Python 语言程序设计:基础知识概述
发布时间: 2024-01-27 08:04:09 阅读量: 61 订阅数: 21 

Python语言程序设计基础教程(持续更新).pdf
# 1. Python语言简介
## 1.1 Python语言的起源和发展
Python语言由Guido van Rossum于1989年在荷兰创造。最初,Python的目标是设计一种易于阅读和编写的语言,具有强大的功能和易于学习的语法。Python语言的发展得益于开发者社区的积极参与和贡献。
## 1.2 Python语言的特点和优势
Python语言具有以下特点和优势:
- 简洁优雅的语法:Python的语法干净、简单,并且易于阅读和理解。
- 多种编程范式支持:Python支持面向对象编程、函数式编程以及命令式编程。
- 广泛的应用领域:Python可用于Web开发、数据分析、人工智能、科学计算等各个领域。
- 强大的标准库和第三方库:Python拥有丰富的标准库和活跃的第三方库生态系统,可以方便地进行开发和扩展。
- 良好的跨平台性:Python可以在多个操作系统上运行,包括Windows、Linux、Mac等。
## 1.3 Python在软件开发领域的应用
Python在软件开发领域有广泛的应用,包括但不限于以下方面:
- 网络和Web开发:Python的轻量级Web框架(如Flask、Django)可以快速构建高效的Web应用程序。
- 数据科学和机器学习:Python的丰富的数据处理库(如NumPy、Pandas)与机器学习库(如Scikit-learn、TensorFlow)结合,可用于数据挖掘、数据分析和机器学习任务。
- 自动化和脚本编程:Python可以通过脚本编写自动化任务,如自动化测试、系统管理和批量处理等。
- 科学计算和数值计算:Python的科学计算库(如SciPy、Matplotlib)提供了丰富的数值计算和数据可视化工具。
- 游戏开发:Python的游戏开发库(如Pygame)为游戏开发者提供了快速开发游戏的工具和框架。
在第一章中,我们介绍了Python语言的起源和发展,以及其特点和优势。同时,我们还瞥了Python在软件开发领域的广泛应用。接下来,我们将深入学习Python的基础语法。
# 2. Python基础语法
## 2.1 Python的变量和数据类型
Python是一种动态语言,不需要预先声明变量的类型,可以直接赋值。
```python
# 定义变量并赋值
name = "John"
age = 25
height = 1.75
# 打印变量的值
print("姓名:", name)
print("年龄:", age)
print("身高:", height)
```
**代码说明:**
- 使用赋值语句将值赋给变量,并使用等号(=)进行赋值。
- 使用print函数可以将变量的值输出到控制台。
**结果说明:**
运行以上代码,将输出以下结果:
```
姓名: John
年龄: 25
身高: 1.75
```
## 2.2 Python的运算符和表达式
Python支持多种运算符,包括算术运算符、比较运算符、逻辑运算符等。
```python
# 算术运算符
x = 10
y = 3
print("x + y =", x + y)
print("x - y =", x - y)
print("x * y =", x * y)
print("x / y =", x / y)
print("x % y =", x % y)
print("x // y =", x // y)
print("x ** y =", x ** y)
# 比较运算符
a = 5
b = 8
print("a > b:", a > b)
print("a < b:", a < b)
print("a == b:", a == b)
print("a != b:", a != b)
print("a >= b:", a >= b)
print("a <= b:", a <= b)
# 逻辑运算符
p = True
q = False
print("p and q:", p and q)
print("p or q:", p or q)
print("not p:", not p)
```
**代码说明:**
- 算术运算符包括加法(+)、减法(-)、乘法(*)、除法(/)、取余(%)、取整除(//)、指数(**)。
- 比较运算符包括大于(>)、小于(<)、等于(==)、不等于(!=)、大于等于(>=)、小于等于(<=)。
- 逻辑运算符包括与(and)、或(or)、非(not)。
**结果说明:**
运行以上代码,将输出以下结果:
```
x + y = 13
x - y = 7
x * y = 30
x / y = 3.3333333333333335
x % y = 1
x // y = 3
x ** y = 1000
a > b: False
a < b: True
a == b: False
a != b: True
a >= b: False
a <= b: True
p and q: False
p or q: True
not p: False
```
## 2.3 控制流程:条件语句和循环结构
Python使用if语句来进行条件判断,使用for和while循环来实现循环结构。
```python
# 条件语句
score = 90
if score >= 90:
print("成绩优秀")
elif score >= 70:
print("成绩良好")
else:
print("成绩不及格")
# for循环
for i in range(1, 6):
print(i)
# while循环
count = 0
while count < 5:
print(count)
count += 1
```
**代码说明:**
- 条件语句使用if、elif和else关键字来判断条件,并根据条件执行相应的代码块。
- for循环使用in关键字来遍历指定范围内的数值或可迭代对象。
- while循环在条件满足时执行循环体内的代码,并在每次循环末尾更新循环条件。
**结果说明:**
运行以上代码,将输出以下结果:
```
成绩优秀
1
2
3
4
5
0
1
2
3
4
```
通过以上章节的介绍,你已经了解了Python基础语法的一些重要内容,包括变量和数据类型、运算符和表达式、以及条件语句和循环结构的使用方法。在后续章节中,我们将深入探讨Python的函数和模块、面向对象编程、文件操作和异常处理、以及常用的标准库和第三方模块等内容。敬请期待。
# 3. Python函数和模块
#### 3.1 函数的定义和调用
在Python中,函数可以使用def关键字进行定义和命名。函数可以接收参数,并且可以返回数值或对象。
```python
# 定义一个简单的函数
def greet(name):
print("Hello, " + name + "!")
# 调用函数
greet("Alice")
```
**代码说明:**
以上代码定义了一个名为greet的函数,它接收一个参数name,并打印出一个简单的问候语。之后,我们调用这个函数并输出结果。
#### 3.2 函数参数和返回值
Python函数可以接收位置参数、关键字参数和默认参数,并且可以返回单个数值或多个数值(以元组的形式)。
```python
# 使用关键字参数和默认参数
def greet(name, message="Hello"):
print(message + ", " + name + "!")
# 调用函数
greet("Bob")
greet("Alice", "Good morning")
```
**代码说明:**
上述代码中,我们定义了一个函数greet,它接收两个参数name和message(默认为"Hello")。在调用函数时,我们可以只传递name参数,也可以传递两个参数,其中第二个参数会覆盖默认值。
#### 3.3 模块的导入和使用
在Python中,可以使用import语句导入其他Python文件中定义的函数和变量,从而实现模块的复用和功能的扩展。
```python
# 导入math模块并使用其中的函数
import math
# 计算圆的面积
radius = 2
area = math.pi * radius**2
print("The area of the circle is", area)
```
**代码说明:**
在这个例子中,我们通过import语句导入了Python标准库中的math模块,然后使用其定义的数学函数来计算圆的面积。
### 结论
本章介绍了Python函数的定义和调用方式,以及函数参数和返回值的相关知识。同时,还讨论了Python中模块的导入和使用方法。这些内容为进一步学习Python编程打下了基础。
# 4. Python面向对象编程
#### 4.1 类和对象的概念
在Python中,一切皆对象。对象是类的实例,类是对象的模板。通过定义类可以创建对象,并在对象中封装属性和方法。类通过属性(变量)和方法(函数)来描述对象的状态和行为。
#### 4.2 类的定义和实例化
在Python中,可以使用class关键字来定义一个类。类的定义包括属性和方法两部分,属性用于描述对象的状态,而方法用于描述对象的行为。实例化是指创建类的实例对象的过程,可以通过类名加括号的方式来实例化对象。
```python
# 定义一个简单的类
class Dog:
# 类的属性
species = 'mammal'
# 类的方法
def __init__(self, name, age):
self.name = name
self.age = age
def description(self):
return f"{self.name} is {self.age} years old"
def speak(self, sound):
return f"{self.name} says {sound}"
# 实例化对象
dog1 = Dog("Tom", 3)
print(dog1.description()) # 输出:Tom is 3 years old
print(dog1.speak("Woof Woof!")) # 输出:Tom says Woof Woof!
```
#### 4.3 继承与多态
在Python中,可以通过继承来实现类与类之间的关系。子类可以继承父类的属性和方法,并且可以重写父类的方法以实现多态的特性。
```python
# 定义一个子类继承自父类
class Bulldog(Dog):
def run(self, speed):
return f"{self.name} runs at {speed} km/h"
bulldog1 = Bulldog("Max", 4)
print(bulldog1.description()) # 输出:Max is 4 years old
print(bulldog1.run(10)) # 输出:Max runs at 10 km/h
```
通过继承和多态的特性,可以实现代码的复用和灵活性,提高了代码的可维护性和扩展性。
# 5. Python文件操作和异常处理
在本章中,我们将学习如何在Python中进行文件的操作以及异常的处理。文件操作是程序开发中非常重要的一部分,它涉及到文件的读取、写入以及其他相关的操作。异常处理则是在程序执行过程中遇到错误时的应对措施,它能够帮助我们优雅地处理错误并保证程序的稳定运行。
## 5.1 文件的读写操作
在Python中,使用内置的open函数可以打开一个文件,并返回一个文件对象。我们可以通过文件对象来进行文件的读取和写入操作。
以下是一个简单的例子,演示了如何打开一个文件,并将内容写入文件中:
```python
# 打开文件
file = open('example.txt', 'w')
# 写入内容
file.write('Hello, World!')
# 关闭文件
file.close()
```
在这个例子中,我们首先使用`open`函数以写入(`w`)模式打开一个名为`example.txt`的文件。接下来,我们使用`write`方法向文件中写入了字符串`Hello, World!`。最后,我们使用`close`方法关闭了文件。
除了使用`write`方法写入内容,我们还可以使用`read`方法来读取文件中的内容:
```python
# 打开文件
file = open('example.txt', 'r')
# 读取内容
content = file.read()
# 输出内容
print(content)
# 关闭文件
file.close()
```
在这个例子中,我们首先使用`open`函数以读取(`r`)模式打开了同一个名为`example.txt`的文件。然后,我们使用`read`方法将读取到的内容赋值给了变量`content`。最后,我们使用`print`函数输出了读取到的内容。
除了上述的读取整个文件的方法之外,我们还可以使用`readline`方法来逐行读取文件的内容:
```python
# 打开文件
file = open('example.txt', 'r')
# 读取一行
line = file.readline()
# 输出一行
print(line)
# 关闭文件
file.close()
```
在这个例子中,我们首先使用`open`函数打开了同一个文件,然后使用`readline`方法读取了文件的第一行,并将其赋值给了变量`line`。最后,我们使用`print`函数输出了读取到的第一行内容。
## 5.2 异常的捕获和处理
在编写程序时,我们无法避免出现各种错误和异常。为了保证程序的稳定运行,我们需要学会捕获和处理异常。
在Python中,使用`try`和`except`语句可以捕获并处理异常。以下是一个示例:
```python
try:
# 可能会出现错误的代码
num = 10 / 0
except ZeroDivisionError:
# 发生除零错误时的处理代码
print("除零错误")
```
在这个例子中,我们在`try`块中执行了可能会出现错误的代码,即对10进行了除以0的运算,这是一个除零错误。在`except`块中,我们使用`ZeroDivisionError`来捕获除零错误,并输出相应的错误信息。
除了`ZeroDivisionError`,Python还提供了众多其他的内置异常类型,比如`FileNotFoundError`用于捕获文件不存在错误,`ValueError`用于捕获数值错误等。
## 5.3 上下文管理器和异常的使用
在Python中,我们可以使用上下文管理器来管理资源的生命周期,同时还能更好地处理异常。
使用上下文管理器可以确保资源的正确关闭,即使在发生异常的情况下也能够正常关闭资源,避免资源泄露。
以下是一个使用上下文管理器的示例:
```python
with open('example.txt', 'r') as file:
content = file.read()
print(content)
```
在这个例子中,我们使用`with`语句打开了同一个文件,并将其赋值给了变量`file`。在`with`块内,我们执行了读取文件内容和输出文件内容的操作。当`with`块结束时,文件会被自动关闭,无需手动调用`close`方法。
使用上下文管理器不仅能够更简洁地管理资源的生命周期,还能更好地处理异常。当发生异常时,上下文管理器会优先处理异常并关闭资源,以保证程序的稳定运行。
总结:
本章我们学习了Python中的文件操作和异常处理。我们了解了如何使用`open`函数来打开文件,并进行读取和写入操作。同时,我们还学习了如何使用`try`和`except`语句来捕获和处理异常。最后,我们探讨了使用上下文管理器来管理资源的生命周期以及更好地处理异常的方法。
接下来,我们将进入第六章,介绍Python的标准库和常用模块。敬请期待!
# 6. Python标准库和常用模块
Python拥有丰富的标准库和各种常用的第三方模块,为开发者提供了强大的工具和组件,大大提高了开发效率和代码质量。本章将介绍Python中常用的标准库和第三方模块,以及对Python开发环境和工具的选择进行探讨。
#### 6.1 常用的标准库介绍
Python标准库涵盖了众多领域,提供了丰富的功能模块,包括但不限于:
- `os`:提供了丰富的操作系统接口,用于文件和目录操作、进程管理等。
- `sys`:用于访问与Python解释器和其环境有关的变量和函数。
- `math`:提供了对浮点数学运算的支持。
- `random`:用于生成伪随机数。
- `datetime`:处理日期和时间的标准库。
下面是一个使用`datetime`模块的示例代码:
```python
import datetime
# 获取当前日期和时间
now = datetime.datetime.now()
print("当前日期和时间:", now)
# 格式化输出日期
formatted_date = now.strftime("%Y-%m-%d %H:%M:%S")
print("格式化后的日期:", formatted_date)
# 创建一个指定日期时间的对象
specified_date = datetime.datetime(2021, 12, 25, 12, 0, 0)
print("指定的日期和时间:", specified_date)
```
上面的代码演示了如何使用`datetime`模块获取当前日期时间、进行日期时间格式化以及创建指定日期时间的操作。
#### 6.2 常用的第三方模块推荐
除了Python标准库外,还有许多优秀的第三方模块可以扩展Python的功能,例如:
- `requests`:强大而简洁的HTTP请求库,用于发送各种类型的HTTP请求。
- `beautifulsoup4`:用于解析HTML和XML文档的库,提供了便捷的信息提取工具。
- `pandas`:提供了高性能、易用的数据结构和数据分析工具,广泛应用于数据科学和数据分析领域。
下面是一个使用`requests`模块发送GET请求的示例代码:
```python
import requests
# 发送一个简单的GET请求
response = requests.get("https://api.github.com")
# 打印响应的状态码
print("响应状态码:", response.status_code)
# 打印响应内容的前100个字符
print("响应内容:", response.text[:100])
```
上面的代码展示了如何使用`requests`第三方模块发送一个简单的GET请求,并获取响应的状态码以及部分内容。
#### 6.3 Python开发环境和工具的选择
针对Python开发,开发者通常会选择合适的集成开发环境(IDE)或文本编辑器。常见的Python开发工具包括:
- PyCharm:JetBrains公司推出的一款功能强大的Python IDE,提供了丰富的功能和插件。
- Visual Studio Code:微软推出的轻量级跨平台代码编辑器,支持丰富的Python扩展。
- Jupyter Notebook:交互式笔记本,适合进行数据分析和可视化实验。
除了IDE和编辑器,Python的包管理工具也是开发过程中不可或缺的一部分。`pip`是Python的包管理工具,用于安装、卸载Python包。同时,`conda`也是一个常用的包管理工具,尤其适用于数据科学领域。
以上是关于Python标准库、第三方模块以及开发工具选择的简要介绍,希望可以帮助开发者更好地利用Python进行开发工作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏《Python 语言程序设计》提供了一个系统的学习Python编程的路径,从基础知识概述开始,涵盖了数据类型和运算符、输入与输出、循环语句、字符串和序列操作、字典和集合、函数调用和变量作用域、文件操作和标准库、绘图库的应用、数据库操作以及数据科学和机器学习等内容。通过这些文章,读者可以逐步掌握Python编程的各个方面,包括基础语法、数据处理、文件操作、图形绘制、数据库操作以及机器学习等应用。每篇文章都深入浅出地介绍了相应的概念和技巧,并辅以具体的实例和实践项目。无论是初学者还是有一定编程经验的人,都可以通过这个专栏快速入门Python,并逐步成为熟练的Python开发者。无论是为了学术研究、数据分析、还是为了开发自己的软件项目,Python的各种功能都能在这个专栏中找到。如果你想学习Python编程,这个专栏将是一个非常好的选择。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python内存管理速成课:5大技巧助你成为内存管理高手

# 摘要
本文系统地探讨了Python语言的内存管理机制,包括内存的分配、自动回收以及内存泄漏的识别与解决方法。首先介绍了Python内存管理的基础知识和分配机制,然后深入分析了内存池、引用计数以及垃圾回收的原理和算法。接着,文章针对高效内存使用策略进行了探讨,涵盖了数据结构优化、减少内存占用的技巧以及内存管理
D700高级应用技巧:挖掘隐藏功能,效率倍增

# 摘要
本文旨在详细介绍Nikon D700相机的基本操作、高级设置、进阶摄影技巧、隐藏功能与创意运用,以及后期处理与工作流优化。从基础的图像质量选择到高级拍摄模式的探索,文章涵盖了相机的全方位使用。特别地,针对图像处理和编辑,本文提供了RAW图像转换和后期编辑的技巧,以及高效的工作流建议。通过对D700的深入探讨,本文旨在帮助摄影爱好者和专业摄影师更好地掌握这款经典相机
DeGroot的统计宇宙:精通概率论与数理统计的不二法门

# 摘要
本文系统地介绍了概率论与数理统计的理论基础及其在现代科学与工程领域中的应用。首先,我们深入探讨了概率论的核心概念,如随机变量的分类、分布特性以及多变量概率分布的基本理论。接着,重点阐述了数理统计的核心方法,包括估计理论、假设检验和回归分析,并讨论了它们在实际问题中的
性能优化秘籍:Vue项目在HBuilderX打包后的性能分析与调优术

# 摘要
随着前端技术的飞速发展,Vue项目性能优化已成为提升用户体验和系统稳定性的关键环节。本文详细探讨了在HBuilderX环境下构建Vue项目的最佳实践,深入分析了性能分析工具与方法,并提出了一系列针对性的优化策略,包括组件与代码优化、资源管理以及打包与部署优化。此外,
MFC socket服务器稳定性关键:专家教你如何实现

# 摘要
本文综合介绍了MFC socket服务器的设计、实现以及稳定性提升策略。首先概述了MFC socket编程基础,包括通信原理、服务器架构设计,以及编程实践。随后,文章重点探讨了提升MFC socket服务器稳定性的具体策略,如错误处理、性能优化和安全性强化。此外,本文还涵
Swat_Cup系统设计智慧:打造可扩展解决方案的关键要素
# 摘要
本文综述了Swat_Cup系统的设计、技术实现、安全性设计以及未来展望。首先,概述了系统的整体架构和设计原理,接着深入探讨了可扩展系统设计的理论基础,包括模块化、微服务架构、负载均衡、无状态服务设计等核心要素。技术实现章节着重介绍了容器化技术(如Docker和Kubernetes)
【鼠标消息剖析】:VC++中实现精确光标控制的高级技巧

# 摘要
本论文系统地探讨了鼠标消息的处理机制,分析了鼠标消息的基本概念、分类以及参数解析方法。深入研究了鼠标消息在精确光标控制、高级处理技术以及多线程环境中的应用。探讨了鼠标消息拦截与模拟的实践技巧,以及如何在游戏开发中实现自定义光标系统,优化用户体验。同时,提出了鼠标消息处理过程中的调试与优化策略,包括使用调试工
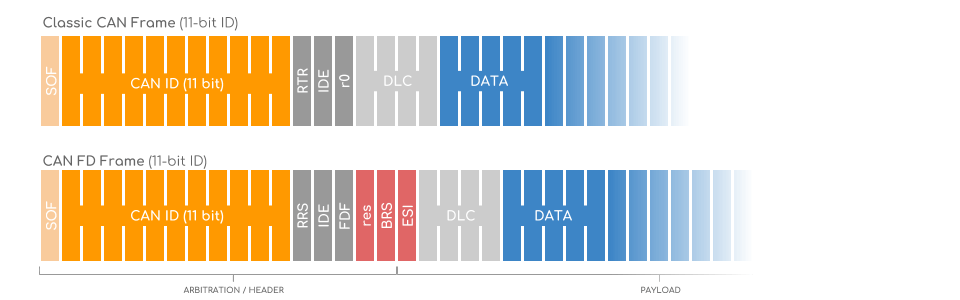
【车辆网络通信整合术】:CANoe中的Fast Data Exchange(FDX)应用
# 摘要
本文主要探讨了CANoe工具与Fast Data Exchange(FDX)技术在车辆网络通信中的整合与应用。第一章介绍了车辆网络通信整合的基本概念。第二章详细阐述了CANoe工具及FDX的功能、工作原理以及配置管理方法。第三章着重分析了FDX在车载数据采集、软件开发及系统诊断中的实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )