MyBatis留言本中使用日志监控与优化
发布时间: 2024-04-02 23:06:07 阅读量: 38 订阅数: 44 

MyBatis基本使用与优化
# 1. 介绍MyBatis和留言本应用
## 1.1 了解MyBatis框架
在本章节中,我们将介绍MyBatis框架的概念、特点和用途,帮助读者对MyBatis有一个全面的认识。
MyBatis是一款优秀的持久层框架,它简化了数据库操作的过程,提供了强大的SQL映射功能,同时兼具了传统Hibernate框架和JDBC的优点。
通过MyBatis,开发人员可以通过XML或注解来配置SQL映射关系,实现Java对象与数据库表的映射,极大地提升了开发效率和易维护性。
## 1.2 留言本应用概述
留言本应用通常是一个典型的Web应用程序,用户可以在上面发表留言、评论、回复等。这种应用一般需要对用户的操作进行持久化存储,因此使用MyBatis这样的持久层框架能够大大简化开发流程。
在留言本应用中,通常需要定义留言、评论等业务实体对象,并通过MyBatis来进行数据库操作,包括插入、查询、更新等操作,通过本章我们将了解MyBatis在留言本应用中的具体应用场景和优势。
# 2. 日志监控在MyBatis中的重要性
在开发和维护MyBatis应用程序时,日志监控是至关重要的。本章将介绍日志监控在MyBatis中的重要性以及相关实现方式。让我们深入了解这一关键主题。
# 3. 配置日志监控功能
在本章中,我们将重点讨论如何配置日志监控功能,包括将日志框架集成到MyBatis中以及配置日志监控参数。
#### 3.1 集成日志框架到MyBatis中
在MyBatis中,我们通常使用日志框架来记录SQL执行的详细信息,以便后续分析和优化。常见的日志框架包括Log4j、Logback等。下面以Logback为例,介绍如何在MyBatis中集成Logback日志框架。
首先,我们需要在项目的依赖中添加Logback的相关依赖,具体可以在`pom.xml`文件中进行配置:
```xml
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
```
接下来,我们需要在项目中创建Logback的配置文件`logback.xml`,配置日志输出的格式和目标等信息。一个简单的Logback配置示例如下:
```xml
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="STDOUT" />
</root>
</configuration>
```
然后,我们需要在MyB

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“MyBatis留言本”专栏是一系列深入探讨 MyBatis 框架在实际应用中的教程。从基础的环境配置和数据库设计,到高级的动态 SQL、注解 CRUD、ResultMap 和 TypeHandler,该专栏涵盖了 MyBatis 的各个方面。此外,还介绍了存储过程、关联查询、分页查询、缓存、日志监控、事务管理、乐观锁和悲观锁等高级概念。为了提高开发效率,该专栏还介绍了代码生成、逆向工程、数据加密和 SQL 注入防范等技术。通过本专栏,开发者可以全面掌握 MyBatis 的强大功能,并将其应用于实际项目中,优化数据库操作,提升应用性能和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JLINK_V8固件烧录故障全解析:常见问题与快速解决

# 摘要
JLINK_V8作为一种常用的调试工具,其固件烧录过程对于嵌入式系统开发和维护至关重要。本文首先概述了JLINK_V8固件烧录的基础知识,包括工具的功能特点和安装配置流程。随后,文中详细阐述了烧录前的准备、具体步骤和烧录后的验证工作,以及在硬件连接、软件配置及烧录失败中可能遇到的常见问题和解决方案
【Jetson Nano 初识】:掌握边缘计算入门钥匙,开启新世界

# 摘要
本论文介绍了边缘计算的兴起与Jetson Nano这一设备的概况。通过对Jetson Nano的硬件架构进行深入分析,探讨了其核心组件、性能评估以及软硬件支持。同时,本文指导了如何搭建Jetson Nano的开发环境,并集成相关开发库与API。此外,还通过实际案例展示了Jetson Nano在边缘计算中的应用,包括实时图像和音频数
MyBatis-Plus QueryWrapper故障排除手册:解决常见查询问题的快速解决方案
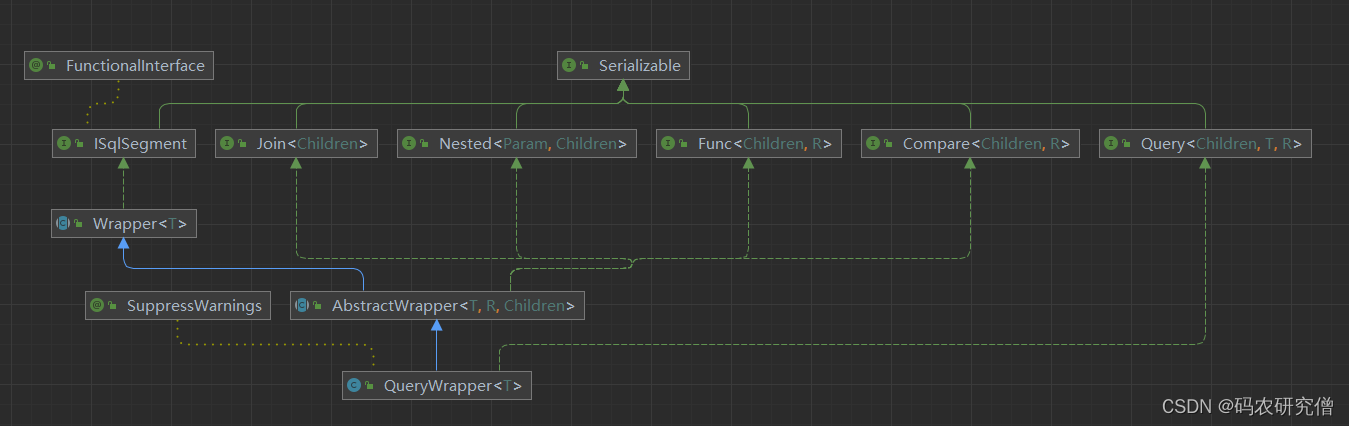
# 摘要
MyBatis-Plus作为一款流行的持久层框架,其提供的QueryWrapper工具极大地简化了数据库查询操作的复杂性。本文首先介绍了MyBatis-Plus和QueryWrapper的基本概念,然后深入解析了QueryWrapper的构建过程、关键方法以及高级特性。接着,文章探讨了在实际应用中查询常见问题的诊断与解决策略,以及在复杂场
【深入分析】SAP BW4HANA数据整合:ETL过程优化策略

# 摘要
SAP BW4HANA作为企业数据仓库的更新迭代版本,提供了改进的数据整合能力,特别是在ETL(抽取、转换、加载)流程方面。本文首先概述了SAP BW4HANA数据整合的基础知识,接着深入探讨了其ETL架构的特点以及集成方法论。在实践技巧方面,本文讨论了数据抽取、转换和加载过程中的优化技术和高级处理方法,以及性能调优策略。文章还着重讲述了ETL过
电子时钟硬件选型精要:嵌入式系统设计要点(硬件配置秘诀)

# 摘要
本文对嵌入式系统与电子时钟的设计和开发进行了综合分析,重点关注核心处理器的选择与评估、时钟显示技术的比较与组件选择、以及输入输出接口与外围设备的集成。首先,概述了嵌入式系统的基本概念和电子时钟的结构特点。接着,对处理器性能指标进行了评估,讨论了功耗管理和扩展性对系统效能和稳定性的重要性。在时钟显示方面,对比了不同显示技术的优劣,并探讨了显示模块设计和电源管理的优化策略。最后,本
【STM8L151电源设计揭秘】:稳定供电的不传之秘

# 摘要
本文对STM8L151微控制器的电源设计进行了全面的探讨,从理论基础到实践应用,再到高级技巧和案例分析,逐步深入。首先概述了STM8L151微控制器的特点和电源需求,随后介绍了电源设计的基础理论,包括电源转换效率和噪声滤波,以及STM8L151的具体电源需求。实践部分详细探讨了适合STM8L151的低压供电解决方案、电源管理策略和外围电源设计。最后,提供了电源设计的高级技巧,包括
NI_Vision视觉软件安装与配置:新手也能一步步轻松入门

# 摘要
本文系统介绍NI_Vision视觉软件的安装、基础操作、高级功能应用、项目案例分析以及未来展望。第一章提供了软件的概述,第二章详细描述了软件的安装流程及其后的配置与验证方法。第三章则深入探讨了NI_Vision的基础操作指南,包括界面布局、图像采集与处理,以及实际应用的演练。第四章着重于高级功能实
【VMware Workstation克隆与快照高效指南】:备份恢复一步到位

# 摘要
VMware Workstation的克隆和快照功能是虚拟化技术中的关键组成部分,对于提高IT环境的备份、恢复和维护效率起着至关重要的作用。本文全面介绍了虚拟机克隆和快照的原理、操作步骤、管理和高级应用,同时探讨了克隆与快照技术在企业备份与恢复中的应用,并对如何
【Cortex R52 TRM文档解读】:探索技术参考手册的奥秘
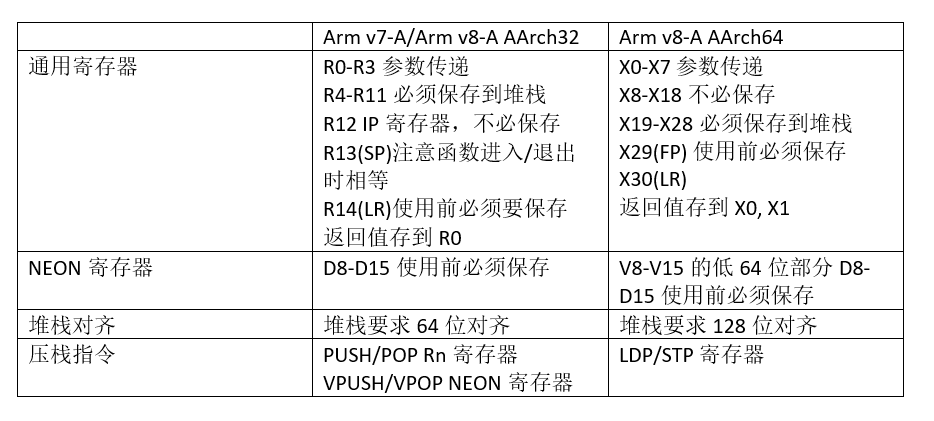
# 摘要
本文深入探讨了Cortex R52处理器的各个方面,包括其硬件架构、指令集、调试机制、性能分析以及系统集成与优化。文章首先概述了Cortex R52处理器的特点,并解析了其硬件架构的核心设计理念与组件。接着,本文详细解释了处理器的执行模式,内存管理机制,以及指令集的基础和高级特性。在调试与性能分析方面,文章介绍了Cortex R52的调试机制、性能监控技术和测试策略。最后,本文探讨了Cortex R52与外部组件的集成,实时操作系统支持,以及在特定应
西门子G120变频器安装与调试:权威工程师教你如何快速上手

# 摘要
西门子G120变频器在工业自动化领域广泛应用,其性能的稳定性与可靠性对于提高工业生产效率至关重要。本文首先概述了西门子G120变频器的基本原理和主要组件,然后详细介绍了安装前的准备工作,包括环境评估、所需工具和物料的准备。接下来,本文指导了硬件的安装步骤,强调了安装过程中的安全措施,并提供硬件诊断与故障排除的方法。此外,本文阐述了软件配置与调试的流程,包括控制面板操作、参数设置、调试技巧以及性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )