Git 常见问题解答与故障排除
发布时间: 2024-01-02 21:49:31 阅读量: 59 订阅数: 24 

Ryuuganime-Nightly:实际网站测试和故障排除的存储库
# 1. Introduction
## 1.1 What is Git?
Git is a distributed version control system that allows developers to track changes in their codebase. It was created by Linus Torvalds in 2005 and has since become one of the most popular version control systems in the software development industry.
## 1.2 Why is Git popular?
There are several reasons why Git has gained widespread popularity among developers:
- **Distributed Architecture**: Git allows developers to work on their projects offline and independently. Each developer maintains their own local copy of the codebase, which they can commit changes to. These commits can later be synchronized with a central repository or shared with other team members.
- **Efficient and Fast**: Git is designed to be efficient and fast, even with large codebases. It uses advanced techniques such as delta compression and branch management to optimize performance.
- **Branching and Merging**: Git makes it easy to create branches and merge changes. This allows developers to work on new features or bug fixes in isolation without affecting the main codebase. Branches can be merged back into the main branch when the changes are ready.
- **Collaboration**: Git provides tools for collaboration and code review. Multiple developers can work on the same project simultaneously and merge their changes together. Git also allows for easy code sharing and contribution from external contributors.
- **Strong Community Support**: Git has a large and active community of developers who contribute to its development and provide support. This ensures that Git is continuously improved and updated with new features and bug fixes.
In the following sections, we will explore how to set up a Git environment, learn the basics of Git, address common problems and solutions, master advanced techniques, and discuss best practices and troubleshooting tips.
## 2. Setting up Git Environment
Before you can start using Git, you need to set it up on your computer. This involves installing Git and configuring it with your personal information.
### 2.1 Installing Git
To install Git, follow the steps below:
#### Windows
1. Visit the official Git website: [https://git-scm.com/downloads](https://git-scm.com/downloads).
2. Download the appropriate installer for your Windows version.
3. Run the installer and follow the installation wizard.
4. Select the desired components to install (leave the default options if you're unsure).
5. Choose the default editor for Git (e.g., Notepad, Vim) or select "Use Git Bash only" if you prefer using the command line.
6. Select the appropriate line-ending conversion options (leave the default options if you're unsure).
7. Choose the default branch name (leave it as "master" unless you have a specific reason to change it).
8. Configure the Git PATH environment (we recommend choosing the default option to avoid conflicts).
9. Choose the desired SSH executable (choose "Use OpenSSH" unless you have a specific reason to use a different SSH client).
10. Configure line ending behaviors (leave the default options if you're unsure).
11. Choose the desired terminal emulator (leave the default option unless you have a specific preference).
12. Configure extra options (leave the default options unless you have specific requirements).
13. Click "Install" to begin the installation process.
14. Once the installation is complete, click "Finish" to exit the installer.
#### macOS
1. Visit the official Git website: [https://git-scm.com/downloads](https://git-scm.com/downloads).
2. Download the macOS version suitable for your operating system.
3. Open the downloaded DMG file.
4. Double-click the "Git" icon to start the installer.
5. Follow the installation wizard and provide your administrator password when prompted.
6. Select the components you want to install or leave the default options.
7. Choose the default text editor for Git (e.g., Vim) or select "Use Git's default editor" if you're unsure.
8. Configure the PATH environment by selecting the terminal app to use (choose the default option or specify a different terminal app if you prefer).
9. Select the HTTPS transport backend (choose the default option unless you have specific requirements).
10. Configure line ending conversions (leave the default options).
11. Configure the terminal emulator to use (leave the default options unless you have specific requirements).
12. Choose the default behavior for Git pull (leave the default option unless you have a specific reason to change it).
13. Configure extra options as needed.
14. Click "Install" to begin the installation process.
15. Once the installation is complete, click "Finish" to exit the installer.
#### Linux (Ubuntu)
1. Open the terminal on your Linux distribution.
2. Run the following command to install Git:
```
sudo apt install git
```
3. Provide your user password when prompted and wait for the installation to complete.
Note: The installation process may differ depending on your Linux distribution. Please refer to the official documentation for your specific distribution if the above steps do not work.
### 2.2 Configuring Git
After installing Git, you need to configure it with your name and email address. Open the terminal (Git Bash for Windows) and run the following commands, replacing "Your Name" and "your.email@example.com" with your actual name and email address:
```
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"
```
These configurations are important because Git records the author of each commit.
You can also configure other settings, such as your preferred text editor and color output. For more information, refer to the Git documentation.
Once Git is installed and configured, you are ready to start using it. In the next chapter, we will cover the basics of Git, including creating a new repository, cloning an existing repository, and the fundamental Git workflow.
### 3. Git Basics
Git is a powerful and versatile version control system that is widely used in software development. In this section, we will explore some of the basic operations and commands in Git, which are essential for managing and working with repositories.
#### 3.1 Creating a new repository
To create a new Git repository, you can navigate to the desired directory in your terminal and use the following command:
```bash
$ git init
```
This command initializes a new Git repository, which enables version control for the files within that directory. Once the repository is created, you can start adding files, committing changes, and managing the project's history.
#### 3.2 Cloning an existing repository
If you want to work with an existing Git repository that is hosted remotely, you can clone it to your local machine using the `git clone` command. For example, to clone a repository from GitHub, you can use the following command:
```bash
$ git clone <repository_URL>
```
Replace `<repository_URL>` with the actual URL of the repository you want to clone. This command creates a copy of the remote repository on your local machine, allowing you to work on the project and collaborate with others.
#### 3.3 Git workflow (add, commit, push, pull)
The typical workflow in Git involves adding changes to the staging area, committing them to the repository, and sharing those changes with other collaborators. Here's a brief overview of these essential operations:
- **Add**: Use the `git add` command to stage changes for the next commit. For example, to add all changes in the current directory, you can use:
```bash
$ git add .
```
- **Commit**: Once changes are staged, you can commit them to the repository along with a descriptive message using the `git commit` command:
```bash
$ git commit -m "Add new feature implementation"
```
- **Push**: If you have made commits to your local repository and want to share those changes with a remote repository (e.g., on GitHub), you can use the `git push` command:
```bash
$ git push origin main
```
- **Pull**: To incorporate changes from a remote repository into your local repository, you can use the `git pull` command. This is particularly useful when working with a team, as it helps keep your local repository up to date with the latest changes made by others.
These basic Git operations form the foundation of collaborative and version-controlled software development workflows. Mastering them is crucial for efficient project management and code collaboration.
### 4. Common Git Problems and Solutions
Git is a powerful tool, but it's not immune to problems. In this section, we'll explore some common Git problems that developers may encounter and provide solutions to resolve them.
#### 4.1 Merge conflicts and how to resolve them
Merge conflicts occur when two separate branches have changes that cannot be automatically merged. To resolve a merge conflict, follow these steps:
1. Identify the conflicted files by running `git status`.
2. Open the conflicted file(s) and look for the conflict markers `<<<<<<<`, `=======`, and `>>>>>>>`.
3. Manually edit the conflicted file(s) to resolve the differences.
4. Stage the resolved files using `git add <filename>`.
5. Commit the changes with `git commit`.
#### 4.2 Git reset vs. Git revert
`git reset` and `git revert` are both used to undo changes in a repository, but they work in different ways. Here's a brief overview:
- `git reset`: This command is used to reset the staging area to the most recent commit, leaving the working directory unchanged. It's important to be cautious when using `git reset` as it can discard uncommitted changes.
- `git revert`: Revert creates a new commit that undoes the changes made by a specific commit. It's a safe way to undo changes that have already been pushed to a shared repository.
#### 4.3 Recovering deleted files using Git
If a file has been accidentally deleted in a Git repository, it can often be recovered using the following steps:
1. Check the commit history using `git log -- <deleted_file_path>` to find the commit where the file was deleted.
2. Use `git checkout <commit_hash> -- <deleted_file_path>` to restore the deleted file from the specific commit.
By following these steps, you can recover the deleted file from the Git repository's history.
### 5. Advanced Git Techniques
Git is a powerful tool that offers advanced techniques for managing your codebase and collaborating with others. In this section, we'll explore some of the advanced Git techniques that can help you take your version control skills to the next level.
#### 5.1 Branching and Merging Strategies
In Git, branching and merging are integral to managing complex development workflows. Here, we'll discuss some common branching and merging strategies that teams use to streamline their development processes.
##### Branching Strategies
Different branching strategies serve various purposes, such as feature development, hotfixes, release management, and more. Some popular branching models include:
- **Feature Branching**: Each new feature is developed in a dedicated branch, allowing for isolated development and easy integration into the main codebase.
- **Gitflow Workflow**: This model defines a strict branching model designed around the project release. It promotes parallel development, collaboration, and release management.
##### Merging Strategies
Git offers several merging strategies to integrate changes from one branch into another. The commonly used options are:
- **Fast-forward Merge**: When the current branch's tip is an ancestor of the other branch, Git performs a fast-forward merge, simply moving the current branch's pointer forward.
- **Recursive Merge**: This is the default merge strategy in Git, which handles merges by recalculating the common base between the two branches.
#### 5.2 Git Stash: Saving and Applying Changes
Git stash is a powerful feature that allows developers to save changes with an option to apply them later. Let's walk through a scenario where using Git stash can be beneficial:
```bash
# Assume you are in the middle of working on a feature and need to switch to another task
$ git stash # Stash the current changes
$ git checkout main # Switch to the main branch to work on a hotfix or another feature
$ git stash apply # Apply the stashed changes to continue where you left off
```
Here's a breakdown of the commands used in the above scenario:
- `git stash`: This command stashes the current changes, reverting the working directory to the state of the last commit.
- `git checkout main`: Switches to the main branch to work on a different task.
- `git stash apply`: Applies the stashed changes from the previous task onto the current working directory.
#### 5.3 Rewriting Commit History using Git Rebase
Git rebase is a powerful tool for rewriting commit history. It allows developers to reapply a series of changes on top of another branch, effectively altering the commit history.
Here's a common use case for Git rebase:
Suppose you have a feature branch with multiple small commits, and you want to tidy up the history before merging it into the main branch. You can use interactive rebase to squash, reword, reorder, or edit commits:
```bash
# Interactively rebase the last 5 commits on the current branch
$ git rebase -i HEAD~5
```
In this scenario, the `-i` flag stands for "interactive," allowing you to interactively choose how to rewrite the commits. This opens a text editor where you can specify the actions to perform for each commit.
When leveraging Git rebase, it's crucial to communicate with your team to avoid potential conflicts when rewriting shared history.
By mastering these advanced Git techniques, you can enhance your version control capabilities and work more efficiently within your development team.
第六章:Best Practices and Troubleshooting
### 6.1 Git tagging and versioning
Git tagging is a useful feature for marking important points in the commit history. It allows you to create a named reference to a specific commit. Tagging is commonly used for marking version releases or important milestones in a project. This section will cover how to create tags and how to manage versions in Git.
#### 6.1.1 Creating tags
To create a tag in Git, you can use the `git tag` command followed by the tag name. By default, Git creates a lightweight tag, which is simply a reference to a specific commit. For example, to create a lightweight tag for the current commit, you can use:
```bash
$ git tag v1.0
```
You can also create an annotated tag, which includes additional information such as the tagger's name, email, date, and a message. Annotated tags are recommended for important version releases. To create an annotated tag, you can use the `-a` flag followed by the tag name. Git will open your default text editor for you to enter the tag message:
```bash
$ git tag -a v1.0 -m "Release version 1.0"
```
#### 6.1.2 Listing tags
To view the list of tags in your repository, you can use the `git tag` command without any arguments:
```bash
$ git tag
v1.0
v2.0
```
By default, tags are listed in lexicographic order based on their names. You can also use the `--list` option to filter the tags based on a pattern. For example, to list all tags starting with "v1", you can use:
```bash
$ git tag --list 'v1*'
v1.0
v1.1
v1.2
```
#### 6.1.3 Checking out tags
To switch to a specific tag, you can use the `git checkout` command followed by the tag name. This will detach your HEAD and put you in a "detached HEAD" state, which means you are no longer on a branch. For example, to checkout the "v1.0" tag, you can use:
```bash
$ git checkout v1.0
```
If you want to create a branch from a tag, you can use the `git checkout` command with the `-b` option followed by the new branch name. For example, to create a branch named "release-1.0" from the "v1.0" tag, you can use:
```bash
$ git checkout -b release-1.0 v1.0
```
#### 6.1.4 Versioning with tags
Tags are commonly used for versioning in Git. Typically, the format of version tags follows a semantic versioning scheme (e.g., "v1.0.0"). Semantic versioning consists of three parts: MAJOR.MINOR.PATCH. Incrementing the MAJOR version indicates incompatible changes, the MINOR version indicates new features without breaking backward compatibility, and the PATCH version indicates bug fixes.
When creating version tags, it's important to follow a consistent naming convention and adhere to the semantic versioning guidelines. This makes it easier for users and collaborators to understand the impact of different versions and choose the appropriate version for their needs.
### 6.2 Managing Git repositories with multiple collaborators
Collaborating on a Git repository with multiple contributors can be challenging without proper coordination and communication. This section will cover some best practices for managing Git repositories with multiple collaborators.
#### 6.2.1 Workflow for multiple collaborators
To ensure smooth collaboration, it's important to establish a clear workflow for multiple contributors. One common approach is to use branches for different features or bug fixes, and merge them into a main branch (e.g., "master" or "develop") when ready. Here are the steps for a typical collaborative workflow:
1. Each contributor creates a branch from the latest state of the main branch.
2. Contributors work independently in their branches, committing their changes frequently and pushing them to the remote repository.
3. When a contributor completes a task or fix, they create a pull request or merge request to propose their changes to be merged into the main branch.
4. Other contributors review the changes, provide feedback, and discuss any necessary modifications.
5. Once the changes are approved, they are merged into the main branch.
6. Contributors regularly update their branches with the latest changes from the main branch to avoid conflicts.
#### 6.2.2 Collaborator access and permissions
It's important to manage collaborator access and permissions to protect the integrity and confidentiality of the repository. Git hosting platforms (e.g., GitHub, GitLab, Bitbucket) provide granular access control features to manage collaborators effectively. These platforms allow repository owners to control read and write access, create teams with different permissions, and manage branch protection rules to prevent accidental or unauthorized changes.
It's recommended to follow the principle of least privilege when granting access to collaborators. Only provide the necessary permissions for collaborators to perform their tasks, and regularly review and revoke access when it is no longer needed.
#### 6.2.3 Communication and conflict resolution
Effective communication is crucial for successful collaboration. Collaborators should use tools like issue trackers, project boards, and chat platforms to discuss and coordinate their work. This helps to avoid duplicated efforts, resolve conflicts, and keep everyone in sync.
In case of conflicts during code merges, it's important to follow the appropriate conflict resolution strategies. Collaborators should communicate and work together to resolve conflicts, either manually by editing the conflicting sections or by using automated merging tools. Regularly updating and synchronizing with the main branch reduces the chances of conflicts and simplifies the merging process.
### 6.3 Troubleshooting common Git errors and warnings
Git is a powerful tool, but it can sometimes throw errors or warnings that need to be resolved. This section will cover some common Git errors and warnings that you may encounter, along with their solutions.
#### 6.3.1 Error: "fatal: refusing to merge unrelated histories"
This error occurs when you try to merge two branches that have unrelated commit histories. To resolve this, you can add the `--allow-unrelated-histories` flag to the merge command:
```bash
$ git merge branch-name --allow-unrelated-histories
```
#### 6.3.2 Warning: "LF will be replaced by CRLF"
This warning indicates that you have inconsistent line endings in your repository. Git has detected a mix of LF (Unix-style) and CRLF (Windows-style) line endings. To resolve this, you can configure Git to automatically convert line endings when checking out and committing files:
```bash
$ git config --global core.autocrlf true
```
#### 6.3.3 Error: "The current branch has no upstream branch"
This error occurs when you try to push a branch that doesn't have an upstream branch set. To set the upstream branch, you can use the `--set-upstream` or `-u` flag with the push command:
```bash
$ git push --set-upstream origin branch-name
```
These are just a few examples of common Git errors and warnings. It's important to understand the error messages and consult Git documentation or online resources for specific solutions when encountering unfamiliar issues.
总结:
在本章中,我们学习了Git标签和版本控制的最佳实践。我们了解了如何创建轻量级标签和注释标签,以及如何查看和切换标签。我们还了解了多个协作者管理Git仓库的工作流程,讨论了权限管理和冲突解决策略。最后,我们介绍了一些常见的Git错误和警告,以及它们的解决方法。
通过遵循最佳实践和处理常见问题,您可以更好地利用Git的功能,并确保项目的版本控制和协作顺利进行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏围绕git操作展开,内容涵盖了从初识git、安装与配置,到创建第一个仓库,添加与提交文件,分支管理,远程仓库共享,解决代码冲突,项目发布准备,撤销更改,文件忽略,团队协作等方面的详细介绍。此外,还包括高级分支管理技术,远程操作,Git实用技巧以及常见问题解答与故障排除等内容。专栏还将介绍Git GUI工具的使用,适应不同项目需求的Git工作流程,深入理解Git的原理与底层数据结构,以及版本回退与恢复的操作。无论初学者还是有经验的开发者,都能从中获得关于Git操作的全面指导和实用技巧,有助于提高开发效率和解决各种代码管理与版本控制问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
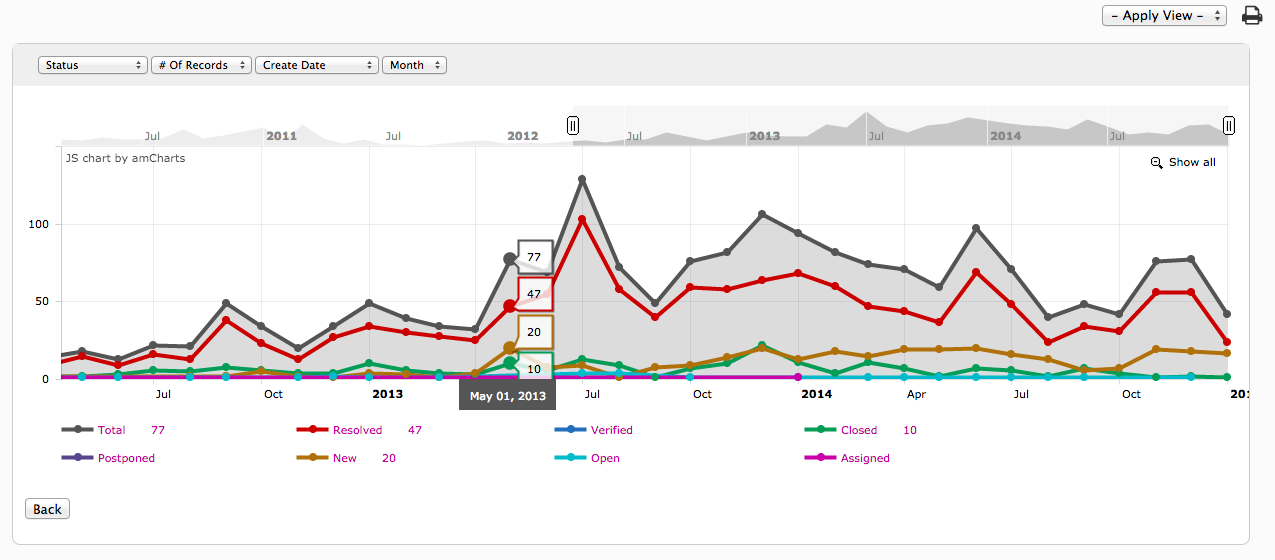
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
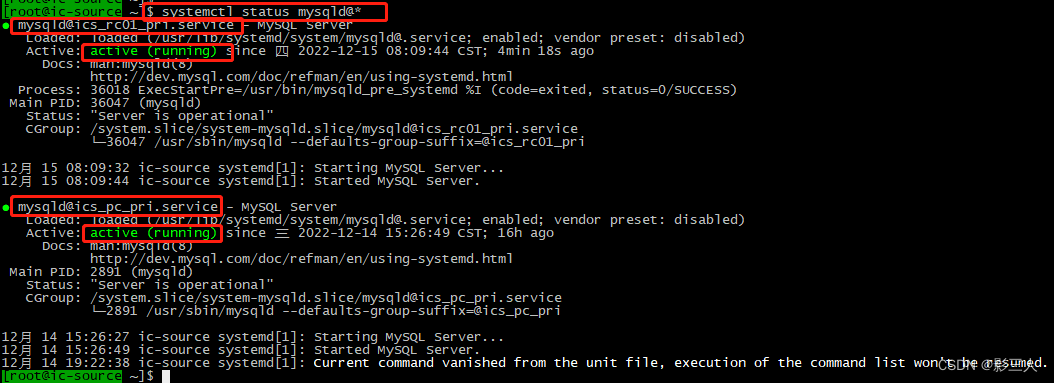
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
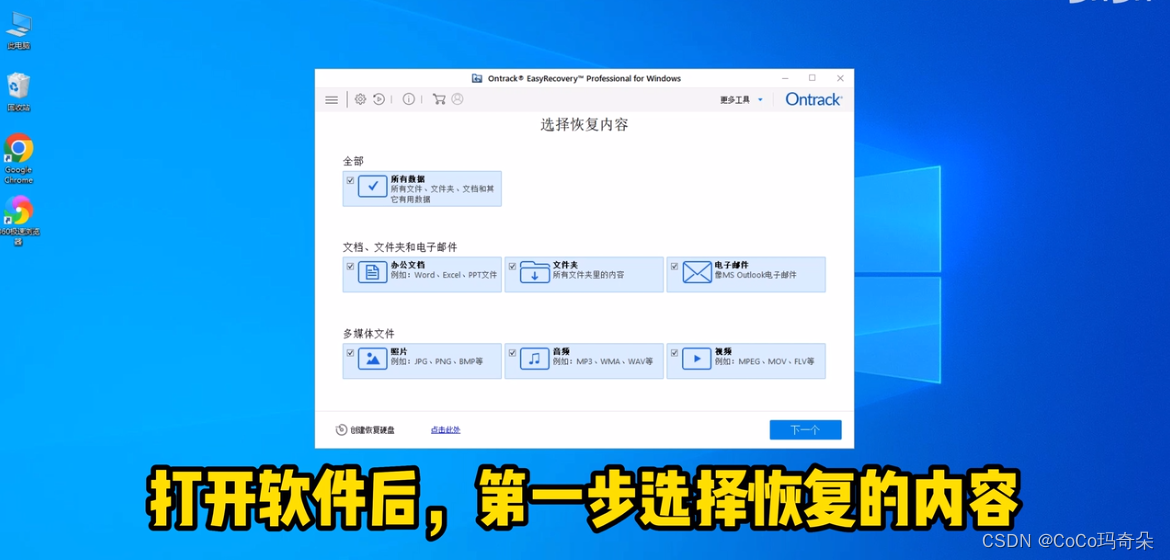
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
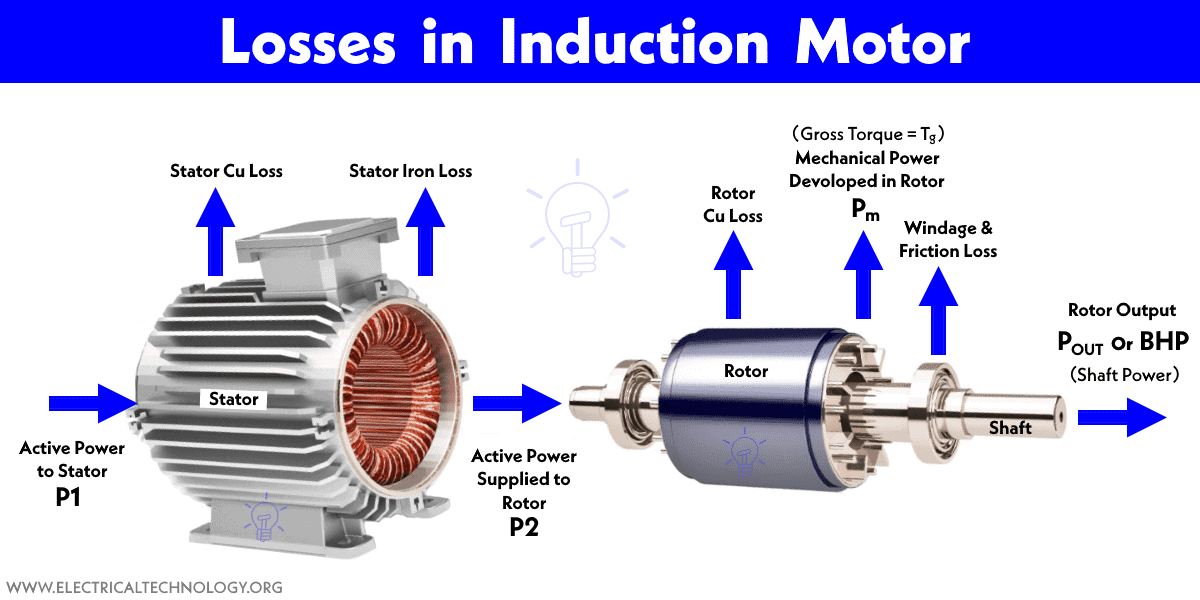
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )