如何使用Spring Data JPA进行数据库操作
发布时间: 2023-12-19 02:45:08 阅读量: 39 订阅数: 23 
# 1. 简介
## 1.1 什么是Spring Data JPA
Spring Data JPA是Spring Data项目的一部分,它提供了对JPA(Java Persistence API)的支持,简化了JPA的数据访问层开发。Spring Data JPA通过使用JPA的标准注解和约定,大大减少了开发者需要编写的代码量,并提供了一种更加方便、快捷的方式来访问数据库。
## 1.2 Spring Data JPA的特点
- 提供了针对JPA的高层抽象,简化数据持久化操作。
- 支持基于方法名的查询方法,大部分查询操作无需编写SQL。
- 集成了Spring的事务管理,可以轻松实现事务操作。
- 支持动态查询、分页查询等高级功能,简化了数据访问操作。
## 1.3 Spring Data JPA与传统JPA的区别
传统的JPA开发需要编写大量的DAO(Data Access Object)接口和实现类,以及对应的实体对象,而Spring Data JPA通过使用接口继承的方式,可以在不编写实现类的情况下直接使用接口定义的查询方法。这样大大减少了冗余代码的编写,提高了开发效率。
此外,Spring Data JPA还提供了更灵活的动态查询功能和集成了Spring的事务管理,使得JPA的使用更加简单、高效。
以上是Spring Data JPA的简介部分,接下来我们将详细介绍如何使用Spring Data JPA进行数据库操作。
# 2. 准备工作
#### 2.1 环境搭建
首先,我们需要搭建Spring Data JPA的开发环境。以下是所需的准备工作:
- Java开发环境
- Maven或Gradle构建工具
- IDE(推荐使用IntelliJ IDEA或Eclipse)
#### 2.2 导入依赖库
在开始之前,我们需要在项目中导入Spring Data JPA的依赖库。可以在项目的pom.xml文件中添加以下依赖:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
```
#### 2.3 配置数据源
在使用Spring Data JPA之前,我们需要配置数据库连接信息。可以在项目的配置文件(application.properties或application.yml)中添加以下配置:
```properties
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
```
这里以MySQL数据库为例,配置了数据库连接的URL、用户名、密码和驱动类。
完成以上准备工作后,我们就可以开始使用Spring Data JPA进行数据库操作了。
# 3. 创建实体类
### 3.1 定义实体类
在使用Spring Data JPA进行数据库操作前,我们需要先定义实体类,实体类对应数据库中的表。以下是一个示例实体类的定义:
```java
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private int age;
// getters and setters
}
```
在上述示例中,我们定义了一个名为`User`的实体类,使用了`@Entity`注解来标识该类是一个实体类,并使用了`@Table`注解来指定对应的数据库表名。实体类中的各个属性使用了`@Column`注解来映射表中的字段。
### 3.2 添加注解
除了上述示例中使用的`@Entity`、`@Table`和`@Column`注解外,Spring Data JPA还提供了许多其他的注解,用于对实体类进行更加精细的配置。以下是一些常用的注解:
- `@Id`:用于标识实体类的主键;
- `@GeneratedValue`:用于指定主键的生成策略;
- `@Temporal`:用于指定日期类型的属性;
- `@Transient`:用于标识一个属性不需要持久化到数据库中。
除了以上注解外,Spring Data JPA还支持使用`@Embeddable`、`@Embedded`、`@MappedSuperclass`等注解来定义复杂的实体类关系。在实际开发中,我们可以根据需要选择合适的注解进行配置。
### 3.3 设置关联关系
在实体类中,我们还可以使用注解来设置实体类之间的关联关系,如一对一关系、一对多关系、多对多关系等。以下是一些常用的关联关系注解:
- `@OneToOne`:一对一关系;
- `@OneToMany`:一对多关系;
- `@ManyToOne`:多对一关系;
- `@ManyToMany`:多对多关系。
使用这些关联关系注解,我们可以在实体类中灵活地配置不同的关联关系,从而构建出复杂的数据库模型。
总结:
在创建实体类时,我们需要定义实体类的属性,并使用注解对属性进行配置,以将实体类与数据库表进行映射。除了基本的注解外,我们还可以使用关联关系注解来设置实体类之间的关系。以上是创建实体类的一些基本步骤和常用注解的介绍。在下一章节中,我们将学习如何创建Repository接口,用于进行数据库的CRUD操作。
# 4. 创建Repository
Spring Data JPA提供了Repository接口来操作数据库,下面将介绍如何创建Repository接口并进行数据库操作。
##### 4.1 什么是Repository
Repository是Spring Data JPA提供的一个接口,用于对数据库进行操作。它提供了一些基本的CRUD方法,同时也支持自定义查询方法。
##### 4.2 创建Repository接口
首先,我们需要创建一个继承自JpaRepository的接口,JpaRepository提供了一些常用的数据库操作方法。比如,save()方法用于保存实体对象、findAll()方法用于查询所有实体对象等。
```java
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
```
在上面的代码中,User是我们要操作的实体类,Long是实体类的主键类型。
##### 4.3 自定义查询方法
除了JpaRepository提供的方法之外,我们还可以自定义查询方法。比如,我们想根据用户名进行查询,可以这样做:
```java
public interface UserRepository extends JpaRepository<User, Long> {
User findByUsername(String username);
}
```
在上面的代码中,我们定义了一个findByUsername()方法,Spring Data JPA会根据方法名自动生成对应的SQL查询语句。这种约定大于配置的方式能够大大减少编码量。
##### 4.4 添加事务支持
在进行数据库操作时,通常需要添加事务支持,以保证数据的一致性和完整性。我们可以在Service层的方法上添加@Transactional注解来开启事务支持。
```java
import org.springframework.transaction.annotation.Transactional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public void saveUser(User user) {
userRepository.save(user);
}
}
```
在上面的代码中,@Transactional注解表示saveUser()方法会在一个事务中运行,如果方法执行过程中出现异常,事务会自动回滚,保证数据的完整性。
这就是使用Spring Data JPA创建Repository接口并进行数据库操作的方法。接下来,我们将进入第五章节,讲解具体的数据库操作。
# 5. 进行数据库操作
在这一章节中,我们将学习如何使用Spring Data JPA进行数据库操作,包括插入数据、查询数据、更新数据、删除数据、分页查询等常用操作。
#### 5.1 插入数据
要插入数据,我们首先需要创建一个实体对象,然后使用Repository的save()方法来保存该对象。
```java
// 创建实体对象
User user = new User();
user.setName("John");
user.setAge(25);
// 调用save()方法保存对象
userRepository.save(user);
```
```python
# 创建实体对象
user = User()
user.name = "John"
user.age = 25
# 调用save()方法保存对象
userRepository.save(user)
```
#### 5.2 查询数据
查询数据是使用Spring Data JPA最常见的操作之一。我们可以使用Repository的findAll()方法来查询所有数据,或者使用findById()方法来根据ID查询数据。
```java
// 查询所有数据
List<User> userList = userRepository.findAll();
// 根据ID查询数据
Optional<User> optionalUser = userRepository.findById(1L);
```
```python
# 查询所有数据
userList = userRepository.findAll()
# 根据ID查询数据
optionalUser = userRepository.findById(1)
```
#### 5.3 更新数据
更新数据也是非常常见的操作,我们可以先查询需要更新的数据,然后修改相应的字段,最后调用save()方法保存修改后的对象。
```java
// 查询需要更新的数据
Optional<User> optionalUser = userRepository.findById(1L);
// 修改字段
User user = optionalUser.get();
user.setName("Mike");
user.setAge(30);
// 保存修改后的对象
userRepository.save(user);
```
```python
# 查询需要更新的数据
optionalUser = userRepository.findById(1)
# 修改字段
user = optionalUser.get()
user.name = "Mike"
user.age = 30
# 保存修改后的对象
userRepository.save(user)
```
#### 5.4 删除数据
删除数据也很简单,我们只需要调用Repository的delete()方法即可。
```java
// 根据ID删除数据
userRepository.deleteById(1L);
```
```python
# 根据ID删除数据
userRepository.deleteById(1)
```
#### 5.5 分页查询
如果数据量很大,我们可能需要进行分页查询,以减轻数据库的压力。Spring Data JPA提供了一些方法来支持分页查询,例如使用Pageable对象进行分页查询。
```java
// 创建Pageable对象
Pageable pageable = PageRequest.of(0, 10);
// 分页查询数据
Page<User> userPage = userRepository.findAll(pageable);
// 获取查询结果
List<User> userList = userPage.getContent();
```
```python
# 创建Pageable对象
pageable = PageRequest.of(0, 10)
# 分页查询数据
userPage = userRepository.findAll(pageable)
# 获取查询结果
userList = userPage.content
```
在本节中,我们学习了如何使用Spring Data JPA进行常见的数据库操作,包括插入数据、查询数据、更新数据、删除数据和分页查询。这些操作可以帮助我们轻松地与数据库进行交互,并提高开发效率。
# 6. 高级应用
#### 6.1 使用Specification进行动态查询
在实际开发中,通常会遇到需要根据用户输入的条件进行动态查询的需求。Spring Data JPA提供了Specification接口,可以方便地实现动态查询。
##### 6.1.1 什么是Specification
Specification是Spring Data JPA提供的一个接口,它定义了一组用于构建查询条件的方法。通过使用Specification,我们可以根据用户输入的条件动态地构建查询语句。
##### 6.1.2 创建Specification
要使用Specification进行动态查询,首先需要创建一个实现了Specification接口的类。下面是一个例子:
```java
public class UserSpecifications {
public static Specification<User> withName(String name) {
return (root, query, criteriaBuilder) -> criteriaBuilder.equal(root.get("name"), name);
}
public static Specification<User> withAge(int age) {
return (root, query, criteriaBuilder) -> criteriaBuilder.greaterThan(root.get("age"), age);
}
// 可根据实际需求继续添加其他规格
}
```
在这个例子中,我们创建了两个Specification:`withName`和`withAge`。它们分别用于根据用户名和年龄进行查询。
##### 6.1.3 使用Specification查询数据
在使用Specification进行查询时,我们可以将多个Specification进行组合,以构建复杂的查询条件。下面是一个例子:
```java
@Autowired
private UserRepository userRepository;
public List<User> findUsersByCondition(String name, int age) {
Specification<User> spec = Specification.where(UserSpecifications.withName(name))
.and(UserSpecifications.withAge(age));
return userRepository.findAll(spec);
}
```
在这个例子中,我们根据用户名和年龄查询满足条件的用户。使用`Specification.where`方法可以将多个Specification进行组合,其中`and`方法表示条件的与操作。
通过使用Specification,我们可以方便地实现动态查询,根据不同条件构建不同的查询语句。这大大提高了查询的灵活性和可复用性。
#### 6.2 使用QueryDSL进行复杂查询
Spring Data JPA提供了对QueryDSL的支持,可以帮助我们更方便地进行复杂的查询操作。
##### 6.2.1 什么是QueryDSL
QueryDSL是一个用于构建类型安全的查询的开源框架。它提供了一种类似于SQL的DSL(领域特定语言)用于构建查询语句,可以更优雅地进行复杂的查询操作。
##### 6.2.2 集成QueryDSL
要使用QueryDSL进行查询,首先需要集成QueryDSL。下面是一个例子:
```xml
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>4.4.0</version>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>4.4.0</version>
<scope>provided</scope>
</dependency>
```
在pom.xml中添加以上依赖,这样就可以使用QueryDSL进行查询了。
##### 6.2.3 创建查询对象
在使用QueryDSL进行查询时,需要创建一个查询对象来构建查询条件。查询对象是通过QueryDSL根据实体类自动生成的,可以方便地进行类型安全的查询。
```java
public class QUser extends EntityPathBase<User> {
public static final QUser user = new QUser("user");
public final NumberPath<Long> id = createNumber("id", Long.class);
public final StringPath name = createString("name");
public final NumberPath<Integer> age = createNumber("age", Integer.class);
public QUser(String variable) {
super(User.class, PathMetadataFactory.forVariable(variable));
}
}
```
以上是使用QueryDSL自动生成的QUser查询对象的示例。根据实际实体类来生成相应的查询对象。
##### 6.2.4 使用QueryDSL查询数据
使用QueryDSL进行查询时,可以使用查询对象来构建查询语句。下面是一个例子:
```java
@Autowired
private JPAQueryFactory queryFactory;
public List<User> findUsersByCondition(String name, int age) {
return queryFactory.selectFrom(QUser.user)
.where(QUser.user.name.eq(name)
.and(QUser.user.age.gt(age)))
.fetch();
}
```
在这个例子中,使用`queryFactory`来创建一个查询,通过`selectFrom`方法指定查询的实体类,然后使用`where`方法构建查询条件。
使用QueryDSL可以更方便地进行复杂的查询操作,并且由于它是类型安全的,可以在编译时捕获一些错误,提高开发效率。
#### 6.3 使用Spring Data JPA与其他框架集成
Spring Data JPA可以与其他框架进行集成,以更好地满足实际开发需求。下面是一些常见的集成方式:
##### 6.3.1 与Spring MVC集成
Spring Data JPA可以与Spring MVC框架集成,方便地进行数据库操作和请求处理。通过集成Spring MVC,可以构建一个完整的Web应用程序。
##### 6.3.2 与Spring Boot集成
Spring Data JPA与Spring Boot集成非常紧密,可以方便地进行快速开发和部署。使用Spring Boot可以减少配置,提高开发效率。
##### 6.3.3 与Spring Security集成
Spring Data JPA可以与Spring Security集成,实现用户认证和授权功能。通过集成Spring Security,可以保护数据库数据的安全性。
以上是几种常见的Spring Data JPA与其他框架集成的方式,它们可以互相协作,提供更强大的功能和更好的开发体验。
### 结束语
本文介绍了Spring Data JPA的基本使用和高级应用,包括使用Specification进行动态查询、使用QueryDSL进行复杂查询以及与其他框架的集成。希望读者通过本文的学习,能够掌握Spring Data JPA的使用,并且能够在实际项目中灵活应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《SpringBoot JPA开发实践》是一本学习SpringBoot框架和JPA持久化技术的实践指南。从入门到进阶,本专栏详细介绍了SpringBoot和JPA的基本概念和使用方法,包括数据库操作、实体映射和关联关系、查询方法、分页和排序查询、原生SQL查询、自定义查询、持久化上下文和事务管理、缓存处理、验证和数据校验、错误处理和异常处理、集成其他数据库、并发控制、延迟加载和懒加载、多数据源配置、审计和日志记录、性能优化、事件监听和触发器以及多租户架构实现等。无论你是初学者还是有一定经验的开发者,都能从本专栏中获得实用的开发技巧和最佳实践,帮助你在SpringBoot和JPA开发中取得更好的效果。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ZW10I8性能提升秘籍:专家级系统升级指南,让效率飞起来!
# 摘要
ZW10I8系统作为当前信息技术领域的关键组成部分,面临着性能提升与优化的挑战。本文首先对ZW10I8的系统架构进行了全面解析,涵盖硬件和软件层面的性能优化点,以及性能瓶颈的诊断方法。文章深入探讨了系统级优化策略,资源管理,以及应用级性能调优的实践,强调了合理配置资源和使用负载均衡技术的重要性。此外,本文还分析了ZW10I8系统升级与扩展的
【ArcGIS制图新手速成】:7步搞定标准分幅图制作

# 摘要
本文详细介绍了使用ArcGIS软件进行制图的全过程,从基础的ArcGIS环境搭建开始,逐步深入到数据准备、地图编辑、分幅图制作以及高级应用技巧等各个方面。通过对软件安装、界面操作、项目管理、数据处理及地图制作等关键步骤的系统性阐述,本文旨在帮助读者掌握ArcGIS在地理信息制图和空间数据分析中的应用。文章还提供了实践操作中的问题解决方案和成果展示技
QNX Hypervisor故障排查手册:常见问题一网打尽
# 摘要
本文首先介绍了QNX Hypervisor的基础知识,为理解其故障排查奠定理论基础。接着,详细阐述了故障排查的理论与方法论,包括基本原理、常规步骤、有效技巧,以及日志分析的重要性与方法。在QNX Hypervisor故障排查实践中,本文深入探讨了启动、系统性能及安全性方面的故障排查方法,并在高级故障排查技术章节中,着重讨论了内存泄漏、实时性问题和网络故障的分析与应对策略。第五章通过案例研究与实战演练,提供了从具体故障案例中学习的排查策略和模拟练习的方法。最后,第六章提出了故障预防与系统维护的最佳实践,包括常规维护、系统升级和扩展的策略,确保系统的稳定运行和性能优化。
# 关键字
Q
SC-LDPC码构造技术深度解析:揭秘算法与高效实现

# 摘要
本文全面介绍了SC-LDPC码的构造技术、理论基础、编码和解码算法及其在通信系统中的应用前景。首先,概述了纠错码的原理和SC-LDPC码的发展历程。随后,深入探讨了SC-LDPC码的数学模型、性能特点及不同构造算法的原理与优化策略。在编码实现方面,本文分析了编码原理、硬件实现与软件实现的考量。在解码算法与实践中
VisualDSP++与实时系统:掌握准时执行任务的终极技巧
# 摘要
本文系统地介绍了VisualDSP++开发环境及其在实时系统中的应用。首先对VisualDSP++及其在实时系统中的基础概念进行概述。然后,详细探讨了如何构建VisualDSP++开发环境,包括环境安装配置、界面布局和实时任务设计原则。接着,文章深入讨论了VisualDSP++中的实时系
绿色计算关键:高速串行接口功耗管理新技术

# 摘要
随着技术的不断进步,绿色计算的兴起正推动着对能源效率的重视。本文首先介绍了绿色计算的概念及其面临的挑战,然后转向高速串行接口的基础知识,包括串行通信技术的发展和标准,以及高速串行接口的工作原理和对数据完整性的要求。第三章探讨了高速串行接口的功耗问题,包括功耗管理的重要性、功耗测量与分析方法以及功耗优化技术。第四章重点介绍了功耗管理的新技术及其在高速串行接口中
MK9019数据管理策略:打造高效存储与安全备份的最佳实践
# 摘要
随着信息技术的飞速发展,数据管理策略的重要性日益凸显。本文系统地阐述了数据管理的基础知识、高效存储技术、数据安全备份、管理自动化与智能化的策略,并通过MK9019案例深入分析了数据管理策略的具体实施过程和成功经验。文章详细探讨了存储介质与架构、数据压缩与去重、分层存储、智能数据管理以及自动化工具的应用,强调了备份策略制定、数据安全和智能分析技术
【电脑自动关机脚本编写全攻略】:从初学者到高手的进阶之路
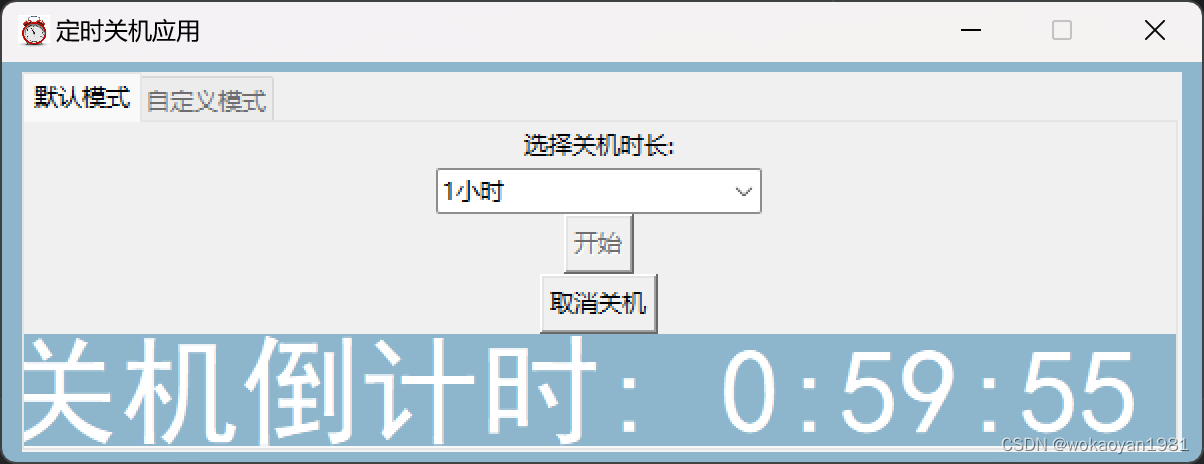
# 摘要
本文系统介绍了电脑自动关机脚本的全面知识,从理论基础到高级应用,再到实际案例的应用实践,深入探讨了自动关机脚本的原理、关键技术及命令、系统兼容性与安全性考量。在实际操作方面,本文详细指导了如何创建基础和高级自动关机脚本,涵盖了脚本编写、调试、维护与优化的各个方面。最后,通过企业级和家庭办公环境中的应用案例,阐述了自动关机脚本的实际部署和用户教育,展望了自动化技术在系统管理中的未来趋势,包
深入CU240BE2硬件特性:进阶调试手册教程

# 摘要
CU240BE2作为一款先进的硬件设备,拥有复杂的配置和管理需求。本文旨在为用户提供全面的CU240BE2硬件概述及基本配置指南,深入解释其参数设置的细节和高级调整技巧,
BRIGMANUAL性能调优实战:监控指标与优化策略,让你领先一步
# 摘要
本文全面介绍了BRIGMANUAL系统的性能监控与优化方法。首先,概览了性能监控的基础知识,包括关键性能指标(KPI)的识别与定义,以及性能监控工具和技术的选择和开发。接着,深入探讨了系统级、应用和网络性能的优化策略,强调了硬件、软件、架构调整及资源管理的重要性。文章进一步阐述了自动化性能调优的流程,包括测试自动化、持续集成和案例研究分析。此外,探讨了在云计算、大
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )