SCL故障排除手册:快速定位与问题解决的技巧
发布时间: 2024-12-02 21:25:42 阅读量: 31 订阅数: 30 

LM75温湿度传感数据手册
参考资源链接:[西门子PLC SCL编程指南:指令与应用解析](https://wenku.csdn.net/doc/6401abbacce7214c316e9485?spm=1055.2635.3001.10343)
# 1. SCL故障排除的基本概念与原理
## 1.1 故障排除的重要性
故障排除是确保系统稳定运行的关键环节。对于SCL(System Configuration Language)环境下的故障排除,其重要性不仅在于解决即时的问题,更在于深入理解系统的架构和潜在的风险点,以便于在未来的工作中预防类似的问题再次发生。
## 1.2 SCL故障排除的基本原理
SCL故障排除涉及对系统配置、代码、网络连接及数据处理等多个方面的深入分析。其基本原理是通过观察系统的异常行为来诊断问题的根源,随后采取相应措施进行修复。理解这一原理能帮助IT专家系统性地识别问题,高效地解决问题。
## 1.3 故障排除的步骤概述
故障排除的步骤通常包括识别问题、收集相关信息、分析故障原因、制定解决方案以及验证问题是否已被解决。在SCL环境中,这些步骤需要结合特定的工具和方法,如SCL日志分析、性能监控等,以确保故障被准确而有效地排除。
# 2. SCL故障诊断工具与方法
## 2.1 SCL日志分析技巧
### 2.1.1 日志文件的重要性
日志文件在SCL(Structured Control Language)故障排除中扮演着至关重要的角色。它们是跟踪系统行为、诊断问题和监控性能的关键信息来源。日志文件能够记录程序运行时的详细活动,包括系统初始化、服务启动和停止以及错误和警告信息。
对日志文件的深入分析可以揭示故障的根本原因,帮助IT专业人员快速定位问题,并进行有效的故障排除。此外,定期的日志分析对于系统安全性的维护也同样重要,因为它们可能包含安全漏洞的迹象或是未授权访问的记录。
### 2.1.2 解读SCL日志文件
解读SCL日志文件首先需要理解日志中使用的特定术语和编码。通常,日志文件包含时间戳、日志级别(如信息、警告、错误等)、消息源、事件描述等关键信息。
例如,一条典型的错误日志条目可能包含如下信息:
```log
[2023-03-27 14:45:02] ERROR: [UserModule] Failed to process input file '/home/user/input.txt': File not found.
```
此日志信息表明在2023年3月27日14时45分2秒,UserModule模块尝试处理一个输入文件时失败了,原因在于文件未找到。
### 2.1.3 利用日志进行故障定位
故障定位过程中,首先要寻找与特定问题相关的日志条目。通常情况下,可以使用关键字搜索或日志级别过滤来缩小问题范围。例如,若要定位与网络问题相关的错误,可以搜索关键字"network"并关注ERROR级别以上的日志。
```bash
grep "ERROR.*network" /var/log/scl.log
```
该命令会搜索位于`/var/log/`目录下`scl.log`文件中所有包含"network"关键字的ERROR级别日志条目。通过这种方式,可以快速找到可能指向问题源头的线索。
## 2.2 SCL性能监控工具
### 2.2.1 监控工具的选择与安装
选择合适的性能监控工具是确保SCL系统稳定运行的关键步骤。市场上有多种开源和商业监控工具可供选择,包括但不限于Nagios、Zabbix、Prometheus和Grafana。
以Prometheus和Grafana为例,它们是开源解决方案,常用于监控SCL系统的性能。安装这些工具之前,应该根据SCL系统的特点和监控需求进行评估。安装通常涉及以下步骤:
1. 下载并安装Prometheus服务端。
2. 配置Prometheus以收集SCL系统的性能指标。
3. 安装Grafana并设置数据源以连接到Prometheus。
4. 配置Grafana面板和仪表盘以显示监控数据。
### 2.2.2 关键性能指标的监控
监控SCL系统的性能时,应关注几个关键指标,比如CPU使用率、内存消耗、I/O操作、进程状态和响应时间。这些指标对于检测系统瓶颈和潜在问题至关重要。
以下是一个示例脚本,用于定期收集CPU和内存使用率:
```bash
#!/bin/bash
# 获取CPU使用率
cpu_usage=$(top -bn1 | grep "Cpu(s)" | sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | awk '{print 100 - $1"%"}')
# 获取内存使用率
mem_usage=$(free -m | awk 'NR==2{printf "%.2f%%", $3*100/$2 }')
echo "CPU usage: $cpu_usage"
echo "Memory usage: $mem_usage"
```
该脚本可以设置为cron作业定期运行,以便于收集和记录历史数据,进而分析系统负载趋势。
### 2.2.3 监控数据的分析与应用
采集到的监控数据需要通过适当的分析来实现其应用价值。这包括但不限于:
- 数据可视化:使用Grafana创建图表和仪表盘,让关键性能指标可视化。
- 趋势分析:分析监控数据随时间的变化趋势,以便于识别潜在的性能问题。
- 报警配置:设置阈值,当系统性能指标超出正常范围时,接收实时警告通知。
## 2.3 网络分析与故障点定位
### 2.3.1 网络流量分析工具介绍
网络故障排除的第一步通常是使用网络流量分析工具来查看SCL系统与网络的交互。工具如Wireshark是一个强大的网络协议分析器,能够捕获并分析实时网络流量。
使用Wireshark的步骤可能包括:
1. 启动Wireshark并选择对应的网络接口。
2. 开始捕获数据包。
3. 使用过滤器来缩小数据包的范围,专注于SCL系统产生的流量。
4. 分析数据包的详细信息,寻找问题的迹象。
### 2.3.2 故障点的快速发现方法
在流量分析之后,故障点的快速发现通常需要对捕获

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《博图SCL手册》专栏是一个全面的指南,涵盖了博图SCL编程语言的各个方面,从入门基础到高级技巧。专栏文章深入探讨了常见的错误诊断、性能提升秘诀、自动化部署技术、脚本性能优化、数据库交互、物联网应用、版本控制、单元测试和文档编写等主题。本专栏旨在帮助读者全面掌握SCL编程,提升系统性能,并构建高效、可靠的自动化解决方案。无论是新手入门还是专家进阶,都可以从专栏中找到有价值的信息和实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【WPF与Modbus通信】:C#新手必学的串口通讯入门秘籍(附实战项目搭建指南)
# 摘要
本文旨在探讨WPF(Windows Presentation Foundation)与Modbus通信协议的集成应用。第一章概述了WPF与Modbus通信的背景与重要性。第二章详细介绍了WPF的基础知识、界面设计、数据绑定技术及其项目结构管理。第三章则深入解析了Modbus协议的原理、通信实现方式及常见问题。在第四章,本文着重讲述了如何在WPF应用中集成Modbus通信,包括客户端与服务器的搭建和测试,以及通信模块在实战项目中的应用。最后一章提供了实战项目的搭建指南,包括需求分析、系统架构设计,以及项目实施过程的回顾和问题解决策略。通过本研究,旨在为开发人员提供一套完整的WPF与Mo
随波逐流工具深度解析:CTF编码解码的高级技能攻略(专家级教程)
# 摘要
本文全面探讨了CTF(Capture The Flag)中的编码解码技术基础与高级策略。首先介绍了编码解码的基本概念和机制,阐述了它们在CTF比赛中的应用和重要性,以及编码解码技能在其他领域的广泛使用。接着,本文深入解析了常见编码方法,并分享了高级编码技术应用与自动化处理的技巧。第三章讲述了编码算法的数学原理,探索了新思路和在信息安全中的角色。最后一章探讨了自定义编码解码工具的开发和提高解码效率的实践,以及设计复杂挑战和验证工具效果的实战演练。
# 关键字
CTF;编码解码;编码算法;信息安全;自动化处理;工具开发
参考资源链接:[随波逐流CTF编码工具:一站式加密解密解决方案]
银河麒麟V10系统与飞腾CPU的交云编译Qt5.15入门指南

# 摘要
本论文深入探讨了银河麒麟V10系统与飞腾CPU结合使用Qt5.15框架进行交叉编译的过程及其实践应用。首先概述了银河麒麟V10系统架构和飞腾CPU的技术规格,并详细介绍了Qt5.15框架的基础知识和环境搭建。随后,本论文详细阐述了Qt5.15应用开发的基础实践,包括Qt Creator的使用、信号与槽机制以及常用控件与界面布局的实现。接着,文章重
【性能提升秘诀】:5种方法加速SUMMA算法在GPU上的执行
# 摘要
本文首先概述了性能优化的理论基础和SUMMA算法原理。随后,详细介绍了基础优化技巧以及SUMMA算法在GPU上的高效实现策略,并通过性能基准测试展示了优化效果。进一步地,本文探讨了数据局部性优化和内存访问模式,以及如何通过分布式计算框架和负载均衡技术提升并行算法的效率。此外,还着重分析了GPU算力优化技巧与创新技术的应用。最后,通过实际案例分析,展示了SUMMA算法在不同领域的成功应用,并对算法的未来发展趋势及研究方向进行了展望。
# 关键字
性能优化;SUMMA算法;GPU并行计算;内存访问模式;负载均衡;算力优化;创新技术应用
参考资源链接:[矩阵乘法的并行实现-summa算
双闭环控制方法在数字电源中的应用:案例研究与实操技巧
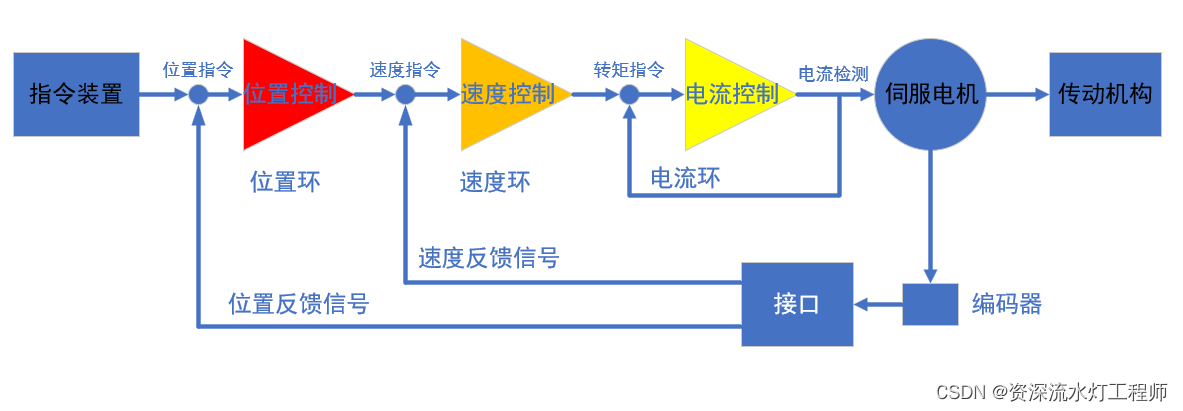
# 摘要
本文全面介绍了双闭环控制方法在数字电源中的应用,阐述了其理论基础、实现以及优化技术。首先概述了双闭环控制方法及其在数字电源工作原理中的重要性,随后详细探讨了数字电源的硬件实现与双闭环控制算法的软件实现。此外,文章还提供了实际案例分析,以展示双闭环控制在数字电源中的实现和优化过程。最后,本文展望了双闭环控制技术的未来发展趋势,包括智能控制技术的融合、创新应用以及行业标准和规范的发展。
# 关键字
双闭环控制;数字电源
Armv7-a架构深度解析:揭秘从基础到高级特性的全攻略
# 摘要
本文对ARMv7-A架构进行了全面的介绍和分析,从基础结构、高级特性到编程实践,深入探讨了该架构在现代计算中的作用。首先,概述了ARMv7-A的架构组成,包括处理器核心组件、内存管理单元和系统控制协处理器。接着,详细解读了执行状态、指令集、中断与异常处理等基础结构元素。在高级特性部分,文中重点分析了TrustZone安全扩展、虚拟化支持和通用性能增强技术。此外,还探讨了ARMv7-A在编程实践中的应用,包括汇编语言编程、操作系统支持及调试与性能分析。最后,通过应用案例,展望了ARMv7-A在未来嵌入式系统和物联网中的应用前景,以及向ARMv8架构的迁移策略。
# 关键字
ARMv7
Desigo CC高级配置案例:借鉴成功项目提升配置策略与效果

# 摘要
本文全面概述了Desigo CC在智能建筑中的应用和高级配置技术。首先介绍了Desigo CC的基本概念及其在智能建筑中的作用,接着深入探讨了配置策略的设计原理、系统要求以及从理论到实践的转化过程。文章通过实践案例分析,详细阐述了配置策略的实施步骤、问题诊断及解决方案,并对配置效果进行了评估。进一步,本文探讨了配置策略进阶技术,包括自动化配置、数据驱动优化以及安全与性能的动态平衡。最后,总结了配置过程中的经验和教训,并对
【LMS系统测试入门必读】:快速掌握操作指南与基础配置
# 摘要
本文全面介绍了学习管理系统(LMS)的测试流程,从测试的理论基础到实际的测试实践,包括系统架构解析、测试环境搭建、功能测试、性能测试以及测试自动化与持续集成。文章强调了LMS系统测试的重要性,阐述了其在软件开发生命周期中的作用,探讨了不同测试类型和方法论,以及如何进行有效的测试环境配置和数据准备。此外,本文还涉及了功能测试和性能测试的规划、执行和缺陷管理,并提出性能优化建议。最后,针对提高测试效率和质量,探讨了自动化测试框架的选择、脚本编写维护,以及持续集成的实施与管理策略。
# 关键字
学习管理系统(LMS);系统架构;性能测试;功能测试;测试自动化;持续集成
参考资源链接:[
【M-BUS主站安全防护攻略】:防雷与ESD设计的实践与心得
# 摘要
随着智能计量技术的广泛应用,M-BUS主站的安全防护已成为行业关注焦点。本文综合分析了M-BUS主站面临的雷电和静电放电(ESD)威胁,并提出了相应的防护措施。从防雷设计的基础理论出发,探讨了防雷系统层级结构、常用器件和材料,以及实施步骤中的注意事项。接着,详细阐述了ESD的物理原理、对电子设备的危害、防护策略和测试评估方法。文章进一步提出结合防雷和ESD的综合防护方案,包括设计原则、防护措施整合优化,以及案例分析。此外,还探讨了防护设备的维护、升级策略以及行业应用案例,为M-BUS主站的安全防护提供了全面的解决方案,并对行业发展趋势进行了展望。
# 关键字
M-BUS主站;安全防
稳定性保障:诺威达K2001-NWD固件兼容性测试与系统优化

# 摘要
本文详细论述了诺威达K2001-NWD固件的概述、兼容性测试理论基础、固件兼容性测试实践、系统优化理论与方法,以及诺威达K2001-NWD系统优化的实战应用。在兼容性测试部分,阐述了兼容性测试的定义、必要性分析以及测试环境的搭建
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )