库的
Python深拷贝与浅拷贝:数据复制的跨平台兼容性
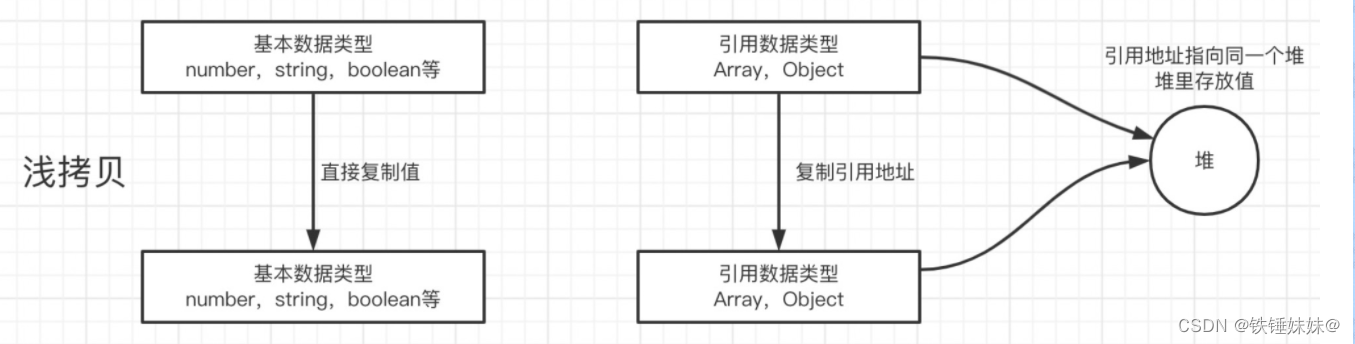
# 1. 数据复制概述**
数据复制是一种将数据从一个位置复制到另一个位置的操作。它在许多应用程序中至关重要,例如备份、数据迁移和并行计算。数据复制可以分为两种基本类型:浅拷贝和深拷贝。浅拷贝只复制对象的引用,而深拷贝则复制对象的整个内容。
浅拷贝和深拷贝之间的主要区别在于对嵌套对象的行为。在浅拷贝中,嵌套对象只被引用,而不会被复制。这意味着对浅拷贝对象的任何修改也会影响原始对象。另一方面,在深拷贝中,
【实战演练】数据聚类实践:使用K均值算法进行用户分群分析
# 1. 数据聚类概述**
数据聚类是一种无监督机器学习技术,它将数据点分组到具有相似特征的组中。聚类算法通过识别数据中的模式和相似性来工作,从而将数据点分配到不同的组(称为簇)。
聚类有许多应用,包括:
- 用户分群分析:将用户划分为具有相似行为和特征的不同组。
- 市场细分:识别具有不同需求和偏好的客户群体。
- 异常检测:识别与其他数据点明显不同的数据点。
# 2
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )