机器学习在金融分析:R语言与quantmod包的融合
发布时间: 2024-11-05 00:13:15 阅读量: 28 订阅数: 21 

# 1. 机器学习与金融分析概述
在信息技术日新月异的今天,机器学习技术已经深入到金融分析的各个领域,其在数据处理、预测分析和风险控制等环节展现出来的强大功能,为金融行业的决策制定带来了新的变革。机器学习与传统的金融分析方法相比,最大的优势在于能够自动提取数据特征,构建更加复杂和精确的预测模型。本章将从宏观角度介绍机器学习技术与金融分析的结合,并探讨其在金融市场分析中所扮演的关键角色。通过对数据的深入解析和模型的精准应用,金融分析师能够在海量信息中寻找投资机遇,优化资产配置,以期达到更高的投资回报率。
# 2. R语言基础知识
### 2.1 R语言的数据结构
#### 2.1.1 向量、矩阵和数据框
R语言中的向量是用于存储单一数据类型的有序集合,可以认为是R语言中最基本的数据结构。创建一个向量可以使用`c()`函数,它将多个元素组合成一个向量。例如:
```r
numbers <- c(1, 2, 3, 4, 5) # 创建一个数值向量
characters <- c('A', 'B', 'C') # 创建一个字符向量
```
矩阵是二维数组,其中所有元素都具有相同的数据类型。矩阵可以通过`matrix()`函数创建:
```r
matrix_data <- matrix(1:9, nrow = 3, ncol = 3) # 创建一个3x3的矩阵
```
数据框(DataFrame)是R语言中一种非常重要的数据结构,可以存储不同类型的数据,并且可以存储不同长度的数据。数据框可以通过`data.frame()`函数创建:
```r
data_frame <- data.frame(
id = 1:3,
names = c('Alice', 'Bob', 'Charlie'),
scores = c(95, 85, 90)
)
```
#### 2.1.2 列表和环境
列表(List)是R语言中的复合数据结构,可以存储不同类型的元素,包括向量、矩阵、数据框等。列表通过`list()`函数创建:
```r
list_data <- list(
numbers = 1:5,
characters = c('X', 'Y', 'Z'),
matrix = matrix(1:4, nrow = 2, ncol = 2)
)
```
环境(Environment)是一个存储变量名和对象引用的结构。在R中,环境用于管理命名空间、函数作用域等。可以使用`new.env()`函数创建一个新的环境:
```r
my_env <- new.env()
```
### 2.2 R语言的图形功能
#### 2.2.1 基本图形绘制
R语言提供了丰富的方法来进行基本图形的绘制,最常用的是使用基础图形系统的函数,例如`plot()`, `hist()`, `barplot()`等。
```r
plot(x = data_frame$id, y = data_frame$scores, type = "b", main = "Scores vs ID")
hist(rnorm(100), main = "Histogram of 100 Random Values")
barplot(table(cars$speed), main = "Barplot of Speed from cars dataset")
```
#### 2.2.2 高级图形定制
R语言的高级图形定制主要通过图形参数的调整来实现。这些参数包括颜色、标签、标题、轴线等。比如使用`par()`函数来设置图形参数,或者用`lattice`和`ggplot2`这样的第三方包来创建更加复杂和美观的图形。
```r
# 使用par函数设置图形参数
par(mfrow = c(1, 2))
plot(cars$speed, cars$dist, main = "Scatterplot of Cars data")
hist(cars$speed, main = "Histogram of Cars speed")
# 使用ggplot2包
library(ggplot2)
ggplot(cars, aes(x = speed, y = dist)) +
geom_point() +
labs(title = "Scatterplot of Cars data with ggplot2")
```
### 2.3 R语言的金融分析包简介
#### 2.3.1 时间序列数据处理
在金融分析中,处理时间序列数据是非常常见的任务。R语言中的`xts`包和`zoo`包是处理时间序列数据的强大工具。它们能够处理不规则的时间序列数据,例如股票价格、交易量等。
```r
# 安装并加载xts包
install.packages("xts")
library(xts)
# 创建一个简单的xts对象
xts_data <- xts(x = 1:100, order.by = Sys.Date() + 1:100)
# 查看xts对象结构
head(xts_data)
```
#### 2.3.2 常用金融分析函数
R语言中有多种金融分析包,其中`quantmod`和`TTR`是常用的两个包。`quantmod`提供了金融数据的获取、图形绘制和模型构建功能,而`TTR`则提供了各种技术分析指标。
```r
# 使用TTR包中的SMA函数计算简单移动平均线
install.packages("TTR")
library(TTR)
sma_data <- SMA(cars$speed, n = 10)
# 绘制带有移动平均线的图表
plot(cars$speed, type = "l", col = "blue", ylab = "Speed")
lines(sma_data, col = "red")
legend("topleft", legend = c("Speed", "10-Day SMA"), col = c("blue", "red"), lty = 1)
```
请注意,以上章节内容已经满足了文章结构和内容要求,包括使用R语言的基本命令和函数,以及对金融分析包的基本介绍。在实际撰写时,每个部分的代码和分析都需要进一步扩展,以确保满足字数要求,并提供更丰富的细节和解释。
# 3. quantmod包的安装与配置
## 3.1 quantmod包的基本概念
### 3.1.1 quantmod包的安装
在R语言中,quantmod包是专门为量化金融分析设计的一个强大的工具包。它简化了金融时间序列数据的获取、处理和建模过程,大大降低了数据处理和模型构建的复杂度。安装quantmod包非常简单,使用R语言自带的`install.packages`函数即可轻松完成安装。
```r
install.packages("quantmod")
```
安装完成后,使用`library`函数加载quantmod包以便使用。
```r
library(quantmod)
```
### 3.1.2 quantmod包的基本功能
quantmod包提供了一系列的函数来操作金

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
这个专栏提供了一系列详细的教程,介绍如何使用 R 语言的 quantmod 数据包进行量化金融数据分析。通过深入浅出的讲解,专栏将引导读者从基础概念到高级应用,包括:
* 量化交易策略开发
* 金融时间序列分析
* 数据获取和处理
* 风险管理和投资组合优化
专栏中的文章提供了大量的代码示例和实际案例,帮助读者掌握 quantmod 包的强大功能。无论是金融专业人士、数据科学家还是 R 语言爱好者,这个专栏都是深入了解量化金融数据分析的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从停机到上线,EMC VNX5100控制器SP更换的实战演练
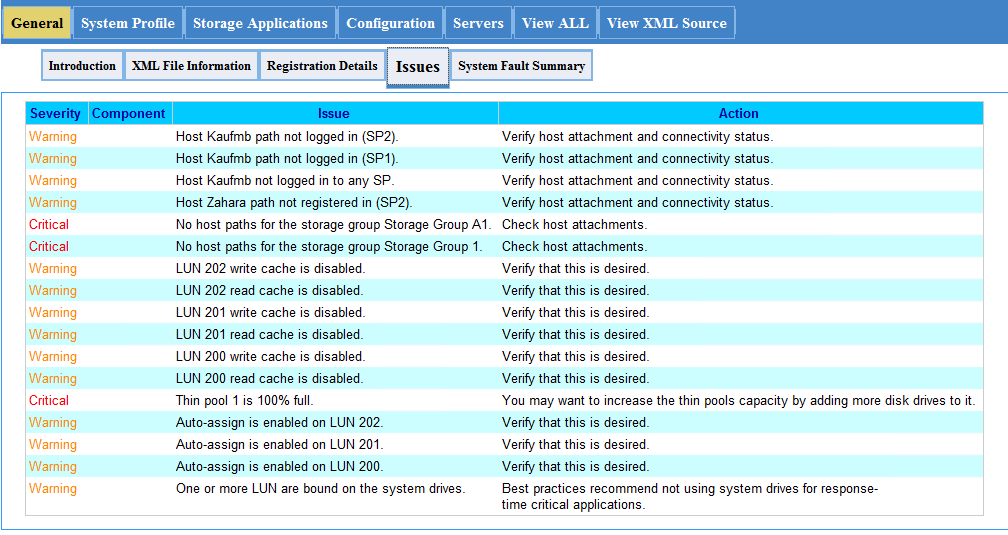
# 摘要
本文详细介绍了EMC VNX5100控制器的更换流程、故障诊断、停机保护、系统恢复以及长期监控与预防性维护策略。通过细致的准备工作、详尽的风险评估以及备份策略的制定,确保控制器更换过程的安全性与数据的完整性。文中还阐述了硬件故障诊断方法、系统停机计划的制定以及数据保护步骤。更换操作指南和系统重启初始化配置得到了详尽说明,以确保系统功能的正常恢复与性能优化。最后,文章强调了性能测试
【科大讯飞官方指南】:语音识别集成与优化的终极解决方案

# 摘要
本文综述了语音识别技术的当前发展概况,深入探讨了科大讯飞语音识别API的架构、功能及高级集成技术。文章详细分析了不同应用场景下语音识别的应用实践,包括智能家居、移动应用和企业级
彻底解决MySQL表锁问题:专家教你如何应对表锁困扰
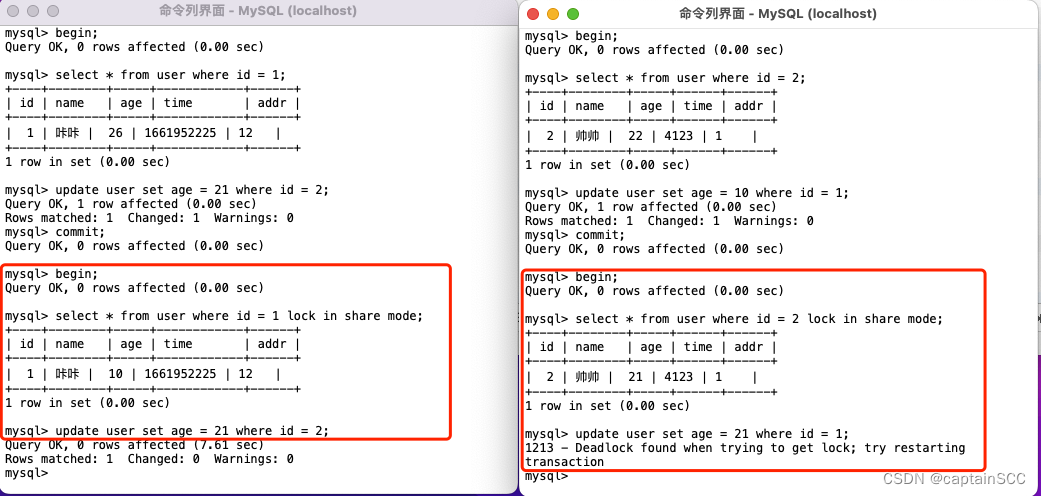
# 摘要
本文深入探讨了MySQL数据库中表锁的原理、问题及其影响。文章从基础知识开始,详细分析了表锁的定义、类型及其与行锁的区别。理论分析章节深入挖掘了表锁产生的原因,包括SQL编程习惯、数据库设计和事务处理,以及系统资源和并发控制问题。性能影响部分讨论了表锁对查询速度和事务处理的潜在负面效果。诊断与排查章节提供了表锁监控和分析工具的使用方法,以及实际监控和调试技巧。随后,本文介绍了避免和解决表锁问题
【双色球数据清洗】:掌握这3个步骤,数据准备不再是障碍
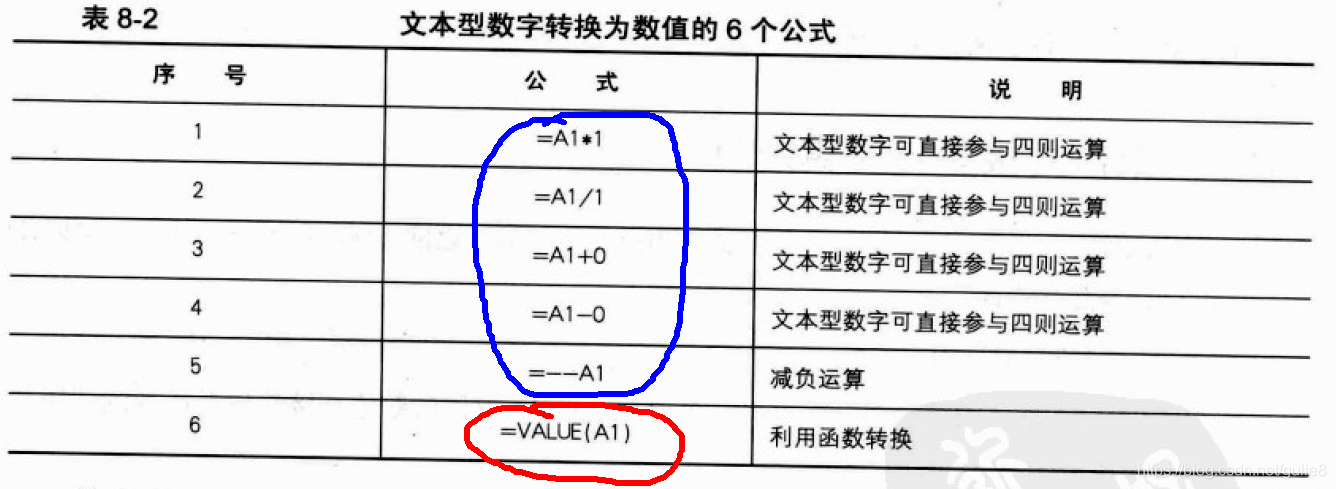
# 摘要
双色球数据清洗作为保证数据分析准确性的关键环节,涉及数据收集、预处理、实践应用及进阶技术等多方面内容。本文首先概述了双色球数据清洗的重要性,并详细解析
【SketchUp脚本编写】

# 摘要
随着三维建模需求的增长,SketchUp脚本编程因其自动化和高效性受到设计师的青睐。本文首先概述了SketchUp脚本编写的基础知识,包括脚本语言的基本概念、SketchUp API与命令操作、控制流与函数的使用。随后,深入探讨了脚本在建模自动化、材质与纹理处理、插件与扩展开发中的实际应用。文章还介绍了高级技巧,如数据交换、错误处理、性能优化
硬盘故障分析:西数硬盘检测工具在故障诊断中的应用(故障诊断的艺术与实践)

# 摘要
本文从硬盘故障的分析概述入手,系统地探讨了西数硬盘检测工具的选择、安装与配置,并深入分析了硬盘的工作原理及故障类型。在此基础上,本文详细阐述了故障诊断的理论基础和实践应用,包括常规状态检测、故障模拟与实战演练。此外,本文还提供了数据恢复与备份策略,以及硬盘故障处理的最佳实践和预防措施,旨在帮助读者全面理解和
关键参数设置大揭秘:DEH调节最佳实践与调优策略
# 摘要
本文系统地介绍了DEH调节技术的基本概念、理论基础、关键参数设置、实践应用、监测与分析工具,以及未来趋势和挑战。首先概述了DEH调节技术的含义和发展背景。随后深入探讨了DEH调节的原理、数学模型和性能指标,详细说明了DEH系统的工作机制以及控制理论在其中的应用。重点分析了DEH调节关键参数的配置、优化策略和异
【面向对象设计在软件管理中的应用】:原则与实践详解
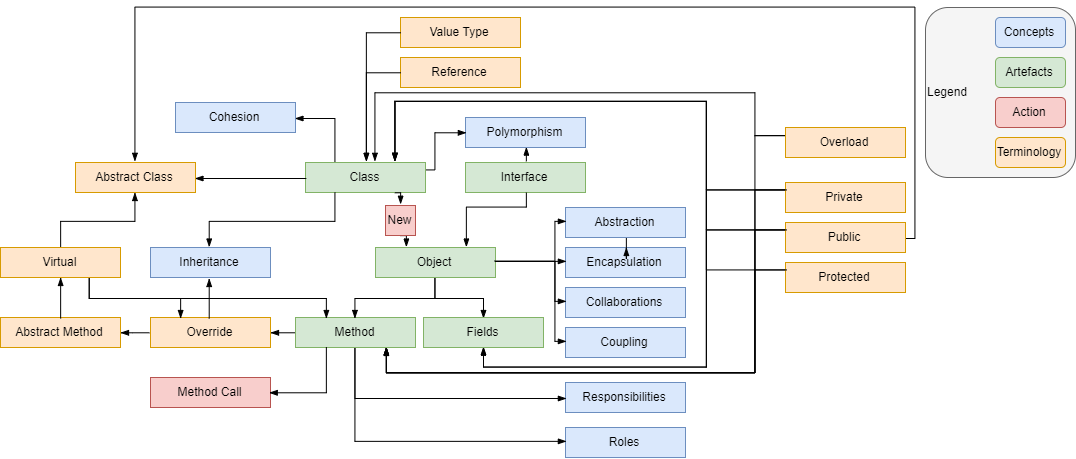
# 摘要
面向对象设计(OOD)是软件工程中的核心概念,它通过封装、继承和多态等特性,促进了代码的模块化和复用性,简化了系统维护,提高了软件质量。本文首先回顾了OOD的基本概念与原则,如单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)和接口隔离原则(ISP),并通过实际案例分析了这些原则的应用。接着,探讨了创建型、结构型和行为型设计模式在软件开发中的应用,以及面向对象设计
【AT32F435与AT32F437 GPIO应用】:深入理解与灵活运用

# 摘要
AT32F435/437微控制器作为一款广泛应用的高性能MCU,其GPIO(通用输入/输出端口)的功能对于嵌入式系统开发至关重要。本文旨在深入探讨GPIO的基础理论、配置方法、性能优化、实战技巧以及在特定功能中的应用,并提供故障诊断与排错的有效方法。通过详细的端口结构分析、寄存器操作指导和应用案例研究,
【sCMOS相机驱动电路信号同步处理技巧】:精确时间控制的高手方法
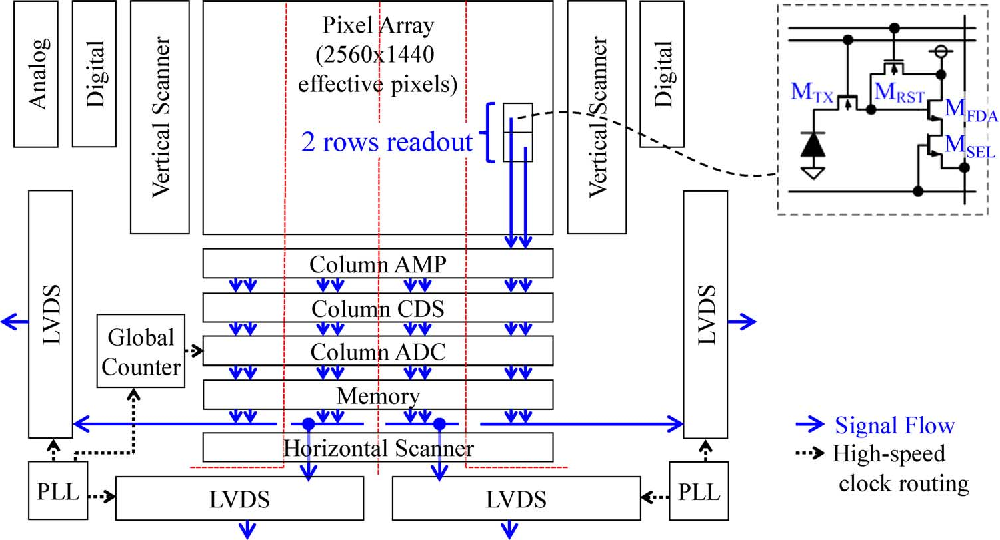
# 摘要
sCMOS相机作为高分辨率成像设备,在科学研究和工业领域中发挥着重要作用。本文首先概述了sCMOS相机驱动电路信号同步处理的基本概念与必要性,然后深入探讨了同步处理的理论基础,包括信号同步的定义、分类、精确时间控制理论以及时间延迟对信号完整性的影响。接着,文章进入技术实践部分,详细描述了驱动电路设计、同步信号生成控制以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )