




PyTorch多GPU训练进阶技巧:混合精度训练(AMP)的深度优化


基于S7-200 PLC与MCGS组态的洗衣机控制系统设计与实现
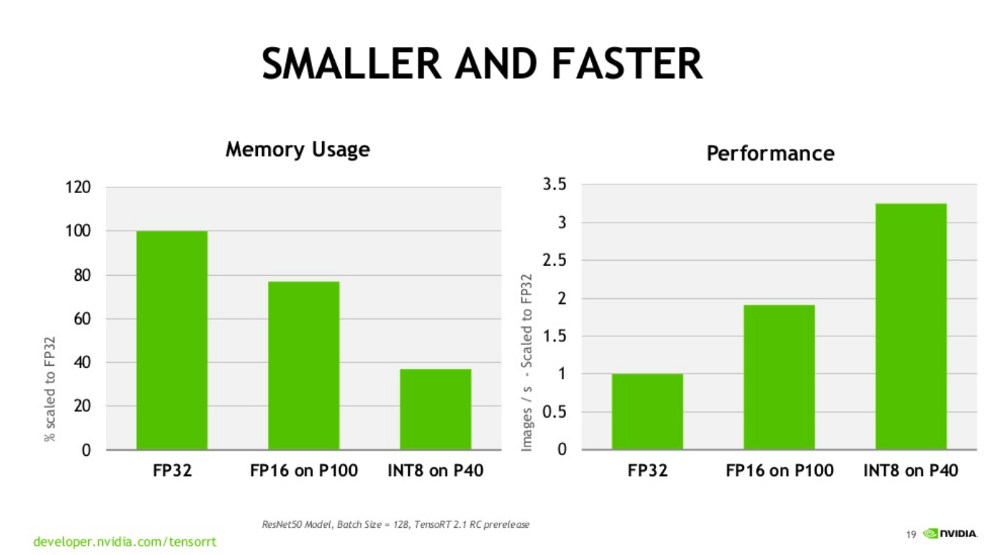
1. 混合精度训练(AMP)概述
在深度学习领域,模型训练的速度和效率始终是研究者和工程师关注的焦点。混合精度训练(AMP)作为一种提高训练速度和减少内存消耗的技术,已经被广泛应用在各种深度学习框架中。本章将带你了解混合精度训练的基本概念、优势以及它在实际应用中的必要性。
2.1 混合精度训练的基本概念
混合精度训练是一种在训练深度神经网络时使用不同数据类型的策略。它涉及使用单精度浮点数(FP32)和半精度浮点数(FP16)共同参与计算,从而在保持模型性能的同时,提升训练速度并减少内存使用。
2.1.1 精度和性能的关系
精度是指数据表示的精确程度,通常情况下,使用更高的数据精度可以提供更好的模型训练效果,但也伴随着更高的计算成本和内存需求。而较低精度可以显著提高计算速度,但也可能引入数值稳定性问题,影响最终的训练效果。
2.1.2 混合精度训练的优势和必要性
混合精度训练综合了FP32和FP16的优势,它不仅能够利用FP16的高计算效率,还能够借助FP32的数值稳定性来维持训练过程的鲁棒性。通过合理设计,混合精度训练可以减少内存占用、加快模型训练速度,而且对于现代GPU架构的支持度也越来越高,对于大规模深度学习模型的训练变得尤为必要。
2. PyTorch中的混合精度训练基础
2.1 混合精度训练的基本概念
2.1.1 精度和性能的关系
在深度学习训练过程中,模型的权重和激活值通常使用32位浮点数(float32,也称为单精度)进行存储。然而,这一过程可能涉及到大量的计算资源和时间成本。降低计算精度到16位浮点数(float16,也称为半精度)能减少内存占用并加速计算,但单纯的半精度训练会因数值范围和精度限制导致训练不稳定,甚至性能下降。
在混合精度训练中,模型的权重和激活值在计算过程中交替使用float16和float32,以求在不牺牲模型性能的前提下,减少资源消耗并提高训练速度。混合精度训练将模型的参数和计算的精度分开考虑,保持模型的稳定性,同时利用低精度算术进行高效计算。
2.1.2 混合精度训练的优势和必要性
混合精度训练的主要优势在于能够大幅缩短训练时间,同时减少内存使用量,从而允许训练更大的模型。此外,在某些硬件上,低精度计算还可以提高吞吐量,因为现代GPU如NVIDIA的Tensor Cores专门设计来优化float16的计算。
混合精度训练的必要性在于当前深度学习模型越来越复杂,需要更多的计算资源。传统的单精度训练方法在大型模型和数据集上会面临巨大的训练时间成本。而混合精度训练可以在不增加成本的情况下,提供显著的性能提升,使得研究人员能够在相同的时间内探索更多的模型架构或进行更大规模的实验。
2.2 PyTorch AMP模块简介
2.2.1 AMP模块的主要功能
PyTorch的自动混合精度(Automatic Mixed Precision, AMP)模块,允许开发者在几乎不修改现有代码的情况下,实现混合精度训练。其主要功能包括:
- 自动管理数据类型转换,实现float16和float32之间的无缝切换。
- 提供损失缩放机制,以防止在使用float16时梯度消失的问题。
- 能够适应不同硬件和GPU配置,无需额外配置。
2.2.2 AMP模块的API概述
PyTorch AMP模块主要由两个API组成:torch.cuda.amp模块中的autocast上下文管理器和GradScaler类。
autocast上下文管理器:在代码块中启用自动混合精度,自动将计算转换为float16。GradScaler类:实现梯度缩放,以便在进行反向传播之前将梯度缩放到一个安全的范围。
下面是一个使用PyTorch AMP模块的基本代码示例:

2.3 实现混合精度训练的基本步骤
2.3.1 初始化AMP环境
初始化AMP环境主要涉及配置环境以支持自动混合精度。在PyTorch中,这通常意味着在训练循环之前导入必要的模块,并且有时候需要确保使用支持自动混合精度的硬件。大多数情况下,初始化工作是由PyTorch自动完成的,用户只需要在训练循环中使用autocast上下文管理器即可。
2.3.2 编写AMP训练循环
编写混合精度训练循环的核心在于将模型的前向和后向传播放入autocast上下文管理器中,并利用GradScaler进行梯度缩放。重要的是,所有的操作都必须在与模型相同的设备(CPU或GPU)上执行,以保证性能。
2.3.3 模型和优化器的调整策略
在混合精度训练中,模型和优化器的调整策略不同于传统的单精度训练。由于使用了float16,模型的权重和梯度的动态范围可能会减小。因此,需要对学习率和权重衰减等超参数进行适当的调整,以避免训练不稳定。
此外,还应定期监控训练过程中可能出现的数值异常,如NaN(非数字)或Inf(无穷大)值。在某些情况下,可能需要适当增加损失缩放因子,以确保梯度信息不会在反向传播中消失。
3. PyTorch AMP高级应用
3.1 自定义混合精度策略
3.1.1 精度范围的调整
在PyTorch中实现混合精度训练时,能够调整精度范围是至关重要的。这不仅影响到模型的训练速度和资源消耗,还可能影响到训练的稳定性和最终模型的性能。AMP(Automatic Mixed Precision)通过动态调整FP32和FP16之间的数据类型,来优化性能和精度。
要调整精度范围,首先需要理解AMP的两个关键组件:GradScaler和scale_loss。GradScaler负责管理损失的缩放,而scale_loss则负责将损失动态缩放到一个在FP16中可以安全处理的范围内。默认情况下,PyTorch的AMP使用自动缩放策略,但开发者可以自定义缩放范围来适应特定的需求。
通过自定义GradScaler的初始化,开发者可以调整其参数,比如init_scale来设置初始缩放值,或者调整growth_factor和backoff_factor来控制缩放策略在遇到梯度消失或爆炸时的响应方式。
3.1.2 损失缩放技术的应用
损失缩放技术是混合精度训练中的一项关键技术,它帮助解决FP16训练中的数值范围限制问题。在FP16中,数值范围大约在610^-8到610^8之间,远小于FP32的范围。如果在训练中直接使用原始损失,很容易发生梯度消失或梯度爆炸,导致训练不稳定或失败。
损失缩放技术通过在训练循环中放大损失值来避免这个问题。这使得优化器处理的是更大的梯度值,但是这些梯度值是经过缩放的,不会超出FP16的处理范围。当对梯度执行优化步骤时,需要相应地缩放梯度。
- # 假设loss是在autocast上下文中计算得到的FP16 tensor
- # 初始化一个GradScaler实例
- scaler = GradScaler(init_scale=2.**16, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000)
- for input, target in data:
- optimizer.zero_grad()
- # 使用autocast控制自动混合精度
- with autocast():
- output = model(input)
- loss = criterion(output, target)
- # 使用GradScaler缩放loss,进行反向传播和优化步骤
- scaler.scale(loss).backward()
- sc

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
Cygwin系统监控指南:性能监控与资源管理的7大要点
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【精准测试】:确保分层数据流图准确性的完整测试方法
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
【T-Box能源管理】:智能化节电解决方案详解


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















