异步处理全攻略:***mon.base库从基础到高级应用
发布时间: 2024-09-26 11:08:58 阅读量: 154 订阅数: 39 

# 1. 异步处理的概念和重要性
在现代的软件开发中,异步处理是一种常见且强大的技术,它能够显著提高应用程序的性能和响应能力。与同步处理相比,异步处理允许程序在等待某些长时间运行的操作(例如,网络请求、文件I/O操作等)完成时,继续执行其他任务,而不是简单地阻塞等待。这种处理方式的核心在于“非阻塞”和“回调”,它可以在多线程环境中大放异彩,有效利用系统的计算资源,提供更加流畅和快速的用户体验。
异步处理的重要性体现在多个方面。首先,它极大地提高了程序的并发性能,允许多个任务同时运行,而不会导致程序界面冻结或响应迟缓。其次,它能够提升系统的吞吐量,因为可以更有效地处理输入和输出操作。最后,异步处理机制可以提高资源利用率,因为它能够确保在等待I/O操作完成时,CPU等核心资源能够得到充分利用。
接下来的章节,我们将深入探讨mon.base库,一个专为异步处理设计的库,以及如何在实际应用中发挥其强大的能力。
# 2. mon.base库基础
### 2.1 mon.base库简介
mon.base是一个功能强大的库,旨在简化异步处理任务。它通过高效的数据队列管理和任务分发,优化了复杂应用的性能和响应速度。mon.base支持多种数据源,并能与多种数据库和存储系统无缝集成,适用于需要处理大量并发任务的场景。
#### 2.1.1 mon.base库的安装和配置
安装mon.base库非常简单,可以通过包管理器轻松完成。以Python为例,可以使用pip进行安装:
```bash
pip install mon.base
```
安装完成后,需要对mon.base进行基本配置。配置主要涉及到数据队列的参数设置和后端存储的连接信息,以下是一个简单的配置示例:
```python
from mon.base import MonBase
# 创建配置实例
config = {
'database': {
'engine': 'sqlite:///example.db', # 数据库连接字符串
'table': 'queue_table', # 数据队列对应的表名
},
'queue': {
'default': 'default_queue', # 默认队列名称
'backlog': 100, # 队列中保留的消息数
},
}
# 实例化mon.base库并传入配置
mon = MonBase(config)
```
在进行配置时,需要根据实际的数据库类型和存储需求调整配置参数。例如,如果是使用MySQL数据库,则需要修改`database`字典中的`engine`字段为适合MySQL的连接字符串。
#### 2.1.2 mon.base库的基本组件和功能
mon.base库的核心组件包括:
- `Queue`: 消息队列,用于异步任务的排队和分发。
- `Worker`: 工作单元,负责从队列中取出消息并处理。
- `Storage`: 数据存储,用于持久化存储任务消息和处理结果。
基本功能包括:
- 消息发布和订阅:允许开发者发布消息到指定队列,或订阅特定队列的消息。
- 任务调度:根据预定策略调度任务的执行。
- 状态跟踪:监控任务的执行状态和结果。
- 异步处理:支持异步方式处理消息,提高处理效率。
### 2.2 mon.base库的数据处理
#### 2.2.1 数据的接收和发送
mon.base库通过`Queue`组件负责数据的接收和发送。开发者可以使用预定义的接口来发布消息到队列。以下是一个简单的发送消息的代码示例:
```python
# 发送消息到队列
def send_message(queue_name, message):
queue = mon.get_queue(queue_name)
queue.put(message) # 将消息放入队列中
send_message('default_queue', {'task_id': 1, 'task_type': 'process_data'})
```
在上述代码中,`mon.get_queue(queue_name)`用于获取指定名称的队列对象,`queue.put(message)`用于将消息放入队列。这样消息就可以被后续的消费者(Consumer)所消费。
接收消息则是通过消费者的工作单元`Worker`来完成。消费者需要订阅相应的队列,并定义如何处理从队列中获取的消息。
#### 2.2.2 数据的存储和查询
mon.base库通过`Storage`组件负责数据的存储和查询。它支持多种后端存储系统,如关系型数据库、NoSQL数据库等。开发者可以定义自己的存储模型,以便灵活地存储和查询数据。以下是一个数据存储和查询的基本操作示例:
```python
# 定义存储模型
from mon.base import Model
class MyModel(Model):
# 模型字段
task_id = Field()
task_type = Field()
result = Field()
# 存储数据
my_model = MyModel(task_id=1, task_type='process_data')
my_model.save()
# 查询数据
my_model = MyModel.get(task_id=1)
print(my_model.task_type) # 输出:process_data
```
在这个例子中,`MyModel`类继承自`mon.base`的`Model`类,定义了数据模型,并提供了存储和查询接口。这样开发者就可以利用这些接口来管理数据的持久化和检索。
#### 2.2.3 数据的转换和处理
mon.base库支持数据的转换和处理,可以将复杂的数据结构进行转换,以便更容易地进行存储和传递。数据转换通常是通过自定义的序列化和反序列化过程来实现的。开发者可以通过实现自己的序列化方法来满足特定的数据格式要求。例如,以下是一个简单的数据转换示例:
```python
# 自定义序列化方法
def serialize_task_data(task_data):
# 将任务数据转换为JSON格式
return json.dumps(task_data)
# 自定义反序列化方法
def deserialize_task_data(serialized_task_data):
# 将JSON格式的数据还原为原始任务数据
return json.loads(serialized_task_data)
# 将任务数据转换并保存
task_data = {'task_id': 1, 'task_type': 'process_data'}
serialized = serialize_task_data(task_data)
my_model = MyModel(task_data=serialized)
my_model.save()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Google Guava 库中功能强大的 com.google.common.base 库。从入门介绍到高级用法,它涵盖了 10 大核心技巧、核心组件的使用、与 Java 8 流 API 的比较、多线程编程中的高级用法、打造高效 Java 工具箱、不可变集合的极致运用、字符串处理的技巧、集合操作性能提升、常见问题解答、集合工具类详解、空值处理的指南、系统性能优化、断言工具、数据验证和异步处理。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助开发人员掌握 com.google.common.base 库,提升 Java 应用程序的效率、健壮性和可维护性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32与SPI通信:10分钟入门到精通
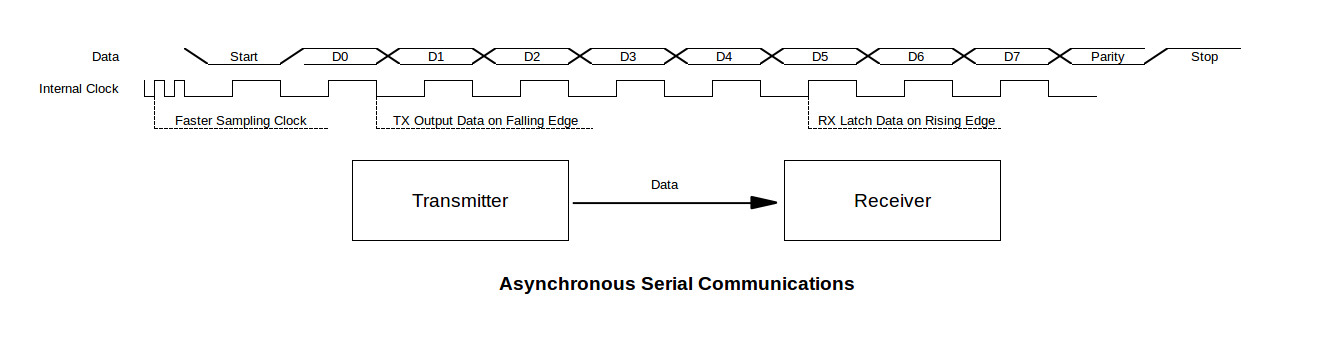
# 摘要
本文全面介绍了STM32微控制器与SPI(串行外设接口)通信的基础知识、协议细节、软件编程、设备交互实例、性能优化以及拓展应用。文章首先解释了SPI通信的基础概念和协议工作原理,然后详细探讨了SPI通信的软件配置、编程接口使用和错误处理方法。通过多个实际应用案例,如与EEPROM和SD卡的通信,以及多从设备环境中的应用,本文揭示了SPI通信的高级技巧和加密安全机制。进一步,本文提供了提升SP
【ASM焊线机工作原理深度挖掘】:自动化焊接技术的幕后英雄

# 摘要
ASM焊线机是电子制造业中不可或缺的先进设备,其工作原理涉及复杂的物理和化学反应,尤其是在焊接过程的热量传递和焊点形成的材料变化方面。本文对ASM焊线机的核心工作原理、硬件组成、软件编程及应用案例进行了详尽分析,同时探讨了其在自动化、智能化以及环境友好型技术方面的未来发展趋势。通过对焊线机各个组成部分的深入理解以及实践应用案例的分析,本文旨在为相关领域的工程师和技
PADS多层板设计:布局布线优化的7大实战技巧

# 摘要
本文系统地介绍了PADS多层板设计的全流程,涵盖了布局、布线优化以及高级设计技巧,并以案例分析的形式展示了在实际项目中的应用。文章首先概述了多层板设计的基础知识,然后深入探讨了布局优化的实战技巧,包括器件布局原则、电源和地的布局策略以及高频和敏感信号的隔离。接着,针对布线优化,文章详细介绍了布线规则、高速信号布线策略以及避免信号完整性问题的方法。最后,本文还探讨了高级设计技巧,如层叠管
Allegro屏蔽罩设计速成课:7个步骤带你入门到精通

# 摘要
本文旨在全面介绍Allegro软件在屏蔽罩设计中的应用基础和高级技术。首先,文章介绍了Allegro软件界面布局、工具设置以及绘图工具的基础使用,然后阐述了从原理图到PCB的转换过程。在屏蔽罩设计的理论与实践部分,文章深入分析了屏蔽罩的基本原理和设计要求,并通过案例展示了实际设计流程。接着,文章探讨了复杂环境下的屏蔽罩设计挑战,以及信号完整性分析与优化方法。最后,文章讨论了Allegro
Allwinner A133硬件加速功能详解:释放多核CPU的全部力量

# 摘要
本论文深入探讨了Allwinner A133处理器以及其硬件加速功能。首先概述了Allwinner A133处理器,紧接着介绍硬件加速技术的基础知识,包括定义、优势、多核CPU工作原理以及关键技术。第三章详细解析了A133的多核架构、硬件加速单元的集成以及专用加速器。第四章聚焦于A133硬件加速的编程实践,涵盖编程模型、性能调优以及多媒体应用的加速实例。第五章展示了A133在移动设备、边
TM1668驱动原理深度剖析:打造您的稳定LED显示系统
# 摘要
本文全面介绍了TM1668驱动芯片的硬件特性、通信协议、显示原理和软件驱动开发方法。首先概述了TM1668的基本功能和应用场景。接着详细分析了TM1668的硬件接口、通信协议和硬件连接实践。第三章探讨了TM1668的显示原理和亮度控制机制,以及显示数据处理方式。第四章则着重介绍了TM1668软件驱动的基本结构、编程接口以及高级功能实现。第五章提供了TM1668的应用案例、故障排除和性能优化策略。最后一章展望了TM1668在未来技术中的应用前景、技术发展和驱动开发面临的挑战。通过本文,读者可以全面掌握TM1668芯片的设计、实现和应用知识。
# 关键字
TM1668驱动芯片;硬件接口
大数据时代的挑战与机遇:如何利用数据爆炸驱动企业增长
# 摘要
大数据时代为决策制定、业务模型创新以及企业架构发展带来了新的机遇和挑战。本文系统性地分析了数据驱动决策理论、数据科学的实践应用、大数据技术栈及其在企业中的集成,以及AI与数据科学的融合。同时,针对大数据环境下的伦理、法规和未来趋势进行了深入探讨。文中详细介绍了数据
AD转换器终极选购攻略:关键性能参数一网打尽
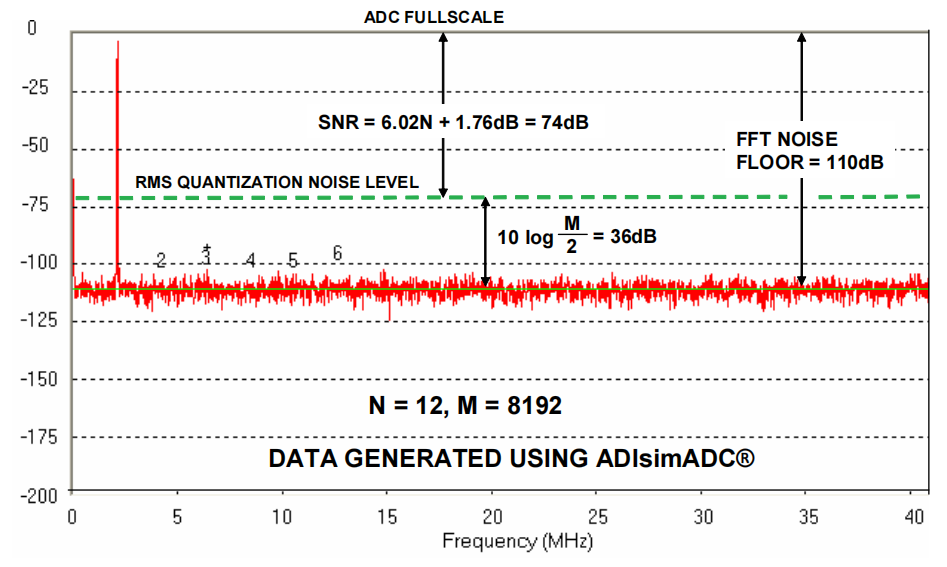
# 摘要
本文全面探讨了模拟到数字(AD)转换器的原理、核心参数、应用领域、品牌与型号分析、选购技巧以及维护与故障排除。首先介绍了AD转换器的基本工作原理和主要应用领域,然后深入解读了分辨率、采样率、线性度和失真等核心参数,以及它们对转换性能的影响。接着,本文分析了市场上主流品牌的AD转换器,并提供了性能对比和选购建议。此外,本文还介绍了AD转换器的技术规格书解读、实验测
Quartus II大师课:EP4CE10F17C8配置与编程技巧
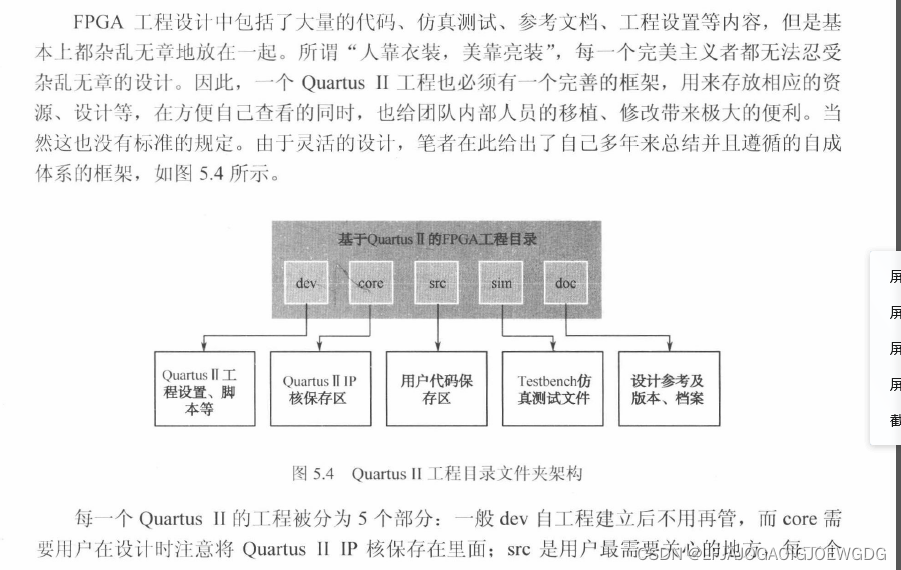
# 摘要
本文全面介绍了使用Quartus II软件对EP4CE10F17C8 FPGA芯片进行配置与编程的过程。从基础项目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )