容器技术:Docker与Kubernetes入门
发布时间: 2024-01-15 05:21:56 阅读量: 43 订阅数: 22 

kubernetes+docker基础篇
# 1. 容器技术简介
## 1.1 什么是容器技术
容器技术是一种轻量级、可移植、自给自足的应用打包和运行环境。它允许开发者将应用和其所有的依赖项(包括库、配置文件等)一起打包至一个称为容器的文件中。这使得应用程序可以在不同的环境中运行,因为容器保证了应用的运行环境的一致性。
## 1.2 容器技术的优势和应用场景
容器技术的优势包括快速部署、资源利用率高、环境一致性、易扩展性以及更好的版本控制。应用场景包括开发和测试环境的快速搭建、持续集成和持续部署、微服务架构、混合云和多云部署等。
## 1.3 容器技术的发展历程
容器技术最早可以追溯到操作系统层的虚拟化技术,如FreeBSD的jails和Solaris的Zone。后来,Docker的出现彻底改变了容器技术的发展格局,大大促进了容器技术的应用和普及。随后,由Google开源的Kubernetes提供了容器编排和管理的解决方案,进一步推动了容器技术的发展。
# 2. Docker入门
### 2.1 Docker的概念和基本原理
Docker是一种开源的容器化平台,可以将应用程序及其依赖项打包到一个可移植的容器中,然后进行发布。Docker容器将应用程序自身与所需的运行环境隔离开来,从而实现了快速部署、升级和扩展。
Docker容器的基本原理是利用Linux内核的Cgroups和Namespace等技术,实现容器的隔离和资源限制。每个容器都运行在宿主机的相同内核上,但是相互之间互相隔离,拥有自己的文件系统、网络和进程空间。
### 2.2 Docker的核心组件和架构
Docker的核心组件包括Docker Engine、Docker Client、Docker Registry和Docker Compose等。
- Docker Engine是一个C/S架构的应用,包括一个长期运行的守护进程(dockerd)和一组用于与守护进程交互的REST API。
- Docker Client是用户与Docker交互的主要方式,可以通过命令行或者API请求与Docker Engine进行交互。
- Docker Registry用来保存Docker镜像,包括公开的Docker Hub和私有的Docker Registry。
- Docker Compose用于定义和运行多个容器的应用,可以通过一个单独的docker-compose.yml文件来配置应用的服务。
### 2.3 安装和配置Docker
#### 在Linux系统上安装Docker
```bash
sudo apt-get update
sudo apt-get install docker-ce
```
#### 在Windows系统上安装Docker
在Docker官网下载适用于Windows的Docker Desktop并安装。
### 2.4 Docker常用命令和操作
1. 检查Docker版本
```bash
docker --version
```
2. 运行一个容器
```bash
docker run -d -p 80:80 nginx
```
3. 列出所有容器
```bash
docker ps -a
```
4. 停止一个容器
```bash
docker stop <container_id>
```
5. 构建镜像
```bash
docker build -t myapp .
```
6. 上传镜像到Docker Hub
```bash
docker push myapp:tag
```
以上是Docker的入门知识,通过学习Docker的概念、架构、安装配置以及常用命令和操作,读者可以深入了解和开始使用Docker容器技术。
# 3. Docker的高级使用
在前两个章节中,我们已经了解了Docker的基本概念、安装和基本操作。在本章节中,我们将进一步学习Docker的高级使用方法,包括镜像的创建和使用、容器的管理和扩展、网络和存储管理以及安全性和监控等方面的内容。
### 3.1 Docker镜像的创建和使用
Docker镜像是Docker容器的基础,它包含了一个完整的文件系统,包括操作系统、应用程序和依赖等。在这一节中,我们将学习如何创建自己的Docker镜像并使用它来运行容器。
首先,我们需要编写一个Dockerfile来定义镜像的构建过程。Dockerfile是一个文本文件,其中包含了一系列的指令,用来描述如何构建镜像。例如,我们可以通过以下的Dockerfile来创建一个基于Ubuntu操作系统的Web应用程序镜像:
```dockerfile
# 使用官方的Ubuntu作为基础镜像
FROM ubuntu:18.04
# 设置镜像的作者信息
MAINTAINER Your Name <your.email@example.com>
# 安装依赖包和运行环境
RUN apt-get update && apt-get install -y \
nginx \
python3 \
python3-pip
# 将本地的应用程序复制到镜像中
COPY ./app /app
# 安装应用程序的依赖包
RUN pip3 install -r /app/requirements.txt
# 设置容器启动时运行的命令
CMD ["nginx", "-g", "daemon off;"]
```
在上述的Dockerfile中,我们首先使用`FROM`指令来指定基础镜像为官方的Ubuntu。然后,使用`MAINTAINER`指令来设置镜像的作者信息。接着,使用`RUN`指令来执行命令安装依赖包和运行环境。使用`COPY`指令将本地的应用程序复制到镜像中,并使用`RUN`指令安装应用程序的依赖包。最后,使用`CMD`指令设置容器启动时运行的命令。
完成了Dockerfile的编写后,我们可以使用`docker build`命令来构建镜像:
```bash
$ docker build -t myapp:1.0 .
```
其中,`-t`参数用来指定镜像的名称和标签,`.`表示Dockerfile所在的目录。
构建镜像完成后,我们可以使用`docker images`命令来查看已有的镜像列表:
```bash
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
myapp 1.0 c35af5ed3029 1 minute ago 313MB
ubuntu 18.04 4c108a37151f 2 weeks ago 64.2MB
```
接下来,我们可以使用`docker run`命令来运行容器:
```bash
$ docker run -d -p 80:80 myapp:1.0
```
其中,`-d`参数表示在后台运行容器,`-p`参数用来指定主机与容器之间的端口映射。
现在,我们可以通过浏览器访问`http://localhost`来查看运行中的Web应用程序了。
### 3.2 Docker容器的管理和扩展
Docker不仅可以创建容器,还提供了一系列的命令和工具来管理和扩展容器。在这一节中,我们将学习一些常用的Docker容器管理和扩展的技巧。
首先,我们可以使用`docker ps`命令来列出正在运行的容器:
```bash
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7967e283c0e6 myapp:1.0 "nginx -g 'daemon…" 5 minutes ago Up 5 minutes 0.0.0.0:80->80/tcp serene_davinci
```
可以看到,容器的ID、镜像名称、命令、创建时间、状态和端口映射等信息都被展示出来了。
如果需要查看所有的容器,包括正在运行和已停止的容器,可以使用`docker ps -a`命令。
接下来,我们可以使用`docker logs`命令来查看容器的日志信息:
```bash
$ docker logs serene_davinci
```
如果容器启动失败或出现问题,可以通过查看日志来找出问题所在。
此外,我们还可以使用`docker exec`命令在运行中的容器中执行命令:
```bash
$ docker exec -it serene_davinci bash
```
其中,`-it`参数表示在容器中启动一个交互式的终端。通过这个方式,我们可以在容器中执行命令、调试和修改配置等。
需要注意的是,每个Docker容器都是独立运行的,它们之间的文件系统和网络是隔离的。但是,如果需要容器之间进行通信,可以使用Docker的网络功能来连接它们。例如,可以创建一个Docker网络,并将多个容器连接到这个网络:
```bash
$ docker network create mynetwork
$ docker run -d --name container1 --network=mynetwork myapp:1.0
$ docker run -d --name container2 --network=mynetwork myapp:1.0
```
通过这种方式,容器之间就可以通过网络进行通信了。
### 3.3 Docker网络和存储管理
除了容器的管理和扩展,Docker还提供了丰富的网络和存储管理功能。在本节中,我们将学习一些常用的Docker网络和存储管理的技巧。
首先,我们可以使用`docker network`命令来管理Docker网络。例如,可以使用`docker network create`命令来创建一个新的网络:
```bash
$ docker network create mynetwork
```
创建完成后,可以使用`docker network ls`命令来列出已有的网络列表。
如果需要将容器连接到特定的网络,可以使用`docker network connect`命令:
```bash
$ docker network connect mynetwork container1
```
其中,`mynetwork`表示网络的名称,`container1`表示容器的名称。
此外,Docker还提供了一些内置的网络模式,例如`bridge`模式、`host`模式和`none`模式等。可以使用`docker run`命令的`--network`参数来指定容器的网络模式:
```bash
$ docker run -d --name container1 --network=bridge myapp:1.0
```
关于Docker的存储管理,我们可以使用`docker volume`命令来管理Docker卷。例如,可以使用`docker volume create`命令来创建一个新的卷:
```bash
$ docker volume create myvolume
```
创建完成后,可以使用`docker volume ls`命令来列出已有的卷列表。
如果需要将容器挂载到特定的卷上,可以使用`docker run`命令的`-v`参数来指定容器和卷的关联:
```bash
$ docker run -d --name container1 -v myvolume:/data myapp:1.0
```
其中,`myvolume`表示卷的名称,`/data`表示容器内的挂载点。
通过以上的网络和存储管理技巧,我们可以更加灵活地使用Docker来构建和管理应用程序。
### 3.4 Docker的安全性和监控
在使用Docker时,我们需要注意容器的安全性和监控。在本节中,我们将学习一些常用的Docker安全和监控的技巧。
首先,为了增强容器的安全性,我们可以使用Docker的用户命名空间功能来隔离容器的用户和进程。在创建容器时,可以使用`--userns`参数来指定用户命名空间的配置:
```bash
$ docker run -d --name container1 --userns=host myapp:1.0
```
其中,`host`表示使用主机的用户命名空间。
此外,在构建和使用Docker镜像时,我们应该尽量避免使用root用户。可以通过在Dockerfile中使用`USER`指令来切换用户:
```dockerfile
# 使用非特权用户运行容器
USER myuser
```
关于Docker的监控,我们可以使用一些第三方工具来帮助我们监控运行中的容器。例如,可以使用`cAdvisor`来监控容器的资源使用情况、运行状态和日志等:
```bash
$ docker run -d --name cadvisor --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 google/cadvisor:latest
```
运行完成后,可以通过访问`http://localhost:8080`来查看监控的界面。
除了`cAdvisor`,还有一些其他的Docker监控工具,例如`Prometheus`、`Grafana`和`ELK Stack`等。
通过以上的安全和监控技巧,我们可以更好地保障容器的安全性和稳定性。
在本章节中,我们学习了Docker的高级使用方法,包括镜像的创建和使用、容器的管理和扩展、网络和存储管理以及安全性和监控等方面的内容。通过这些技巧,我们可以更加灵活和高效地使用Docker来构建和管理应用程序。
在下一章节中,我们将学习Kubernetes的入门知识。敬请期待!
# 4. Kubernetes入门
Kubernetes是一个用于自动部署、扩展和管理容器化应用程序的开源平台。本章将介绍Kubernetes的概念、基本原理、核心组件、架构、安装配置以及常用操作。
#### 4.1 Kubernetes的概念和基本原理
Kubernetes是一个容器编排引擎,它可以跨多个主机来管理容器化的应用程序。Kubernetes通过一组集群节点来运行应用程序,并提供了自动化的容器操作、调度和管理功能。其基本原理是利用容器化技术,在集群中自动部署和管理应用程序。
#### 4.2 Kubernetes的核心组件和架构
Kubernetes的核心组件包括Master组件和Node组件。Master组件包括API Server、Scheduler、Controller Manager和etcd。Node组件包括Kubelet、Kube-Proxy和容器运行时。这些组件共同构成了Kubernetes的架构,在集群中协同工作,实现容器应用的管理和调度。
#### 4.3 安装和配置Kubernetes集群
安装Kubernetes集群需要先部署Master节点,然后在Node节点上加入集群。可以使用工具如kubeadm、kubespray等来简化部署流程。在配置Kubernetes集群时,需要关注网络插件、存储插件、认证授权等方面的配置。
#### 4.4 Kubernetes常用命令和操作
Kubernetes提供了丰富的命令行工具kubectl来与集群进行交互。常用操作包括创建/删除Pod、部署应用、扩展应用、管理服务、监控集群状态等。这些操作可以通过kubectl命令来完成,方便用户对集群进行管理和调度。
通过本章的内容,读者可以初步了解Kubernetes的概念、组件、架构以及基本操作,为进一步学习Kubernetes的高级使用打下基础。
# 5. Kubernetes的高级使用
Kubernetes作为一个容器编排和管理平台,除了基本的容器管理功能外,还提供了许多高级功能和特性,帮助用户更加灵活、高效地管理容器化应用。
#### 5.1 Pod和容器编排
在Kubernetes中,一个Pod可以包含一个或多个紧密关联的容器,它们共享网络和存储资源。通过Pod的调度和管理,可以实现容器之间的协同工作,比如共享数据卷、共享网络命名空间等功能。通过Kubernetes的容器编排功能,可以灵活地控制Pod的部署和调度,实现资源的高效利用和任务的自动化管理。
```python
# 示例代码:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: container1
image: nginx
ports:
- containerPort: 80
- name: container2
image: redis
ports:
- containerPort: 6379
```
*代码解释:* 上面的示例代码定义了一个包含两个容器的Pod,一个运行nginx,一个运行redis。这样就可以实现两个容器之间的协同工作。
#### 5.2 Service和负载均衡
Kubernetes中的Service可以将一组Pod组合成一个服务,提供统一的访问入口。通过Service,可以实现内部集群中Pod之间的服务发现和负载均衡,同时也提供了对外暴露服务的能力。Kubernetes通过Service的抽象层实现了对后端Pod实例的动态负载均衡,使得整个集群的服务更加稳定和高可用。
```java
// 示例代码:
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: LoadBalancer
```
*代码解释:* 上面的示例代码定义了一个Service,将标签为"myapp"的Pod组合成一个服务,并通过LoadBalancer类型的Service对外提供负载均衡的访问入口。
#### 5.3 Kubernetes的自动伸缩和滚动更新
Kubernetes提供了自动伸缩的功能,可以根据CPU利用率或自定义指标自动调整Pod实例的数量,以满足应用对资源需求的变化。同时,Kubernetes还支持滚动更新,可以逐步替换旧版本的Pod实例,确保应用的平稳升级和持续可用。
```go
// 示例代码:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: myapp:v2
```
*代码解释:* 上面的示例代码定义了一个Deployment,用于管理应用的多个副本,当更新镜像或应用版本时,Kubernetes会自动按照指定策略进行滚动更新。
#### 5.4 持久化存储和故障恢复
Kubernetes支持多种持久化存储方案,如PersistentVolume和PersistentVolumeClaim,可以为应用提供可靠的持久化存储能力。通过存储卷的动态绑定和复制,可以实现存储资源的动态调度和应用的故障自动恢复。
```js
// 示例代码:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
```
*代码解释:* 上面的示例代码定义了一个PersistentVolumeClaim,用于申请一个1Gi的持久化存储资源,并指定了读写模式为单次读写,确保Pod可以独占使用存储资源。
通过上述高级功能的使用,Kubernetes可以更好地支持容器化应用的生产部署和运维管理,帮助用户构建稳定、可靠的容器集群。
# 6. Docker与Kubernetes的比较和结合
在本章中,我们将探讨Docker和Kubernetes这两个容器技术之间的比较和结合使用方法。我们将详细介绍它们各自的优势和适用场景,同时也会讨论它们之间的共同点和区别。最后,我们还会展望Docker与Kubernetes的发展趋势和前景。
### 6.1 Docker和Kubernetes的优势和适用场景
Docker是一个轻量级的容器化平台,它具有以下优势和适用场景:
- 灵活性:Docker能够将应用程序和其依赖打包成一个独立的容器,可以在任何环境中运行,无需担心环境差异带来的问题。
- 高效性:Docker容器可以共享主机操作系统的内核,减少了资源消耗和启动时间,使得应用程序的部署和扩展更加迅速和高效。
- 可移植性:Docker容器可以在不同的主机和云平台上运行,保证了应用程序的可移植性和多样化部署选择。
- 可扩展性:Docker容器可以根据需求进行快速的水平扩展,从而满足应对高负载的需求。
Kubernetes是一个开源的容器编排平台,它具有以下优势和适用场景:
- 自动化管理:Kubernetes可以自动化地管理大规模的容器集群,提供了自动部署、水平伸缩、负载均衡等功能,大大简化了容器管理的复杂度。
- 可靠性和可用性:Kubernetes具备自动容错和自我修复的能力,能够保证应用程序的高可用性和可靠性,防止单点故障导致的应用中断。
- 弹性调度:Kubernetes可以根据应用程序的资源需求和约束条件,智能地进行容器的调度和分配,实现了资源的最优利用和负载均衡。
- 领先的生态系统:Kubernetes已经成为容器编排领域的事实标准,拥有庞大的社区和丰富的生态系统,提供了各种插件和工具来支持不同的应用场景。
### 6.2 Docker和Kubernetes的共同点和区别
尽管Docker和Kubernetes都属于容器技术,但它们有一些共同点和区别:
共同点:
- 都可以实现应用程序的容器化部署和管理。
- 都支持在不同的平台和环境中运行容器。
- 都具有高度的可扩展性和可靠性。
区别:
- Docker更为轻量级,适用于单个主机上的容器化部署和管理。而Kubernetes则适用于大规模的容器集群管理,并提供了更强大的自动化和调度功能。
- Docker更侧重于应用程序的打包和分发,而Kubernetes更强调容器编排和集群管理。
- Docker可以独立于Kubernetes使用,但Kubernetes需要依赖Docker作为其容器运行时环境。
### 6.3 如何结合使用Docker和Kubernetes
结合使用Docker和Kubernetes可以充分发挥它们的优势,实现高效的容器化部署和管理。一般的使用方法如下:
1. 使用Docker将应用程序打包成容器镜像,并上传到Docker仓库或私有仓库中。
2. 配置和启动Kubernetes集群。
3. 使用Kubernetes的命令和API创建和管理应用程序的Pod,将Docker容器运行在集群中。
4. 根据需要配置Kubernetes的服务和网络,提供负载均衡和访问控制。
5. 使用Kubernetes的自动伸缩和滚动更新功能,根据应用程序的需求进行弹性调整和版本更新。
6. 监控和管理Kubernetes集群,保证应用程序的可用性和安全性。
### 6.4 Docker与Kubernetes的发展趋势和前景展望
Docker和Kubernetes作为容器技术的代表,目前已经得到了广泛的应用和认可。未来的发展趋势和前景展望如下:
- 社区变得更加活跃:Docker和Kubernetes拥有庞大的社区支持,未来社区将会更加活跃,提供更多的解决方案和插件来支持不同的应用场景。
- 容器技术的标准化:随着容器技术的发展,相关的标准和规范将会逐渐成熟,使得容器技术更加标准化和通用化。
- 容器化的普及和广泛应用:越来越多的企业和组织将采用容器技术,实现应用程序的容器化部署和管理,从而提高开发、测试和生产环境的效率和可靠性。
总之, Docker和Kubernetes作为容器技术的代表在当前的云计算和微服务时代扮演着重要角色,它们的结合使用将为软件开发和应用部署带来巨大的便利和效益。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《管理信息系统开发》涵盖了信息系统开发过程中的各个关键领域和技术。从数据库设计与创建,到SQL语句的使用与查询,再到数据库索引与性能优化,读者将能够全面了解并掌握数据存储与管理的基础知识。接着,我们将深入讨论数据仓库与数据挖掘、ETL技术与数据集成,以及关系型数据库与NoSQL数据库的对比,帮助读者在实际应用中做出合理的选择。在Web开发方面,我们将介绍HTML与CSS的基础知识,讨论JavaScript的交互性设计,以及React和Vue这两个常用的前端开发框架的比较。此外,我们还将介绍Node.js的基础知识以及RESTful API的设计与开发。同时,我们将讨论数据库和Web应用的安全性问题,并介绍电子商务网站开发技术以及移动应用开发的入门和进阶知识。最后,我们将深入探讨分布式系统原理、微服务架构、容器技术以及大数据技术和人工智能基础中的机器学习算法。本专栏旨在帮助读者全面理解和掌握管理信息系统开发的各个方面,提供实用的技术指导和实践经验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
企业价值评估策略:德勤价值地图高级应用,优化企业价值最大化的决策

# 摘要
企业价值评估是理解和促进企业长期成功的重要工具。本文从理论基础出发,深入探讨了德勤价值地图的结构、关键成功因素以及在不同行业中的应用,同时分析了量化分析技术在数据收集和财务模型中的运用。实践操作部分详细介绍了企业内部评估流程、评估模型构建以及评估结果的应用。在企业
单片机中断管理的3个高级技巧:解锁系统性能的秘密武器

# 摘要
单片机中断管理是嵌入式系统设计的关键技术之一,涉及中断优先级设定、中断嵌套处理、中断服务程序设计与优化,以及资源冲突的预防和中断同步问题。本文对中断管理进行了全面的概述,详细分析了中断优先级的理论基础、中断嵌套的实现和限制、中断服务程序的设计准则和低功耗模式的协同工作。进一步探讨了中断管理中的资源冲突和同步问题,以及在实时操作系统中的中断管理策略和高级应用技巧。通过案例分析,本文阐述了这些理论和策略在实际项目
深入iSecure Center:高级功能实操与应用指南

# 摘要
本文全面介绍了iSecure Center的安全管理平台,阐述了其核心优势、基础操作、高级功能以及集成与扩展能力。通过对用户界面的定制、资产的管理、风险评估工具的使用,展示了iSecure Center在提升企业信息安全方面的基础操作。进一步地,文章探讨了如何利用iSecure Center实现定制化监控、自动化响应和高级报告,以及合规性检查,增强了系统的实
嵌入式系统实战:轻松实现Modbus_RTU CRC校验
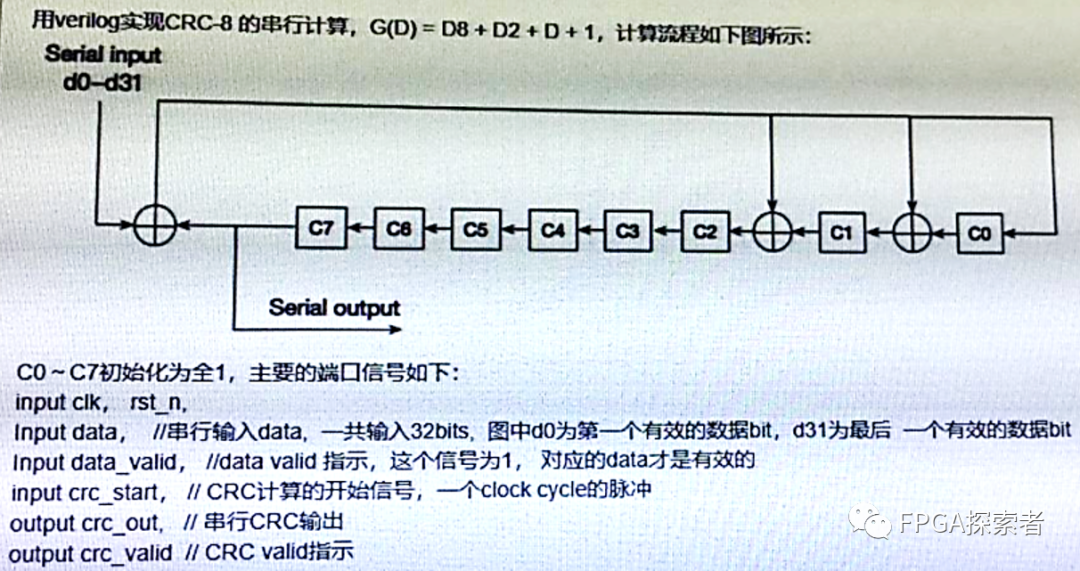
# 摘要
本文系统地分析了Modbus协议及其RTU模式,并详细解读了CRC校验算法的原理和实现方法。通过介绍CRC在嵌入式系统中的计算方式和代码实现,本文展示了如何在Modbus_RTU通信中集成CRC校验,以及如何进行优化和调试以提升性能。在案例分析章节,探讨了Modbus协议在物联网中的应用前景,以及嵌入式系统中的扩展应用和跨平台通信实现。文章为开发者提供了深入理解Modbus协议和C
【XP系统升级秘籍】:开启AHCI模式的10个步骤,释放硬盘潜能
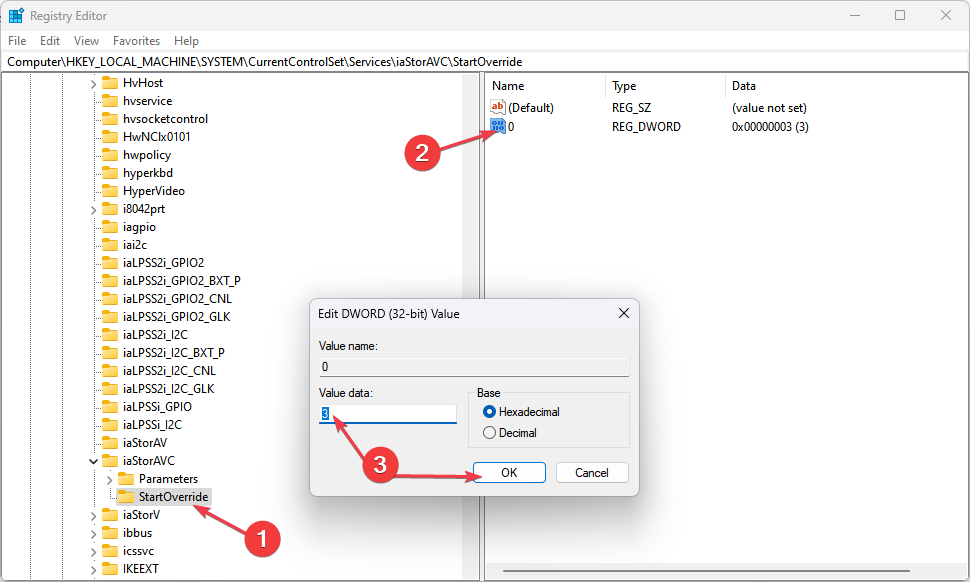
# 摘要
本文首先介绍了AHCI模式在XP系统中的概念和优势,详细阐述了该模式的工作原理,并与IDE模式进行了比较分析。随后,本文提供了开启XP系统AHCI模式的详细步骤,包括BIOS设置调整、系统安装盘准备和使用,以及驱动程序更新与系统配置。在此基础上,文章进一步探讨了在AHCI模式下进行硬盘管理与优化的策略,包括性能监控、系统和驱动程序的定期更新,以及故障排
【深入解析Excel公式】:身份证号码中年龄的自动计算方法
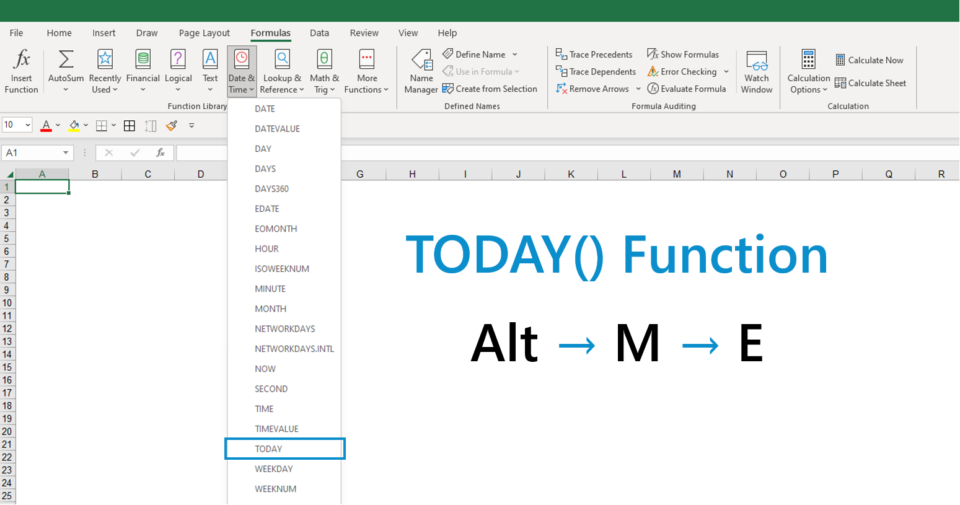
# 摘要
本文旨在提供一个详尽的指南,以在Excel环境中解析和计算身份证号码中的年龄信息。文章首先介绍了身份证号码的基本信息和结构,接着详细阐述了使用Excel公式进行身份证号码解析和年龄计算的基本方法和技巧。在此基础上,本文进一步讨论了年龄计算公式的高级应用和优化,包括如何处理跨年度更新、增强公式的通用性及错误处理。最后,文章展望了Excel公式在年
【H3C-CAS-Converter问题解决全书】:常见问题与最佳解决方案

# 摘要
本文全面介绍了H3C-CAS-Converter的特性、安装与配置、常见问题诊断、高级功能应用,以及监控与维护。首先概述了 Converter 的基本功能和应用场景,接着详细描述了从安装前的准备到安装步骤和配置指南,确保用户可以顺利完成产品部署。针对用户可能遇到的网络、系统兼容性、性能和安全问题,本文提供了详细的诊断和解
【IBM Power服务器性能调优】:AIX 6.1案例研究的性能飞跃

# 摘要
随着技术进步,AIX 6.1作为IBM Power服务器的核心操作系统,其系统监控和性能调优策略变得日益重要。本文对AIX 6.1系统监控基础进行概述,并深入探讨了优化CPU、内存以及磁盘I/O性能的关键策略。通过案例分析,提供了针对大型数据库服务器和高并发Web应用服务器的性能调优实践。此外,文章还涵盖了高级性能优化技术,包括在虚拟化环境下的性能管理和自动性能调整工具的应用,旨在建
【人群模拟高手】Lumion 12 Pro高效创建与管理人群动态

# 摘要
Lumion 12 Pro是当前流行的建筑可视化软件,其人群模拟功能为设计师提供了强大的工具以创建真实感强的人群场景。本文首先介绍了Lumion 12 Pro的基本功能和人群模拟的基础理论与实践,包括人群行为心理学和动态模拟的物理基础。随后,探讨了高级技巧,例如控制人群密度、流量以及构建复杂场景的能力,并着重于实时人群反馈与优化。文章进一步通过实际案例
图像形态学操作详解:期末复习形状与结构处理术(形态学操作一学就会)

# 摘要
图像形态学是数字图像处理的重要领域,它涉及到图像的结构特征及其变换。本文系统地阐述了图像形态学的基本概念、理论基础和算法实现,以及在实践中的应用。通过分析形态学操作中的基本操作原理,如腐蚀、膨胀、开运算和闭运算,以及形态变换的数学描述,本文深入探讨了结构元素的选择、形态变换的集合
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )