了解HTTP及其在网络通信中的作用
发布时间: 2024-03-31 02:49:31 阅读量: 39 订阅数: 26 

深入理解HTTP协议
# 1. HTTP的基础概念
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于传输超媒体文档(如HTML)的协议。在互联网上,HTTP是客户端和服务器之间进行通信的基础。本章将介绍HTTP的基本概念、发展历史、工作原理以及与HTTPS的区别。
## 1.1 什么是HTTP
HTTP是一种应用层协议,主要用于传输超文本文档(如网页)中的数据,基于请求-响应模型。客户端发送HTTP请求到服务器,服务器处理请求后返回HTTP响应给客户端。HTTP通常基于TCP连接,在端口80上进行通信。
## 1.2 HTTP的发展历史
HTTP的发展经历了多个版本,从最初的HTTP/0.9到目前广泛应用的HTTP/1.1和HTTP/2。每个版本都在不断优化以提高性能和安全性。
## 1.3 HTTP的工作原理
HTTP工作原理是通过请求-响应模型实现的。客户端发送HTTP请求给服务器,请求包括请求方法、URL、协议版本等信息;服务器接收请求后处理,并返回HTTP响应,包括状态码、响应头部和响应体。
## 1.4 HTTP与HTTPS的区别
HTTPS是在HTTP基础上加入了加密处理,通过SSL/TLS协议进行数据加密传输,提高了通信安全性。HTTPS通常运行在安全的传输层上,使用加密的443端口进行通信,相比HTTP更安全可靠。
# 2. HTTP请求与响应
HTTP协议是一种无状态的协议,客户端通过发送请求到服务器来获取资源,服务器接收请求后返回响应。在HTTP请求与响应中,包含了一系列的信息,包括请求方法、请求头部、请求体以及响应状态码等内容。下面将详细介绍HTTP请求与响应的相关概念以及使用方法。
### 2.1 HTTP请求方法
在HTTP协议中,定义了多种请求方法,常见的包括:
- GET:用于请求指定资源
- POST:向指定资源提交数据进行处理,常用于表单提交
- PUT:向指定资源位置上传新的内容
- DELETE:请求服务器删除指定资源
- HEAD:类似于GET请求,只返回请求头部信息而不返回实体主体
- OPTIONS:用于查询指定资源的支持方法
下面是一个使用Python的requests库发送GET请求的示例代码:
```python
import requests
response = requests.get("https://www.example.com")
print(response.text)
```
**代码说明:**
- 使用requests库发送了一个GET请求到"https://www.example.com"
- 打印了服务器返回的响应内容
**结果说明:**
- 打印出了请求到的网页内容
### 2.2 HTTP请求头部
HTTP请求头部包含了关于请求的各种信息,常见的请求头部包括:
- User-Agent:浏览器或客户端的信息
- Accept:客户端能够接收的内容类型
- Content-Type:请求体的类型
- Authorization:身份验证信息
下面是一个使用Python的requests库设置请求头部的示例代码:
```python
import requests
headers = {
'User-Agent': 'Mozilla/5.0',
'Accept': 'application/json'
}
response = requests.get("https://api.example.com", headers=headers)
```
**代码说明:**
- 定义了一个包含User-Agent和Accept的请求头部字典
- 使用requests库发送了一个带有自定义请求头部的GET请求到"https://api.example.com"
**结果说明:**
- 请求会带有自定义的请求头部信息发送到服务器,并收到响应
### 2.3 HTTP请求体
在一些请求中,需要发送数据到服务器,此时请求体就会起到作用。常见的情况包括使用POST方法提交表单数据或上传文件等。
下面是一个使用Python的requests库发送POST请求的示例代码:
```python
import requests
data = {
'username': 'example_user',
'password': 'example_password'
}
response = requests.post("https://api.example.com/login", data=data)
print(response.text)
```
**代码说明:**
- 定义了一个包含用户名和密码的数据字典
- 使用requests库发送了一个带有数据的POST请求到"https://api.example.com/login"
- 打印了服务器返回的响应内容
**结果说明:**
- 打印出了登录接口返回的数据
### 2.4 HTTP响应状态码
HTTP响应状态码用于表示服务器对请求的处理结果,常见的状态码包括:
- 200:成功
- 404:未找到
- 500:服务器错误
- 302:重定向
在使用requests库时,可以通过response.status_code获取服务器返回的状态码。
以上就是关于HTTP请求与响应的基本知识和示例代码,通过学习这些内容可以更好地掌握如何使用HTTP协议与服务器进行通信。
# 3. HTTP的连接管理
HTTP的连接管理对于网络通信的效率和性能有着重要影响,本章将介绍HTTP的连接管理相关内容。
#### 3.1 HTTP持久连接
HTTP持久连接是指客户端和服务器建立一次TCP连接后可以在一次连接中传输多个HTTP请求和响应。这种机制可以减少建立和关闭连接的开销,提高数据传输的效率。在HTTP/1.1中,默认开启了持久连接。
```python
import requests
# 使用Session对象实现HTTP持久连接
with requests.Session() as session:
response1 = session.get('https://www.example.com/page1')
response2 = session.get('https://www.example.com/page2')
print(response1.text)
print(response2.text)
```
**代码说明:**
1. 创建一个Session对象,该对象会在内部自动处理持久连接的逻辑。
2. 使用Session对象发送多个HTTP请求,这些请求会共享同一个TCP连接。
**结果说明:**
- 以上代码发送了两个HTTP GET请求,共享了同一个TCP连接,提高了数据传输效率。
#### 3.2 HTTP管线化
HTTP管线化允许在一个TCP连接上连续发送多个HTTP请求,而不必等待响应返回后再发送下一个请求。这种方式在一定程度上减少了网络传输的延迟。
```java
import java.net.*;
import java.io.*;
// 使用HTTP管线化发送多个请求
public class HttpClient {
public static void main(String[] args) {
String[] urls = {"https://www.example.com/page1", "https://www.example.com/page2"};
try {
URL url = new URL("https://www.example.com");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setUseCaches(false);
conn.setDoOutput(true);
conn.setRequestProperty("Connection", "Keep-Alive");
for (String u : urls) {
conn.setRequestMethod("GET");
conn.setRequestProperty("Content-Type", "application/json");
conn.getOutputStream().flush();
}
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
reader.close();
conn.disconnect();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
**代码说明:**
1. 创建一个HTTP连接,并设置Connection为Keep-Alive,启用HTTP管线化。
2. 连续发送多个GET请求,减少了请求间的等待时间。
**结果说明:**
- 以上代码通过HTTP管线化方式发送了多个请求,并在同一个TCP连接上实现了请求的连续传输。
#### 3.3 HTTP2.0的多路复用
HTTP2.0引入了多路复用机制,允许在一个连接上同时传输多个请求和响应,避免了HTTP/1.x中存在的队头阻塞问题,提高了性能。
```go
package main
import (
"fmt"
"net/http"
)
func main() {
client := &http.Client{}
req1, _ := http.NewRequest("GET", "https://www.example.com/page1", nil)
req2, _ := http.NewRequest("GET", "https://www.example.com/page2", nil)
resp1, _ := client.Do(req1)
resp2, _ := client.Do(req2)
fmt.Println(resp1.Status)
fmt.Println(resp2.Status)
}
```
**代码说明:**
1. 创建一个HTTP Client对象,用于发送HTTP请求。
2. 使用HTTP/2多路复用机制同时发送多个请求,提高了性能。
**结果说明:**
- 以上代码展示了通过HTTP2.0多路复用实现的多个请求同时传输的效果,提升了网络传输效率。
# 4. HTTP的安全性
在网络通信中,保障数据的安全性至关重要。HTTP协议本身并不具备很强的安全性,因此衍生出了HTTPS协议等更加安全的通信方式。在本章节中,我们将详细探讨HTTP的安全性问题及相关解决方案。
#### 4.1 HTTP加密传输
HTTP在传输过程中是明文传输的,这意味着网络中的任何一方都可以窃听通信双方之间传输的数据,造成信息泄露的风险。为了保证数据传输的安全性,可以通过对HTTP通信进行加密处理来防止被恶意获取敏感信息。
下面是一个使用Python的示例代码,演示了如何使用HTTP库发送加密的HTTP请求:
```python
import requests
url = 'https://www.example.com'
response = requests.get(url)
print(response.text)
```
**代码说明:**
- 通过Python的`requests`库发送HTTPS请求。
- 通过`get`方法获取指定URL的内容。
- 打印响应内容。
**结果说明:**
如果目标网站支持HTTPS,那么这段代码会使用加密传输进行通信,保证数据隐私和完整性。
#### 4.2 HTTPS的工作原理
HTTPS是在HTTP的基础上加入了SSL/TLS协议进行加密通信的协议,其工作原理主要包括以下几个步骤:
1. 客户端发起HTTPS请求。
2. 服务端返回数字证书。
3. 客户端验证数字证书合法性。
4. 客户端生成对称加密密钥,用服务端公钥加密后发送给服务端。
5. 服务端使用私钥解密获取对称加密密钥。
6. 双方使用对称加密密钥进行加密通信。
#### 4.3 SSL/TLS协议
SSL(Secure Sockets Layer)和TLS(Transport Layer Security)是用于加密通信的安全协议,用于在客户端与服务器之间建立安全的通信连接。SSL已经被TLS所取代,TLS的最新版本是TLS 1.3,其安全性和性能优于之前的版本。
以上是关于HTTP安全性的内容,希望能够帮助读者更好地了解HTTP协议的安全机制。
# 5. HTTP缓存与内容协商
在本章中,我们将深入探讨HTTP缓存与内容协商的相关概念,这对于优化网站性能和减少网络流量至关重要。
### 5.1 HTTP缓存机制
HTTP缓存是指在客户端或服务器端存储先前获取的资源副本,以便将来重复使用,从而加快访问速度。HTTP缓存可以减少网络延迟、降低服务器压力,并提高用户体验。
#### 代码示例 - 使用Python实现简单的HTTP缓存控制
```python
from flask import Flask, Response
import datetime
app = Flask(__name__)
@app.route('/cached_resource')
def cached_resource():
response = Response("This is a cached resource", status=200)
expires = datetime.datetime.now() + datetime.timedelta(days=7)
response.headers['Cache-Control'] = 'max-age=604800, public'
response.headers['Expires'] = expires.strftime('%a, %d %b %Y %H:%M:%S GMT')
return response
if __name__ == '__main__':
app.run()
```
**注释:** 上述代码展示了如何在Python中使用Flask框架实现简单的HTTP缓存控制,通过设置`Cache-Control`和`Expires`头部来指定资源的缓存策略。
**代码总结:** 通过控制缓存的`max-age`和`Expires`时间,可以控制资源在客户端或代理服务器中的缓存时间。
**结果说明:** 当客户端第一次请求`/cached_resource`资源时会返回资源并将其缓存,之后再次请求时,客户端会根据缓存策略判断是否要直接使用缓存的资源。
### 5.2 缓存控制头部
HTTP缓存可以通过一系列的缓存控制头部来控制缓存的行为,常见的头部包括`Cache-Control`、`Expires`、`Last-Modified`、`ETag`等,这些头部可以指导客户端和服务器如何处理缓存。
### 5.3 客户端与服务器的缓存协商
在HTTP缓存中,客户端和服务器之间进行缓存协商,以确定是否需要重新请求资源。常见的协商方式有**验证缓存**和**协商缓存**,客户端可以通过发送`If-Modified-Since`或`If-None-Match`头部来告知服务器资源的最后修改时间或实体标签,从而由服务器判断是否返回304 Not Modified响应。
通过合理地设置缓存策略和进行缓存协商,可以有效减少不必要的网络流量和加快网站的加载速度。
# 6. HTTP的进阶应用
在现代web开发中,HTTP已经不再仅仅限于传输网页内容。它还被广泛应用于构建API、实现实时通讯等高级功能。本章将介绍HTTP的进阶应用,包括RESTful API基于HTTP、GraphQL与HTTP以及WebSockets与HTTP的结合使用。
#### 6.1 RESTful API基于HTTP
REST(Representational State Transfer)是一种设计风格,它提供了一套架构约束和原则,用于构建可靠性更高、更具可扩展性的网络应用系统。而RESTful API则是符合REST风格的API设计。在RESTful API中,HTTP协议的各种方法如GET、POST、PUT、DELETE等被用来操作资源。以下是一个简单的RESTful API示例:
```python
from flask import Flask, jsonify
app = Flask(__name__)
tasks = [
{
'id': 1,
'title': 'Learn Python',
'done': False
},
{
'id': 2,
'title': 'Build RESTful API',
'done': False
}
]
@app.route('/tasks', methods=['GET'])
def get_tasks():
return jsonify({'tasks': tasks})
if __name__ == '__main__':
app.run(debug=True)
```
**代码解释:**
- 第2行:导入Flask模块
- 第4-8行:定义了一组示例任务数据
- 第10-16行:定义了一个GET请求的路由`/tasks`,返回任务列表
- 第18-20行:运行Flask应用
通过以上代码,我们可以创建一个简单的RESTful API,可以通过发送GET请求获取任务列表。
#### 6.2 GraphQL与HTTP
GraphQL是一个由Facebook开发的查询语言,它允许客户端按需获取需要的数据,避免了Over-fetching和Under-fetching的问题。在GraphQL中,客户端可以明确指定需要的数据结构,而服务器会返回对应的数据,这种灵活性使得GraphQL在API开发中越来越受欢迎。以下是一个简单的GraphQL示例:
```javascript
const { graphql, buildSchema } = require('graphql');
const schema = buildSchema(`
type Query {
hello: String
}
`);
const root = {
hello: () => 'Hello, World!'
};
graphql(schema, '{ hello }', root).then((response) => {
console.log(response);
});
```
**代码解释:**
- 第1行:引入graphql和buildSchema
- 第3-5行:定义了一个简单的查询结构
- 第7-9行:创建了一个包含`hello`字段的查询解析器
- 第11行:执行GraphQL查询,输出`Hello, World!`
通过以上代码,我们可以看到如何使用GraphQL执行一个简单的查询并获取数据。
#### 6.3 WebSockets与HTTP
WebSockets是一种在单个TCP连接上进行全双工通信的协议。与HTTP不同,WebSockets允许服务器主动向客户端推送数据,而不需要客户端先发起请求。在实时应用中,如在线游戏、聊天室等,WebSockets是一种非常有用的技术。以下是一个简单的WebSockets示例:
```javascript
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', (ws) => {
console.log('Client connected');
ws.on('message', (message) => {
console.log(`Received message: ${message}`);
});
ws.send('Hello, Client! Welcome to the WebSocket server.');
});
```
**代码解释:**
- 第1行:引入WebSocket模块
- 第3行:创建WebSocket服务器实例,监听8080端口
- 第5-10行:处理客户端连接和消息
- 第12行:向客户端发送消息
通过以上代码,我们可以实现一个简单的WebSocket服务器,与客户端进行实时双向通信。
在本章中,我们介绍了RESTful API、GraphQL以及WebSockets这些HTTP的进阶应用,它们为开发者提供了更丰富和灵活的选择,使得HTTP在各种应用场景中发挥更大的作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在帮助Java开发人员深入了解和掌握通过HTTP接口进行网络通信的相关知识和技术。从HTTP协议的基础概念到GET和POST方法的应用区别,从HttpURLConnection和HttpClient的性能对比到OkHttp库的最佳实践,再到RESTful风格接口设计原则的讲解,本专栏涵盖了Java中各种HTTP通信相关主题,同时还涉及到数据加密、超时处理、异常处理等细节问题。我们将详细探讨Java中URL、HttpURLConnection、Apache HttpClient、RestTemplate等工具类和库的用法,以及在实际项目中如何构建HTTP接口调用服务,实现请求重试机制以及确保数据传输的安全性。通过学习本专栏,读者将能够全面掌握Java中HTTP接口调用的要点与最佳实践,提升开发效率与代码质量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ASR3603性能测试指南:datasheet V8助你成为评估大师

# 摘要
本论文全面介绍了ASR3603性能测试的理论与实践操作。首先,阐述了性能测试的基础知识,包括其定义、目的和关键指标,以及数据表的解读和应用。接着,详细描述了性能测试的准备、执行和结果分析过程,重点讲解了如何制定测试计划、设计测试场景、进行负载测试以及解读测试数据。第三章进一步
【安全设计,可靠工作环境】:安川机器人安全性设计要点

# 摘要
本文全面探讨了安川机器人在安全性方面的理论和实践。首先概述了安川机器人安全性的重要性,并详细介绍了其基本安全特性,包括安全硬件设计、安全软件架构以及安全控制策略。随后,文章分析了安川机器人安全功能的应用,特别是在人机协作、高级安全配置以及安全测试与认证方面的实践。面对实际应用中遇到的挑战,本文讨论了安
【数字电路实验】:四位全加器设计案例,Quartus II全解析
# 摘要
本论文深入探讨了四位全加器的设计原理和实现过程,重点在于利用Quartus II软件和硬件描述语言(HDL)进行设计和测试。首先,介绍
【安全编程实践】:如何防止攻击,提升单片机代码的鲁棒性?

# 摘要
本文深入探讨了单片机安全编程的重要性,从基础概念到高级技巧进行全面概述。首先介绍了单片机面临的安全风险及常见的攻击类型,并对安全编程的理论基础进行了阐述。在此基础上,本文进一步分析了强化单片机编程安全性的策略,包括输入验证、内存保护、安全通信和加密技术的应用。最后,通过实战案例分析,展示了如何在实际开发中应用这些策略
环境影响下的电路性能研究:PSpice温度分析教程(必须掌握)
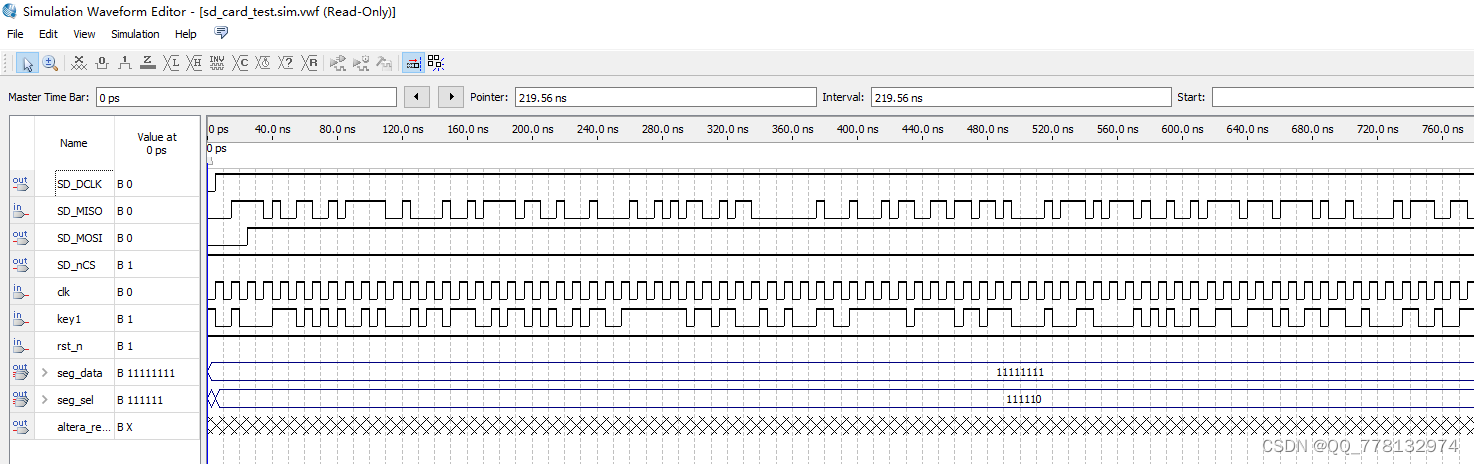
# 摘要
本文探讨了电路仿真与环境因素的关联,并深入分析了PSpice软件的工作原理、温度分析的基础知识及其在电路设计中的应用。文章首先介绍了PSpice软件及其温度模型的配置方法,然后详述了温度对电路元件性能的影响,并讨论了如何设计仿真实验来评估这些影响。接着,本文探讨了多环境温度下电路性能仿真的高级应用,并提出了散热设计与电路稳定性的关系及其验证方法。最后,文章展望了未来电路设计中温度管理的创新方法,包括新型材料的温度控制技术、
【城市交通规划】:模型对实践指导的6大实用技巧

# 摘要
城市交通规划对于缓解交通拥堵、提升城市运行效率以及确保可持续发展至关重要。本文首先介绍了城市交通规划的重要性与面临的挑战,接着深入探讨了交通规划的基础理论,包括交通流理论、需求分析、数据采集方法等。在实践技巧章节,本文分析了模型选择、拥堵解决策略和公共交通系统规划的实际应用。此外,现代技术在交通规划中的应用,如智能交通系统(ITS)、大数
人工智能算法精讲与技巧揭秘:王万森习题背后的高效解决方案
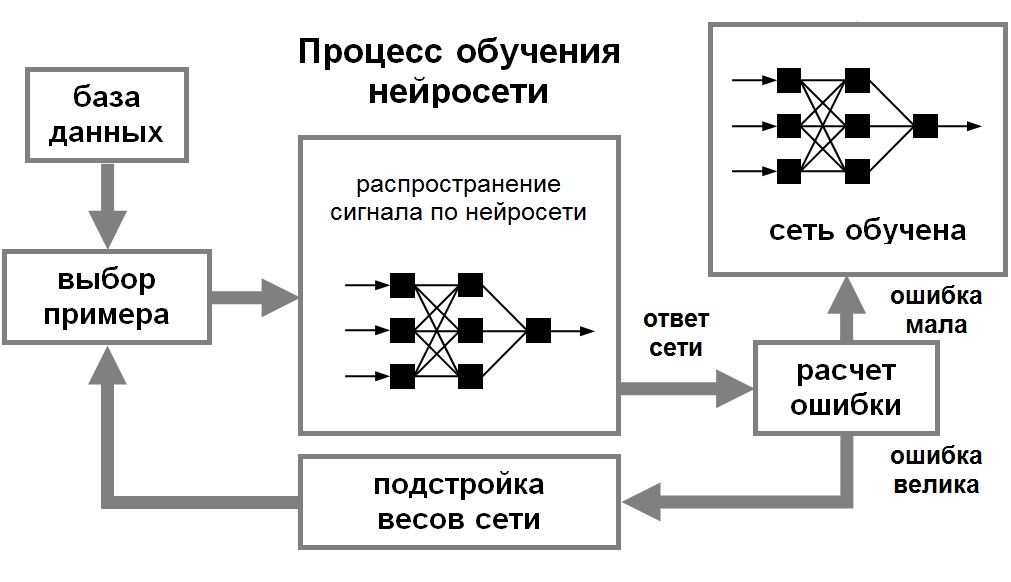
# 摘要
本论文全面探讨了人工智能算法的基础、核心算法的理论与实践、优化算法的深入剖析、进阶技巧与实战应用以及深度学习框架的使用与技巧。首先介绍了人工智能算法的基本概念,接着详细解析了线性回归、逻辑回归、决策树与随机森林等核心算法,阐述了梯度下降法、正则化技术及神经网络优化技巧。随后,探讨了集成学习、数据预处理、模型评估与选择等算法进阶技巧,并给出了实战应用案例。最
BTN7971驱动芯片应用案例精选:电机控制的黄金解决方案
# 摘要
本文全面介绍了BTN7971驱动芯片,探讨了其在电机控制理论中的应用及其实践案例。首先概述了BTN7971的基本工作原理和电机控制的基础理论,包括H桥电路和电机类型。其次,详细分析了BTN7971在电机控制中的性能优势和高级技术应用,例如控制精度和PWM调速技术。文中还提供了 BTN7971在不同领域,如家用电器、工业自动化和电动交通工具中的具体应用案例。最后,本文展望了BTN7971在物联网时代面临的趋势和挑战,并讨论了未来发展的方向,包括芯片技术的迭代和生态系统构建。
# 关键字
BTN7971驱动芯片;电机控制;PWM调速技术;智能控制;热管理;生态构建
参考资源链接:[B
【电力电子技术揭秘】:斩控式交流调压电路的高效工作原理
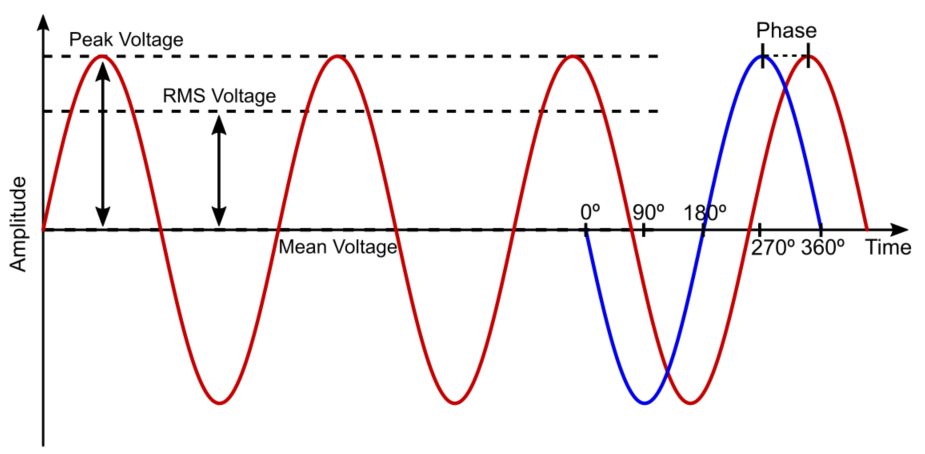
# 摘要
斩控式交流调压电路是电力电子技术中的一个重要应用领域,它通过控制斩波器的导通和截止来实现对交流电压的精确调节。本文首先概述了斩控式交流调压电路的基本概念,接着详细介绍了电力电子技术的基础理论、交流电的基础知识以及斩控技术的工作原理。第三章深入探讨了斩控式交流调压电路的设计,包括电路设计原则、元器件选型分析以及控制策略的实现。第四章和第五章分别介绍了电路的模拟与仿真以及实验与实践,分析了仿真测试流程和实验数据,提供了性能
【RN8209D固件升级攻略】:顺利升级的步骤与关键点
# 摘要
本文全面探讨了RN8209D固件升级的全过程,从前期准备到升级操作步骤,再到升级后的优化与维护以及高级定制。重点介绍了升级前的准备工作,包括硬件和软件的兼容性检查、升级工具的获取以及数据备份和安全措施。详细阐述了固件升级的具体操作步骤,以及升级后应进行的检查与验证。同时,针对固件升级中可能遇到的硬件不兼容、软件升级失败和数据丢失等问题提供了详尽的解决方案。最后,本文还探讨了固件升级后的性能优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )