部署与扩展——web开发框架在生产环境中的应用
发布时间: 2023-12-14 12:31:54 阅读量: 26 订阅数: 36 

web 开发框架
# 一、引言
## a.背景介绍
在现代化的互联网时代,web开发已经成为了一个重要的领域。随着越来越多的企业和个人开始构建自己的网站和应用程序,选择适合的web开发框架显得尤为重要。一个好的开发框架能够提高开发效率,降低维护成本,并且保证系统的可靠性和安全性。
## b.问题陈述
在选择适合的web开发框架时,开发者常常会面临以下问题:
1. 市面上存在众多的web开发框架,如何选择适合自己项目需求的框架?
2. 如何进行框架的部署准备,包括环境配置和依赖管理?
3. 框架的部署过程是否存在安全性考虑?
4. 如何保证框架具备良好的扩展性,能够适应项目的需求变化?
5. 在生产环境中如何进行框架的优化与监控,以提供更好的用户体验和保证系统的稳定性?
### 二、选择适合的web开发框架
a.常见的web开发框架介绍
b.选择适合项目需求的框架
## 三、框架的部署准备
在开始部署选定的Web开发框架之前,我们需要进行一些准备工作。这些工作包括环境配置和依赖管理与安装。
### 环境配置
首先,我们需要确保我们的开发环境满足框架的要求。不同的框架对环境的要求可能有所不同,因此我们需要仔细查阅框架的官方文档以获取准确的配置要求。
- 操作系统:确定框架支持的操作系统,如Windows、Linux等。
- 编程语言:确认框架所使用的编程语言及其版本要求,例如Python3、Java11等。
- 数据库:确定框架所支持的数据库类型和版本,如MySQL、PostgreSQL等。
- Web服务器:了解框架是否需要与特定的Web服务器(如Apache、Nginx)配合使用。
- 其他依赖项:查阅框架的依赖项清单,并确保这些依赖项已经正确安装。
### 依赖管理和安装
在环境配置完成后,我们需要管理和安装框架所依赖的软件和库。根据不同的框架,我们可以选择不同的工具来管理和安装依赖项,例如Python的pip、Java的Maven、Node.js的npm等。
以下是一个示例场景,以Python的Django框架为例:
1. 创建虚拟环境:在项目目录下创建虚拟环境,可以使用`python -m venv myenv`命令来创建一个名为`myenv`的虚拟环境。
2. 激活虚拟环境:使用适当的命令(如`source myenv/bin/activate`)激活虚拟环境,以确保后续的操作仅在该环境中进行。
3. 安装依赖项:使用pip工具安装Django框架及其所需的依赖库,可以通过执行`pip install django`命令来安装Django。
4. 确认安装:使用`pip freeze`命令可以查看当前虚拟环境中已安装的所有库及其版本,确保Django及其依赖项已正确安装。
以上是一个简单的示例,实际操作可能因框架的不同而有所变化。请根据框架的官方文档进行详细的依赖管理和安装工作。
### 四、框架的部署过程
#### a. 安全性考虑
在部署web开发框架时,安全性是至关重要的考虑因素。以下是一些常见的安全性考虑方面:
1. **认证与授权**: 确保只有经过授权的用户可以访问特定的功能和数据。使用框架提供的认证和授权机制,并结合适当的角色管理,以保障系统的安全性。
```python
# Python中使用Flask框架进行基于角色的认证与授权
@app.route('/admin')
@roles_required('admin')
def admin_page():
# 只有具有admin角色的用户可以访问该页面
return render_template('admin.html')
```
2. **输入验证与过滤**: 对于用户输入数据,进行严格的验证和过滤,防止SQL注入、跨站脚本攻击等安全威胁。
```java
// 在Spring框架中使用Hibernate Validator进行输入验证
@NotNull
@Size(min=1, max=20)
private String username;
```
3. **防止跨站请求伪造(CSRF)**: 使用框架提供的CSRF保护机制,确保用户提交的表单数据不被恶意篡改。
```html
<!-- 在HTML中使用Django框架提供的CSRF token保护 -->
<form method="post">
{% csrf_token %}
<!-- 其他表单字段 -->
<input type="submit" value="Submit">
</form>
```
#### b. 代码部署与调试
1. **版本控制与持续集成**: 使用版本控制工具(如Git)对代码进行管理,并结合持续集成工具(如Jenkins)进行自动化部署和测试,以确保代码的稳定性和可靠性。
```yaml
# 集成Jenkins进行持续集成和部署
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'mvn clean package'
}
}
stage('Deploy') {
steps {
sh 'ansible deploy.yml'
}
}
}
}
```
2. **日志记录与调试**: 在框架中合理地记录日志,并使用调试工具进行错误排查和修复,以提高代码的可维护性和可靠性。
```javascript
// 在Node.js中使用Winston进行日志记录
const winston = require('winston');
const logger = winston.createLogger({
format: winston.format.combine(
winston.format.timestamp(),
winston.format.json()
),
transports: [
new winston.transports.File({ filename: 'error.log', level: 'error' }),
new winston.transports.File({ filename: 'combined.log' })
]
});
```
### 五、框架的扩展性考虑
在选择适合项目需求的web开发框架后,我们需要考虑框架的扩展性,以便未来能够轻松地引入新功能、组件和插件。在本节中,我们将讨论框架的模块化设计与可拔插扩展,以及如何选择可扩展组件与插件。
#### a. 模块化设计与可拔插扩展
1. **模块化设计:** 一个良好的web开发框架应该支持模块化设计,使得不同功能模块之间能够相互独立、解耦合。这样一来,我们可以更容易地引入新的模块,或者更新现有的模块,而不会对整个系统造成影响。
2. **可拔插扩展:** 框架的扩展性也是非常重要的,我们希望能够通过简单的配置或代码编写,将新的功能或插件无缝地集成到现有的框架中。这样做可以大大提高开发效率,并且为未来的功能扩展提供了更灵活的可能性。
#### b. 如何选择可扩展组件与插件
1. **组件选择原则:** 当我们需要引入新的组件来扩展框架功能时,我们应该考虑以下几个原则:
- 组件的稳定性和可靠性
- 组件的维护和更新频率
- 组件是否符合当前项目的技术栈和架构设计
2. **插件选择指南:** 在选择适合的插件时,我们需要考虑以下几点:
- 插件的兼容性和易用性
- 插件的性能和安全性
- 插件的社区支持和文档完善程度
六、生产环境中的优化与监控
### a.性能优化策略
在部署和运行框架的生产环境中,性能优化是一个非常重要的考虑因素。以下是一些常用的性能优化策略:
1. 缓存优化:通过使用缓存技术减少数据库或网络请求,提高访问速度。可以使用内存缓存(如Redis、Memcached)、数据库缓存(如数据库查询缓存)以及页面缓存等方式来进行优化。
2. 数据库优化:针对数据库的性能问题,可以通过对数据库进行索引优化、查询优化以及数据库连接池的配置等方式来提高性能。
3. 并发优化:通过增加服务器的并发处理能力来提高性能。可以考虑使用负载均衡、分布式部署以及异步处理等方式来实现并发优化。
4. 前端优化:优化前端资源加载速度,如合并和压缩CSS和JavaScript文件、使用CDN加速、使用图片懒加载、浏览器缓存等方式。
5. 性能监控:使用监控工具对系统性能进行监控,例如监控服务器的CPU、内存、磁盘和网络使用情况,及时发现和解决性能瓶颈问题。
### b.常见问题的排查与修复
在线上环境中,可能会遇到各种性能问题和异常情况。以下是一些常见问题的排查和修复方法:
1. 高负载问题:当系统负载过高时,可以通过调整服务器配置、优化数据库查询、增加服务器数量等方式来解决问题。
2. 内存泄漏问题:当系统内存占用过高或者内存泄漏时,可以通过内存分析工具来定位问题,并及时修复。
3. 长耗时请求:当某个请求耗时较长时,可以通过日志和性能监控工具查看具体耗时点,优化代码逻辑或者进行异步处理来提高性能。
4. 数据库连接问题:当出现数据库连接过多或者连接池不足的情况时,可以调整数据库连接池配置或者增加连接池数量来解决问题。
5. 外部资源依赖问题:当系统依赖的外部资源(如API、第三方服务)出现故障或者性能问题时,可以通过对依赖进行监控和容错处理来提高系统稳定性。
总之,生产环境中的优化与监控是一个持续进行的过程,需要不断地进行性能测试、排查问题并进行优化,在保证系统稳定性和高性能的基础上提供更好的用户体验。
【代码总结】:
在生产环境中,性能优化是至关重要的。常见的性能优化策略包括缓存优化、数据库优化、并发优化、前端优化以及性能监控。此外,常见问题的排查和修复方法包括解决高负载问题、内存泄漏问题、长耗时请求、数据库连接问题以及外部资源依赖问题。
【结果说明】:

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以自主编写web开发框架为主题,通过一系列文章深入探讨了web开发框架的核心概念和基本结构。首先从概述与基本结构开始,逐步介绍了HTTP协议与web开发框架的关系,MVC架构在框架中的作用与实现,以及与数据库的集成实现。接着,重点讲解了表单数据处理、URL路由与视图函数的应用,以及用户认证与授权功能的实现。随后,深入探讨了模板引擎实现动态页面、构建RESTful API以及文件上传与下载功能在框架中的实现。然后,着重介绍了缓存技术与性能优化、集成第三方API与服务,以及日志记录与错误处理方面的内容。最后,讨论了部署与扩展、使用测试框架进行单元测试与集成测试、代码质量保证,以及使用Docker部署框架和性能监测与优化等主题。通过本专栏的学习,读者可以全面了解web开发框架的设计原理与实现,并能在实际项目中运用所学知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【调试与诊断】:cl.exe高级调试技巧,让代码问题无所遁形
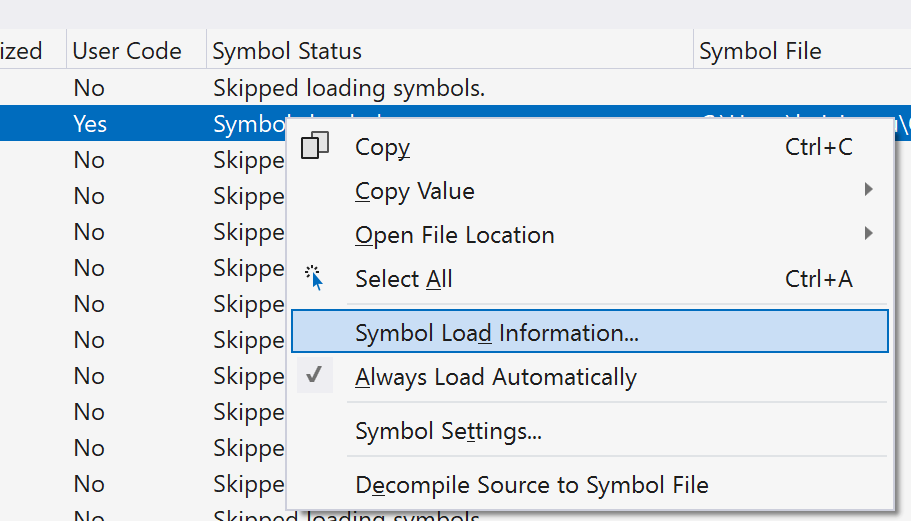
# 摘要
本文围绕软件开发的调试与诊断技术进行了深入探讨,特别是聚焦于Microsoft Visual Studio环境中的cl.exe编译器。文章首先介绍了调试与诊断的基础知识,随后详细解析了cl.exe编译器的使用、优化及调试符号管理。高级
【多核系统中Xilinx Tri-Mode MAC的高效应用】:架构设计与通信机制

# 摘要
本文深入探讨了多核系统环境下网络通信的优化与维护问题,特别关注了Xilinx Tri-Mode MAC架构的关键特性和高效应用。通过对核心硬件设计、网络通信协议、多核处理器集成以及理论模型的分析,文章阐述了如何在多核环境中实现高速数据传输与任务调度。本文还提供了故障诊断技术、系统维护与升级策略,并通过案例研究,探讨了Tri-Mode MAC在高性能计算与数据中心的应用
【APQC五级设计框架深度解析】:企业流程框架入门到精通

# 摘要
APQC五级设计框架是一个综合性的企业流程管理工具,旨在通过结构化的方法提升企业的流程管理能力和效率。本文首先概述了APQC框架的核心原则和结构,强调了企业流程框架的重要性,并详细描述了框架的五大级别和流程分类方法。接着,文章深入探讨了设计和实施APQC框架的方法论,包括如何识别关键流程、确定流程的输入输出、进行现状评估、制定和执行实施计划。此外,本文还讨论了APQC
ARINC653标准深度解析:航空电子实时操作系统的设计与应用(权威教程)

# 摘要
ARINC653作为一种航空航天领域内应用广泛的标准化接口,为实时操作系统提供了一套全面的架构规范。本文首先概述了ARINC653标准,然后详细分析了其操作系统架构及实时内核的关键特性,包括任务管理和时间管理调度、实时系统的理论基础与性能评估,以及内核级通信机制。接着,文章探讨了ARINC653的应用接口(
【软件仿真工具】:MATLAB_Simulink在倒立摆设计中的应用技巧
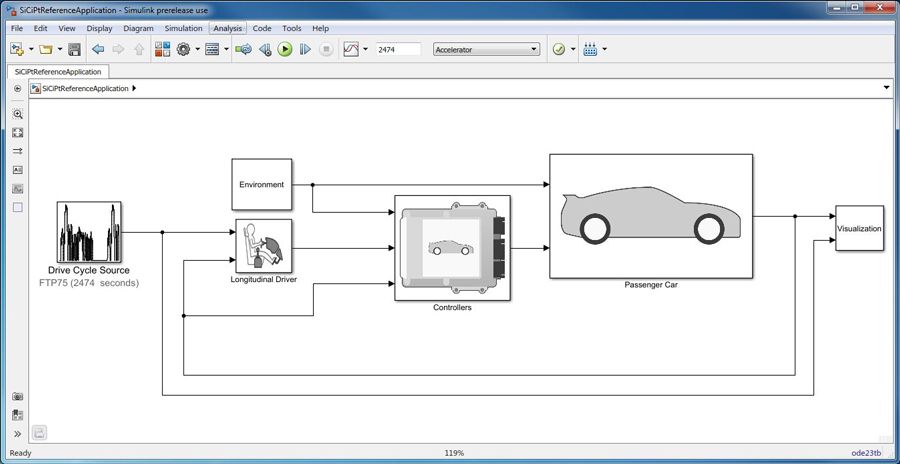
# 摘要
本文系统地介绍了MATLAB与Simulink在倒立摆系统设计与控制中的应用。文章首先概述
自动化测试与验证指南:高通QXDM工具提高研发效率策略

# 摘要
随着移动通信技术的快速发展,高通QXDM工具已成为自动化测试和验证领域不可或缺的组件。本文首先概述了自动化测试与验证的基本概念,随后对高通QXDM工具的功能、特点、安装和配置进行了详细介绍。文章重点探讨了QXDM工具在自动化测试与验证中的实际应用,包括脚本编写、测试执行、结果分析、验证流程设计及优化策略。此外,本文还分析了QXDM工具如何提高研发效率,并探讨了其技术发展趋势以及
C语言内存管理:C Primer Plus第六版指针习题解析与技巧

# 摘要
本论文深入探讨了C语言内存管理和指针应用的理论与实践。第一章为C语言内存管理的基础介绍,第二章系统阐述了指针与内存分配的基本概念,包括动态与静态内存、堆栈管理,以及指针类型与内存地址的关系。第三章对《C Primer Plus》第六版中的指针习题进行了详细解析,涵盖基础、函数传递和复杂数据结构的应用。第四章则集中于指针的高级技巧和最佳实践,重点讨论了内存操作、防止内存泄漏及指针错
【PDF元数据管理艺术】:轻松读取与编辑PDF属性的秘诀

# 摘要
本文详细介绍了PDF元数据的概念、理论基础、读取工具与方法、编辑技巧以及在实际应用中的案例研究。PDF元数据作为电子文档的重要组成部分,不仅对文件管理与检索具有关键作用,还能增强文档的信息结构和互操作性。文章首先解析了PDF文件结构,阐述了元数据的位置和作用,并探讨了不同标准和规范下元数据的特点。随后,本文评述了多种读取PDF元数据的工具和方法,包括命令行和图形用户
中兴交换机QoS配置教程:网络性能与用户体验双优化指南
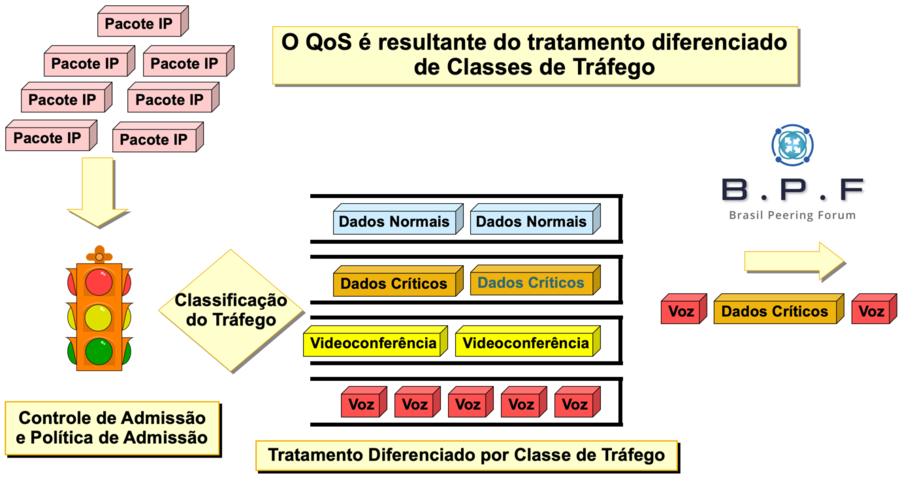
# 摘要
随着网络技术的快速发展,服务质量(QoS)成为交换机配置中的关键考量因素,直接影响用户体验和网络资源的有效管理。本文详细阐述了QoS的基础概念、核心原则及其在交换机中的重要性,并深入探讨了流量分类、标记、队列调度、拥塞控制和流量整形等关键技术。通过中兴交换机的配置实践和案例研究,本文展示了如何在不同网络环境中有效地应用QoS策略,以及故障排查
工程方法概览:使用MICROSAR进行E2E集成的详细流程
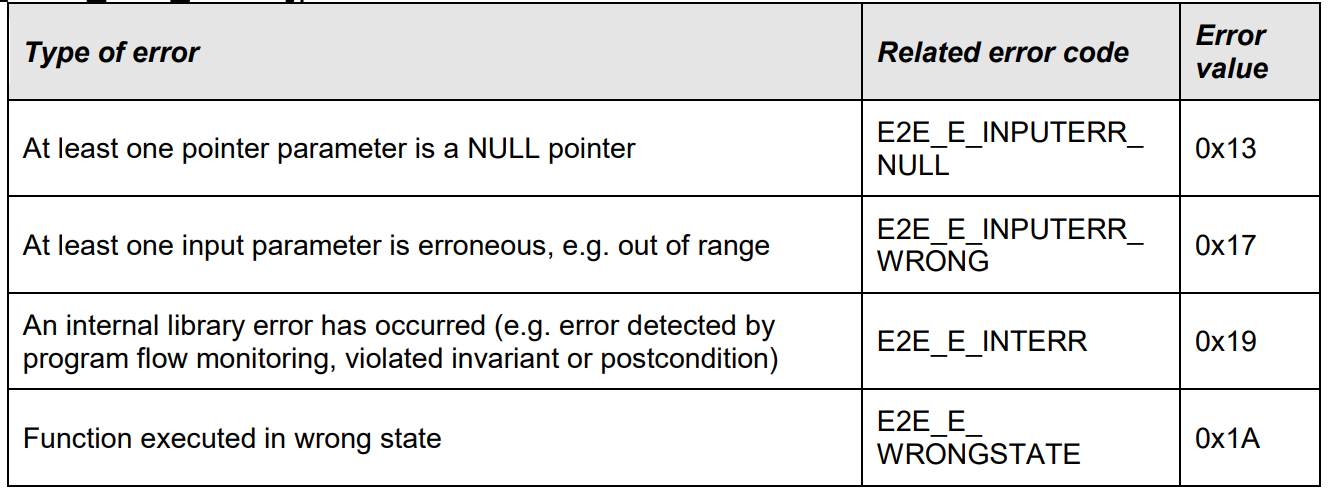
# 摘要
本文全面阐述了MICROSAR基础和其端到端(E2E)集成概念,详细介绍了MICROSAR E2E集成环境的建立过程,包括软件组件的安装配置和集成开发工具的使用。通过实践应用章节,分析了E2E集成在通信机制和诊断机制的实现方法。此外,文章还探讨了E2E集成的安全机制和性能优化策略,以及通过项目案例分析展示了E2E集成在实际项目中的应用,讨论了遇到的问题和解决方案,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )