STM32单片机指令集与寄存器:深入解析,提升编程效率
发布时间: 2024-07-03 13:20:16 阅读量: 236 订阅数: 43 

STM32常用汇编指令.pdf

# 1. STM32单片机架构与指令集概述
STM32单片机是意法半导体(STMicroelectronics)推出的32位微控制器系列,基于ARM Cortex-M内核,广泛应用于嵌入式系统中。
STM32单片机的架构主要包括:
* **内核:**负责执行指令和处理数据,包括ARM Cortex-M系列内核,如Cortex-M3、Cortex-M4和Cortex-M7。
* **存储器:**存储程序和数据,包括闪存(Flash)、静态随机存储器(SRAM)和动态随机存储器(DRAM)。
* **外设:**提供各种功能,如定时器、串口、ADC和DAC,用于与外部设备交互。
* **总线:**连接各个组件,包括地址总线、数据总线和控制总线。
STM32单片机的指令集包括:
* **基本指令集:**用于执行基本操作,如数据传输、算术和逻辑运算。
* **高级指令集:**用于执行更复杂的操作,如条件执行、循环和中断处理。
* **位操作指令:**用于对寄存器的单个位进行操作。
# 2. STM32单片机寄存器详解
### 2.1 通用寄存器组
#### 2.1.1 通用寄存器的功能和用途
STM32单片机共有16个通用寄存器,分别为R0~R15。这些寄存器主要用于存储数据和地址,可以根据需要灵活使用。
| 寄存器 | 用途 |
|---|---|
| R0 | 常用作累加器,存储运算结果 |
| R1 | 常用作基址寄存器,存储地址偏移量 |
| R2~R3 | 常用作指针寄存器,存储内存地址 |
| R4~R7 | 常用作临时寄存器,存储中间数据 |
| R8~R11 | 常用作参数寄存器,传递函数参数 |
| R12 | 常用作帧指针,指向当前函数的栈帧 |
| R13 | 常用作栈指针,指向当前栈顶 |
| R14 | 常用作连接寄存器,存储函数返回地址 |
| R15 | 常用作程序计数器,指向下一条要执行的指令 |
#### 2.1.2 通用寄存器的寻址方式
STM32单片机的通用寄存器可以通过以下寻址方式访问:
* **寄存器直接寻址:**直接使用寄存器名,如:`MOV R0, #10`
* **寄存器间接寻址:**使用`*`运算符,如:`MOV R0, [R1]`
* **寄存器相对寻址:**使用`+`或`-`运算符,如:`MOV R0, [R1 + #10]`
* **基址寻址:**使用`[]`运算符,如:`MOV R0, [R1, R2]`
### 2.2 特殊功能寄存器组
#### 2.2.1 外设控制寄存器
外设控制寄存器用于控制和配置单片机的各种外设,如定时器、串口、ADC等。这些寄存器通常具有以下功能:
* **控制位:**用于使能或禁用外设,设置工作模式等。
* **配置位:**用于设置外设的时钟频率、数据格式、中断使能等。
* **状态位:**用于反映外设的当前状态,如是否发生中断、数据是否就绪等。
#### 2.2.2 中断控制寄存器
中断控制寄存器用于管理单片机的中断系统,主要包括以下功能:
* **中断使能寄存器:**用于使能或禁用特定的中断源。
* **中断优先级寄存器:**用于设置不同中断源的优先级。
* **中断挂起寄存器:**用于挂起或恢复特定的中断源。
* **中断服务程序地址寄存器:**用于存储特定中断源的中断服务程序地址。
### 代码示例
以下代码示例展示了如何使用通用寄存器和特殊功能寄存器:
```
; 初始化定时器1
MOV R0, #0x40000000 ; 定时器1基址地址
MOV R1, #0x00000001 ; 使能定时器1
STR R1, [R0 + #0x00] ; 写入控制寄存器
; 设置定时器1时钟频率为1MHz
MOV R0, #0x40000000 ; 定时器1基址地址
MOV R1, #0x00000004 ; 设置时钟源为APB1
STR R1, [R0 + #0x04] ; 写入时钟配置寄存器
; 设置定时器1中断优先级为最高
MOV R0, #0xE000E104 ; 中断优先级寄存器地址
MOV R1, #0x000000FF ; 设置定时器1中断优先级为最高
STR R1, [R0 + #0x04] ; 写入中断优先级寄存器
```
### 逻辑分析
上述代码首先初始化定时器1,使能定时器并设置时钟源。然后设置定时器1的中断优先级为最高,确保定时器1中断能够及时响应。
### 参数说明
| 参数 | 说明 |
|---|---|
| `R0` | 通用寄存器,用于存储定时器1基址地址 |
| `R1` | 通用寄存器,用于存储控制位和配置位 |
| `#0x40000000` | 定时器1基址地址 |
| `#0x00000001` | 使能定时器1控制位 |
| `#0x00000004` | 设置时钟源为APB1配置位 |
| `#0xE000E104` | 中断优先级寄存器地址 |
| `#0x000000FF` | 设置定时器1中断优先级为最高 |
# 3. STM32单片机指令集编程实践
### 3.1 基本指令集
#### 3.1.1 数据传输指令
数据传输指令用于在寄存器、存储器和外设之间移动数据。常用的数据传输指令包括:
- **MOV**:将数据从一个源操作数移动到一个目标操作数。
- **LD**:将数据从存储器加载到寄存器。
- **ST**:将数据从寄存器存储到存储器。
- **PUSH**:将数据压入堆栈。
- **POP**:将数据从堆栈弹出。
**代码块:**
```assembly
MOV R0, #0x1234
LD R1, [R0]
ST R2, [R0]
PUSH R3
POP R4
```
**逻辑分析:**
* 第一行将十六进制值 0x1234 加载到寄存器 R0 中。
* 第二行将存储在 R0 中的地址处的数据加载到寄存器 R1 中。
* 第三行将寄存器 R2 中的数据存储到 R0 中的地址处。
* 第四行将寄存器 R3 中的数据压入堆栈。
* 第五行将堆栈中的数据弹出到寄存器 R4 中。
#### 3.1.2 算术逻辑指令
算术逻辑指令用于对数据进行算术和逻辑操作。常用的算术逻辑指令包括:
- **ADD**:将两个操作数相加。
- **SUB**:将两个操作数相减。
- **MUL**:将两个操作数相乘。
- **DIV**:将两个操作数相除。
- **AND**:对两个操作数进行按位与操作。
- **OR**:对两个操作数进行按位或操作。
- **XOR**:对两个操作数进行按位异或操作。
**代码块:**
```assembly
ADD R0, R1, R2
SUB R3, R4, R5
MUL R6, R7, R8
DIV R9, R10, R11
AND R12, R13, R14
OR R15, R16, R17
XOR R18, R19, R20
```
**逻辑分析:**
* 第一行将寄存器 R1 和 R2 中的数据相加,结果存储在 R0 中。
* 第二行将寄存器 R4 和 R5 中的数据相减,结果存储在 R3 中。
* 第三行将寄存器 R7 和 R8 中的数据相乘,结果存储在 R6 中。
* 第四行将寄存器 R10 和 R11 中的数据相除,结果存储在 R9 中。
* 第五行对寄存器 R13 和 R14 中的数据进行按位与操作,结果存储在 R12 中。
* 第六行对寄存器 R16 和 R17 中的数据进行按位或操作,结果存储在 R15 中。
* 第七行对寄存器 R19 和 R20 中的数据进行按位异或操作,结果存储在 R18 中。
### 3.2 高级指令集
#### 3.2.1 条件执行指令
条件执行指令根据条件是否满足来执行或跳过指令。常用的条件执行指令包括:
- **B**:无条件跳转。
- **BEQ**:如果相等则跳转。
- **BNE**:如果不相等则跳转。
- **BGT**:如果大于则跳转。
- **BLT**:如果小于则跳转。
**代码块:**
```assembly
B label
BEQ R0, #0, label
BNE R1, R2, label
BGT R3, R4, label
BLT R5, R6, label
```
**逻辑分析:**
* 第一行无条件跳转到标签 label。
* 第二行如果寄存器 R0 等于 0,则跳转到标签 label。
* 第三行如果寄存器 R1 不等于 R2,则跳转到标签 label。
* 第四行如果寄存器 R3 大于 R4,则跳转到标签 label。
* 第五行如果寄存器 R5 小于 R6,则跳转到标签 label。
#### 3.2.2 循环指令
循环指令用于重复执行一段代码。常用的循环指令包括:
- **CMP**:比较两个操作数。
- **BLE**:如果小于或等于则跳转。
- **BGE**:如果大于或等于则跳转。
- **B**:无条件跳转。
**代码块:**
```assembly
loop:
CMP R0, #10
BLE loop
B end
end:
```
**逻辑分析:**
* 该代码段是一个无限循环,不断将寄存器 R0 与 10 进行比较。
* 如果 R0 小于或等于 10,则跳转到标签 loop,继续执行循环。
* 如果 R0 大于 10,则跳转到标签 end,退出循环。
# 4. STM32单片机寄存器编程技巧
### 4.1 寄存器操作的位操作
#### 4.1.1 位操作指令
STM32单片机提供了丰富的位操作指令,可以对寄存器中的单个位进行操作,包括:
- `SETBIT`:将指定位置1
- `CLRBIT`:将指定位置0
- `INVBIT`:将指定位取反
- `TSTBIT`:测试指定位的值
#### 4.1.2 位操作的应用场景
位操作指令在寄存器编程中有着广泛的应用,例如:
- **设置或清除标志位:**通过设置或清除寄存器中特定的标志位,可以控制程序的执行流程。
- **控制外设:**许多外设寄存器包含控制外设功能的位,通过位操作可以实现对这些功能的细粒度控制。
- **数据处理:**位操作指令可以用于执行简单的布尔运算、位移和旋转操作。
### 4.2 寄存器组的管理
#### 4.2.1 寄存器组的保存和恢复
STM32单片机提供了多种方法来保存和恢复寄存器组,包括:
- **压栈和出栈指令:**`PUSH`和`POP`指令可以将寄存器组压入或弹出堆栈,从而实现寄存器组的保存和恢复。
- **寄存器组切换指令:**`MRS`和`MSR`指令可以将当前寄存器组切换到指定的寄存器组,从而实现寄存器组的快速切换。
#### 4.2.2 寄存器组的切换
寄存器组切换在以下场景中非常有用:
- **上下文切换:**当发生中断或异常时,需要保存当前寄存器组并切换到异常处理程序的寄存器组。
- **任务调度:**在多任务系统中,需要在不同的任务之间切换寄存器组,以保证每个任务拥有自己的寄存器环境。
- **代码优化:**通过切换寄存器组,可以避免频繁使用压栈和出栈指令,从而优化代码性能。
# 5.1 汇编语言编程
### 5.1.1 汇编语言的语法和结构
汇编语言是一种低级编程语言,它直接操作CPU的寄存器和指令集。汇编语言的语法和结构与机器语言非常相似,但它使用助记符来表示指令,而不是二进制代码。
汇编语言程序由一系列指令组成,每条指令都包含一个操作码和一个或多个操作数。操作码指定要执行的操作,而操作数指定操作所涉及的数据或地址。
汇编语言程序通常分为以下几个部分:
- **数据段:**存储程序中使用的常量和变量。
- **代码段:**包含程序的指令。
- **堆栈段:**用于存储函数调用和局部变量。
### 5.1.2 汇编语言的指令集
汇编语言的指令集包括各种指令,用于执行算术、逻辑、数据传输、控制流和输入/输出操作。以下是一些常用的汇编语言指令:
| 指令 | 描述 |
|---|---|
| MOV | 将数据从一个位置移动到另一个位置 |
| ADD | 将两个数字相加 |
| SUB | 将两个数字相减 |
| MUL | 将两个数字相乘 |
| DIV | 将两个数字相除 |
| CMP | 比较两个数字 |
| JMP | 跳转到指定地址 |
| CALL | 调用一个函数 |
| RET | 从函数返回 |
汇编语言指令通常使用寄存器作为操作数。寄存器是CPU内部的小型存储单元,用于存储临时数据和地址。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**STM32 单片机解密专栏**
本专栏深入解析 STM32 单片机的内部架构、指令集、寄存器、外设功能、中断机制、时钟系统、电源管理、存储器结构、I/O 端口、通信协议、DMA、ADC、固件升级、调试、故障分析、性能优化、功耗管理、安全机制、开发环境、RTOS、图形界面、网络通信、传感器、电机控制、人工智能和机器学习等各个方面。
通过揭秘这些关键技术,专栏旨在帮助开发人员充分掌握 STM32 单片机的特性和应用,从而开发出高效、可靠、智能的嵌入式系统。本专栏内容深入浅出,既适合初学者入门,也适合经验丰富的工程师进阶。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
5G NR信号传输突破:SRS与CSI-RS差异的实战应用
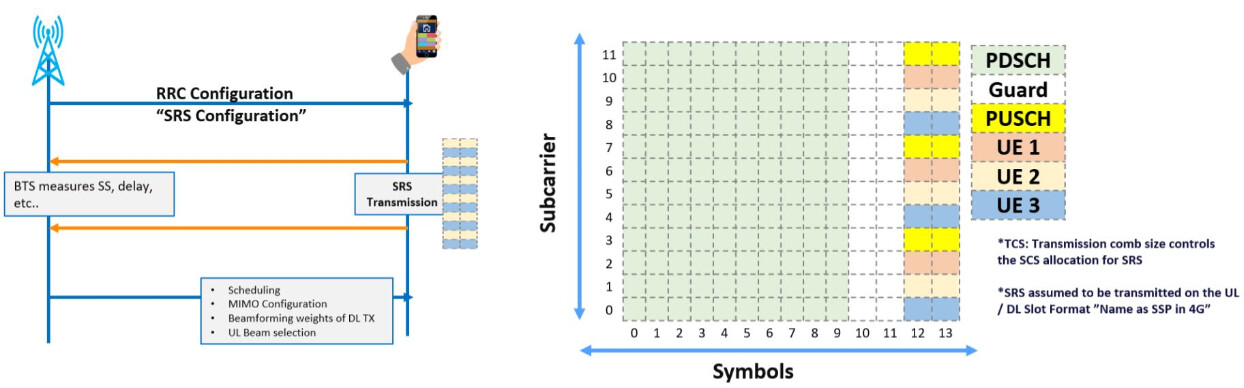
# 摘要
本文深入探讨了5G NR信号传输中SRS信号和CSI-RS信号的理论基础、实现方式以及在5G网络中的应用。首先介绍了SRS信号的定义、作用以及配置和传输方法,并探讨了其优化策略。随后,文章转向CSI-RS信号,详细阐述了其定义、作用、配置与传输,并分析了优化技术。接着,本文通过实际案例展示了SRS和CSI-RS在5G N
【性能分析】:水下机器人组装计划:性能测试与提升的实用技巧
# 摘要
水下机器人作为探索海洋环境的重要工具,其性能分析与优化是当前研究的热点。本文首先介绍了水下机器人性能分析的基础知识,随后详细探讨了性能测试的方法,包括测试环境的搭建、性能测试指标的确定、数据收集与分析技术。在组装与优化方面,文章分析了组件选择、系统集成、调试过程以及性能提升的实践技巧。案例研究部分通过具体实例,探讨了速度、能源效率和任务执行可靠性的
【性能基准测试】:ILI9881C与其他显示IC的对比分析

# 摘要
随着显示技术的迅速发展,性能基准测试已成为评估显示IC(集成电路)性能的关键工具。本文首先介绍性能基准测试的基础知识和显示IC的概念。接着,详细探讨了显示IC性能基准测试的理论基础,包括性能指标解读、测试环境与工具选择以及测试方法论。第三章专注于ILI
从零到英雄:MAX 10 LVDS IO电路设计与高速接口打造

# 摘要
本文主要探讨了MAX 10 FPGA在实现LVDS IO电路设计方面的应用和优化。首先介绍了LVDS技术的基础知识、特性及其在高速接口中的优势和应用场景。随后,文章深入解析了MAX 10器件的特性以及在设计LVDS IO电路时的前期准备、实现过程和布线策略。在高速接口设计与优化部分,本文着重阐述了信号完整性、仿真分析以及测试验证的关键步骤和问题解决方法。最
【群播技术深度解读】:工控机批量安装中的5大关键作用

# 摘要
群播技术作为高效的网络通信手段,在工控机批量安装领域具有显著的应用价值。本文旨在探讨群播技术的基础理论、在工控机批量安装中的实际应用以及优化策略。文章首先对群播技术的原理进行解析,并阐述其在工控机环境中的优势。接着,文章详细介绍了工控机批量安装前期准备、群播技术实施步骤及效果评估与优化。深入分析了多层网络架构中群播的实施细节,以及在保证安全性和可靠性的同时,群播技术与现代工控机发展
Twincat 3项目实战:跟随5个案例,构建高效的人机界面系统
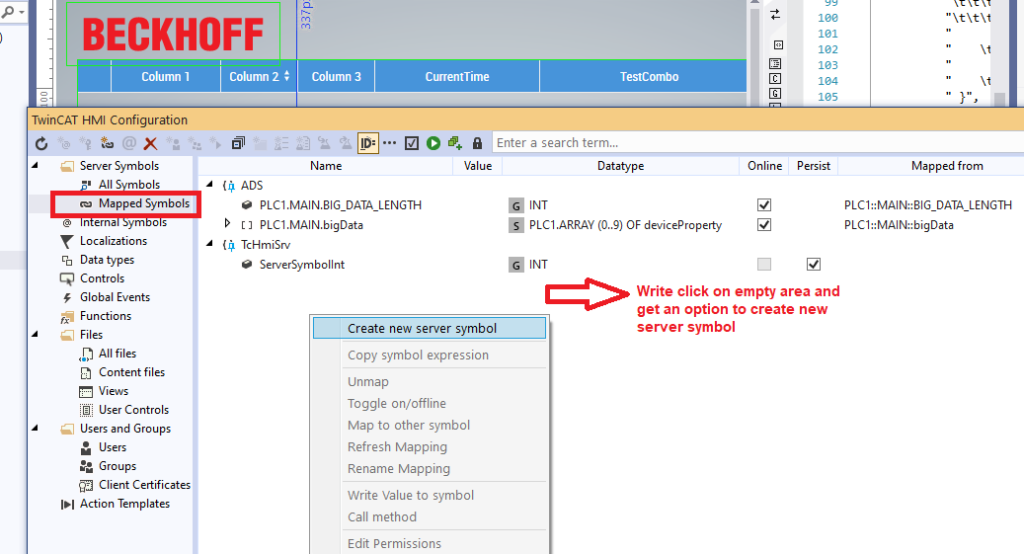
# 摘要
本论文提供了一个全面的Twincat 3项目实战概览,涵盖了从基础环境搭建到人机界面(HMI)设计,再到自动化案例实践以及性能优化与故障诊断的全过程。文章详细介绍了硬件选择、软件配置、界面设计原则、功能模块实现等关键步骤,并通过案例分析,探讨了简单与复杂自动化项目的设计与执行。最后,针对系统性能监测、优化和故障排查,提出了实用的策略和解决方案,并
【MT2492降压转换器新手必读】:快速掌握0到1的使用技巧与最佳实践

# 摘要
本文全面介绍了MT2492降压转换器的设计、理论基础、实践操作、性能优化以及最佳实践应用。首先,本文对MT2492进行了基本介绍,阐释了其工作原理和主要参数。接着,详细解析了硬件接线和软件编程的相关步骤和要点。然后,重点讨论了性能优化策略,包括热管理和故障诊断处理。最后,本文提供了MT2492在不同应用场景中的案例分析,强调了其在电
【水务行业大模型指南】:现状剖析及面临的挑战与机遇
# 摘要
本论文对水务行业的现状及其面临的数据特性挑战进行了全面分析,并探讨了大数据技术、机器学习与深度学习模型在水务行业中的应用基础与实践挑战。通过分析水质监测、水资源管理和污水处理等应用场景下的模型应用案例,本文还着重讨论了模型构建、优化算法和模型泛化能力等关键问题。最后,展望了水务行业大模型未来的技术发展趋势、政策环境机遇,以及大模型在促进可持续发展中的潜在作用。
# 关键字
水务行业;大数据技术;机器学习
SoMachine V4.1与M241的协同工作:综合应用与技巧
# 摘要
本文介绍了SoMachine V4.1的基础知识、M241控制器的集成过程、高级应用技巧、实践应用案例以及故障排除和性能调优方法。同时,探讨了未来在工业4.0和智能工厂融合背景下,SoMachine V4.1与新兴技术整合的可能性,并讨论了教育和社区资源拓展的重要性。通过对SoMachine V4.1和M241控制器的深入分析,文章旨在为工业自动化领域提供实用的实施策略和优化建议,确保系统的高效运行和可靠控
【Cadence Virtuoso热分析技巧】:散热设计与热效应管理,轻松搞定
# 摘要
随着集成电路技术的快速发展,热分析在电子设计中的重要性日益增加。本文系统地介绍了Cadence Virtuoso在热分析方面的基础理论与应用,涵盖了散热设计、热效应管理的策略与技术以及高级应用。通过对热传导、对流、辐射等基础知识的探讨,本文详细分析了散热路径优化、散热材料选择以及热仿真软件的使用等关键技术,并结合电源模块、SoC和激光二极管模块的实践案例进行了深入研究。文章还探讨了多物理场耦合分析、高效热分析流程的建立以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )