:Prim算法实战:案例分析,应用场景大揭秘
发布时间: 2024-08-27 18:17:47 阅读量: 42 订阅数: 41 

Python实现最小生成树:Prim算法与Kruskal算法详解

# 1. Prim算法概述
Prim算法是一种经典的贪心算法,用于寻找加权无向连通图中的最小生成树。最小生成树是一棵连通子图,其中所有顶点都被连接,并且总权重最小。
Prim算法通过逐步添加边来构建最小生成树。它从一个任意的顶点开始,然后重复以下步骤,直到所有顶点都被添加到生成树中:
1. 选择生成树中权重最小的边,连接生成树中的顶点和非生成树中的顶点。
2. 将选定的边添加到生成树中。
# 2. Prim算法实战应用
### 2.1 最小生成树的定义和性质
#### 2.1.1 最小生成树的概念
最小生成树(MST)是一种无向连通图的生成树,其中所有边权之和最小。生成树是指包含图中所有顶点的无环连通子图。
#### 2.1.2 最小生成树的性质
* **唯一性:**对于给定的无向连通图,其最小生成树是唯一的。
* **边权和最小:**最小生成树中所有边权之和最小。
* **连通性:**最小生成树包含图中所有顶点,且这些顶点通过树中的边连接。
* **无环性:**最小生成树中不存在环路。
### 2.2 Prim算法的步骤和实现
#### 2.2.1 Prim算法的步骤
Prim算法是一种贪心算法,用于寻找无向连通图的最小生成树。其步骤如下:
1. 选择一个顶点作为起始顶点。
2. 找到起始顶点与其他所有顶点的最短边,并将其添加到最小生成树中。
3. 重复步骤2,直到所有顶点都被添加到最小生成树中。
#### 2.2.2 Prim算法的代码实现
```python
def prim(graph):
"""
Prim算法寻找最小生成树
参数:
graph:无向连通图,用邻接表表示
返回:
最小生成树的边集合
"""
# 初始化
mst = set() # 最小生成树的边集合
visited = set() # 已访问的顶点集合
visited.add(graph[0]) # 选择第一个顶点作为起始顶点
# 循环,直到所有顶点都被访问
while len(visited) < len(graph):
# 找到已访问顶点到未访问顶点的最短边
min_weight = float('inf')
min_edge = None
for v in visited:
for u, weight in graph[v]:
if u not in visited and weight < min_weight:
min_weight = weight
min_edge = (v, u)
# 将最短边添加到最小生成树中
mst.add(min_edge)
visited.add(min_edge[1])
return mst
```
**代码逻辑分析:**
* 初始化时,将第一个顶点添加到已访问顶点集合中,并创建一个空集来存储最小生成树的边。
* 循环遍历所有顶点,直到所有顶点都被访问。
* 在每次循环中,找到已访问顶点到未访问顶点的最短边,并将其添加到最小生成树中。
* 将最短边的另一个顶点添加到已访问顶点集合中。
* 重复上述步骤,直到所有顶点都被访问,最终得到最小生成树的边集合。
# 3. 网络拓扑图
#### 3.1.1 网络拓扑图的建模
网络拓扑图是一种抽象的数据结构,用于表示网络中的节点和连接关系。在Prim算法中,网络拓扑图可以建模为一个带权无向图,其中:
* 节点表示网络中的设备,如路由器、交换机或主机。
* 边表示设备之间的连接,权重表示连接的成本或距离。
#### 3.1.2 Prim算法的应用
Prim算法可以用于计算网络拓扑图中的最小生成树(MST)。MST是一组边,它连接了图中的所有节点,并且总权重最小。
Prim算法的应用步骤如下:
1. 选择一个起始节点作为生成树的根节点。
2. 从根节点出发,找到连接到根节点的所有边中权重最小的边。
3. 将权重最小的边添加到生成树中,并将其连接的节点添加到生成树中。
4. 重复步骤2和3,直到生成树包含了所有节点。
```python
import networkx as nx
def prim_mst(graph):
# 初始化生成树
mst = nx.Graph()
# 选择起始节点
start_node = list(graph.nodes)[0]
mst.add_node(start_node)
# 循环添加边到生成树
while len(mst) < len(graph):
# 找到权重最小的边
min_edge = None
min_
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了最小生成树算法,特别是 Prim 算法,涵盖了从理论到实践的各个方面。它提供了 Java 实现 Prim 算法的详细指南,并将其与 Kruskal 算法进行了比较。专栏还探讨了优化 Prim 算法的方法,并通过案例分析展示了其在实际应用中的优势。此外,它还分析了 Prim 算法在网络拓扑、数据结构、图论、并行计算、分布式系统、机器学习、自然语言处理、计算机视觉、运筹学、金融建模和生物信息学中的作用和应用。通过深入的分析和示例,本专栏为读者提供了对 Prim 算法及其广泛应用的全面理解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
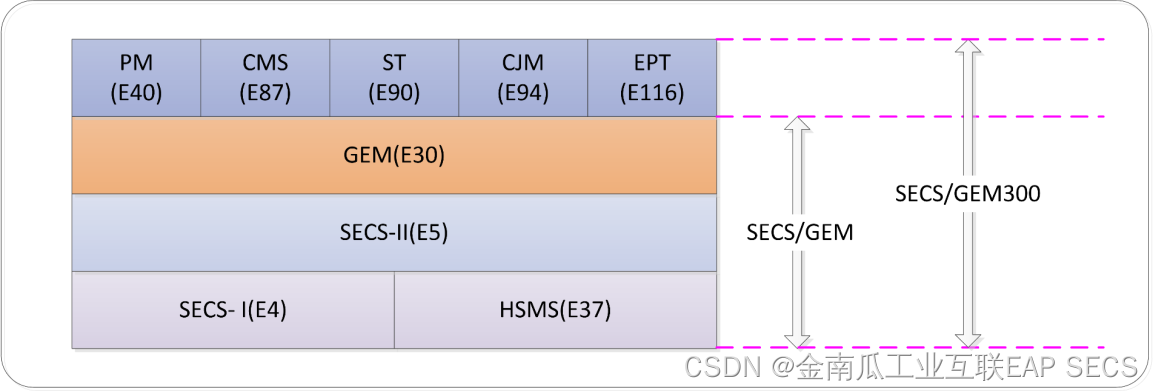
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )