Oracle数据库导入最佳实践:提升效率,保障安全
发布时间: 2024-07-26 18:09:02 阅读量: 31 订阅数: 30 

# 1. Oracle数据库导入概述
Oracle数据库导入是将数据从外部源(如文件、其他数据库或备份)复制到目标数据库的过程。它对于数据迁移、恢复和维护至关重要。
导入过程涉及从源系统提取数据,将其转换为Oracle数据库可以理解的格式,然后将其加载到目标表中。Oracle提供多种导入方法,每种方法都有其优点和缺点。
本章将概述Oracle数据库导入的总体概念,包括导入方法、优化策略和安全保障措施。
# 2. 导入方法及优化策略
### 2.1 数据泵导入
#### 2.1.1 数据泵导入原理
数据泵导入是一种基于元数据的导入方法,它将源数据库中的数据和元数据导出为一个或多个数据泵文件,然后将这些文件导入到目标数据库中。数据泵导入过程包括以下步骤:
1. **导出数据和元数据:**使用 `expdp` 命令将源数据库中的数据和元数据导出为数据泵文件。
2. **导入数据和元数据:**使用 `impdp` 命令将数据泵文件导入到目标数据库中。
#### 2.1.2 导入参数优化
| 参数 | 描述 | 优化建议 |
|---|---|---|
| **PARALLEL** | 指定导入并行度 | 根据源数据库和目标数据库的资源情况设置合适的并行度 |
| **BUFFER** | 指定导入缓冲区大小 | 根据源数据库和目标数据库的内存情况设置合适的缓冲区大小 |
| **LOGFILE** | 指定导入日志文件 | 指定一个足够大的日志文件,以记录导入过程中的错误和警告信息 |
| **SKIP_UNUSABLE_INDEXES** | 忽略不可用索引 | 在导入过程中忽略不可用索引,提高导入速度 |
| **COMMIT** | 指定提交频率 | 根据导入数据量和目标数据库的性能设置合适的提交频率 |
**代码示例:**
```bash
impdp user/password@target_db directory=dpump_dir dumpfile=export.dmp logfile=import.log parallel=4 buffer=1024M skip_unusable_indexes=y commit=1000
```
**代码逻辑解读:**
* `user/password@target_db`:目标数据库的用户名和密码。
* `directory=dpump_dir`:数据泵文件所在的目录。
* `dumpfile=export.dmp`:要导入的数据泵文件。
* `logfile=import.log`:导入日志文件。
* `parallel=4`:导入并行度设置为 4。
* `buffer=1024M`:导入缓冲区大小设置为 1024MB。
* `skip_unusable_indexes=y`:忽略不可用索引。
* `commit=1000`:提交频率设置为每 1000 行提交一次。
### 2.2 SQL*Loader导入
#### 2.2.1 SQL*Loader导入原理
SQL*Loader是一种基于文件的导入方法,它将源数据文件中的数据直接加载到目标数据库表中。SQL*Loader导入过程包括以下步骤:
1. **准备数据文件:**将源数据导出为一个或多个数据文件,并使用 SQL*Loader 控制文件定义数据文件的格式和加载规则。
2. **加载数据:**使用 `sqlldr` 命令将数据文件中的数据加载到目标数据库表中。
#### 2.2.2 导入性能优化
| 参数 | 描述 | 优化建议 |
|---|---|---|
| **DIRECT** | 使用直接路径加载 | 启用直接路径加载,绕过 redo 日志,提高导入速度 |
| **PARALLEL** | 指定加载并行度 | 根据源数据库和目标数据库的资源情况设置合适的并行度 |
| **BUFFER** | 指
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Oracle数据库导入:从入门到精通》专栏是一份全面的指南,涵盖了Oracle数据库导入的各个方面。从基础概念到高级技术,专栏深入探讨了导入流程、常见问题、性能优化、数据完整性保护和故障排除。
专栏包括一系列标题,为读者提供逐步指导,包括:
* 一步步掌握导入全流程
* 轻松解决导入常见问题
* 5个优化技巧,让导入飞起来
* 导入前后必做的检查
* SQL*Loader使用指南
* Data Pump实战指南
* Direct Path Load终极指南
* 故障排除全攻略
* 性能分析与优化
* 修复数据不一致策略
* 表锁管理和索引维护
* 约束检查和触发器处理
* 事务控制和日志分析
* 异常处理和最佳实践
通过深入的解释、示例和最佳实践,该专栏旨在帮助读者掌握Oracle数据库导入,提高效率,并确保数据完整性和业务稳定性。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python版本与性能优化:选择合适版本的5个关键因素

# 1. Python版本选择的重要性
Python是不断发展的编程语言,每个新版本都会带来改进和新特性。选择合适的Python版本至关重要,因为不同的项目对语言特性的需求差异较大,错误的版本选择可能会导致不必要的兼容性问题、性能瓶颈甚至项目失败。本章将深入探讨Python版本选择的重要性,为读者提供选择和评估Python版本的决策依据。
Python的版本更新速度和特性变化需要开发者们保持敏锐的洞
【递归与迭代决策指南】:如何在Python中选择正确的循环类型
# 1. 递归与迭代概念解析
## 1.1 基本定义与区别
递归和迭代是算法设计中常见的两种方法,用于解决可以分解为更小、更相似问题的计算任务。**递归**是一种自引用的方法,通过函数调用自身来解决问题,它将问题简化为规模更小的子问题。而**迭代**则是通过重复应用一系列操作来达到解决问题的目的,通常使用循环结构实现。
## 1.2 应用场景
递归算法在需要进行多级逻辑处理时特别有用,例如树的遍历和分治算法。迭代则在数据集合的处理中更为常见,如排序算法和简单的计数任务。理解这两种方法的区别对于选择最合适的算法至关重要,尤其是在关注性能和资源消耗时。
## 1.3 逻辑结构对比
递归
Python函数性能优化:时间与空间复杂度权衡,专家级代码调优
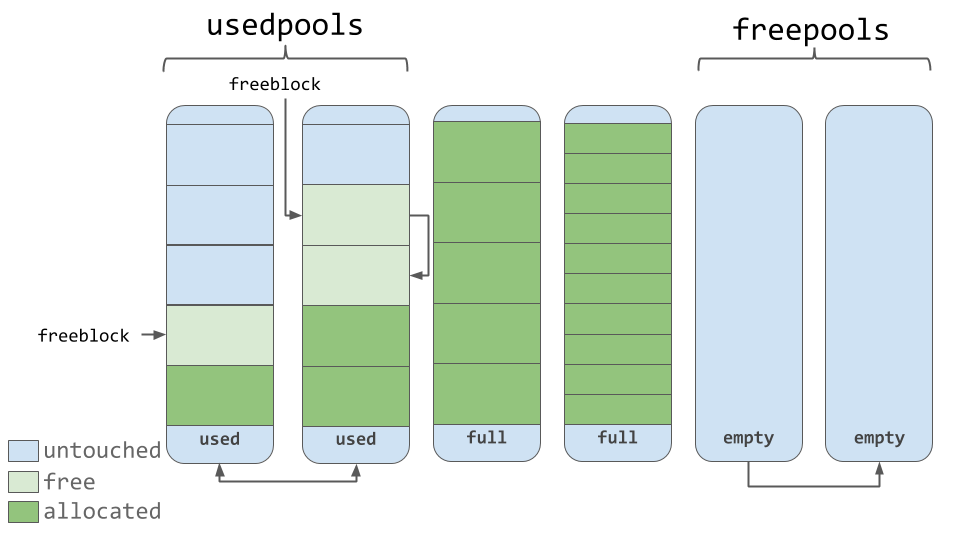
# 1. Python函数性能优化概述
Python是一种解释型的高级编程语言,以其简洁的语法和强大的标准库而闻名。然而,随着应用场景的复杂度增加,性能优化成为了软件开发中的一个重要环节。函数是Python程序的基本执行单元,因此,函数性能优化是提高整体代码运行效率的关键。
## 1.1 为什么要优化Python函数
在大多数情况下,Python的直观和易用性足以满足日常开发
【Python项目管理工具大全】:使用Pipenv和Poetry优化依赖管理

# 1. Python依赖管理的挑战与需求
Python作为一门广泛使用的编程语言,其包管理的便捷性一直是吸引开发者的亮点之一。然而,在依赖管理方面,开发者们面临着各种挑战:从包版本冲突到环境配置复杂性,再到生产环境的精确复现问题。随着项目的增长,这些挑战更是凸显。为了解决这些问题,需求便应运而生——需要一种能够解决版本
Python装饰模式实现:类设计中的可插拔功能扩展指南
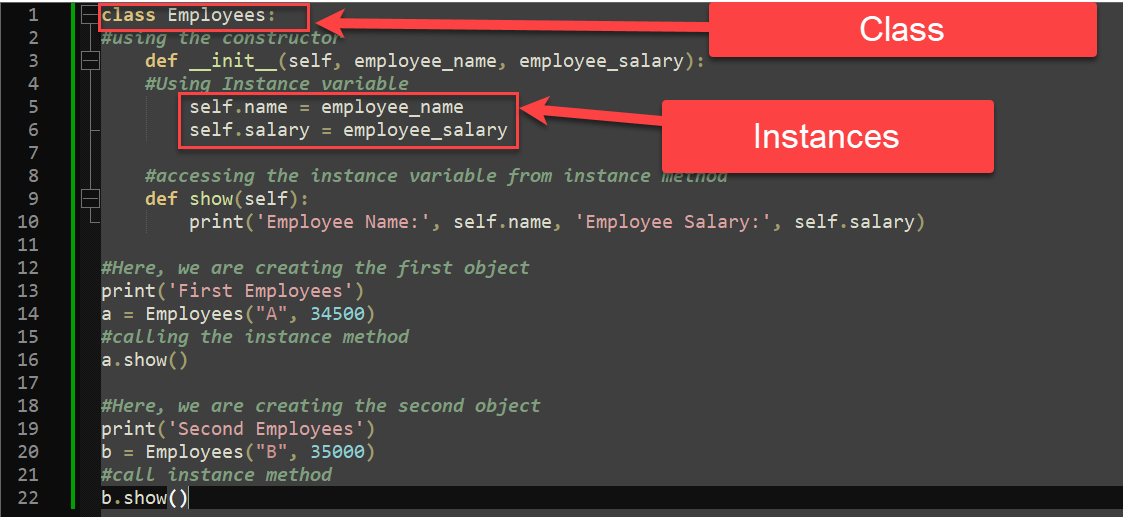
# 1. Python装饰模式概述
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许动态地添加或修改对象的行为。在Python中,由于其灵活性和动态语言特性,装饰模式得到了广泛的应用。装饰模式通过使用“装饰者”(Decorator)来包裹真实的对象,以此来为原始对象添加新的功能或改变其行为,而不需要修改原始对象的代码。本章将简要介绍Python中装饰模式的概念及其重要性,为理解后
Python pip性能提升之道
# 1. Python pip工具概述
Python开发者几乎每天都会与pip打交道,它是Python包的安装和管理工具,使得安装第三方库变得像“pip install 包名”一样简单。本章将带你进入pip的世界,从其功能特性到安装方法,再到对常见问题的解答,我们一步步深入了解这一Python生态系统中不可或缺的工具。
首先,pip是一个全称“Pip Installs Pac
Python print语句装饰器魔法:代码复用与增强的终极指南

# 1. Python print语句基础
## 1.1 print函数的基本用法
Python中的`print`函数是最基本的输出工具,几乎所有程序员都曾频繁地使用它来查看变量值或调试程序。以下是一个简单的例子来说明`print`的基本用法:
```python
print("Hello, World!")
```
这个简单的语句会输出字符串到标准输出,即你的控制台或终端。`prin
Python数组在科学计算中的高级技巧:专家分享

# 1. Python数组基础及其在科学计算中的角色
数据是科学研究和工程应用中的核心要素,而数组作为处理大量数据的主要工具,在Python科学计算中占据着举足轻重的地位。在本章中,我们将从Python基础出发,逐步介绍数组的概念、类型,以及在科学计算中扮演的重要角色。
## 1.1 Python数组的基本概念
数组是同类型元素的有序集合,相较于Python的列表,数组在内存中连续存储,允
【Python集合异常处理攻略】:集合在错误控制中的有效策略

# 1. Python集合的基础知识
Python集合是一种无序的、不重复的数据结构,提供了丰富的操作用于处理数据集合。集合(set)与列表(list)、元组(tuple)、字典(dict)一样,是Python中的内置数据类型之一。它擅长于去除重复元素并进行成员关系测试,是进行集合操作和数学集合运算的理想选择。
集合的基础操作包括创建集合、添加元素、删除元素、成员测试和集合之间的运
【Python字典的并发控制】:确保数据一致性的锁机制,专家级别的并发解决方案

# 1. Python字典并发控制基础
在本章节中,我们将探索Python字典并发控制的基础知识,这是在多线程环境中处理共享数据时必须掌握的重要概念。我们将从了解为什么需要并发控制开始,然后逐步深入到Python字典操作的线程安全问题,最后介绍一些基本的并发控制机制。
## 1.1 并发控制的重要性
在多线程程序设计中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )