Anaconda新手必读:6步搭建最佳Python科学计算环境
发布时间: 2024-12-10 02:00:42 阅读量: 22 订阅数: 14 

Python科学计算环境推荐——Anaconda
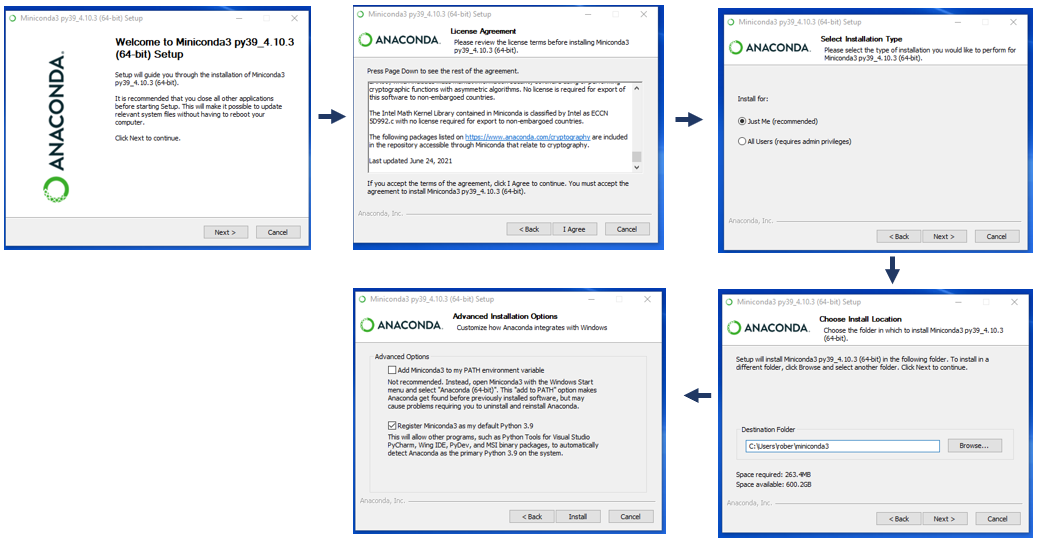
# 1. Anaconda简介与科学计算的重要性
## 1.1 Anaconda概述
Anaconda是一个流行的开源科学计算发行版,它集成了包管理和环境管理工具conda,并且包含了如NumPy、SciPy、Pandas和Matplotlib等超过7200个科学计算相关的开源库。Anaconda致力于简化包管理和部署流程,使得数据科学家和IT从业者能够轻松地进行数据分析、机器学习和高性能计算。
## 1.2 科学计算的重要性
在信息科技高速发展的今天,数据已成为新的自然资源。科学计算是利用计算机进行科学问题求解的一种方法,涵盖了数学建模、数值计算、算法开发、图形可视化等多个方面。它在工程、科研、金融、生物信息等众多领域扮演着越来越重要的角色。因此,能够熟练掌握并使用合适的科学计算工具,对提高工作效率和质量具有决定性意义。
接下来的章节,我们将深入了解Anaconda的安装、环境配置以及它如何与Python基础科学计算库协同工作,从而构建一个高效、可靠的数据科学工作环境。
# 2. Anaconda安装与环境配置
## 2.1 下载与安装Anaconda
### 2.1.1 选择合适的Anaconda版本
Anaconda是一个强大的Python分发包,它包含了众多科学计算所需要的库。选择合适的Anaconda版本是开始使用Anaconda的第一步。下载之前,应考虑以下几个因素:
- 操作系统:Anaconda支持Windows、macOS和Linux。
- Python版本:建议选择与项目需求相符的最新稳定版Python。
- 需要的预装包:根据项目需求,选择包含常用科学计算库的Miniconda或预装更多库的Anaconda。
在选择版本时,通常推荐最新稳定版本,因为它们包含了最新的安全补丁和性能改进。对于有特定需求的用户,也可以考虑长期支持版(LTS)。
### 2.1.2 安装过程中的常见问题及解决方案
Anaconda的安装过程相对简单,但用户在安装过程中可能会遇到一些问题。以下是一些常见问题及其解决方案:
- **权限问题**:在Windows系统中,以管理员身份运行安装程序;在Linux或macOS上,使用sudo命令。
- **安装路径权限**:确保安装路径对当前用户有读写权限。
- **环境变量冲突**:在安装过程中不要勾选“Add Anaconda to my PATH environment variable”选项,以避免与已存在的Python环境冲突。安装完成后,可手动将Anaconda路径添加到环境变量中。
- **依赖问题**:在安装过程中,根据提示确保所有依赖包被正确安装。
## 2.2 管理Anaconda环境
### 2.2.1 创建和管理虚拟环境
虚拟环境在Anaconda中是一个非常重要的概念。它可以让你在同一台机器上同时运行多个项目,每个项目都有自己的依赖库和Python版本。
- **创建环境**:使用`conda create`命令创建新环境。例如,创建一个名为`myenv`的环境,使用Python 3.8版本:
```bash
conda create -n myenv python=3.8
```
- **激活环境**:使用`conda activate`命令激活环境:
```bash
conda activate myenv
```
- **列出环境**:使用`conda env list`命令列出所有已创建的环境。
- **删除环境**:使用`conda remove --name myenv --all`命令删除环境。
### 2.2.2 环境的导出与复制
有时需要将环境复制到另一台计算机或者备份当前环境。`conda`命令行工具提供了相关的功能。
- **导出环境**:将当前环境导出到一个YAML文件中,使用`conda env export`命令:
```bash
conda env export > environment.yaml
```
- **复制环境**:在新机器上,使用`conda env create`命令根据YAML文件创建环境:
```bash
conda env create -f environment.yaml
```
## 2.3 包管理和更新
### 2.3.1 使用conda命令管理包
Anaconda通过`conda`命令管理包,它是一个全面的包、依赖和环境管理器,使得安装和更新变得非常容易。
- **安装包**:使用`conda install`命令安装包。例如,安装`numpy`库:
```bash
conda install numpy
```
- **更新包**:使用`conda update`命令更新包。例如,更新`numpy`库:
```bash
conda update numpy
```
### 2.3.2 包的查找、安装和更新策略
在安装和更新包时,用户需要考虑一些策略,比如是否使用最新版本的包,以及如何避免依赖冲突。
- **查找包**:使用`conda search`命令查找可用包:
```bash
conda search numpy
```
- **安装特定版本**:安装时指定版本号,以避免自动更新带来的潜在问题:
```bash
conda install numpy=1.20
```
- **构建依赖图**:使用`conda list --revisions`命令查看环境的变更历史,帮助跟踪已安装的包和它们的版本。
- **避免自动更新**:默认情况下,`conda`会安装最新版本的包。可以通过修改`channel_priority`配置或使用`pip`作为替代来避免自动更新。
通过上述章节的介绍,您应该对Anaconda的安装、环境配置和包管理有了基本的认识。下一章节,我们将深入学习Python基础科学计算库的使用与实践。
# 3. Python基础科学计算库
在当今的数据科学和机器学习领域,Python已经成为了一门不可忽视的编程语言。它之所以能在科学计算领域占据一席之地,很大程度上得益于它那丰富的基础科学计算库。这些库不仅功能强大,而且使用简单,为处理各种类型的数据和执行复杂的计算任务提供了极大的便利。本章将深入探讨一些基础且核心的Python科学计算库,如NumPy、Pandas和Matplotlib,并展示它们的实际使用案例。
## 3.1 NumPy的使用与实践
### 3.1.1 NumPy数组的操作与计算
NumPy(Numerical Python)是Python最重要的科学计算库之一,其核心功能是提供高性能的多维数组对象以及这些数组的操作工具。NumPy数组相比Python的内置列表,不仅占用更少的内存空间,而且支持矢量化操作,极大地提升了运算速度。
为了更好地理解NumPy数组的操作与计算,我们首先需要安装NumPy库。通过命令 `pip install numpy` 即可安装最新版本的NumPy。
下面是一个简单的NumPy数组创建及操作的例子:
```python
import numpy as np
# 创建一个一维数组
arr1d = np.array([1, 2, 3, 4])
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
# 访问数组元素
print(arr1d[1]) # 输出: 2
print(arr2d[1, 1]) # 输出: 5
# 数组基本运算
print(arr1d + arr2d[0]) # [2, 4, 6]
```
从上面的例子中我们可以看到,通过 `np.array()` 函数可以创建一维和二维的NumPy数组,并且数组支持基本的索引和切片操作。NumPy数组的加法操作是矢量化的,可以直接对数组的每一个元素进行运算。
矢量化操作是NumPy的核心优势之一,它比传统的Python循环更快。接下来,我们看看矢量化操作的具体例子:
```python
# 生成两个随机数数组
a = np.random.rand(10000)
b = np.random.rand(10000)
# 使用矢量化进行乘法运算
c = a * b
```
在上述代码中,`np.random.rand(10000)` 生成了一个包含10000个随机浮点数的数组。我们使用 `*` 运算符对两个数组进行了元素级别的乘法运算,这是通过NumPy内部的矢量化机制实现的。如果使用Python的for循环来实现相同的操作,则速度会慢得多。
接下来,NumPy数组支持一些有用的数学函数,如求和、平均、最大值等,使得数据分析和预处理变得更加简单。例如,我们可以使用 `np.sum()` 和 `np.mean()` 分别计算数组的总和和平均值:
```python
# 计算数组的总和
sum_result = np.sum(a)
# 计算数组的平均值
mean_result = np.mean(a)
```
### 3.1.2 与Pandas的数据交互
Pandas是一个强大的数据分析和操作库,与NumPy紧密集成,可以实现复杂的数据处理。Pandas中的数据结构,如Series和DataFrame,内部底层使用NumPy数组。
为了实现NumPy与Pandas之间的数据交互,我们需要先安装Pandas库。使用以下命令进行安装:
```shell
pip install pandas
```
现在,让我们看看如何从NumPy数组创建Pandas的Series和DataFrame,并进行一些简单的操作:
```python
import pandas as pd
# 创建一个NumPy数组
data = np.random.rand(5)
# 将NumPy数组转换为Pandas Series
s = pd.Series(data)
# 创建一个二维NumPy数组
data_2d = np.random.rand(5, 2)
# 将二维NumPy数组转换为Pandas DataFrame
df = pd.DataFrame(data_2d, columns=['A', 'B'])
# 打印Pandas Series和DataFrame
print(s)
print(df)
```
Pandas和NumPy之间的数据交换非常灵活,支持不同类型的数据结构转换。这在数据分析流程中非常有用,因为有时候我们需要从NumPy数组导入数据到Pandas中进行进一步的分析或清洗,之后又可能需要将数据导出为NumPy数组进行科学计算。
这种灵活性不仅增加了工具的实用性,而且使得从初步探索数据到深度分析的过程更加顺畅。
## 3.2 Pandas的数据处理
### 3.2.1 数据结构和基本操作
Pandas的核心是它提供了两种主要的数据结构:Series和DataFrame。Series是一维的标签数组,可以存储任何类型的数据(整数、字符串、浮点数、Python对象等)。而DataFrame是一个二维的标签数据结构,可以想象成一个表格,或是Excel中的一个工作表。
首先,安装Pandas库:
```shell
pip install pandas
```
然后,通过以下代码来理解Series和DataFrame的基本操作:
```python
import pandas as pd
import numpy as np
# 创建一个简单的Series
s = pd.Series([1, 2, 3, 4, 5])
# 创建一个DataFrame
df = pd.DataFrame(np.random.rand(5, 2), columns=['A', 'B'])
# 索引和切片操作
print(s[1]) # 输出: 2
print(df['A']) # 输出Series
print(df[1:3]) # 输出DataFrame的子集
# 数据筛选
print(df[df > 0.5]) # 输出所有大于0.5的值
# 分组聚合
grouped = df.groupby(df['A'] > 0.5)
print(grouped.mean()) # 计算分组的均值
```
从上面的例子可以看出,Series和DataFrame都提供了强大的索引和切片功能。这让我们可以非常方便地访问和操作数据集中的特定部分。在数据分析中,经常需要对数据进行筛选和聚合操作,Pandas提供了简洁的语法来实现这些操作。
Pandas还提供了丰富的数据清洗和预处理功能,比如缺失值处理、数据类型转换等,这些功能对于确保数据质量至关重要。例如:
```python
# 填充缺失值
df_filled = df.fillna(0)
# 数据类型转换
df['A'] = df['A'].astype(int)
```
### 3.2.2 数据清洗与预处理
数据清洗是数据分析流程中不可或缺的一环,Pandas提供了许多函数和方法来进行这一工作。在实际操作中,我们经常会遇到数据集包含缺失值、重复记录、异常值等问题。
在数据清洗与预处理方面,Pandas的 `dropna()` 方法可以用来删除包含缺失值的行或列,`drop_duplicates()` 方法可以用来删除重复数据,而 `replace()` 方法可以用来替换数据中的异常值。
下面是Pandas进行数据清洗的代码示例:
```python
# 删除缺失值
df_cleaned = df.dropna()
# 删除重复数据
df_noduplicates = df.drop_duplicates()
# 替换异常值
df_replaced = df.replace(-1, np.nan)
```
通过以上步骤,我们可以确保数据集的质量,为后续的分析和模型构建打下坚实的基础。
## 3.3 Matplotlib与可视化
### 3.3.1 基本图表的创建与定制
数据可视化是数据科学领域不可或缺的一部分。Matplotlib是一个强大的绘图库,能够创建高质量的二维图表。Matplotlib的设计灵感来自于MATLAB,因此其API设计直观易用。
首先,安装Matplotlib库:
```shell
pip install matplotlib
```
接下来,我们来看如何使用Matplotlib来创建一个简单的折线图:
```python
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 创建图表
plt.plot(x, y)
# 添加标题和标签
plt.title('Sine Wave')
plt.xlabel('x axis')
plt.ylabel('y axis')
# 显示图表
plt.show()
```
从上面的代码可以看出,通过简单几行代码就可以创建一个基本图表,并且添加了图表的标题和坐标轴标签。此外,我们还可以自定义图表的样式,包括颜色、线型、点型、图例等,来满足不同的可视化需求。
```python
# 使用不同的颜色和线型
plt.plot(x, y, color='red', linestyle='--')
# 添加图例
plt.plot(x, y*2, label='y*2')
plt.legend()
# 添加网格线
plt.grid(True)
# 添加文字注释
plt.annotate('Max', xy=(np.pi/2, 1), xytext=(np.pi/2, 1.5),
arrowprops=dict(facecolor='black', shrink=0.05))
plt.show()
```
### 3.3.2 复杂数据可视化案例
Matplotlib不仅限于简单的图表,还可以用来创建复杂的可视化作品。比如,我们可以用它来绘制散点图、直方图、箱型图等。
下面的代码展示了如何用Matplotlib创建散点图,并且针对不同点的颜色和大小进行定制:
```python
# 创建散点图
plt.scatter(x, y, c='blue', s=50)
# 添加颜色条
plt.colorbar(label='Color Scale')
# 设置坐标轴范围
plt.xlim(0, 10)
plt.ylim(-1, 1)
plt.show()
```
再来看一个更复杂的数据可视化案例,我们将用Matplotlib创建一个箱型图:
```python
# 生成一些随机数据用于可视化
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
# 创建箱型图
plt.boxplot(data, vert=True, patch_artist=True)
# 添加标题和标签
plt.title('Box Plot')
plt.xlabel('Data')
plt.ylabel('Value')
plt.show()
```
在上面的例子中,我们生成了三个不同的正态分布数据集,并将它们绘制成箱型图。箱型图非常有助于显示数据的分布情况,包括中位数、四分位数和异常值。通过颜色填充,我们可以进一步提高图形的视觉吸引力。
这些例子仅仅展示了Matplotlib的一部分能力,实际上它能够创建几乎所有类型的统计图表,并且允许我们定制图表的每一个细节。这对于数据科学家来说至关重要,因为在与利益相关者沟通时,清晰和准确的数据可视化可以帮助我们更好地传达数据分析的结论。
以上就是本章关于Python基础科学计算库的主要内容。通过NumPy、Pandas和Matplotlib的介绍和实践,可以看出Python已经成为科学计算领域内不可或缺的工具之一。下一章,我们将进一步探讨如何使用高级科学计算库,如SciPy、Scikit-learn,以及Jupyter Notebook的交互式编程,来解决更复杂的数据科学问题。
# 4. 高级科学计算与数据分析
## 4.1 SciPy在科学计算中的应用
SciPy是基于NumPy的一个科学计算库,它扩展了NumPy的功能,提供了许多用于科学和技术计算的工具。SciPy集成了各种数学算法和便利的功能,涵盖了优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理等领域。
### 4.1.1 线性代数和优化问题求解
线性代数是科学计算的基础,在数据处理和机器学习中扮演着核心角色。SciPy中的`scipy.linalg`模块提供了广泛的线性代数操作,如矩阵运算、特征值分解、奇异值分解等。
```python
from scipy import linalg
# 创建一个矩阵
A = [[1, 2], [3, 4]]
# 计算矩阵的特征值和特征向量
eigenvalues, eigenvectors = linalg.eig(A)
print("特征值:", eigenvalues)
print("特征向量:", eigenvectors)
```
在上述代码中,使用`linalg.eig`函数计算矩阵的特征值和特征向量。`eigenvalues`变量包含了矩阵`A`的特征值,`eigenvectors`包含了对应的特征向量。这是线性代数中非常重要的概念,尤其在主成分分析(PCA)和机器学习的特征提取中广泛应用。
对于优化问题,SciPy的`scipy.optimize`模块提供了解决线性和非线性优化问题的功能。例如,使用`minimize`函数可以求解多变量函数的最小值。
```python
from scipy.optimize import minimize
# 定义要最小化的目标函数
def objective(x):
return x[0]**2 + x[1]**2
# 初始猜测值
x0 = [1.0, 1.0]
# 调用最小化函数
res = minimize(objective, x0)
print("最优解:", res.x)
```
在这段代码中,定义了一个简单的二次目标函数`objective`,并使用`minimize`函数找到其最小值。`res.x`包含了最优解的坐标。
### 4.1.2 科学模拟和工程计算
除了基本的数学运算和优化问题外,SciPy也广泛应用于物理模拟和工程计算中。比如,`scipy.integrate`模块可以用于数值积分,这对于物理方程的解析和工程中的积分问题非常有用。
```python
from scipy.integrate import quad
# 定义被积函数
def integrand(x):
return x**2 + 2*x + 1
# 计算定积分
result, error = quad(integrand, 0, 1)
print("积分结果:", result)
```
通过上述代码,我们计算了函数`x**2 + 2*x + 1`在区间[0, 1]上的定积分。`quad`函数返回积分的结果以及估计误差。
在工程计算中,常涉及到微分方程的求解。`scipy.integrate`模块提供的`odeint`和`solve_ivp`函数可以帮助我们解决常微分方程初值问题。
```python
from scipy.integrate import solve_ivp
import numpy as np
# 定义微分方程
def system(t, y):
return [y[1], -y[0]]
# 初始条件和时间区间
y0 = [0, 1]
t_span = (0, np.pi)
# 解微分方程
sol = solve_ivp(system, t_span, y0)
print("解的值:", sol.y)
```
上述代码中,我们定义了一个简单的谐振子系统,并求解了其在区间[0, π]上的运动。`solve_ivp`函数返回了时间点`t`和在这些时间点上的解向量`y`。
## 4.2 Scikit-learn机器学习基础
Scikit-learn是机器学习领域内广泛使用的Python库之一,它提供了一系列简单而高效的数据挖掘和数据分析工具。该库覆盖了从数据预处理、特征提取、模型选择到模型评估的整个机器学习工作流。
### 4.2.1 模型的训练和评估
在机器学习项目中,模型训练和评估是核心环节。Scikit-learn提供了多种类型的机器学习模型,如分类器、回归模型、聚类算法等。使用这些模型的第一步是数据的准备。
```python
from sklearn import datasets
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
```
在上述代码段中,我们使用`load_iris`函数加载了鸢尾花数据集,并使用`train_test_split`函数将其划分为训练集和测试集。这是进行机器学习模型训练和评估的标准过程。
模型训练通常涉及以下步骤:
1. 初始化模型。
2. 使用训练数据拟合模型。
3. 使用测试数据评估模型性能。
4. 调整模型参数,以获得更好的性能。
```python
from sklearn.ensemble import RandomForestClassifier
# 初始化随机森林分类器
clf = RandomForestClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集结果
predictions = clf.predict(X_test)
# 评估模型
from sklearn.metrics import accuracy_score
print("准确率:", accuracy_score(y_test, predictions))
```
在该示例中,我们选择了随机森林分类器,并使用训练集数据训练了该模型。接着,我们在测试集上进行预测,并通过准确率来评估模型性能。
### 4.2.2 常见的机器学习算法
Scikit-learn库支持多种机器学习算法,包括但不限于:
- 分类算法:如决策树、支持向量机、朴素贝叶斯、K最近邻(KNN)等。
- 回归算法:如线性回归、决策树回归、支持向量回归等。
- 聚类算法:如K均值、层次聚类、DBSCAN等。
- 降维算法:如主成分分析(PCA)、t分布随机邻域嵌入(t-SNE)等。
以下展示了如何使用Scikit-learn实现KNN算法,并评估其分类性能:
```python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
# 使用K最近邻算法
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 进行预测
knn_predictions = knn.predict(X_test)
# 打印混淆矩阵和分类报告
print(confusion_matrix(y_test, knn_predictions))
print(classification_report(y_test, knn_predictions))
```
通过上述代码,我们训练了一个KNN分类器,并在测试集上进行了预测。`confusion_matrix`和`classification_report`函数分别提供了混淆矩阵和分类报告,帮助我们更直观地了解模型的性能。
## 4.3 Jupyter Notebook交互式编程
Jupyter Notebook是一个开源的Web应用程序,它允许用户创建和共享包含实时代码、方程、可视化和文本的文档。它已经成为数据科学家和开发者的标准工具之一,用于数据清理、转换、可视化、机器学习等多种任务。
### 4.3.1 Notebook的创建与使用
Jupyter Notebook通过笔记本的形式组织和展示数据科学工作流。每个笔记本由多个单元格构成,可以包含代码、Markdown文本、HTML、甚至LaTeX数学公式。
要创建一个新的Notebook,只需在Jupyter的主界面中点击“新建”按钮,并选择“Python”环境。随后,你可以添加一个单元格(Cell),并在其中输入代码或文本。
```python
# 示例:在Notebook中编写并执行Python代码
print("Hello, Jupyter!")
```
Notebook的交互式特性允许你即时执行单元格中的代码,并查看结果,而无需在命令行中运行整个程序。
### 4.3.2 代码的组织与分享
Notebook的一个重要优势在于其对代码的组织和分享能力。你可以按照逻辑顺序排列单元格,创建完整的数据分析或机器学习项目,并且可以方便地导出为多种格式,如HTML、PDF或Python脚本。
```python
# 示例:在Notebook中组织代码以进行数据分析
# 加载数据集
import pandas as pd
df = pd.read_csv('data.csv')
# 数据探索
print(df.head())
# 数据可视化
import matplotlib.pyplot as plt
df['column'].hist()
plt.show()
```
为了分享Notebook,你可以使用Jupyter Notebook的导出功能,将Notebook保存为`.ipynb`文件。此外,你可以通过Jupyter Notebook服务器的共享功能,让他人通过Web访问Notebook。
通过合并使用Anaconda、SciPy、Scikit-learn和Jupyter Notebook,数据科学家和工程师能够高效地进行科学计算、数据分析和机器学习项目开发。这些工具共同提供了一套完整的生态系统,用于处理各种复杂问题,并且支持从数据采集到结果分析的整个工作流程。
# 5. Anaconda在实际项目中的应用
Anaconda不仅是个人科学计算和数据分析的利器,它在组织层面,特别是在项目管理、协作和性能优化方面也展现了巨大的潜力。在本章节中,我们将深入探讨Anaconda在实际项目中如何发挥作用。
## 5.1 项目环境的搭建与部署
在项目开发过程中,项目环境的搭建和部署是一个重要环节。项目环境确保了依赖关系的正确和隔离,这在多人协作的项目中尤为重要。
### 5.1.1 环境配置文件的创建和使用
Anaconda环境配置文件可以记录一个项目所需的所有包及其版本号,这对于项目部署和团队协作来说是非常有用的。
使用`conda env export`命令可以导出当前环境的配置文件`environment.yml`:
```bash
conda env export > environment.yml
```
这个文件将包括所有的包和它们的精确版本号,可以被其他人用来创建一个相同的环境:
```yaml
name: myenv
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.19.5
- pandas=1.2.3
```
### 5.1.2 环境的打包和部署策略
在需要将环境分发给其他用户或服务器时,可以使用`conda pack`来打包环境:
```bash
conda activate myenv
conda pack -n myenv -o myenv.tar.gz
```
这个命令将创建一个包含所需所有依赖的压缩包。部署时,其他用户可以通过以下方式解压和激活环境:
```bash
tar -xzf myenv.tar.gz
conda activate $(basename myenv.tar.gz .tar.gz)
```
## 5.2 版本控制与项目协作
版本控制系统是项目协作的重要组成部分。Anaconda与Git的结合使用可以更好地管理代码和依赖。
### 5.2.1 使用Git进行版本控制
在项目中使用Git可以跟踪代码的变更历史。结合Anaconda,项目依赖可以被记录在`environment.yml`文件中,并与代码一起版本控制。当其他开发者克隆项目时,他们可以使用以下命令来设置相同的开发环境:
```bash
git clone <repository-url>
conda env create -f environment.yml
```
### 5.2.2 Anaconda Cloud的使用与优势
Anaconda Cloud是Anaconda的云服务平台,可以存储和共享环境配置文件,以及利用其包管理服务来发布和安装包。用户可以利用Anaconda Cloud一键部署环境:
```bash
conda env create -n myenv -f https://conda.anaconda.org/channel/path/to/environment.yml
```
## 5.3 性能优化与故障排除
在项目的运行阶段,性能优化和故障排除是确保高效运行的关键。
### 5.3.1 性能监控与调优技巧
性能监控可以使用`conda`命令进行。例如,列出所有已安装包的版本和依赖关系,可以帮助发现可能导致冲突的包。
此外,使用如`nvidia-smi`(针对GPU计算)等工具,可以对硬件资源使用情况进行监控。
性能调优可以涉及对Python解释器参数的调整,使用`pympler`库来监控对象的内存使用情况,以及利用`line_profiler`进行逐行性能分析。
### 5.3.2 常见问题诊断和解决方法
针对常见的问题,如环境无法激活、包安装失败等,Anaconda社区提供了大量的解决方案。使用`conda list`命令可以帮助识别环境中的包,确保它们与项目的依赖相匹配。如果遇到包安装失败,可以尝试使用不同的通道或检查网络设置。
故障排除可以是一个复杂的过程,但Anaconda提供了一个诊断工具,可以自动检测和解决一些常见问题:
```bash
conda info --envs
conda list --envs myenv
```
通过这些工具和方法,用户可以有效地诊断和解决在使用Anaconda过程中遇到的大部分问题。
在下一章节中,我们将探讨如何利用Anaconda进行高效的数据处理和机器学习模型训练。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Anaconda的版本控制与管理》专栏深入探讨了Anaconda的版本控制和管理技巧,为用户提供了全面的指南。专栏涵盖了从初学者入门到高级用户技巧的各个方面,包括:
* 如何搭建最佳Python科学计算环境
* 如何无缝迁移到最新版Anaconda
* 如何备份和恢复Anaconda环境,高效管理项目依赖
* 如何监控和提升Anaconda环境性能
* 如何制作可复现的环境文件,便于环境导出和分享
* 如何按需安装核心包,从零开始构建Anaconda环境
* 如何批量管理包和环境,提高效率
该专栏为Anaconda用户提供了宝贵的知识和技巧,帮助他们充分利用Anaconda的强大功能,管理和优化其Python环境,提高工作效率和项目可复现性。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MAC地址申请全攻略:步骤、误区和全球分配机构解析

参考资源链接:[IEEE下的MAC地址申请与费用详解](https://wenku.csdn.net/doc/646764ec5928463033d8ada0?spm=1055.2635.3001.10343)
# 1. MAC地址概述及其重要性
MAC地址,即媒体访问控制地址,是网络设备在局域网中用于唯一标识的地址。它由48位二进制数字构成,通常以十六进制数的形式表示
【奇安信漏扫安全策略】

参考资源链接:[网神SecVSS3600漏洞扫描系统用户手册:安全管理与操作指南](https://wenku.csdn.net/doc/3j9q3yzs1j?spm=1055.2635.3001.10343)
# 1. 奇安信漏扫工具概述
网络安全是当今信息时代不可忽视的话题,随着数字化转型的加速,企业网络面临的安全威胁与日俱增。奇安信漏扫工具是业界知名的安全扫描解决方案,旨在帮助
AE-2M-3043 GC2053 CSP核心参数深度解读:技术手册速成教程

参考资源链接:[GC2053 CSP图像传感器 datasheet V1.2:AE-2M-3043 最新版](https://wenku.csdn.net/doc/5dmsy2n5n3?spm=1055.2635.3001.10343)
# 1. GC2053 CSP核心参数概述
在集成电路设计领域,了解核心组件
【质量监控必学】:PPK实战应用技巧,提升过程控制精度
参考资源链接:[CP、CPK、PP、PPK、CMK的计算公式过程能力指数公式](https://wenku.csdn.net/doc/6412b710be7fbd1778d48f44?spm=1055.2635.3001.10343)
# 1. PPK概念解析及应用场景
在制造和质量控制领域,PPK(过程性能指数)是一个至关重要的概念。PPK提供了一个度量,用于确定一个过程在长期运行中满足顾客规格要求的程度。
CREAD_CWRITE进阶教程:机器人编程参数与性能同步提升

参考资源链接:[KUKA机器人高级编程:CREAD与CWRITE详解](https://wenku.csdn.net/doc/wf9hqgps2r?spm=1055.2635.3001.10343)
# 1. CREAD_CWRITE概念解析
在现代IT技术和系统架构中,CREAD_CWRITE是一个关键的概念,它涉及到系统对于
Verilog编码器优化秘籍:提升性能与降低功耗的20个实用技巧

参考资源链接:[8-13编码器 verilog 实现 包含仿真图](https://wenku.csdn.net/doc/6412b78bbe
【兄弟 DCP9020CDN 维修手册】:打印机操作技巧与故障解决全攻略

参考资源链接:[兄弟DCP9020CDN等系列彩色激光多功能设备维修手册指南](https://wenku.csdn.net/doc/644b8ce2ea0840391e559a94?spm=1055.2635.3001.1
PLC程序逻辑全解析:水塔水位控制系统的深入理解

参考资源链接:[PLC编程实现水塔水位智能控制系统设计](https://wenku.csdn.net/doc/64a4de3450e8173efdda6ba2?spm=1055.2635.3001.10343)
# 1. PLC程序逻辑控制基础
## 1.1 PLC的定义及工作原理
可编程逻辑控制器(PLC)是一种用于自动化控制的工业数字计算机。它通过读取输入信号,根据用户编写的程序
【嵌入式系统性能调优】:CCRAM配置与优化策略,专家级教程

参考资源链接:[STM32与GD32使用CCRAM指南:arm-gcc配置](https://wenku.csdn.net/doc/8556i38a8x?spm=1055.2635.3001.10343)
# 1. 嵌入式系统性能调优概述
在嵌入式系统的开发和维护过程中,性能调优始终是一个核心议题。随着技术的不断进步,嵌入式设备的性能需求日益增长,对于内存管理的要求也随之提高。内存调
RV-C文档结构全解析:深入理解与编写的艺术
参考资源链接:[北美房车通讯协议RV-C:CAN2.0应用详解](https://wenku.csdn.net/doc/70dzrx8o2e?spm=1055.2635.3001.10343)
# 1. RV-C文档结构的基础知识
## 1.1 RV-C文档的概念解析
RV-C文档是一种结构化数据表达方式,广泛应用于IT行业进行数据存储和交换。它以清晰定义的结构和格式,确保了数据的一致性和可读性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )