揭秘CMake编译OpenCV的奥秘:从零开始构建OpenCV,解决编译难题
发布时间: 2024-08-09 03:56:10 阅读量: 352 订阅数: 57 

Windows下CMAKE编译opencv + opencv-contrib + CUDA12.1 + Cudnn

# 1. CMake简介与基础
CMake是一个跨平台的构建系统,用于管理软件项目的编译、链接和安装过程。它使用声明式语言来指定项目的依赖关系和构建规则,并生成平台特定的构建文件,如Makefiles或Ninja文件。
CMake的主要优点包括:
- **跨平台:**CMake可以在Windows、Linux、macOS和各种嵌入式系统等多个平台上运行。
- **可扩展:**CMake可以通过模块和函数进行扩展,以支持各种语言、工具和构建系统。
- **自动化:**CMake可以自动化编译和安装过程,减少手动配置和错误的可能性。
# 2. CMake构建OpenCV的理论基础
### 2.1 CMake的语法和指令
CMake是一种基于文本的构建系统,它使用一种声明式语言来描述构建过程。CMake语言由指令组成,指令以关键字开头,后跟参数。最常见的指令包括:
- `project()`: 定义项目名称和版本。
- `cmake_minimum_required()`: 指定CMake的最低版本要求。
- `find_package()`: 查找并加载系统上已安装的包。
- `add_executable()`: 添加一个可执行文件到构建中。
- `add_library()`: 添加一个库到构建中。
- `target_link_libraries()`: 链接目标到其他库。
### 2.2 CMake的变量和函数
CMake提供了许多变量和函数,用于控制构建过程。变量存储信息,例如项目名称、版本和构建类型。函数执行各种任务,例如查找文件、创建目录和设置编译器选项。
**变量**
- `PROJECT_NAME`: 项目名称。
- `PROJECT_VERSION`: 项目版本。
- `CMAKE_BUILD_TYPE`: 构建类型(例如,Debug、Release)。
- `CMAKE_CURRENT_SOURCE_DIR`: 当前源目录。
- `CMAKE_CURRENT_BINARY_DIR`: 当前二进制目录。
**函数**
- `message()`: 输出消息到控制台。
- `file()`: 操作文件和目录。
- `execute_process()`: 执行外部命令。
- `string()`: 操作字符串。
- `list()`: 操作列表。
### 2.3 CMake的模块和包
**模块**
模块是包含特定功能的CMake脚本。它们可以扩展CMake的功能,例如添加对特定语言或平台的支持。
**包**
包是一组模块,它们一起提供特定功能。包通常用于管理第三方库的构建和安装。
**代码块**
```cmake
project(OpenCV VERSION 4.5.5)
cmake_minimum_required(VERSION 3.15)
find_package(OpenCV REQUIRED)
add_executable(my_program main.cpp)
target_link_libraries(my_program OpenCV::opencv)
```
**逻辑分析**
这段代码使用CMake指令来构建一个名为“my_program”的可执行文件,该可执行文件链接到OpenCV库。
**参数说明**
- `project()`: 项目名称为“OpenCV”,版本为“4.5.5”。
- `cmake_minimum_required()`: 指定CMake的最低版本要求为“3.15”。
- `find_package()`: 查找并加载OpenCV包。
- `add_executable()`: 添加一个名为“my_program”的可执行文件到构建中。
- `target_link_libraries()`: 将“my_program”目标链接到OpenCV库。
# 3.1 OpenCV的依赖关系分析
在构建OpenCV之前,需要了解其依赖关系。OpenCV依赖于以下库:
- **C语言标准库 (C Standard Library)**:提供基本的数据结构和函数,如数组、字符串和数学运算。
- **C++标准库 (C++ Standard Library)**:提供更高级的数据结构和算法,如容器、迭代器和算法。
- **操作系统库 (Operating System Libraries)**:提供与操作系统交互的函数,如文件系统访问和线程管理。
- **图像处理库 (Image Processing Libraries)**:提供图像处理和计算机视觉功能,如 OpenCV 本身。
### 3.2 CMakeLists.txt文件的编写
CMakeLists.txt文件是CMake构建过程的核心。它包含一系列指令,用于配置构建过程。以下是CMakeLists.txt文件的典型结构:
```cmake
cmake_minimum_required(VERSION 3.18)
project(OpenCV VERSION 4.5.5)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${OpenCV_LIBRARY_DIRS})
add_executable(opencv_example main.cpp)
target_link_libraries(opencv_example ${OpenCV_LIBRARIES})
```
### 3.3 编译和安装OpenCV
要编译和安装OpenCV,请执行以下步骤:
1. **配置构建**:运行 `cmake` 命令配置构建过程。这将生成一个 Makefile 或其他构建系统文件。
2. **构建**:运行 `make` 命令构建 OpenCV。
3. **安装**:运行 `make install` 命令将 OpenCV 安装到系统中。
**代码块:配置构建**
```cmake
cmake -S . -B build
```
**代码逻辑分析:**
- `-S .` 指定源代码目录。
- `-B build` 指定构建目录。
**参数说明:**
- `-S <source_directory>`:指定 CMakeLists.txt 文件所在的源代码目录。
- `-B <build_directory>`:指定构建目录。构建过程将在该目录中进行。
**表格:OpenCV构建过程中的常见错误**
| 错误 | 原因 | 解决方案 |
|---|---|---|
| 找不到 OpenCV | OpenCV 库未安装 | 安装 OpenCV 库 |
| 找不到头文件 | OpenCV 头文件路径未正确配置 | 在 CMakeLists.txt 文件中包含 OpenCV 头文件路径 |
| 链接错误 | OpenCV 库未正确链接 | 在 CMakeLists.txt 文件中链接 OpenCV 库 |
**Mermaid流程图:OpenCV构建过程**
```mermaid
graph LR
subgraph 配置构建
A[配置构建] --> B[生成构建文件]
end
subgraph 构建
B[生成构建文件] --> C[构建OpenCV]
end
subgraph 安装
C[构建OpenCV] --> D[安装OpenCV]
end
```
# 4. CMake构建OpenCV的疑难解答
### 4.1 常见的编译错误和解决方法
在构建OpenCV时,可能会遇到各种编译错误。以下是解决常见编译错误的一些方法:
- **找不到头文件或库:**确保已安装所有必需的依赖项,并且CMake已正确配置以查找它们。使用`find_package()`命令来搜索依赖项。
- **符号未定义:**这通常表示缺少库或头文件。检查依赖项的安装路径,并确保CMake已正确配置以包含它们。
- **链接器错误:**这通常表示缺少库或库的顺序不正确。使用`target_link_libraries()`命令来指定链接顺序。
- **版本不匹配:**确保OpenCV和依赖项的版本兼容。检查依赖项的版本要求,并确保安装了正确的版本。
- **平台不兼容:**确保CMake已正确配置为目标平台。使用`CMAKE_SYSTEM_NAME`变量来指定目标平台。
### 4.2 调试和优化CMake构建过程
为了调试和优化CMake构建过程,可以使用以下技术:
- **使用CMake日志:**通过设置`CMAKE_VERBOSE_MAKEFILE=ON`来启用CMake日志,以查看详细的构建过程。
- **使用CMake缓存:**使用`ccmake`或`cmake-gui`来查看和修改CMake缓存,以调试配置问题。
- **使用CTest:**使用CTest框架来运行单元测试和集成测试,以帮助识别构建问题。
- **使用性能分析器:**使用`perf`或`gprof`等工具来分析构建过程的性能,并识别瓶颈。
- **使用CMake模块:**使用CMake模块来扩展CMake的功能,例如添加自定义命令或提供其他功能。
### 代码示例
以下代码块展示了如何使用CMake日志来调试构建过程:
```cmake
cmake -DCMAKE_VERBOSE_MAKEFILE=ON ..
```
以下代码块展示了如何使用CTest来运行单元测试:
```cmake
ctest -V
```
### 表格示例
| CMake选项 | 描述 |
|---|---|
| `CMAKE_BUILD_TYPE` | 指定构建类型(例如,Debug、Release) |
| `CMAKE_INSTALL_PREFIX` | 指定安装前缀 |
| `CMAKE_CXX_FLAGS` | 指定C++编译器标志 |
| `CMAKE_MODULE_PATH` | 指定CMake模块的搜索路径 |
### Mermaid流程图示例
```mermaid
graph LR
subgraph CMake构建OpenCV
A[依赖关系分析] --> B[CMakeLists.txt编写]
B --> C[编译和安装]
end
```
# 5.1 CMake的跨平台构建
### 跨平台构建的挑战
在不同的操作系统和硬件架构上构建软件时,会遇到各种挑战,包括:
- **文件路径差异:**不同操作系统使用不同的文件路径分隔符,如 Windows 的 `\` 和 Linux 的 `/`。
- **库和头文件可用性:**某些库和头文件可能在某些平台上不可用,导致编译错误。
- **编译器和链接器差异:**不同编译器和链接器具有不同的语法和选项,可能导致构建失败。
### CMake的跨平台支持
CMake提供了强大的跨平台支持,使您能够使用单个 CMakeLists.txt 文件在不同的平台上构建软件。它通过以下机制实现:
- **平台特定指令:**CMake 提供了特定于平台的指令,例如 `windows_dll` 和 `target_link_libraries`,用于处理不同平台上的特定要求。
- **变量和函数:**CMake 提供了变量和函数,例如 `CMAKE_SYSTEM_NAME` 和 `find_library`,用于查询平台信息和查找系统库。
- **生成器:**CMake 可以使用不同的生成器(如 Make、Ninja 和 Visual Studio)来生成特定于平台的构建文件。
### 使用 CMake 进行跨平台构建
要使用 CMake 进行跨平台构建,请执行以下步骤:
1. **安装 CMake:**在所有目标平台上安装 CMake。
2. **编写 CMakeLists.txt 文件:**编写一个 CMakeLists.txt 文件,其中包含构建软件所需的所有指令。
3. **设置目标平台:**使用 `CMAKE_SYSTEM_NAME` 变量或 `target_compile_definitions` 指令设置目标平台。
4. **使用平台特定指令:**根据需要使用平台特定指令处理不同平台上的特定要求。
5. **生成构建文件:**使用 CMake 生成器为每个目标平台生成构建文件。
6. **构建软件:**使用生成的构建文件构建软件。
### 示例:跨平台构建 OpenCV
以下 CMakeLists.txt 文件演示了如何在 Windows 和 Linux 上跨平台构建 OpenCV:
```cmake
cmake_minimum_required(VERSION 3.10)
project(OpenCV)
# 设置目标平台
set(CMAKE_SYSTEM_NAME "Windows" CACHE STRING "Target platform")
# 查找 OpenCV 库
find_package(OpenCV REQUIRED)
# 添加 OpenCV 库到链接目标
target_link_libraries(OpenCV::opencv)
# 设置编译器选项
if(CMAKE_SYSTEM_NAME STREQUAL "Windows")
# Windows 特定编译器选项
add_compile_definitions(-DWIN32)
elseif(CMAKE_SYSTEM_NAME STREQUAL "Linux")
# Linux 特定编译器选项
add_compile_definitions(-DLINUX)
endif()
# 生成构建文件
add_executable(opencv_example main.cpp)
```
通过使用 `CMAKE_SYSTEM_NAME` 变量,此 CMakeLists.txt 文件可以根据目标平台自动配置编译器选项。
## 5.2 CMake的自定义模块和函数
### 自定义模块
CMake 模块是一种可重用代码片段,可以包含指令、变量和函数。它们可以用来扩展 CMake 的功能或创建自定义构建逻辑。
要创建自定义模块,请创建一个带有 `.cmake` 扩展名的文件,并将其放置在 CMake 的模块路径中。然后,可以使用 `include` 指令在 CMakeLists.txt 文件中包含该模块。
### 示例:自定义模块用于查找系统库
以下自定义模块用于查找系统库:
```cmake
# find_system_library.cmake
find_path(SYSTEM_LIBRARY_PATH
NAMES my_library
PATHS /usr/lib /usr/local/lib
)
```
要使用此模块,请在 CMakeLists.txt 文件中包含它并使用 `find_system_library` 函数:
```cmake
include(find_system_library.cmake)
find_system_library(MY_LIBRARY my_library)
```
### 自定义函数
CMake 函数是一种在 CMakeLists.txt 文件中定义的代码块。它们可以用来执行特定任务或计算值。
要创建自定义函数,请使用 `function` 和 `endfunction` 指令。函数可以接受参数并返回值。
### 示例:自定义函数用于打印消息
以下自定义函数用于打印消息:
```cmake
# print_message.cmake
function(print_message MESSAGE)
message(${MESSAGE})
endfunction()
```
要使用此函数,请在 CMakeLists.txt 文件中包含它并调用 `print_message` 函数:
```cmake
include(print_message.cmake)
print_message("Hello, world!")
```
## 5.3 CMake的测试和集成
### 测试
CMake 提供了内置的测试框架,使您能够编写和运行单元测试。要编写测试,请使用 `add_test` 指令。测试可以是可执行文件、脚本或自定义命令。
### 示例:测试 OpenCV 函数
以下 CMakeLists.txt 文件演示了如何测试 OpenCV 函数:
```cmake
add_test(opencv_test
COMMAND ${CMAKE_COMMAND}
-E compare_files
${CMAKE_CURRENT_SOURCE_DIR}/expected_output.txt
${CMAKE_CURRENT_BINARY_DIR}/actual_output.txt
)
```
此测试将比较 `expected_output.txt` 文件和 `actual_output.txt` 文件的内容,如果内容相同则测试通过。
### 集成
CMake 可以与其他构建系统集成,例如 Make、Ninja 和 Visual Studio。这使您可以利用这些构建系统的功能,同时保留 CMake 的跨平台优势。
要集成 CMake,请使用 `externalproject_add` 指令。此指令允许您定义外部项目,该项目可以使用 CMake 或其他构建系统构建。
### 示例:集成 Make
以下 CMakeLists.txt 文件演示了如何集成 Make:
```cmake
externalproject_add(make_project
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/make_project
BUILD_COMMAND make
INSTALL_COMMAND make install
)
```
此集成将允许您使用 CMake 构建和安装 Make 项目。
# 6.1 CMake构建的性能优化
在构建OpenCV时,性能优化至关重要,因为它可以显着减少编译时间并提高整体构建效率。以下是一些优化CMake构建性能的最佳实践:
- **并行构建:**利用CMake的并行构建功能,允许多个编译器进程同时工作。这可以通过在CMake命令行中添加`-j`标志来实现,后跟要使用的进程数。例如:`cmake -j8`。
- **预编译头文件:**预编译头文件可以减少编译时间,因为它允许编译器在编译每个源文件之前预编译公共头文件。这可以通过在CMakeLists.txt文件中使用`set(CMAKE_USE_PRECOMPILE_HEADER ON)`指令来实现。
- **缓存变量:**CMake缓存变量可以存储构建配置信息,从而避免在每次重新配置时重新生成该信息。这可以通过在CMakeLists.txt文件中使用`set(CMAKE_CACHE_VARIABLE ON)`指令来实现。
- **使用Ninja生成器:**Ninja是一个快速且高效的构建系统,可以显着减少构建时间。要使用Ninja,请在CMake命令行中添加`-G Ninja`标志。
- **优化编译器标志:**优化编译器标志可以提高编译代码的性能。这可以通过在CMakeLists.txt文件中使用`add_compile_options()`指令来实现,后跟要使用的标志列表。例如:`add_compile_options(-O3 -march=native)`。
- **使用Clang:**Clang是一个现代且高效的编译器,可以比GCC产生更优化的代码。要使用Clang,请在CMake命令行中添加`-DCMAKE_C_COMPILER=clang`和`-DCMAKE_CXX_COMPILER=clang++`标志。
- **使用静态链接:**静态链接可以减少运行时依赖项并提高性能。这可以通过在CMakeLists.txt文件中使用`set(CMAKE_EXE_LINKER_FLAGS "-static")`指令来实现。
通过应用这些最佳实践,可以显着优化CMake构建OpenCV的性能,从而节省时间并提高整体构建效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 CMake 编译 OpenCV 的方方面面,从基础知识到高级技术。它提供了分步指南,帮助您从头开始构建 OpenCV,并解决常见的编译难题。专栏还涵盖了优化编译效率、提升编译质量、跨平台编译、自动化编译过程、调试错误、优化性能、扩展编译能力、获取社区支持、分享最佳实践和经验教训、探索替代方案、揭示底层机制以及管理不同版本的 OpenCV。通过遵循本专栏的指导,您可以掌握 CMake 编译 OpenCV 的艺术,并构建高效、可靠且可移植的 OpenCV 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
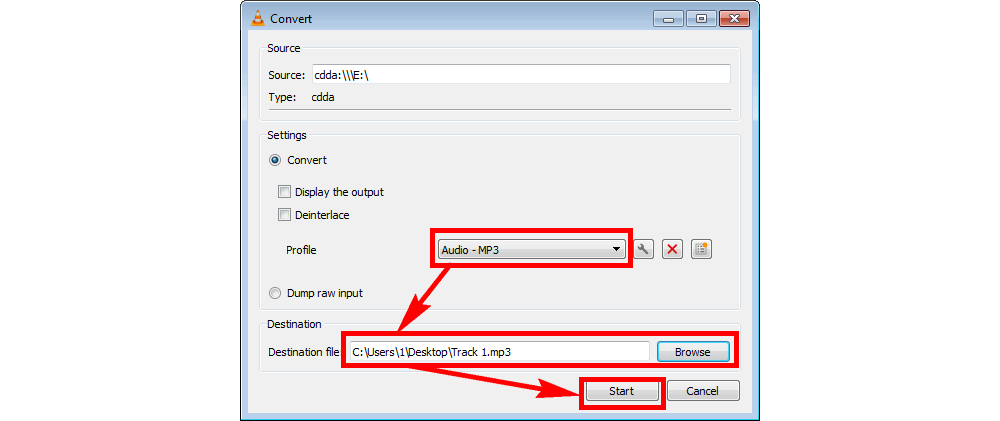
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
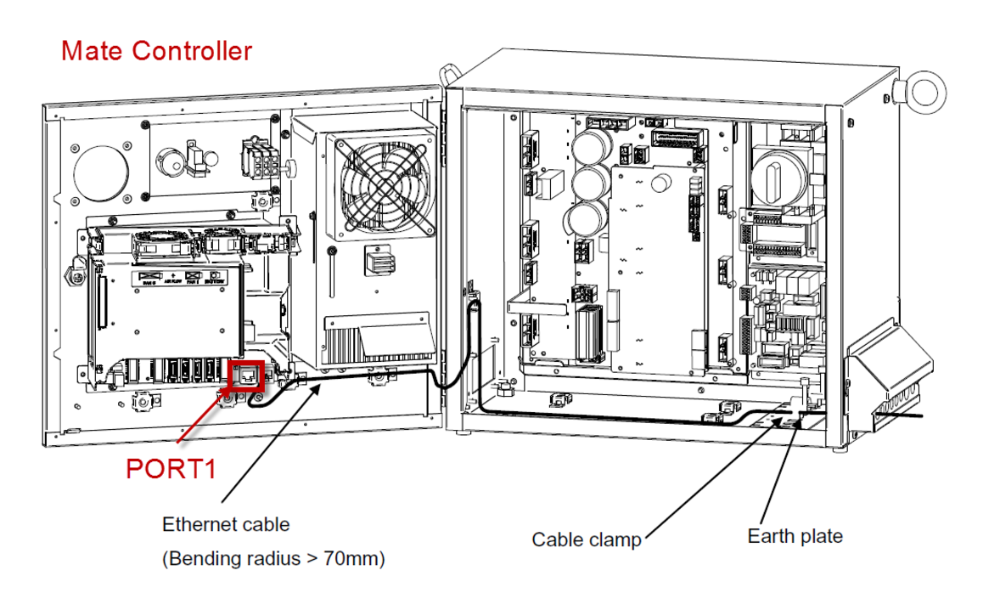
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
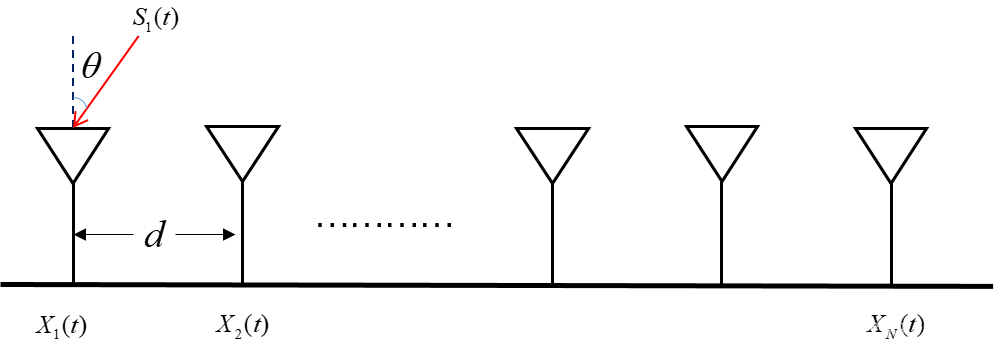
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
# 摘要
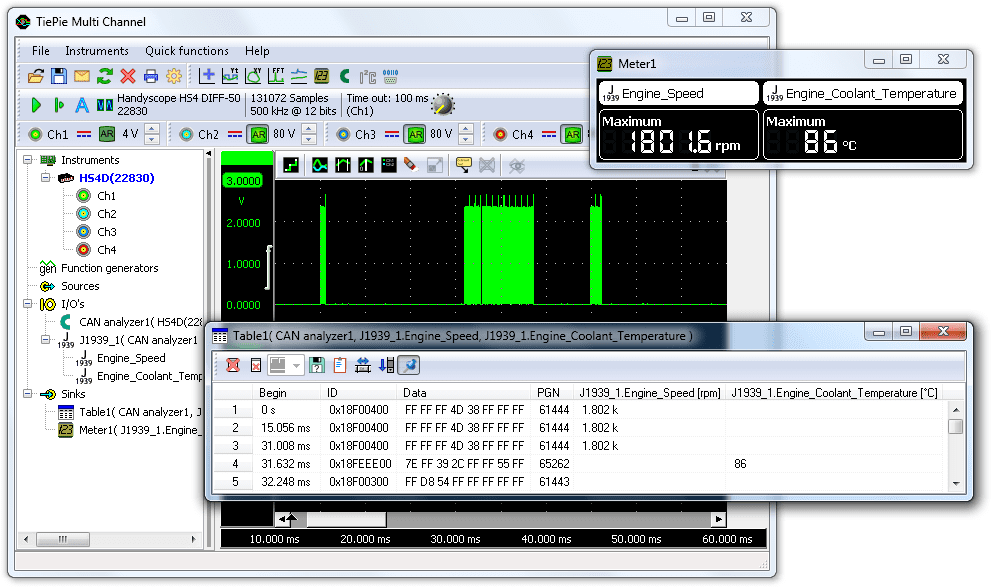
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )