易语言yolo神经网络在工业领域的应用:提升生产效率,寓教于乐,激发学习兴趣
发布时间: 2024-08-17 22:24:56 阅读量: 20 订阅数: 33 

易语言神经网络学习

# 1. 易语言yolo神经网络概述**
易语言yolo神经网络是一种基于易语言编程语言开发的轻量级、高效的目标检测神经网络。它利用卷积神经网络(CNN)的强大功能,可以快速、准确地检测图像中的对象。与其他目标检测算法相比,易语言yolo神经网络具有以下优点:
* **速度快:**易语言yolo神经网络的推理速度非常快,可以在实时环境中处理图像。
* **精度高:**易语言yolo神经网络的检测精度很高,可以准确地识别和定位图像中的对象。
* **易于使用:**易语言yolo神经网络的API非常简单易用,即使是初学者也可以轻松上手。
# 2. 易语言yolo神经网络在工业领域的应用
易语言yolo神经网络在工业领域有着广泛的应用前景,能够显著提升生产效率,寓教于乐,为工业发展注入新的活力。
### 2.1 生产效率提升
易语言yolo神经网络在生产效率提升方面发挥着至关重要的作用。
#### 2.1.1 质量检测和缺陷识别
易语言yolo神经网络可以对产品进行实时质量检测和缺陷识别。通过训练神经网络识别产品缺陷,如划痕、凹痕、颜色偏差等,可以有效提高生产线的检测效率和准确性。
```易语言
// 质量检测模型
Model = LoadModel("quality_detection_model.yml")
// 检测产品图像
Image = LoadImage("product_image.jpg")
Result = DetectObject(Model, Image)
// 输出检测结果
Print("检测到的缺陷:")
For i = 1 To Result.Count
Print(Result[i].Class)
Next
```
#### 2.1.2 生产线监控和优化
易语言yolo神经网络可以对生产线进行实时监控和优化。通过部署神经网络在生产线上,可以检测异常情况,如设备故障、人员操作失误等,并及时发出警报,帮助企业及时采取措施,避免生产事故和损失。
```易语言
// 生产线监控模型
Model = LoadModel("production_line_monitoring_model.yml")
// 监控生产线图像
Image = LoadImage("production_line_image.jpg")
Result = DetectObject(Model, Image)
// 输出监控结果
Print("检测到的异常情况:")
For i = 1 To Result.Count
Print(Result[i].Class)
Next
```
### 2.2 寓教于乐
易语言yolo神经网络在寓教于乐方面也大有可为。
#### 2.2.1 互动式教学平台
易语言yolo神经网络可以构建互动式教学平台,让学生在实践中学习。通过开发基于yolo神经网络的教学软件,学生可以直观地了解神经网络的原理和应用,激发学习兴趣,提高学习效率。
```易语言
// 互动式教学平台
// 界面设计略
// 加载神经网络模型
Model = LoadModel("teaching_platform_model.yml")
// 处理用户输入
Input = InputBox("请输入待识别图像路径:")
// 检测图像
Image = LoadImage(Input)
Result = DetectObject(Model, Image)
// 显示检测结果
ShowImage(Image)
For i = 1 To Result.Count
DrawRect(Image, Result[i].X, Result[i].Y, Result[i].Width, Re
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
易语言yolo神经网络专栏深入探索了易语言中yolo神经网络的原理、实现和应用。从零开始,该专栏提供了打造AI应用的实战指南,涵盖了数据集构建、模型评估和部署等各个方面。通过揭秘yolo神经网络在图像识别、目标检测、视频分析、医疗、安防、交通、金融、教育和零售等领域的应用,专栏展示了易语言yolo神经网络的强大功能和广泛的适用性。此外,专栏还对比了yolo神经网络与其他框架的优势和劣势,为读者提供了全面的技术洞察。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
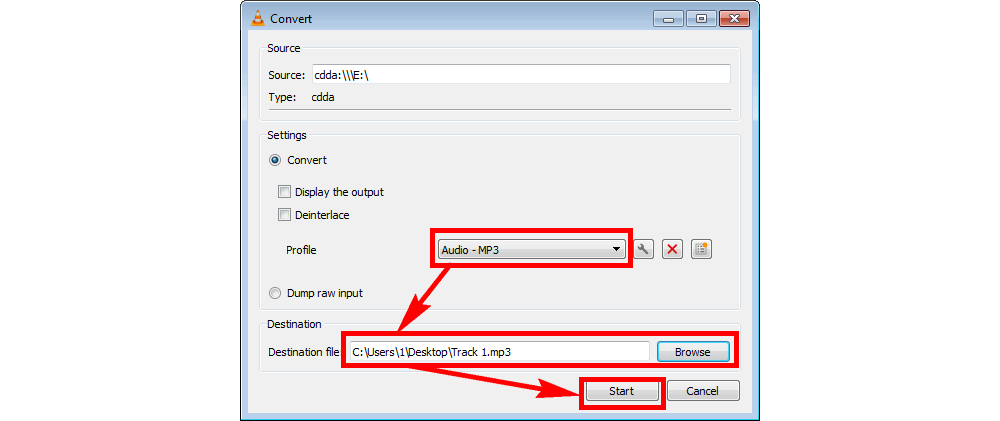
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
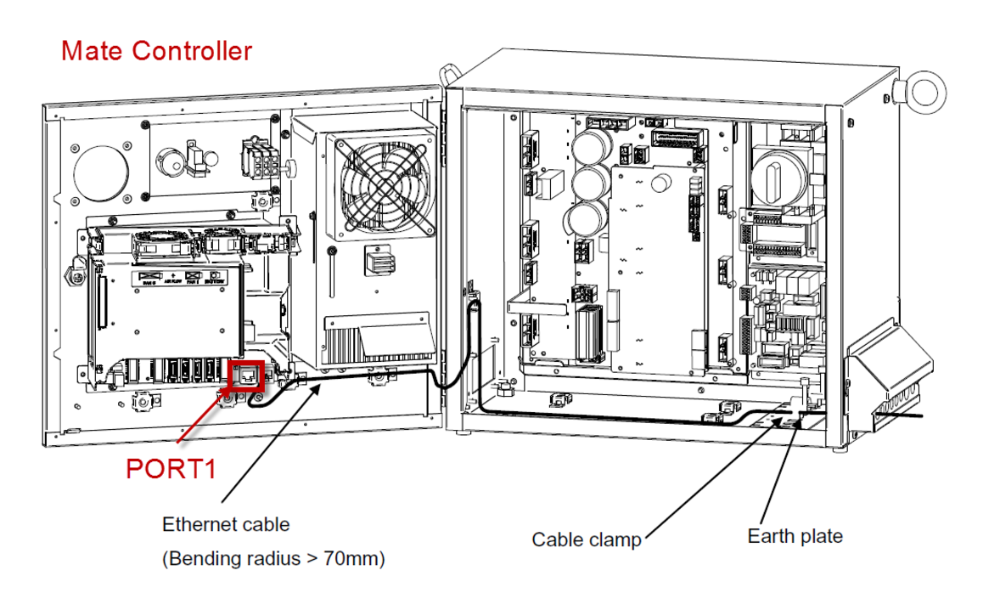
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
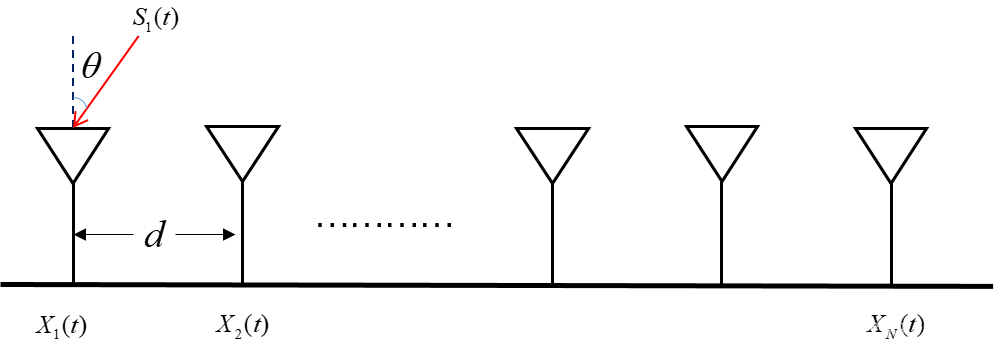
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
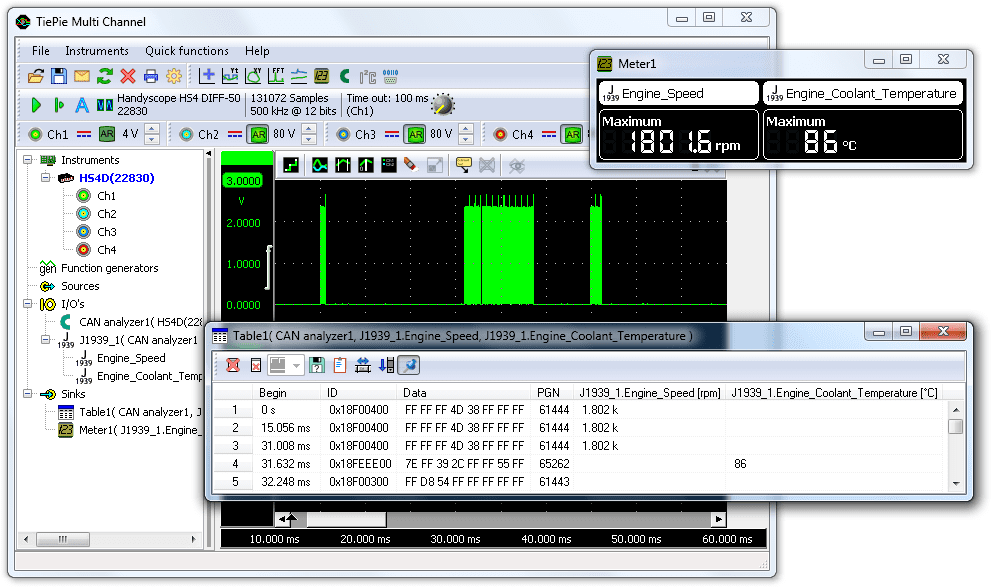
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )