Anaconda环境配置实战:如何打造高效、专属的数据科学工作空间
发布时间: 2024-12-10 03:19:27 阅读量: 4 订阅数: 20 

PyTorch环境配置指南:基于Anaconda平台的技术步骤
# 1. Anaconda环境配置概览
在当今数据科学领域中,有效的环境配置是确保项目顺利进行的关键。Anaconda作为一款流行的Python发行版,提供了便于管理和部署Python包和环境的工具,极大简化了复杂项目的部署流程。本章将为读者提供一个关于Anaconda环境配置的概览,涵盖其核心组件及操作流程,为后续章节中关于安装、管理、优化等详细讨论打下基础。在接下来的章节中,我们将详细介绍Anaconda的优势,展示如何安装Anaconda,以及如何高效管理和优化配置,确保读者能够掌握Anaconda环境配置的最佳实践。
# 2. Anaconda基础和安装流程
## 2.1 Anaconda的介绍与优势
### 2.1.1 数据科学工作流程的变革
Anaconda作为数据科学领域的领头羊,其集成的工具和包极大地简化了数据科学工作流程。其主要特点包括:
- **包管理的便捷性**:Anaconda自带了超过7500个开源库,覆盖数据科学、机器学习、深度学习等领域,方便用户一键安装。
- **环境隔离**:通过conda创建虚拟环境,可以让不同项目依赖的库和版本互不干扰,解决了包管理中的一大难题。
- **集成开发环境(IDE)**:Anaconda提供了Anaconda Navigator,这是一个图形界面的集成开发环境,使得非编程背景的用户也能快速上手。
### 2.1.2 Anaconda与其他Python发行版的比较
在众多Python发行版中,Anaconda以其在数据科学领域的专业性脱颖而出。相对于其他发行版,Anaconda有以下优势:
- **科学计算包的丰富性**:Anaconda自带的包覆盖了科学计算的大部分需求,如NumPy、Pandas、Matplotlib等。
- **跨平台的支持**:Anaconda支持Windows、macOS和Linux平台,适合不同背景的用户。
- **社区支持**:Anaconda拥有庞大的用户社区,提供了丰富的学习资源和问题解决方案。
## 2.2 安装Anaconda的步骤详解
### 2.2.1 系统需求和兼容性
安装Anaconda前,需要确认系统是否满足基本需求:
- **操作系统**:Windows 7/10/11(64位)、macOS 10.13+、Linux(如Ubuntu, Fedora, Debian等)。
- **硬件资源**:建议至少4GB内存,1GB磁盘空间用于Anaconda安装,额外空间用于包的安装和数据存储。
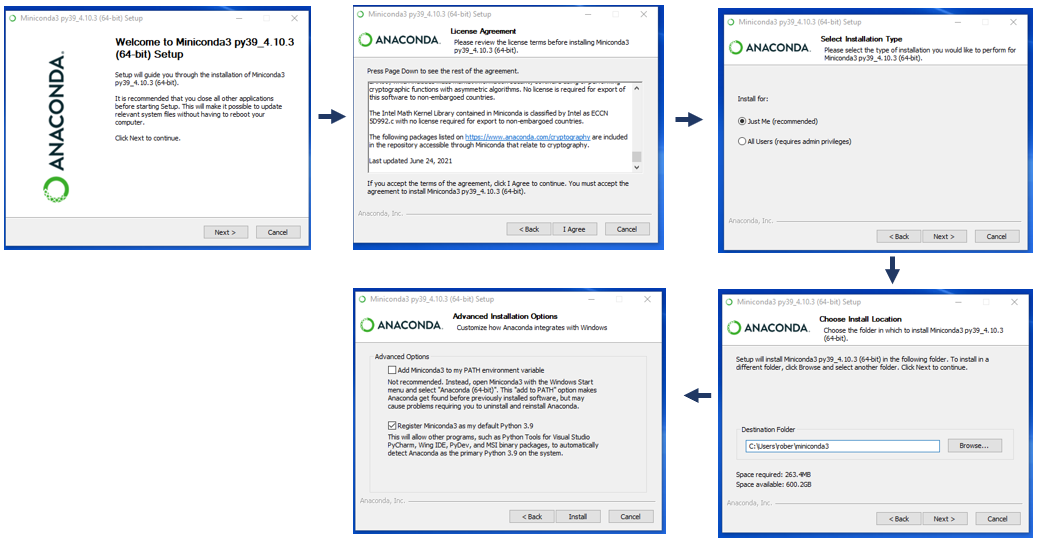
### 2.2.2 官网下载与安装指南
以下是Anaconda的官方安装指南:
1. 访问[Anaconda官网](https://www.anaconda.com/),下载适合操作系统的Anaconda安装程序。
2. 根据操作系统运行安装程序。例如,在Windows上,双击下载的`.exe`文件;在macOS上,打开`.pkg`文件;在Linux上,使用命令行安装。
```bash
# 示例:在Linux上安装Anaconda
chmod +x Anaconda3-2023.02-Linux-x86_64.sh
./Anaconda3-2023.02-Linux-x86_64.sh
```
3. 按照安装向导完成安装,接受许可协议,选择安装位置等。
### 2.2.3 安装验证和环境变量配置
安装完成后,需要验证安装是否成功:
- **运行Anaconda Navigator**:在开始菜单或应用程序中找到Anaconda Navigator,点击运行以验证安装。
- **使用conda命令**:打开命令行工具,输入`conda list`确认conda是否正常工作。
```bash
# 在命令行中运行conda list验证安装
conda list
```
安装Anaconda后,建议配置环境变量,确保系统能在任何路径下识别conda命令。在Windows上,将Anaconda安装目录添加到PATH环境变量中。在Linux或macOS上,通常安装过程会自动配置。
```bash
# 示例:配置环境变量的命令(Linux/macOS)
echo 'export PATH="/path/to/anaconda3/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
```
请注意,上述命令中的`/path/to/anaconda3/bin`需要替换为实际的Anaconda安装路径。
# 3. Anaconda环境管理和虚拟环境设置
Anaconda的环境管理功能是其最为用户所称道的特性之一。它允许用户创建隔离的环境,以便在不影响全局Python安装的情况下安装和运行不同版本的包。本章将深入探讨conda命令的基础使用,以及如何创建、管理和操作虚拟环境,同时介绍一些高级环境管理技巧。
## 3.1 掌握conda基础命令
### 3.1.1 conda list: 列出已安装的包
conda list是查看当前环境所有已安装包的命令。在终端或命令提示符中输入`conda list`,系统将列出该环境中所有已安装的包及其版本号。这是一个非常实用的命令,可以帮助用户了解环境状态,检查特定包是否已经安装。
```bash
conda list
```
### 3.1.2 conda create: 创建新环境
使用conda create命令,用户可以创建一个新的隔离环境。这个新环境将拥有用户指定的Python版本和其他包。例如,创建一个名为`new_env`的新环境,并安装Python 3.8和一些数据科学常用包,可以使用以下命令:
```bash
conda create -n new_env python=3.8 numpy pandas scikit-learn
```
这里`-n new_env`指定了环境名称,`python=3.8`指定了Python版本,`numpy`、`pandas`和`scikit-learn`是需要安装的包。
## 3.2 虚拟环境的操作技巧
### 3.2.1 激活和停用环境
创建虚拟环境后,需要先激活该环境才能在其中工作。在Windows系统中,激活命令如下:
```cmd
conda activate new_env
```
在Linux和MacOS系统中,相应的命令是:
```bash
source activate new_env
```
激活环境后,环境名称会出现在命令提示符之前。如果需要停用环境并返回到默认环境,可以使用以下命令:
```bash
conda deactivate
```
### 3.2.2 导出和导入环境
为了避免重复安装相同包,用户可以导出现有环境的配置,然后在另一台机器或新环境中导入。使用以下命令导出环境:
```bash
conda env export -n my_env > environment.yml
```
这里的`my_env`是环境名称,`environment.yml`是导出的文件。要导入环境,只需执行:
```bash
conda env create -f environment.yml
```
### 3.2.3 删除和管理环境
当不再需要某个环境时,可以使用`conda remove`命令删除它。删除名为`my_env`的环境的命令如下:
```bash
conda remove -n my_env --all
```
该命令中的`--all`选项确保环境中的所有包同时被删除。
## 3.3 高级环境管理
### 3.3.1 环境的备份和迁移
除了导出和导入环境的配置文件外,用户还可以通过备份整个环境目录来备份和迁移环境。例如,备份名为`my_env`的环境:
```bash
conda pack -n my_env -o my_env.tar.gz
```
然后在另一台机器上解压该文件,即可恢复环境。
### 3.3.2 多环境下的工作流管理
在处理多个项目时,可能需要频繁在不同环境之间切换。为了提高效率,可以编写shell脚本或使用conda提供的工具如`conda develop`来管理工作流,快速进入开发模式。
```bash
conda develop /path/to/project
```
该命令将项目路径添加到PYTHONPATH中,可以在不创建新环境的情况下,直接在现有环境中工作。
在本章节中,我们通过一步步的介绍和操作实例,详细地展示了如何使用Anaconda进行有效的环境管理和虚拟环境设置。下一章节我们将深入探讨如何通过Anaconda管理和更新包,以及优化Anaconda环境的性能和安全性。
# 4. Anaconda包管理与更新
## 4.1 包的安装和管理
在数据分析和科学计算中,我们经常需要安装和管理各种Python包。Anaconda提供了非常便捷的包管理和安装方式。本章节将详细介绍如何在Anaconda环境中安装、升级和管理包,以及在遇到依赖问题时应如何处理。
### 4.1.1 安装特定版本的包
为了保证环境的一致性和项目的可复现性,有时候我们需要安装特定版本的包。Anaconda提供了直接通过conda命令安装特定版本包的能力。
```bash
conda install numpy=1.16.4
```
此命令将安装Numpy的1.16.4版本。需要注意的是,当你指定安装特定版本时,conda会自动处理好所有依赖关系,从而避免潜在的版本冲突问题。对于需要的特定版本包,可以在conda的官方仓库或PyPI中查找。
### 4.1.2 升级和降级包
随着时间推移,可能需要更新包到最新版本或者降级到旧版本。Conda提供了简单命令来实现这些需求。
```bash
conda update numpy
```
该命令会将Numpy包更新到最新版本,而如果想要降级到之前的某个版本,可以使用类似:
```bash
conda install numpy=1.16.4
```
执行这些操作时,conda会确保所有依赖包也相应更新或降级,以保证环境的稳定性。
### 4.1.3 遇到依赖问题时的处理方法
在使用conda进行包的安装和管理过程中,可能会遇到依赖冲突的问题。此时可以采取以下策略:
1. **创建新环境**:为了避免潜在的冲突,可以在新环境中安装所需的包。
2. **使用conda-forge频道**:某些包可能在默认的conda频道中找不到,但conda-forge频道可能有更新的版本。
3. **指定包安装源**:可以通过`-c`参数指定从特定的频道安装包。
```bash
conda install -c conda-forge numpy
```
### 参数说明
- `-c`参数用于指定使用额外的频道,如上面的conda-forge频道。
### 代码逻辑说明
- 上述命令首先查找指定频道中是否存在请求的包,并检查与现有环境的兼容性。
- 然后下载并安装该包,同时处理所有依赖关系。
## 4.2 常用数据科学包介绍
Anaconda的一大优势是预装了很多常用的数据科学包。本节将介绍几个必备的数据科学包,以及一些常用于机器学习和深度学习的高级包。
### 4.2.1 Numpy, Pandas和Scikit-learn
Numpy是Python科学计算的基础包。它提供了高性能的多维数组对象以及相关的工具。
Pandas建立在Numpy之上,提供了易于使用的数据结构和数据分析工具。它特别擅长处理结构化数据,是数据分析工作中不可或缺的工具。
Scikit-learn是机器学习领域应用广泛的库,提供了各种常见的机器学习算法,方便进行分类、回归、聚类等任务。
### 4.2.2 机器学习与深度学习包
除了Scikit-learn,还有一系列强大的机器学习和深度学习包,如TensorFlow、Keras和PyTorch等。它们为构建复杂的模型提供了丰富的接口和功能。
- **TensorFlow**:一个开源的机器学习框架,支持大规模的深度学习应用。
- **Keras**:一个高层神经网络API,能够在TensorFlow, CNTK或Theano之上运行。
- **PyTorch**:一个Python机器学习库,以其动态计算图和直观易用而闻名。
## 4.3 包的冲突解决和最佳实践
在复杂的数据科学项目中,可能会安装多个包,这些包之间可能存在依赖和兼容性问题。合理管理这些包是保持开发环境稳定的关键。
### 4.3.1 如何避免包版本冲突
为了避免版本冲突,可以:
- **使用环境隔离**:每个项目在独立的conda环境中开发,避免不同项目间的依赖冲突。
- **定期更新包**:定期更新conda和包到最新版本,减少兼容性问题。
- **使用虚拟环境**:利用conda创建虚拟环境来隔离不同的开发和测试环境。
### 4.3.2 包管理的最佳实践
以下是使用conda进行包管理的一些最佳实践:
- **维护环境文件**:保存每个项目使用的包的版本信息到环境文件`environment.yml`中,方便环境的复制和重现。
- **创建最小化环境**:不要在环境中安装不必要的包,保持环境的精简。
- **定期检查和更新**:定期检查conda环境中包的版本,确保安全性和功能性。
通过遵循以上实践,可以最大程度地减少开发过程中的问题,提高生产效率。
在下一章节中,我们将探讨如何通过Anaconda进行环境优化和安全配置,从而进一步提升开发和运行的性能和安全性。
# 5. Anaconda环境优化和安全配置
## 5.1 配置环境以提升性能
Anaconda环境的性能优化是确保高效数据科学工作流程的关键。一个高效运行的环境不仅可以提升工作速度,还可以减少系统资源的浪费。
### 5.1.1 内存管理和优化
内存是运行复杂数据科学模型和算法的重要资源。在使用Anaconda进行数据分析时,合理的内存管理可以帮助我们避免内存溢出(Out of Memory, OOM)错误。
#### 参数调整技巧
- 在安装和更新包时,使用`--no-builds`参数可以避免重新构建已有的二进制包,从而节省时间和内存。
```bash
conda install <package_name> --no-builds
```
- 对于一些特定的包,比如TensorFlow,可以通过设置环境变量`TF_FORCE_GPU_ALLOW_GROWTH`为`true`来动态申请GPU内存,避免一次性占用过多内存。
```bash
export TF_FORCE_GPU_ALLOW_GROWTH=true
```
### 5.1.2 环境变量的高级设置
环境变量在Anaconda环境配置中起着关键作用。正确配置可以提升性能并保证环境的稳定运行。
#### 优化方法
- 利用`CONDA_DLL_SEARCH_MODIFICATION_ENABLE`环境变量来指定Anaconda搜索DLL文件的路径,这可以提高包的安装速度。
```bash
export CONDA_DLL_SEARCH_MODIFICATION_ENABLE=1
```
- 设置`CONDA_PREFIX`环境变量可以固定Conda包的安装路径,避免在多个环境间产生依赖问题。
```bash
export CONDA_PREFIX=/path/to/your/environment
```
## 5.2 安全性配置和数据备份
在进行数据分析和研究时,安全性和数据备份是不可忽视的两个方面。
### 5.2.1 加密和密码保护
- 使用Conda的包安装时可以采用密码保护,以防止未授权访问。
```bash
conda install <package_name> --password <your_password>
```
### 5.2.2 数据备份和恢复策略
- 使用`conda env export`命令导出当前环境的包列表,然后通过`conda env create`命令在新环境或恢复时使用此配置。
```bash
# 导出环境到文件
conda env export > environment.yml
# 在新环境中创建相同的环境
conda env create -f environment.yml
```
## 5.3 跨平台使用Anaconda
Anaconda的一大优势就是它的跨平台性,使用户能在不同的操作系统之间迁移环境,以及在云端使用。
### 5.3.1 在不同操作系统间迁移环境
Anaconda环境的迁移可通过导出和导入环境来实现,但在迁移时要注意包的依赖性可能因平台而异。
### 5.3.2 云端使用Anaconda的解决方案
- Anaconda Cloud是一个共享和使用数据科学包的平台。用户可以在云端创建、存储和分享自己的环境。
```bash
# 使用Anaconda Cloud的账户上传环境
conda env upload -n myenv -f environment.yml
```
- Anaconda的商业产品Anaconda Enterprise允许用户在云端部署、管理和协作数据分析项目。
通过以上的优化和安全配置,可以确保Anaconda环境在各种使用场景下的性能和安全。然而,这些配置只是开始,持续监控和调整是保持高效和安全环境的关键。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Anaconda专栏提供全面的Anaconda指南,涵盖从初学者到高级用户的各个方面。它包含了Anaconda快速项目部署、Conda命令行工具、第三方扩展包安装、Python数据分析、GPU加速和常用工具和库的深入解读。本专栏旨在帮助用户充分利用Anaconda,提高数据科学和机器学习项目的效率和性能。无论是新手还是经验丰富的从业者,都可以从本专栏中找到有价值的信息和技巧,从而提升他们的Anaconda技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【解密ISO 11898-2】:7大案例揭示CAN总线技术的实际应用
参考资源链接:[ISO 11898-2中文版:道路车辆CAN高速物理层标准解析](https://wenku.csdn.net/doc/26ogdo5nba?spm=1055.2635.3001.10343)
# 1. CAN总线技术概述
## 1.1 CAN总线的起源与定义
控制器局域网络(CAN)总线是一种广泛应用于电子控制单元(ECU)之间的可靠通信协议。它最初由德国博世公司为汽车内部网络通信开发,以取
Max-Log-MAP与SOVA:Turbo码性能与应用的双重视角

参考资源链接:[ Turbo码译码算法详解:MAP、Max-Log-MAP、Log-MAP与SOVA](https://wenku.csdn.net/doc/67u
【STM32F407终极指南】:7大技巧带你从新手到实战专家
参考资源链接:[STM32F407 Cortex-M4 MCU 数据手册:高性能、低功耗特性](https://wenku.csdn.net/doc/64604c48543f8444888dcfb2?spm=1055.2635.3001.10343)
# 1. STM32F407概述和开发环境搭建
## 1.1 STM32F407简介
STM32F407是由STMicroelectronics(意法
电子称校准秘籍:掌握这3个艺术级技巧,确保精准无误
参考资源链接:[梅特勒-托利多电子称全面设置教程](https://wenku.csdn.net/doc/10hjvgjrbf?spm=1055.2635.3001.10343)
# 1. 电子称校准的基础知识
## 1.1 校准的重要性
校准是确保电子称量设备精确性和可靠性的关键步骤。在日常使用过程中,多种因素如温度变化、机械磨损等可能导致电子称的读数偏离真实值。定期进行校准可以保证测量结果的准确性,符合行业标准和法律法规的要求。
## 1.2 校准的定义和目的
电子称校准是指使用已知精度的标准砝码或其他校准工具,对照电子称的显示值进行比对和调整,以消除误差或偏差,保证称量结果的准确可靠
坐标系统的秘密:Tecplot从笛卡尔到极坐标的高级应用解析

参考资源链接:[Tecplot入门教程:数据可视化与图形处理](https://wenku.csdn.net/doc/3e4i6cw3r9?spm=1055.2635.3001.10343)
# 1. Tecplot软件概览及坐标系统基础
## 1.1 Tecplot软件的介绍
Tecplot是一款广泛应用于科学和工程领域的数据分析和可视化软件。它提供了丰富的坐
SINAMICS S120电源模块详解:正确安装与维护的黄金法则

参考资源链接:[西门子SINAMICS S120伺服系统调试指南](https://wenku.csdn.net/doc/64715846d12cbe7ec3ff8638?spm=1055.2635.3001.10343)
# 1. SINAMICS S120电源模块概述
SIN
动态规划在MATLAB中的实现:案例分析与实用技巧

参考资源链接:[最优化方法Matlab程序设计课后答案详解](https://wenku.csdn.net/doc/6472f573d12cbe
揭秘DCDC-Boost电路仿真:10个案例深度分析与性能优化策略
参考资源链接:[LTspice新手指南:DC/DC Boost电路仿真](https://wenku.csdn.net/doc/1ue4eodgd8?spm=1055.2635.3001.10343)
# 1. DCDC-Boost电路仿真基础
## 1.1 电路仿真概述
电路仿真技术是一种利用计算工具模拟电路行为的过程,它能够帮助工程师在实际搭建电路前预测电路的性能。在电力电子领域,DCDC-Boost电路作为提
SINAMICS G120 CU240B-2_CU240E-2应用技巧: 参数手册中的隐藏功能全面挖掘

参考资源链接:[SINAMICS G120 CU240B/CU240E变频器参数手册(2016版)](https://wenku.csdn.net/doc/64658f935928463033ceb8af?spm=1055.2635.3
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )