使用SQL语言访问Oracle数据库
发布时间: 2023-12-16 22:52:17 阅读量: 14 订阅数: 14 
# 第一章:数据库基础知识
## 1.1 数据库概述
数据库是指按照数据模型组织、存储和管理数据的集合。数据库可以以文件或其他形式存储,是支持持久化的数据结构。
数据库可以分为关系型数据库和非关系型数据库两大类。关系型数据库以表格的形式组织数据,表与表之间通过键值关联。非关系型数据库可以根据数据特性进行存储,如键值对、文档、图形等。
## 1.2 关系型数据库概念
关系型数据库是指采用了关系模型来组织数据的数据库。它将数据以表格的形式组织,并通过键值关联来建立表与表之间的联系。
关系模型以实体、属性和关系为基本概念。实体表示对象,属性表示实体的特征,关系表示实体之间的连接。
## 1.3 Oracle数据库简介
Oracle是一种关系型数据库管理系统(RDBMS),由Oracle公司开发。它是全球使用最广泛的关系型数据库之一,具有高性能、可扩展性和安全性的特点。
Oracle数据库采用了多种存储模式和数据表达方式,支持高级查询语言SQL(Structured Query Language)进行数据的访问和操作。
## 1.4 SQL语言概述
SQL是结构化查询语言(Structured Query Language)的缩写,是一种用于与关系型数据库进行交互的语言。SQL可以用来查询、插入、更新和删除数据库中的数据。
SQL语言包括数据查询语言(DQL)、数据操作语言(DML)、数据定义语言(DDL)和数据控制语言(DCL)等多种子语言。
## 第二章:连接Oracle数据库
### 2.1 安装Oracle数据库客户端
在使用SQL语言访问Oracle数据库之前,需要先安装Oracle数据库客户端。以下是安装步骤:
步骤1:访问Oracle官方网站(https://www.oracle.com/downloads/index.html),下载适用于您操作系统的Oracle数据库客户端安装包。
步骤2:运行安装包,按照安装向导的提示完成安装过程。在安装过程中,您可以选择安装所需的组件和配置选项。
步骤3:安装完成后,将Oracle数据库客户端的安装目录添加到系统环境变量中,以便在命令行中访问Oracle相关命令和工具。
### 2.2 配置数据库连接信息
连接Oracle数据库之前,需要配置数据库连接信息。以下是配置步骤:
步骤1:打开Oracle客户端安装目录,找到"tnsnames.ora"文件。该文件包含了用于连接Oracle数据库的网络服务名称配置。
步骤2:使用文本编辑器打开"tnsnames.ora"文件,并添加一个新的网络服务名称配置。配置内容如下:
```
<service_name> =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = <oracle_host>)(PORT = <oracle_port>))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = <service_name>)
)
)
```
在上述配置中,需要替换以下参数:
- `<service_name>`:数据库的服务名称,可以是任意字符。
- `<oracle_host>`:数据库的主机名或IP地址。
- `<oracle_port>`:数据库的端口号。
步骤3:保存并关闭"tnsnames.ora"文件。
### 2.3 测试连接和验证
完成以上配置后,可以使用SQL语言访问Oracle数据库。以下是测试连接和验证的步骤:
步骤1:打开命令行终端或SQL开发工具,输入以下命令连接到Oracle数据库:
```sql
sqlplus <username>/<password>@<service_name>
```
在上述命令中,需要替换以下参数:
- `<username>`:数据库的用户名。
- `<password>`:数据库的密码。
- `<service_name>`:数据库的服务名称,与之前配置的网络服务名称一致。
步骤2:如果连接成功,将显示Oracle数据库的命令行提示符。
步骤3:输入SQL语句进行数据库操作,例如查询数据、插入数据等。可以使用标准的SQL语法进行操作。
步骤4:执行SQL语句后,将显示执行结果。
## 第三章:SQL基础
本章将介绍SQL语言的基础知识,包括SQL语句的结构、数据查询和过滤、数据排序和分组、聚合函数和子查询等内容。
### 3.1 SQL语句结构
SQL(Structured Query Language)是一种用于操作关系型数据库的语言。SQL语句由一个或多个关键字组成,用于执行特定的数据库操作,如查询、插入、更新和删除操作。
SQL语句通常分为以下几个部分:
- SELECT:用于查询数据,可以指定要查询的字段或表达式。
- FROM:用于指定要查询的表名或视图名。
- WHERE:用于指定查询的条件,可以使用比较运算符、逻辑运算符和通配符等。
- GROUP BY:用于分组查询,根据指定的字段对结果进行分组。
- HAVING:用于指定分组后的查询条件。
- ORDER BY:用于排序查询结果。
- LIMIT:用于限制查询结果的数量。
### 3.2 数据查询和过滤
数据查询是SQL语言最常用的功能之一。通过SELECT语句可以从数据库中检索出符合指定条件的数据。
下面是一个简单的SELECT语句的示例:
```sql
SELECT column1, column2 FROM table_name WHERE condition;
```
- column1, column2:要查询的字段名。
- table_name:要查询的表名。
- condition:查询的条件。
### 3.3 数据排序和分组
在查询数据时,经常需要对结果进行排序或分组操作。ORDER BY用于对查询结果进行排序,而GROUP BY用于按指定的字段对结果进行分组。
下面是一个排序查询和分组查询的示例:
```sql
-- 排序查询
SELECT column1, column2 FROM table_name ORDER BY column1 ASC;
-- 分组查询
SELECT column1, COUNT(column2) FROM table_name GROUP BY column1;
```
### 3.4 聚合函数和子查询
除了基本的查询和过滤操作之外,SQL还提供了一些聚合函数和子查询功能,用于进行更复杂的数据分析和统计。
聚合函数用于对数据进行计算,如求和、平均值、最大值、最小值等。常用的聚合函数包括SUM、AVG、MAX、MIN等。
子查询是指在一个查询中嵌套另一个查询,用于获取更精确的查询结果或作为其他查询的条件。
下面是一个使用聚合函数和子查询的示例:
```sql
-- 使用聚合函数
SELECT AVG(salary) FROM employees;
-- 使用子查询
SELECT column1 FROM table_name WHERE column2 IN (SELECT column2 FROM table_name2 WHERE condition);
```
### 第四章:数据操作
数据操作是使用SQL语言对数据库中的数据进行增、删、改的过程。本章将介绍如何使用SQL语言来操作Oracle数据库中的数据。
#### 4.1 插入数据
插入数据是将新的数据添加到数据库表中的操作。在Oracle数据库中,可以使用INSERT语句来实现数据插入。
示例代码(Python):
```python
import cx_Oracle
# 连接数据库
conn = cx_Oracle.connect('username/password@hostname:port/service_name')
# 创建游标
cur = conn.cursor()
# 定义插入语句
insert_query = "INSERT INTO employees (emp_id, emp_name, emp_salary) VALUES (:1, :2, :3)"
# 定义插入的数据
emp_id = 1
emp_name = 'John Doe'
emp_salary = 5000
# 执行插入语句
cur.execute(insert_query, (emp_id, emp_name, emp_salary))
# 提交事务
conn.commit()
# 关闭游标和数据库连接
cur.close()
conn.close()
```
注释:
- 首先使用cx_Oracle模块连接到Oracle数据库。
- 然后通过`connect()`方法传入数据库连接信息进行连接。
- 创建一个游标对象,可以通过游标执行SQL语句。
- 定义插入语句,使用`VALUES`子句指定要插入的数据。
- 通过`execute()`方法执行插入语句,使用绑定变量来传递实际的数据。
- 提交事务,将改动内容保存到数据库。
- 最后关闭游标和数据库连接。
#### 4.2 更新数据
更新数据是修改数据库表中已有数据的操作。在Oracle数据库中,可以使用UPDATE语句来实现数据更新。
示例代码(Java):
```java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class UpdateData {
public static void main(String[] args) {
String url = "jdbc:oracle:thin:@localhost:1521:xe";
String username = "username";
String password = "password";
try {
// 连接数据库
Connection conn = DriverManager.getConnection(url, username, password);
// 定义更新语句
String updateQuery = "UPDATE employees SET emp_salary = ? WHERE emp_id = ?";
// 创建PreparedStatement对象
PreparedStatement stmt = conn.prepareStatement(updateQuery);
// 定义更新的数据
int empId = 1;
double newSalary = 6000;
// 设置参数
stmt.setDouble(1, newSalary);
stmt.setInt(2, empId);
// 执行更新语句
int rowsAffected = stmt.executeUpdate();
System.out.println("Updated " + rowsAffected + " rows");
// 关闭连接和语句
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
```
注释:
- 首先使用`DriverManager.getConnection()`方法连接到Oracle数据库,传入数据库连接信息。
- 定义更新语句,使用`SET`子句指定要更新的字段和新的值。
- 创建`PreparedStatement`对象,可以通过预编译的方式执行SQL语句。
- 设置更新的数据,使用`setX()`方法设置参数,参数索引从1开始。
- 执行更新语句,`executeUpdate()`方法返回受影响的行数。
- 最后关闭连接和语句。
#### 4.3 删除数据
删除数据是将数据库表中的数据删除的操作。在Oracle数据库中,可以使用DELETE语句来实现数据删除。
示例代码(Golang):
```go
package main
import (
"database/sql"
"fmt"
_ "github.com/godror/godror"
)
func main() {
connStr := `user="username" password="password" connectString="hostname:port/service_name"`
// 连接数据库
db, err := sql.Open("godror", connStr)
if err != nil {
fmt.Println("Failed to connect to database:", err)
return
}
defer db.Close()
// 定义删除语句
deleteQuery := "DELETE FROM employees WHERE emp_id = :1"
// 创建准备语句
stmt, err := db.Prepare(deleteQuery)
if err != nil {
fmt.Println("Failed to prepare query:", err)
return
}
defer stmt.Close()
// 定义删除的数据
empId := 1
// 执行删除语句
result, err := stmt.Exec(empId)
if err != nil {
fmt.Println("Failed to execute query:", err)
return
}
// 获取受影响的行数
rowsAffected, err := result.RowsAffected()
if err != nil {
fmt.Println("Failed to get rows affected:", err)
return
}
fmt.Println("Deleted", rowsAffected, "rows")
}
```
注释:
- 首先使用`sql.Open()`方法连接到Oracle数据库,传入连接字符串。
- 定义删除语句,使用`DELETE FROM`子句指定要删除的表和条件。
- 创建准备语句,通过预编译的方式执行SQL语句。
- 定义删除的数据,使用实际的数据替换绑定变量。
- 执行删除语句,`Exec()`方法返回一个`Result`对象。
- 通过`RowsAffected()`方法获取受影响的行数。
- 最后关闭数据库连接和语句。
#### 4.4 事务处理与回滚
事务是一组数据库操作的集合,要么全部成功提交,要么全部失败回滚。在Oracle数据库中,可以使用事务来确保数据库操作的完整性和一致性。
示例代码(JavaScript):
```javascript
const oracledb = require('oracledb');
oracledb.autoCommit = false;
async function run() {
let conn;
try {
// 连接数据库
conn = await oracledb.getConnection({
user: 'username',
password: 'password',
connectString: 'hostname:port/service_name'
});
// 开始事务
await conn.execute('BEGIN');
// 执行多个操作
// 操作1
await conn.execute('INSERT INTO employees (emp_id, emp_name, emp_salary) VALUES (:1, :2, :3)', [1, 'John Doe', 5000]);
// 操作2
const result = await conn.execute('UPDATE employees SET emp_salary = :1 WHERE emp_id = :2', [6000, 1]);
console.log('Updated', result.rowsAffected, 'rows');
// 提交事务
await conn.execute('COMMIT');
} catch (err) {
console.error('Error:', err.message);
// 发生错误回滚事务
if (conn) {
await conn.execute('ROLLBACK');
}
} finally {
// 关闭连接
if (conn) {
await conn.close();
}
}
}
run().catch(err => console.error('Error:', err));
```
注释:
- 首先使用`oracledb.getConnection()`方法连接到Oracle数据库,传入连接信息。
- 将`autoCommit`属性设置为`false`,禁止自动提交事务。
- 在`run()`函数中,使用`await`关键字执行各个操作。
- 使用`await conn.execute('BEGIN')`开始事务。
- 执行一系列的数据库操作,包括插入、更新等。
- 使用`await conn.execute('COMMIT')`提交事务。
- 如果发生错误,使用`await conn.execute('ROLLBACK')`回滚事务。
- 最后使用`await conn.close()`关闭数据库连接。
这样可以确保在执行多个数据库操作时,如果其中一个操作出现错误,可以回滚事务以保持数据的一致性。
## 第五章:高级SQL操作
### 5.1 多表联接
在实际的数据库操作中,经常需要处理多个表之间的关系。而通过多表联接,我们可以方便地将多个表中的数据进行关联和查询。
#### 5.1.1 内连接(INNER JOIN)
内连接是最常用的一种连接方式,它会返回同时满足两个表中条件的记录。
下面是一个示例,假设我们有两个表:`Customers`和`Orders`。我们想要获取所有有订单的客户的信息:
```sql
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
INNER JOIN Orders
ON Customers.CustomerID = Orders.CustomerID;
```
在上述示例中,我们使用`INNER JOIN`将`Customers`和`Orders`表连接起来,并指定了连接的条件。通过选择需要的字段,我们可以得到所有有订单的客户的姓名和订单号。
#### 5.1.2 左连接(LEFT JOIN)
左连接会返回左表中的所有记录,以及右表中满足条件的记录。
假设我们希望获取所有客户的信息,无论他们是否有订单:
```sql
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders
ON Customers.CustomerID = Orders.CustomerID;
```
在上述示例中,使用`LEFT JOIN`将`Customers`和`Orders`表连接起来。即使某些客户没有订单,他们的信息也会被返回,只是订单号字段会显示为`NULL`。
#### 5.1.3 右连接(RIGHT JOIN)
右连接会返回右表中的所有记录,以及左表中满足条件的记录。
假设我们希望获取所有订单的信息,无论订单是否对应一个客户:
```sql
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
RIGHT JOIN Orders
ON Customers.CustomerID = Orders.CustomerID;
```
在上述示例中,使用`RIGHT JOIN`将`Customers`和`Orders`表连接起来。即使某些订单没有对应的客户,它们的信息也会被返回,只是客户姓名字段会显示为`NULL`。
#### 5.1.4 全连接(FULL JOIN)
全连接会返回左表和右表中的所有记录,无论是否满足条件。
假设我们希望获取所有客户和订单的信息:
```sql
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL JOIN Orders
ON Customers.CustomerID = Orders.CustomerID;
```
在上述示例中,使用`FULL JOIN`将`Customers`和`Orders`表连接起来。无论客户是否有订单、订单是否对应一个客户,所有的记录都会被返回。
### 5.2 视图的使用
视图是一个虚拟表,可以根据查询定义创建。它是一个保存查询结果的查询。
下面是一个示例,我们创建一个视图来获取具有特定条件的订单信息:
```sql
CREATE VIEW HighValueOrders AS
SELECT OrderID, OrderDate, TotalAmount
FROM Orders
WHERE TotalAmount > 1000;
```
在上述示例中,我们使用`CREATE VIEW`语句创建了一个名为`HighValueOrders`的视图,它的定义是获取`Orders`表中总金额大于1000的订单信息。
可以像查询表一样使用视图,例如:
```sql
SELECT * FROM HighValueOrders;
```
上述查询会返回满足条件的订单信息。
### 5.3 索引和性能优化
索引是对数据库表中一列或多列的值进行排序的一种结构,它可以提高数据的检索效率。
#### 5.3.1 创建索引
假设我们有一个名为`Employees`的表,我们希望通过员工的姓名快速查找员工信息。为了提高查询的速度,我们可以创建一个索引。
```sql
CREATE INDEX idx_employees_name ON Employees (EmployeeName);
```
在上述示例中,我们使用`CREATE INDEX`语句创建了一个名为`idx_employees_name`的索引,它针对`Employees`表中的`EmployeeName`列进行排序。
#### 5.3.2 使用索引
在查询中使用索引可以加快数据检索的速度。
```sql
SELECT * FROM Employees WHERE EmployeeName = 'John Doe';
```
在上述示例中,我们通过查询`Employees`表中姓名为`John Doe`的员工信息。由于我们创建了姓名列的索引,查询会更加快速。
#### 5.3.3 索引优化
对于频繁被查询的列,使用索引可以提高查询效率。然而,过多的索引会增加插入、更新和删除操作的开销,因此需要权衡。
可以通过使用数据库管理工具或执行查询来查看索引的使用情况,并根据查询的性能进行调整和优化。
## 第六章:SQL的高级功能
在本节中,我们将介绍一些SQL的高级功能,包括存储过程和触发器、自定义函数、递归查询和分析函数以及数据库权限管理。
### 6.1 存储过程和触发器
#### 6.1.1 存储过程
存储过程是一组经过预编译的SQL语句的集合,也可以包含流程控制语句,用于执行特定的数据库操作。存储过程可以接收参数,并返回结果集或输出参数。
示例代码(使用Java):
```java
// 创建存储过程
String createProcedure = "CREATE PROCEDURE get_employee(IN id INT, OUT name VARCHAR(255)) " +
"BEGIN " +
"SELECT emp_name INTO name FROM employees WHERE emp_id = id; " +
"END";
// 调用存储过程
String callProcedure = "CALL get_employee(1, @name)";
String selectResult = "SELECT @name";
// 执行存储过程并获取结果
try (Connection connection = DriverManager.getConnection(url, username, password);
Statement statement = connection.createStatement()) {
// 创建存储过程
statement.executeUpdate(createProcedure);
// 调用存储过程
statement.executeUpdate(callProcedure);
// 获取结果
ResultSet resultSet = statement.executeQuery(selectResult);
while (resultSet.next()) {
String employeeName = resultSet.getString(1);
System.out.println("Employee name: " + employeeName);
}
} catch (SQLException e) {
e.printStackTrace();
}
```
#### 6.1.2 触发器
触发器是与数据库表相关联的特殊类型的存储过程。它们在表上的插入、更新或删除操作发生时自动执行。通过使用触发器,可以在数据库层面上实现业务规则的完整性和一致性。
示例代码(使用Python):
```python
# 创建触发器
createTrigger = """
CREATE OR REPLACE TRIGGER calculate_salary
BEFORE INSERT OR UPDATE ON employees
FOR EACH ROW
BEGIN
IF :new.salary < 1000 THEN
raise_application_error(-20000, 'Salary must not be less than 1000');
END IF;
:new.salary_with_bonus := :new.salary * 1.1;
END;
"""
# 插入数据
insertData = "INSERT INTO employees (emp_id, emp_name, salary) VALUES (1, 'John Smith', 900)"
selectData = "SELECT emp_id, emp_name, salary_with_bonus FROM employees WHERE emp_id = 1"
# 执行触发器并获取结果
with cx_Oracle.connect("username/password@ip:port/service_name") as connection:
with connection.cursor() as cursor:
# 创建触发器
cursor.execute(createTrigger)
# 插入数据
cursor.execute(insertData)
# 获取结果
cursor.execute(selectData)
result = cursor.fetchone()
print("Employee ID: ", result[0])
print("Employee Name: ", result[1])
print("Salary with Bonus: ", result[2])
```
### 6.2 自定义函数
自定义函数是指用户根据自己的需求编写的可被SQL语句调用的函数。通过自定义函数,可以实现一些复杂或特定的计算逻辑,并在数据库中重用。
示例代码(使用Go):
```go
// 创建自定义函数
createFunction := `
CREATE OR REPLACE FUNCTION calculate_tax(income NUMBER) RETURN NUMBER IS
tax_rate NUMBER;
BEGIN
IF income < 50000 THEN
tax_rate := 0.15;
ELSE
tax_rate := 0.2;
END IF;
RETURN income * tax_rate;
END;
`
// 调用自定义函数
callFunction := `
DECLARE
net_income NUMBER;
BEGIN
net_income := calculate_tax(60000);
DBMS_OUTPUT.PUT_LINE('Net Income: ' || net_income);
END;
`
// 执行自定义函数
func ExecuteCustomFunction(conn *sql.DB) {
_, err := conn.Exec(createFunction)
if err != nil {
fmt.Println("Error creating custom function:", err)
return
}
_, err = conn.Exec(callFunction)
if err != nil {
fmt.Println("Error calling custom function:", err)
return
}
}
```
### 6.3 递归查询和分析函数
递归查询是一种特殊的查询方式,在查询过程中可以引用查询结果集本身。分析函数允许在查询时对结果集进行计算和分析,并可以与其他查询语句结合使用。
示例代码(使用JavaScript):
```javascript
// 递归查询
WITH recursive_query (emp_id, emp_name, manager_id, emp_level) AS (
SELECT emp_id, emp_name, manager_id, 0
FROM employees
WHERE emp_id = 1
UNION ALL
SELECT e.emp_id, e.emp_name, e.manager_id, r.emp_level + 1
FROM employees e
INNER JOIN recursive_query r ON e.manager_id = r.emp_id
)
SELECT emp_id, emp_name, manager_id, emp_level
FROM recursive_query
// 分析函数
SELECT emp_id, emp_name, salary,
ROW_NUMBER() OVER(PARTITION BY department_id ORDER BY salary DESC) AS rank
FROM employees
```
### 6.4 数据库权限管理
数据库权限管理是指根据不同的用户和角色,对数据库中的对象和操作进行授权和限制的过程。可以通过数据库的访问控制语句来实现对用户权限的控制。
示例代码(使用Python):
```python
# 创建用户
createUser = "CREATE USER testuser IDENTIFIED BY password"
# 授权用户
grantPermission = "GRANT CONNECT, RESOURCE, CREATE SESSION TO testuser"
# 撤销权限
revokePermission = "REVOKE RESOURCE FROM testuser"
# 删除用户
dropUser = "DROP USER testuser"
# 执行操作
with cx_Oracle.connect("username/password@ip:port/service_name") as connection:
with connection.cursor() as cursor:
# 创建用户
cursor.execute(createUser)
# 授权用户
cursor.execute(grantPermission)
# 撤销权限
cursor.execute(revokePermission)
# 删除用户
cursor.execute(dropUser)
```
以上是SQL的高级功能的介绍,包括存储过程和触发器、自定义函数、递归查询和分析函数以及数据库权限管理。这些功能能够帮助开发人员提高开发效率和数据管理能力。
0
0
相关推荐

专栏简介
专栏《Oracle数据库管理系统与SQL优化》涵盖了Oracle数据库管理系统的基本概念、架构以及SQL优化的实践技巧。从Oracle数据库的安装配置到SQL语言的基本语法与高级查询技巧,涉及了表的创建、修改和删除操作、索引和约束优化、数据类型和转换处理等内容。此外,还介绍了事务与并发控制、视图和存储过程的应用、触发器和事件实现数据库的自动化操作、备份与恢复保证数据的安全性、性能调优与监控等方面的技术。专栏通过实例分析和案例演示帮助读者深入理解Oracle数据库管理系统与SQL优化,适合数据库从业人员及对Oracle数据库管理与SQL开发感兴趣的人士参考学习。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
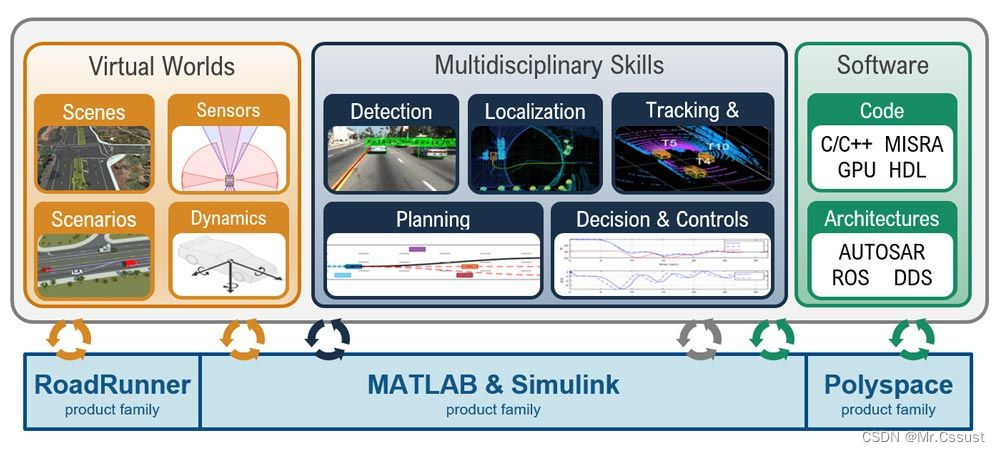
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
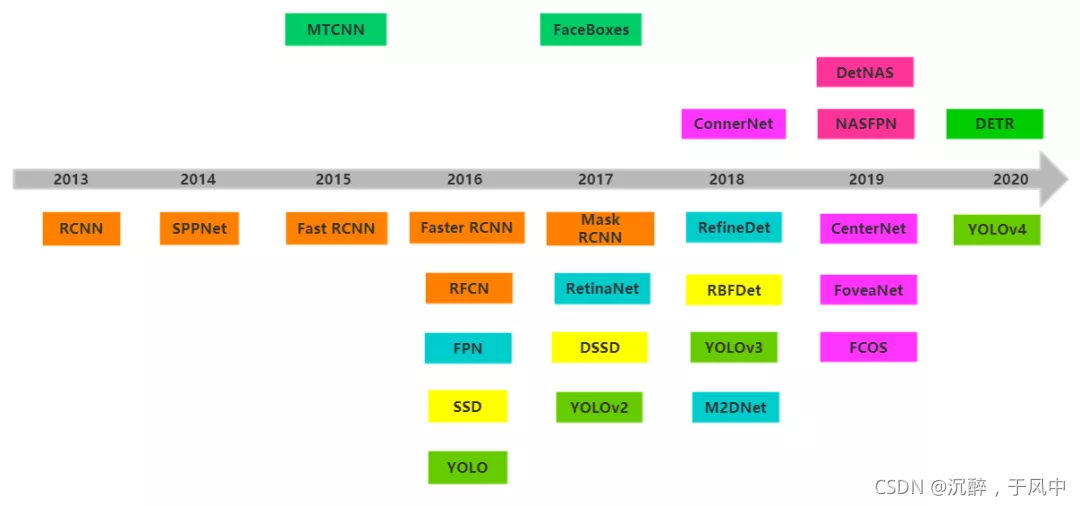
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )