Docker 容器技术初探
发布时间: 2023-12-21 00:33:32 阅读量: 41 订阅数: 41 

docker容器技术初探与实践
# 章节一:Docker 容器技术概述
## 1.1 Docker 容器的基本概念和原理
Docker 是一个开源的平台,利用 Linux 容器(LXC)和内核的命名空间(namespace)技术,能够为应用程序提供一个"容器",用于隔离应用及其依赖环境。Docker 容器包含应用程序所需的所有内容:代码、运行时环境、系统工具、系统库等,确保应用在任何环境中都能够一致运行。
通过 Docker 容器,可以实现开发、交付、运行和扩展应用程序。Docker 容器的基本组成部分包括镜像(image)、容器(container)、仓库(repository)和 Docker 客户端、主机、守护进程等。
在 Docker 容器技术中,有几个核心概念需要理解:
- 镜像(Image):Docker 镜像是容器的基础,它包含了运行容器所需的所有代码、库、环境变量和配置文件等。镜像可以被用来创建和运行容器。
- 容器(Container):容器是 Docker 镜像的运行实例,它包含了应用程序及其依赖的运行时环境。通过容器,可以将应用程序隔离运行,并且提供了一致的运行环境。
- 仓库(Repository):Docker 仓库用于保存 Docker 镜像,分为公共仓库和私有仓库。可以通过 Docker 仓库进行镜像的发布、共享和获取。
Docker 容器技术的基本原理是利用 Linux 内核的命名空间和控制组(cgroup)等技术实现对进程、文件系统、网络、用户等资源的隔离。这种轻量级的隔离机制使得 Docker 容器相比于传统虚拟化技术有更高的性能和更快的启动速度。
```python
# 示例代码:使用 Docker 容器运行一个简单的 Python 应用
# 1. 首先,确保本地已经安装 Docker 并启动
# 2. 编写一个简单的 Python 应用,比如 hello.py
# 示例代码如下:
# hello.py
print("Hello, Docker!")
# 3. 编写 Dockerfile,用于构建 Docker 镜像
# 示例 Dockerfile 内容如下:
# Dockerfile
FROM python:3
COPY hello.py /
CMD ["python", "./hello.py"]
# 4. 在终端执行以下命令,构建 Docker 镜像
# $ docker build -t hello-python .
# 5. 运行 Docker 容器,执行 Python 应用
# $ docker run hello-python
# 输出:Hello, Docker!
```
**代码总结:**
以上示例代码演示了如何使用 Docker 容器运行一个简单的 Python 应用。首先编写一个简单的 Python 应用 hello.py,然后编写 Dockerfile 定义镜像的构建过程和运行时配置。最后通过命令构建 Docker 镜像,并运行 Docker 容器来执行 Python 应用。
**结果说明:**
## 章节二:Docker 安装与配置
### 2.1 Docker 的安装步骤及要点
Docker 的安装分为在不同操作系统下的安装步骤,下面以 Ubuntu 20.04 为例进行说明。
步骤一:更新系统软件包
```bash
sudo apt update
sudo apt upgrade
```
步骤二:安装 Docker 依赖
```bash
sudo apt install apt-transport-https ca-certificates curl software-properties-common
```
步骤三:添加 Docker 官方 GPG 密钥
```bash
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
```
步骤四:添加 Docker 软件源
```bash
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
```
步骤五:安装 Docker 引擎
```bash
sudo apt update
sudo apt install docker-ce
```
步骤六:启动 Docker 服务
```bash
sudo systemctl start docker
```
步骤七:验证 Docker 是否安装成功
```bash
sudo docker --version
```
### 2.2 Docker 网络配置与容器间通讯
Docker 提供了多种网络模式,常用的有 bridge、host、overlay 等。其中 bridge 是 Docker 默认的网络模式,容器之间可以通过桥接网络进行通讯。
步骤一:查看 Docker 网络列表
```bash
sudo docker network ls
```
步骤二:创建自定义的 bridge 网络
```bash
sudo docker network create my-bridge-network
```
步骤三:启动带网络设置的容器
```bash
sudo docker run -d --name container1 --network my-bridge-network nginx
sudo docker run -d --name container2 --network my-bridge-network nginx
```
步骤四:测试容器间通讯
```bash
sudo docker exec -it container1 ping container2
```
### 2.3 Docker 存储管理与数据卷配置
Docker 的数据卷(Volume)可以在容器之间共享和持久化数据,提供了方便的存储管理方式。
步骤一:创建数据卷
```bash
sudo docker volume create my-volume
```
步骤二:启动容器并挂载数据卷
```bash
sudo docker run -d --name volume-test --mount source=my-volume,target=/data nginx
```
步骤三:在容器中操作数据卷
```bash
sudo docker exec -it volume-test /bin/bash
# 在容器内部进行文件操作,对 /data 目录下的内容进行修改
```
### 章节三:Docker 镜像管理
Docker 镜像是容器的基础,它包含了运行容器所需的所有内容,包括文件系统、代码、运行时库等。在本章节中,我们将深入讨论 Docker 镜像的理解、构建、发布与分享、版本管理与更新等内容。
#### 3.1 Docker 镜像的理解与构建
在 Docker 中,镜像是由多个文件系统构成,并且每个文件系统都是 Docker 镜像的一个层。通常情况下,一个 Docker 镜像会基于另外一个镜像进行定制化,最终形成多层叠加的文件系统。这种结构使得镜像的构建和定制变得非常灵活。
要构建一个 Docker 镜像,我们首先需要编写一个 Dockerfile 文件,其中定义了镜像的内容和构建步骤。接下来,我们通过 `docker build` 命令来构建镜像,示例 Dockerfile 如下:
```Dockerfile
# 使用官方 Python 运行时作为父镜像
FROM python:3.7-slim
# 设置镜像的作者信息
LABEL maintainer="yourname@example.com"
# 在镜像内创建一个新目录
RUN mkdir /app
# 将工作目录切换为 /app
WORKDIR /app
# 将本地目录下的所有内容复制到 /app 下
COPY . /app
# 使用 pip 安装依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 容器监听的端口
EXPOSE 80
# 容器启动时运行 app.py
CMD ["python", "app.py"]
```
通过上述 Dockerfile,我们定义了一个基于 Python 3.7 的镜像,将当前目录下的代码复制到镜像中,并安装依赖。运行 `docker build -t my-python-app .` 命令,即可构建出名为 `my-python-app` 的镜像。
#### 3.2 Docker 镜像的发布与分享
构建好的 Docker 镜像可以发布到 Docker Hub 或私有仓库中,以便他人下载和使用。要发布镜像到 Docker Hub,首先需要在 Docker Hub 上注册账号,并通过 `docker login` 命令登录。接着使用 `docker tag` 命令给镜像打上适当的标签,然后通过 `docker push` 命令将镜像上传至 Docker Hub。
```bash
# 给镜像打标签
docker tag my-python-app username/my-python-app
# 将镜像上传至 Docker Hub
docker push username/my-python-app
```
#### 3.3 Docker 镜像的版本管理与更新
在 Docker 中,每个镜像都可以有多个不同的版本。可以使用 `docker tag` 命令给镜像打上不同的标签,来管理不同的版本。通过版本管理,可以方便地进行镜像的更新和回滚操作。
```bash
# 给镜像打上带有版本号的标签
docker tag my-python-app username/my-python-app:v1.0
# 更新镜像的代码和依赖后,构建新版本的镜像
docker build -t my-python-app:latest .
# 将新版本的镜像上传至 Docker Hub
docker push username/my-python-app:latest
```
## 章节四:Docker 容器管理
在本章中,我们将深入讨论 Docker 容器的管理,包括容器的创建与启动、容器的监控与日志管理,以及容器的网络与资源控制。
### 4.1 Docker 容器的创建与启动
在 Docker 中,可以通过 Docker 镜像来创建和启动容器。首先,我们需要下载或构建一个 Docker 镜像,然后可以使用该镜像来创建和启动容器。
下面是一个基本的示例,演示了如何使用 Docker 镜像创建并启动一个简单的容器。
```bash
# 使用 Docker 镜像创建并启动一个容器
docker run -d -p 8080:80 --name my_container nginx
```
上面的命令中:
- `docker run`:表示运行一个新的容器
- `-d`:表示在后台模式下运行容器
- `-p 8080:80`:表示将主机的 8080 端口映射到容器的 80 端口
- `--name my_container`:为容器命名为 my_container
- `nginx`:指定要使用的 Docker 镜像为 nginx
通过上面的命令,我们成功创建并启动了一个基于 nginx 镜像的容器,并且将容器的 80 端口映射到主机的 8080 端口。
### 4.2 Docker 容器的监控与日志管理
在实际的生产环境中,我们通常需要对 Docker 容器进行监控,并且管理容器的日志输出。Docker 提供了丰富的命令和工具来实现这些操作。
例如,我们可以使用 `docker stats` 命令来实时监控运行中容器的资源占用情况。
```bash
# 查看容器实时资源占用情况
docker stats my_container
```
另外,我们可以使用 `docker logs` 命令来查看容器的日志输出。比如:
```bash
# 查看指定容器的日志输出
docker logs my_container
```
通过上述命令,我们可以轻松地查看容器的日志输出,以及实时监控容器的资源占用情况。
### 4.3 Docker 容器的网络与资源控制
在 Docker 中,我们可以对容器的网络进行配置,并且灵活地控制容器的资源使用情况。这包括设置容器的网络模式、配置容器间的通讯,以及限制容器可以使用的资源。
例如,我们可以使用 `docker network` 命令来管理 Docker 的网络,包括创建新的网络、连接容器到网络等操作。
```bash
# 创建一个自定义的桥接网络
docker network create --driver bridge my_network
```
此外,通过 `docker update` 命令,我们还可以在容器运行时动态地调整容器可以使用的 CPU 和内存等资源限制。
```bash
# 动态调整容器的 CPU 限制
docker update --cpus 2 my_container
```
通过以上操作,我们可以灵活地管理容器的网络和资源控制,以满足不同应用场景下的需求。
在本章中,我们详细地介绍了 Docker 容器的创建与启动、容器的监控与日志管理,以及容器的网络与资源控制。这些内容涵盖了 Docker 容器管理的基本知识和实践操作,有助于读者深入了解和应用 Docker 容器技术。
### 章节五:Docker 与容器编排
容器编排是指通过自动化工具来管理、调度和扩展容器化应用程序的过程,它可以帮助我们更高效地管理大规模的容器部署。Docker 提供了多种容器编排工具,包括 Docker Compose、Docker Swarm 和 Kubernetes,它们分别适用于不同规模和复杂度的容器化应用。
#### 5.1 Docker Compose 的使用与原理
Docker Compose 是一个用来定义和运行多容器 Docker 应用的工具,通过一个单独的 `docker-compose.yml` 文件来配置应用的服务、网络和卷等。以下是一个简单的示例 `docker-compose.yml` 文件:
```yaml
version: '3.7'
services:
web:
image: nginx:latest
ports:
- "8080:80"
api:
image: my-api:latest
ports:
- "5000:5000"
```
通过 `docker-compose up` 命令, Docker 将会启动一个包含 `nginx` 和 `my-api` 两个服务的容器,它们可以通过指定的端口进行访问。
#### 5.2 Docker Swarm 的概念与实践
Docker Swarm 是 Docker 官方提供的容器编排引擎,它可以将多台 Docker 主机聚集在一起,统一管理和调度这些主机上的容器。我们可以通过以下步骤来创建一个 Swarm 集群:
1. 初始化 Swarm 集群:`docker swarm init`
2. 加入节点至 Swarm 集群:`docker swarm join --token <token> <manager-ip:port>`
3. 部署服务至 Swarm 集群:`docker service create --replicas 3 -p 80:80 --name my-web nginx`
通过上述步骤,我们就可以在 Swarm 集群上部署一个包含三个副本的 `nginx` 服务。
#### 5.3 Kubernetes 与 Docker 的集成
Kubernetes 是由 Google 开源的容器集群管理工具,它支持自动部署、扩展和操作应用程序容器。与 Docker 结合使用时,我们可以利用 `kubectl` 命令来管理 Kubernetes 集群中的容器。
以下是一个使用 Kubernetes 部署容器的示例 `deployment.yml` 文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
通过 `kubectl create -f deployment.yml` 命令,我们就可以在 Kubernetes 集群上部署一个包含三个副本的 `nginx` 服务。
通过 Docker Compose、Docker Swarm 和 Kubernetes 等工具,我们可以更加灵活和高效地管理和编排容器化应用,提高应用的可靠性和可扩展性。
### 6. 章节六:Docker 安全与最佳实践
Docker 在实践中需要特别注意安全性,包括基本的安全原则和漏洞管理。同时,在生产环境中需要遵循最佳实践来确保容器的安全运行。此外,集成容器与持续集成/持续部署(CI/CD)也是关键的优化步骤之一。
#### 6.1 Docker 安全的基本原则和漏洞管理
Docker 安全的基本原则包括以下几点:
- 最小化镜像:基于最小化的基础镜像构建自定义镜像,减少潜在的安全风险。
- 更新镜像:定期更新基础镜像和应用程序镜像,及时修复已知漏洞。
- 容器隔离:使用 Docker 提供的命名空间、控制组等特性,实现容器之间和宿主机之间的隔离。
- 安全配置:配置容器的安全参数,如限制资源使用、只暴露必要的端口、使用安全的网络通讯等。
漏洞管理方面,可以定期使用漏洞扫描工具扫描镜像和容器,及时发现和修复漏洞。
```bash
# 使用 Trivy 漏洞扫描工具扫描 Docker 镜像
trivy <image_name>
```
#### 6.2 Docker 在生产环境中的最佳实践
在将 Docker 运用于生产环境时,有一些最佳实践需要遵循:
- 自动化构建和部署:利用 CI/CD 工具,自动化构建和部署 Docker 镜像和容器,确保发布流程的高效和可靠。
- 容器编排工具:使用容器编排工具(如 Kubernetes、Docker Swarm)来管理和编排大规模的容器集群,实现高可用、灵活扩展和自愈能力。
- 日志和监控:建立集中化的日志和监控平台,监控容器运行情况、资源利用率等,并能够快速定位和解决问题。
- 安全审计和访问控制:定期进行安全审计,加强访问控制,确保容器环境的安全性。
#### 6.3 Docker 容器与 CI/CD 的集成与部署优化
在 CI/CD 中集成 Docker 容器技术,可以通过 Docker 镜像来实现持续集成和持续部署的优化。例如,可以将构建好的应用程序打包成 Docker 镜像,然后进行自动化测试和部署。
```yaml
# 示例:使用 Docker 容器进行持续集成和持续部署
stages:
- build
- test
- deploy
build:
stage: build
script:
- docker build -t myapp .
- docker push myapp
test:
stage: test
script:
- docker run myapp /tests
deploy:
stage: deploy
script:
- docker pull myapp
- docker stack deploy -c docker-compose.yml myapp
```
通过集成 Docker 容器技术,可以实现更快速、可靠的持续集成和持续部署流程。
以上是关于 Docker 安全与最佳实践的部分内容,合理的安全策略和最佳实践是确保容器环境安全的关键所在。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Netkiller Architect》专栏提供了计算机网络和软件架构领域的全面学习资源,涵盖了从基础的计算机网络、操作系统、数据库到前沿的容器技术、分布式系统、机器学习等多个方面的知识。专栏以深入浅出的方式,介绍了TCP/IP协议、Linux基础操作、Docker容器技术、Python编程、Git版本控制、Web开发基础、前端与后端技术、数据库优化以及大数据和机器学习等多个主题,内容涵盖了从初学者到高级工程师所需的知识。无论您是刚入门的技术爱好者还是资深的IT从业者,本专栏都能帮助您构建起系统的知识体系,提升技术能力,成为一名卓越的架构师。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
93K缓存策略详解:内存管理与优化,提升性能的秘诀

# 摘要
93K缓存策略作为一种内存管理技术,对提升系统性能具有重要作用。本文首先介绍了93K缓存策略的基础知识和应用原理,阐述了缓存的作用、定义和内存层级结构。随后,文章聚焦于优化93K缓存策略以提升系统性能的实践,包括评估和监控93K缓存效果的工具和方法,以及不同环境下93K缓存的应用案例。最后,本文展望了93K缓存
Masm32与Windows API交互实战:打造个性化的图形界面
# 摘要
本文旨在介绍基于Masm32和Windows API的程序开发,从基础概念到环境搭建,再到程序设计与用户界面定制,最后通过综合案例分析展示了从理论到实践的完整开发过程。文章首先对Masm32环境进行安装和配置,并详细解释了Masm编译器及其他开发工具的使用方法。接着,介绍了Windows API的基础知识,包括API的分类、作用以及调用机制,并对关键的API函数进行了基础讲解。在图形用户界面(GUI)的实现章节中,本文深入
数学模型大揭秘:探索作物种植结构优化的深层原理
# 摘要
本文系统地探讨了作物种植结构优化的概念、理论基础以及优化算法的应用。首先,概述了作物种植结构优化的重要性及其数学模型的分类。接着,详细分析了作物生长模型的数学描述,包括生长速率与环境因素的关系,以及光合作用与生物量积累模型。本文还介绍了优化算法,包括传统算法和智能优化算法,以及它们在作物种植结构优化中的比较与选择。实践案例分析部分通过具体案例展示了如何建立优化模型,求解并分析结果。
S7-1200 1500 SCL指令性能优化:提升程序效率的5大策略

# 摘要
本论文深入探讨了S7-1200/1500系列PLC的SCL编程语言在性能优化方面的应用。首先概述了SCL指令性能优化的重要性,随后分析了影响SCL编程性能的基础因素,包括编程习惯、数据结构选择以及硬件配置的作用。接着,文章详细介绍了针对SCL代码的优化策略,如代码重构、内存管理和访问优化,以及数据结构和并行处理的结构优化。
泛微E9流程自定义功能扩展:满足企业特定需求

# 摘要
本文深入探讨了泛微E9平台的流程自定义功能及其重要性,重点阐述了流程自定义的理论基础、实践操作、功能扩展案例以及未来的发展展望。通过对流程自定义的概念、组件、设计与建模、配置与优化等方面的分析,本文揭示了流程自定义在提高企业工作效率、满足特定行业需求和促进流程自动化方面的重要作用。同时,本文提供了丰富的实践案例,演示了如何在泛微E9平台上配置流程、开发自定义节点、集成外部系统,
KST Ethernet KRL 22中文版:硬件安装全攻略,避免这些常见陷阱

# 摘要
本文详细介绍了KST Ethernet KRL 22中文版硬件的安装和配置流程,涵盖了从硬件概述到系统验证的每一个步骤。文章首先提供了硬件的详细概述,接着深入探讨了安装前的准备工作,包括系统检查、必需工具和配件的准备,以及
约束理论与实践:转化理论知识为实际应用
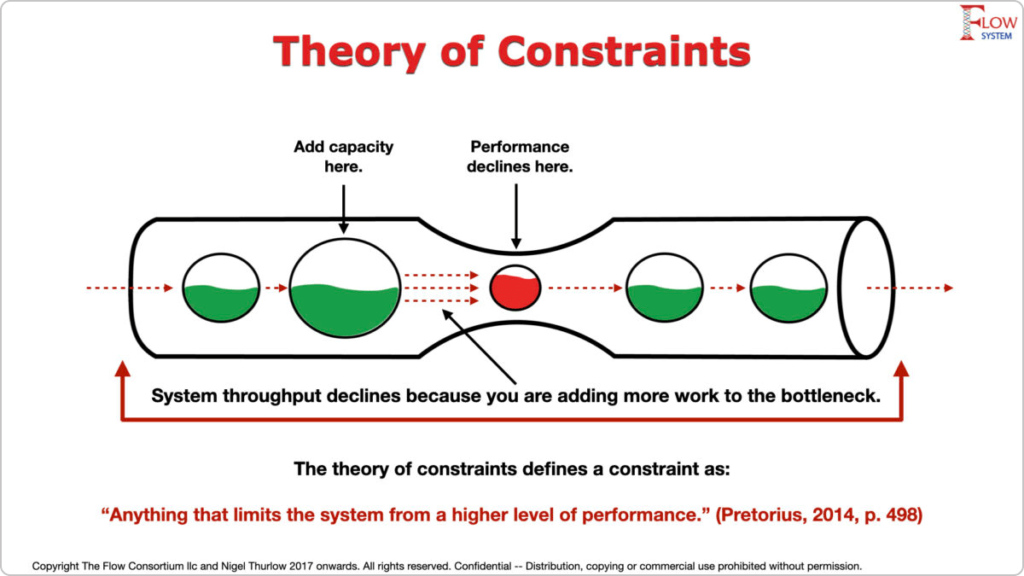
# 摘要
约束理论是一种系统性的管理原则,旨在通过识别和利用系统中的限制因素来提高生产效率和管理决策。本文全面概述了约束理论的基本概念、理论基础和模型构建方法。通过深入分析理论与实践的转化策略,探讨了约束理论在不同行业,如制造业和服务行业中应用的案例,揭示了其在实际操作中的有效性和潜在问题。最后,文章探讨了约束理论的优化与创新,以及其未来的发展趋势,旨在为理论研究和实际应用提供更广阔的
FANUC-0i-MC参数与伺服系统深度互动分析:实现最佳协同效果
# 摘要
本文深入探讨了FANUC 0i-MC数控系统的参数配置及其在伺服系统中的应用。首先介绍了FANUC 0i-MC参数的基本概念和理论基础,阐述了参数如何影响伺服控制和机床的整体性能。随后,文章详述了伺服系统的结构、功能及调试方法,包括参数设定和故障诊断。在第三章中,重点分析了如何通过参数优化提升伺服性能,并讨论了伺服系统与机械结构的匹配问题。最后,本文着重于故障预防和维护策略,提
ABAP流水号安全性分析:避免重复与欺诈的策略
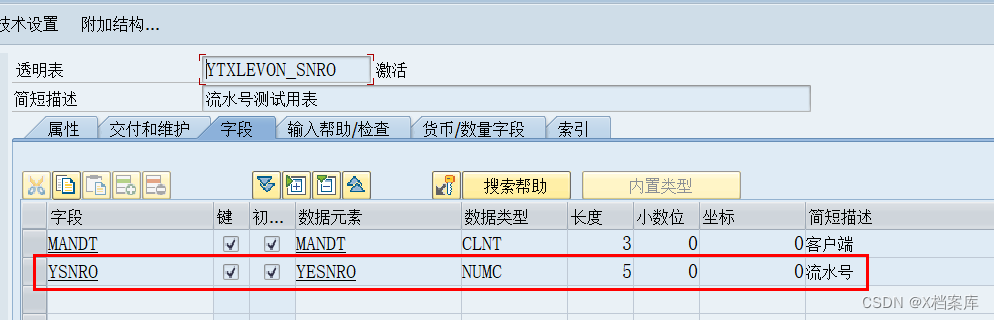
# 摘要
本文全面探讨了ABAP流水号的概述、生成机制、安全性实践技巧以及在ABAP环境下的安全性增强。通过分析流水号生成的基本原理与方法,本文强调了哈希与加密技术在保障流水号安全中的重要性,并详述了安全性考量因素及性能影响。同时,文中提供了避免重复流水号设计的策略、防范欺诈的流水号策略以及流水号安全的监控与分析方法。针对ABAP环境,本文论述了流水号生成的特殊性、集成安全机制的实现,以及安全问题的ABAP代
Windows服务器加密秘籍:避免陷阱,确保TLS 1.2的顺利部署
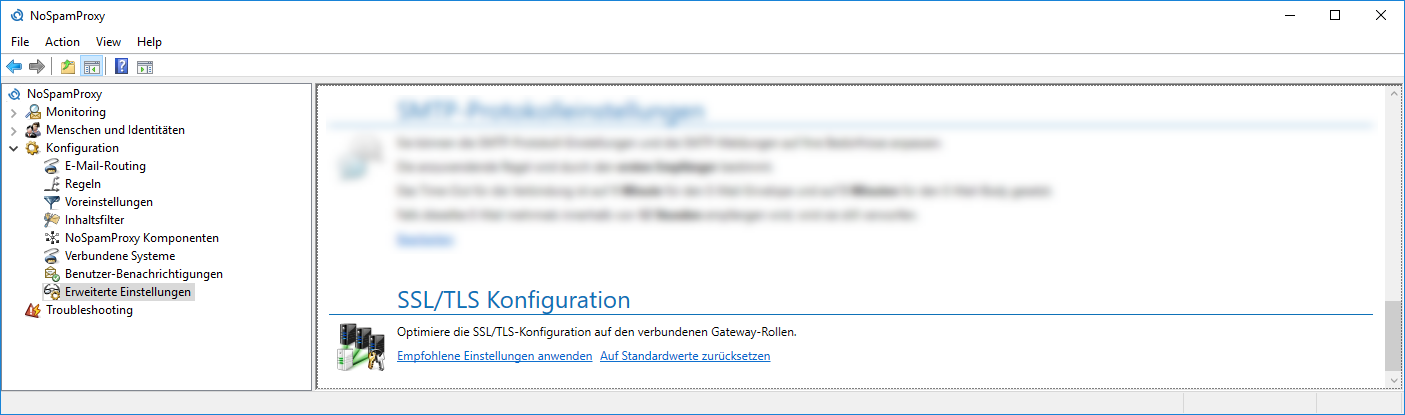
# 摘要
本文提供了在Windows服务器上配置TLS 1.2的全面指南,涵盖了从基本概念到实际部署和管理的各个方面。首先,文章介绍了TLS协议的基础知识和其在加密通信中的作用。其次,详细阐述了TLS版本的演进、加密过程以及重要的安全实践,这
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )