初探ReplicaSet和Deployment的基本概念
发布时间: 2024-03-10 08:08:08 阅读量: 12 订阅数: 10 
# 1. 简介
在当今云原生技术蓬勃发展的背景下,容器编排成为了许多云计算平台的核心功能之一。而在容器编排中,ReplicaSet和Deployment作为重要的概念,扮演着保证应用高可用性和扩展性的关键角色。
## 介绍文章的背景和目的
容器编排技术的快速发展使得应用部署、管理和扩展变得更加简单高效。然而,不同的控制器在容器编排中有着不同的作用和优势,因此本文将重点介绍ReplicaSet和Deployment这两个重要概念。
## 引出ReplicaSet和Deployment在容器编排中的重要性
ReplicaSet作为Kubernetes中的一个资源控制器,可以确保指定数量的Pod副本一直在运行,从而提高应用的可用性。而Deployment则是ReplicaSet的进一步封装,提供了更多便捷的管理功能和更新策略,使得应用的部署和更新更加灵活和可靠。在本文中,我们将深入探讨ReplicaSet和Deployment的概念、配置以及实践指南,帮助读者更好地理解和应用这两个关键概念。
# 2. ReplicaSet概念详解
ReplicaSet是Kubernetes中的一个重要概念,用于确保指定数量的Pod副本始终在运行状态。在容器编排中,ReplicaSet扮演着非常关键的角色,下面我们将详细解析ReplicaSet的相关概念和用法。
#### 2.1 什么是ReplicaSet
ReplicaSet是Kubernetes中的控制器对象,用于确保指定数量的Pod副本始终处于运行状态。如果某个Pod因为节点故障或其他原因被删除,ReplicaSet将负责启动新的Pod来替代,以确保系统的稳定运行。
#### 2.2 ReplicaSet的作用和特点
- **确保Pod副本数量**:ReplicaSet可以根据指定的副本数量创建和维护Pod的多个副本。
- **故障自愈**:当某个Pod发生故障时,ReplicaSet会自动创建新的Pod来替代,从而确保副本数量符合设定值。
- **版本管理**:ReplicaSet可以通过控制Pod的标签选择器来管理不同版本的Pod副本。
- **水平扩展**:可以通过更改ReplicaSet的副本数量来实现Pod的水平扩展。
#### 2.3 ReplicaSet与Pod的关系
ReplicaSet是管理Pod副本的控制器,它通过Pod模板的定义来创建和管理Pod。在ReplicaSet中定义了Pod的模板(包括容器镜像、标签选择器等),当需要创建新的Pod副本时,ReplicaSet会根据这个模板来生成新的Pod对象。
在下一节中,我们将重点讨论ReplicaSet的配置与管理,包括如何创建一个ReplicaSet以及对其进行配置。
# 3. ReplicaSet配置与管理
在本章中,我们将详细讨论ReplicaSet的配置与管理,包括如何创建一个ReplicaSet、ReplicaSet的yaml配置文件解析以及ReplicaSet的自动伸缩策略。让我们一起深入了解吧。
**1. 如何创建一个ReplicaSet**
要创建一个ReplicaSet,首先需要编写一个ReplicaSet的yaml配置文件,示例如下:
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:latest
ports:
- containerPort: 80
```
在上述示例中,我们定义了一个名为`my-replicaset`的ReplicaSet,指定了副本数为3,使用了一个带有`app: my-app`标签的Pod模板,其中运行了一个Nginx容器。
通过使用`kubectl apply -f replicaset.yaml`命令,即可创建该ReplicaSet。运行`kubectl get rs`命令可以查看ReplicaSet的状态。
**2. ReplicaSet的yaml配置文件解析**
- `apiVersion`: 指定使用的API版本,这里使用的是`apps/v1`。
- `kind`: 指定资源类型为ReplicaSet。
- `metadata`: 包含ReplicaSet的元数据信息,如名称。
- `spec`: ReplicaSet的规格,指定了副本数、选择器和Pod模板。
- `replicas`: 指定副本数。
- `selector`: 定义匹配Pod的标签选择器。
- `template`: Pod的模板信息,包括标签和容器定义。
- `metadata`: Pod的元数据,包括标签。
- `spec`: 定义Pod的规格,如容器信息。
**3. ReplicaSet的自动伸缩策略**
ReplicaSet没有原生的自动伸缩功能,但可以结合Horizontal Pod Autoscaler(HPA)来实现根据CPU利用率等指标自动伸缩副本数量。通过定义HPA对象并将其与ReplicaSet关联,即可实现自动横向扩展。
```yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: ReplicaSet
name: my-replicaset
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
```
在这个示例中,我们定义了一个HPA对象,指定了当CPU利用率达到80%时,副本数最小为2个,最大为5个。
通过以上方式,我们可以配置和管理ReplicaSet,实现应用程序的高可用性和弹性扩展。
# 4. Deployment概念解析
在容器编排中,Deployment是一种用于管理Pod的控制器,它提供了对Pod的创建、扩展、收缩、更新以及滚动回滚等功能。下面我们来详细解析Deployment的相关概念和特点。
**什么是Deployment**
Deployment是Kubernetes中的一个资源对象,用于定义Pod的部署方式和管理。通过Deployment对象的控制,可以确保应用的容器始终保持可用状态,同时支持滚动更新和回滚操作,保障应用的稳定性。
**Deployment的优势与特点**
- **简化管理**:Deployment可以方便地管理Pod的创建和更新,无需手动处理Pod的创建与销毁过程。
- **自动修复**:Deployment能够自动监控Pod的状态,并在Pod故障时进行自动恢复,保证应用的高可用性。
- **滚动更新**:Deployment支持滚动更新功能,可以逐步更新应用的副本,避免一次性更新导致的系统不可用问题。
- **回滚操作**:如果应用更新后发生问题,可以通过Deployment快速回滚至之前稳定的版本,降低更新风险。
**Deployment与ReplicaSet的关系**
在Kubernetes中,Deployment实际上是通过控制ReplicaSet来管理Pod的。Deployment定义了ReplicaSet的模板,并通过ReplicaSet来控制Pod的数量及更新等操作。Deployment提供了更高级别的抽象,方便管理和操作应用的部署过程。
综上所述,Deployment作为Kubernetes中重要的资源对象之一,为容器编排提供了强大的部署和管理功能,极大地简化了应用的部署流程,提高了应用的可靠性和稳定性。
# 5. Deployment实践指南
Deployment是Kubernetes中用于管理应用部署的重要控制器,它提供了对应用的创建、更新和回滚的功能。在本节中,我们将介绍如何使用Deployment来管理应用的部署,并演示一些常见的操作命令。
#### 如何使用Deployment管理应用的部署
要使用Deployment来管理应用的部署,首先需要创建一个Deployment对象,定义应用的镜像、副本数等信息。接下来,Kubernetes将根据这些配置来创建Pod并确保其稳定运行。下面是一个简单的Deployment配置示例:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerPort: 8080
```
上面的配置文件定义了一个名为`myapp-deployment`的Deployment,指定了应用的副本数为3,并且定义了Pod模板的镜像和端口信息。
#### Deployment的常见操作命令
一旦Deployment创建完成,我们可以使用`kubectl`命令来对Deployment进行管理,例如:
- 查看Deployment列表:
```bash
kubectl get deployments
```
- 查看Deployment详细信息:
```bash
kubectl describe deployment myapp-deployment
```
- 扩容Deployment的副本数:
```bash
kubectl scale deployment myapp-deployment --replicas=5
```
- 滚动更新Deployment的镜像版本:
```bash
kubectl set image deployment/myapp-deployment myapp-container=myapp:v2
```
#### Deployment的滚动更新和回滚功能
Deployment还提供了滚动更新和回滚功能,可以在不中断应用的情况下更新应用的镜像版本。例如,要将`myapp-deployment`的镜像版本回滚到上一个版本,可以使用以下命令:
```bash
kubectl rollout undo deployment/myapp-deployment
```
通过上述命令,Deployment将自动回滚到上一个成功的版本,确保应用的稳定性和可靠性。
通过这些操作命令,我们可以灵活地管理Deployment,实现应用的平滑更新和部署的灵活管理。
以上是关于使用Deployment管理应用部署的实践指南,希望对你有所帮助。
# 6. 实例分析与总结
在这一部分,我们将通过一个具体的实例来展示ReplicaSet和Deployment的应用,并对它们进行总结和分析。
#### 具体实例
假设我们有一个Web应用,需要部署到Kubernetes集群上,并且需要保证高可用性和扩展性。我们可以通过ReplicaSet和Deployment来完成这个任务。
首先,我们创建一个ReplicaSet来确保至少有3个Pod副本在运行,以保证高可用性和负载均衡。接下来,我们可以使用Deployment来管理这个ReplicaSet,并实现滚动更新和回滚功能,确保应用的稳定性和可维护性。
下面是一个示例的ReplicaSet和Deployment的yaml配置文件:
```yaml
# ReplicaSet配置文件示例
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: webapp-replicaset
labels:
app: webapp
spec:
replicas: 3
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: webapp
image: nginx:latest
ports:
- containerPort: 80
```
```yaml
# Deployment配置文件示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp-deployment
labels:
app: webapp
spec:
replicas: 3
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: webapp
image: nginx:1.19
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
```
#### 总结与分析
通过以上实例,我们可以看到ReplicaSet和Deployment的应用场景和优势:
- ReplicaSet通过管理多个Pod副本,实现了应用的高可用性和负载均衡,保证了应用的稳定性和可靠性。
- Deployment通过控制ReplicaSet的创建和更新过程,实现了应用的滚动更新和回滚功能,帮助我们轻松管理应用的版本和变更。
当然,ReplicaSet和Deployment也有一些局限性,比如无法处理跨节点的故障转移和富容器的部署等问题,但它们在容器编排领域仍然扮演着重要的角色。
#### 展望未来
随着容器编排技术的不断发展,ReplicaSet和Deployment也在不断演进和完善。未来,我们可以期待它们在跨节点调度、故障自愈、自动扩展等方面有更多的突破和创新,为容器化应用提供更多的可能性和便利。
通过以上实例分析和总结,我们对ReplicaSet和Deployment有了更深入的了解,并对它们的发展方向有了一定的展望。
以上是本章内容,如有其他需要,请随时告诉我。
0
0
相关推荐

最低0.47元/天 解锁专栏
VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB遗传算法交通规划应用:优化交通流,缓解拥堵难题

# 1. 交通规划概述**
交通规划是一门综合性学科,涉及交通工程、城市规划、经济学、环境科学等多个领域。其主要目的是优化交通系统,提高交通效率,缓解交通拥堵,保障交通安全。
交通规划的范围十分广泛,包括交通需求预测、交通网络规划、交通管理和控制、交通安全管理等。交通规划需要考虑多种因素,如人口分布、土地利用、经济发展、环境保护等,并综合运用各种技术手段和管理措施,实现交通系统的可持续发展。
# 2. 遗传算法原理
保障飞行安全,探索未知领域:MATLAB数值积分在航空航天中的应用

# 1. MATLAB数值积分简介
MATLAB数值积分是利用计算机近似求解积分的
MATLAB带通滤波器在电力系统分析中的应用:4种滤波方案,优化数据质量,提升系统稳定性

# 1. MATLAB带通滤波器的理论基础**
带通滤波器是一种仅允许特定频率范围信号通过的滤波器,在信号处理和电力系统分析中广泛应用。MATLAB提供了强大的工具,用于设计和实现带通滤波器。
**1.1 滤波器设计理论**
带通滤波器的设计基于频率响应,它表示滤波器对不同频率信号的衰减特性。常见的滤波器类型包括巴特沃斯、切比雪夫和椭圆滤
应用MATLAB傅里叶变换:从图像处理到信号分析的实用指南

# 1. MATLAB傅里叶变换概述
傅里叶变换是一种数学工具,用于将信号从时域转换为频域。它在信号处理、图像处理和通信等领域有着广泛的应用。MATLAB提供了一系列函
Kafka消息队列实战:从入门到精通

# 1. Kafka消息队列概述**
Kafka是一个分布式流处理平台,用于构建实时数据管道和应用程序。它提供了一个高吞吐量、低延迟的消息队列,可处理大量数据。Kafka的架构和特性使其成为构建可靠、可扩展和容错的流处理系统的理想选择。
Kafka的关键组件包括生产者、消费者、主题和分区。生产者将消息发布到主题中,而消费者订阅主题并消费消息。主题被划分为分区
傅里叶变换在MATLAB中的云计算应用:1个大数据处理秘诀

# 1. 傅里叶变换基础**
傅里叶变换是一种数学工具,用于将时域信号分解为其频率分量。它在信号处理、图像处理和数据分析等领域有着广泛的应用。
傅里叶变换的数学表达式为:
```
F(ω) = ∫_{-\infty}^{\infty} f(t) e^(-iωt) dt
```
其中:
* `f(t)` 是时域信号
* `F(ω)` 是频率域信号
* `ω`
MATLAB随机数交通规划中的应用:从交通流量模拟到路线优化

# 1.1 交通流量的随机特性
交通流量具有明显的随机性,这主要体现在以下几个方面:
- **车辆到达时间随机性:**车辆到达某个路口或路段的时间不是固定的,而是服从一定的概率分布。
- **车辆速度随机性:**车辆在道路上行驶的速度会受到各种因素的影响,如道路状况、交通状况、天气状况等,因此也是随机的。
- **交通事故随机性:**交通事故的发生具有偶然性,其发生时间
MATLAB等高线在医疗成像中的应用:辅助诊断和治疗决策,提升医疗水平
# 1. MATLAB等高线在医疗成像中的概述**
MATLAB等高线是一种强大的工具,用于可视化和分析医疗图像中的数据。它允许用户创建等高线图,显示图像中特定值或范围的区域。在医疗成像中,等高线可以用于各种应用,包括图像分割、配准、辅助诊断和治疗决策。
等高线图通过将图像中的数据点连接起来创建,这些数据点具有相同的特定值。这可以帮助可视化图像中的数据分布,并识别感兴趣
C++内存管理详解:指针、引用、智能指针,掌控内存世界
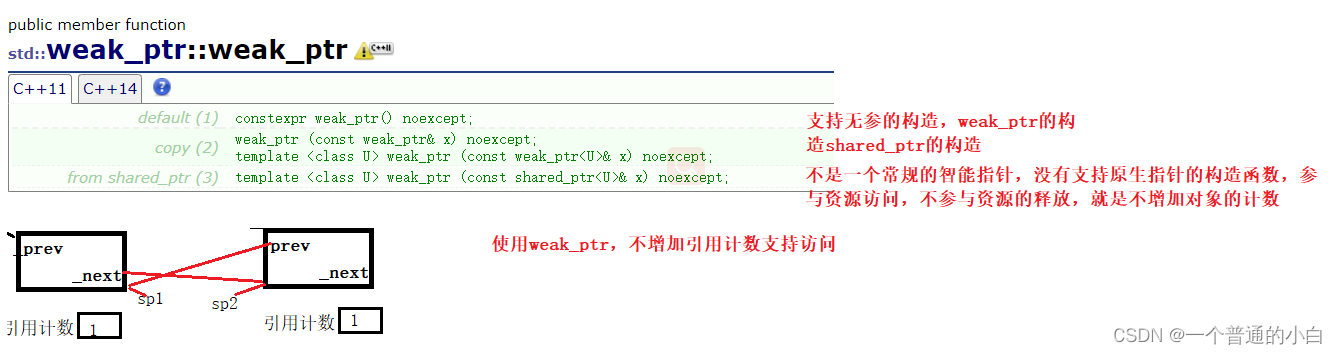
# 1. C++内存管理基础**
C++内存管理是程序开发中的关键环节,它决定了程序的内存使用效率、稳定性和安全性。本章将介绍C++内存管理的基础知识,为后续章节的深入探讨奠定基础。
C++中,内存管理主要涉及两个方面:动态内存分配和内存释放。动态内存分配是指在程序运行时从堆内存中分配内存空间,而内存释放是指释放不再使用的内存空间,将其返还给系统。
# 2. 指针与引用
### 2.1 指针的本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )