实战解析:如何利用Django构建功能强大的动态内容聚合器
发布时间: 2024-10-09 13:39:55 阅读量: 1 订阅数: 24 

# 1. Django基础与内容聚合的概念
## 1.1 Django框架的简介
Django是一个由Python编写的高级Web框架,它鼓励快速开发和干净、实用的设计。其遵循MTV(Model-Template-View)设计模式,使得Web开发更模块化、重用性高。对于内容聚合网站来说,Django强大的模型系统和模板引擎能很好地聚合分散在不同源的内容。
## 1.2 内容聚合的基本理念
内容聚合指的是将分散在互联网上的信息集中起来进行展示或再分发的过程。这通常涉及到网络数据抓取、数据解析以及动态内容更新等步骤。在Web应用中实现内容聚合,不仅可以提供更加丰富的用户体验,还能拓宽信息传播的渠道。
## 1.3 Django与内容聚合的结合
结合Django进行内容聚合,可以利用Django内置的ORM来设计和操作数据库模型,通过视图层处理逻辑来获取、处理和展示聚合内容。同时,Django强大的模板系统可以帮助我们以灵活的方式展示聚合的内容数据。在下一章中,我们将深入了解Django模型的设计原则和数据库设计,为内容聚合打下坚实的基础。
# 2. Django模型和数据库设计
### 2.1 Django模型的设计原则
#### 模型的定义和字段类型
在Django中,模型是指数据库表的Python表示。定义模型是构建任何Django项目的基础。每个模型都是一个Python类,它继承自`django.db.models.Model`,并且每个模型的属性对应于数据库表中的一个字段。
使用字段类型定义模型时,Django 提供了多种内置字段类型,例如 `CharField`、`TextField`、`IntegerField`、`DateField`、`BooleanField` 等。下面是一个简单的模型定义示例:
```python
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
author = models.ForeignKey('auth.User', on_delete=models.CASCADE)
published_date = models.DateTimeField()
is_published = models.BooleanField(default=False)
```
在这个示例中,`Article` 类包含以下字段:
- `title`:文章标题,使用 `CharField` 字段类型。
- `content`:文章内容,使用 `TextField` 字段类型。
- `author`:文章作者,使用 `ForeignKey` 字段类型表示外键关系。
- `published_date`:发布日期,使用 `DateTimeField` 字段类型。
- `is_published`:表示文章是否发布,使用 `BooleanField` 字段类型。
字段类型不仅定义了存储在数据库中的数据类型,还提供了一些额外的参数,例如 `max_length` 和 `default`,来控制字段行为和验证数据。
#### 模型间关系的建立与优化
在实际的项目开发中,表与表之间往往存在着复杂的关系,Django ORM 支持三种主要关系类型:
- **一对多关系** (`ForeignKey`): 例如,一个作者可以撰写多篇文章,但每篇文章只有一个作者。
- **多对多关系** (`ManyToManyField`): 例如,一篇文章可以被多个标签标记,而一个标签也可以标记多篇文章。
- **一对一关系** (`OneToOneField`): 例如,一个用户只有一个用户配置文件,一个用户配置文件也只对应一个用户。
优化模型间关系时,需要考虑几个关键因素:
- **规范化**: 避免数据重复,减少冗余,使数据结构更清晰。
- **反向查询**: Django ORM 允许通过关系进行反向查询,例如 `author.article_set.all()` 来获取某个作者的所有文章。
- **索引**: 在关系字段上创建索引可以加快查询速度,特别是在使用 `filter()` 或 `exclude()` 方法时。
在设计模型关系时,应尽量避免过度规范化,因为这可能会降低数据库操作的效率。
### 2.2 数据库的迁移与管理
#### 数据库迁移的基本步骤
Django 使用迁移来同步模型定义与数据库结构的变更。迁移是一系列记录了模型变更的文件。
1. **创建初始迁移**: 使用 `python manage.py makemigrations` 创建迁移文件,这将记录模型的当前状态。
2. **查看迁移内容**: 使用 `python manage.py showmigrations` 查看所有迁移文件及其状态。
3. **执行迁移**: 使用 `python manage.py migrate` 应用迁移到数据库,使数据库结构与模型保持一致。
迁移操作是通过一个内部的迁移系统来管理的,它会记录每个迁移是否被应用,确保数据库状态的准确性。
#### 迁移文件的管理和数据一致性的维护
迁移文件管理的核心在于维护数据的一致性。在开发过程中,多次修改模型并生成新的迁移文件是很常见的。为维护数据的一致性,Django 提供了以下功能:
- **迁移依赖**: 确保迁移是有序的,依赖于前一个迁移正确执行。
- **回滚迁移**: 使用 `python manage.py migrate <app_name> <migration_name>` 可以回滚到指定的迁移版本。
- **数据迁移**: 在进行结构变更的同时,可能还需要进行数据迁移。数据迁移允许你在执行数据库结构变更的同时,对数据进行修改。
### 2.3 高级数据库操作
#### 数据库查询优化技巧
Django ORM 提供了一种高级的查询接口,但如果不注意,复杂的查询可能会导致性能问题。以下是一些优化查询的技巧:
- 使用 `select_related` 和 `prefetch_related`:在进行外键和多对多关系查询时,可以预先获取关联对象以减少数据库查询次数。
- 利用 `QuerySet API` 的 `.count()`、`.exists()` 等方法,以避免不必要的数据加载。
- 使用 `Explain` 查看查询的执行计划,以便于发现潜在的性能瓶颈。
- 对于复杂的查询,考虑使用原生 SQL 查询以提高性能。
#### Django ORM的高级用法
Django ORM 支持很多高级用法,可以让你用更少的代码完成复杂的查询。
- **子查询**: 在 Django 1.10 及以上版本中,可以使用 `Subquery` 和 `OuterRef` 来编写子查询。
- **注释 (Annotations)** 和 **聚合 (Aggregates)**: 用于对查询集进行统计分析。
- **事务控制**: 使用 `transaction.atomic()` 包裹代码块,保证一组操作的原子性。
```python
from django.db import transaction
@transaction.atomic
def create_order(item_list, user):
order = Order.objects.create(user=user)
for item in item_list:
OrderItem.objects.create(order=order, item=item)
```
使用事务控制可以确保即使在发生错误时,数据库的状态也不会出现不一致。
总结而言,理解 Django 模型的设计原则、数据库的迁移与管理以及高级数据库操作,对于构建高效和可维护的 Django 应用至关重要。通过运用这些高级技术,开发者可以显著提升应用的性能和稳定性。
# 3. 动态内容的获取与处理
## 3.1 网络数据抓取技术
### 3.1.1 利用Django内置的请求库进行网络请求
Django作为Python的一个高级Web框架,它内置了一个强大的库`requests`,这使得开发者能够轻松地通过网络抓取内容。`requests`库是Python标准库的一部分,被广泛用于发送HTTP请求。它简洁易用,能够处理多种HTTP相关的功能,如GET、POST、PUT、DELETE、HEAD、OPTIONS等。
在实现网络数据抓取时,首先需要引入`requests`库并发送请求。例如,想要获取一个网页的数据,可以通过如下代码实现:
```python
import requests
response = requests.get('***')
if response.status_code == 200:
print(response.text)
else:
print('请求失败')
```
在上述代码中,`requests.get`是一个便捷的方法用于发起GET请求。在执行请求后,我们检查HTTP响应状态码,如果状态码为200,表示请求成功,然后打印网页的源码。如果失败,则打印错误信息。
### 3.1.2 非阻塞式网络请求的处理
非阻塞式网络请求是提高Web应用性能的一个重要方面。在这种模式下,服务器在等待网络操作如数据库查询或外部服务调用完成时,会继续处理其他的请求。这通常由异步编程来实现。
在Django中,可以使用异步视图来处理非阻塞式网络请求。从Django 3.1版本开始,Django引入了对异步视图的支持。异步视图使用了Python的`async def`语法,并通过`asgi`协议,使得Web应用能够异步运行。
一个简单的异步视图示例如下:
```python
from django.http import HttpResponse
import asyncio
async def fetch_data():
# 假设这是一个异步获取数据的函数
await asyncio.sleep(1)
return 'Data Fetched'
async def async_view(request):
data = await fetch_data()
return HttpResponse(data)
```
在这个示例中,`fetch_data`是一个模拟的异步函数,它使用`asyncio.sleep(1)`来模拟网络请求。`async_view`是一个异步视图函数,它等待`fetch_data`函数完成数据获取,然后返回包含数据的响应。
## 3.2 数据解析与内容提取
### 3.2.1 使用BeautifulSoup和lxml解析HTML/XML
当从网络获取到HTML/XML内容后,我们需要解析这些内容以提取所需的数据。`BeautifulSoup`是一个可以从HTML或XML文件中提取数据的Python库。它能够通过解析器将复杂的数据结构化,提供简单易用的API。`lxml`是一个高效的库,可以用来解析HTML/XML,它通常作为`BeautifulSoup`的解析器后端。
首先,你需要安装这两个库(如果还没有安装的话):
```shell
pip install beautifulsoup4 lxml
```
然后,使用`BeautifulSoup`和`lxml`来解析HTML数据:
```python
from bs4 import BeautifulSoup
html_doc = '''
<html>
<head>
<title>Page Title</title>
</head>
<body>
<p class="title"><b>My First Heading</b></p>
<p class="title"><b>My First Paragraph</b></p>
</body>
</html>
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.title.text)
print(soup.p.text)
```
在这个示例中,我们首先创建了一个`BeautifulSoup`对象,将HTML文档和`lxml`作为解析器。之后,可以轻松地访问文档的各个部分,例如获取`<title>`标签的文本或获取所有`<p>`标签的文本。
### 3.2.2 从不同数据源提取和清洗信息
在Web应用中,数据源可能来自多种多样。除了HTML/XML之外,还可能有JSON、API、数据库等。提取和清洗这些数据源的信息是数据处理过程的重要部分。
以JSON数据为例,假设我们从一个API获取了以下JSON数据:
```json
{
"name": "Alice",
"age": 30,
"address": {
"street": "123 Main St",
"city": "Wonderland"
}
}
```
我们可以使用Python的`json`库来解析这个JSON数据:
```python
import json
data = '''
{
"name": "Alice",
"age": 30,
"address": {
"street": "123 Main St",
"city": "Wonderland"
}
}
json_data = json.loads(data)
print(json_data['name'])
print(json_data['address']['city'])
```
在这个代码块中,`json.loads`方法用来将JSON字符串转换成Python字典。之后,我们就可以像操作普通字典一样来访问和操作这些数据了。
清洗信息是内容提取的一个重要步骤。例如,去除字符串中的空格、转换数据类型、处理缺失值、标准化数据等。为了更好地展示这个过程,我们来处理一组假设的数据:
```python
import pandas as pd
# 假设有一组数据
data = {
'name': [' Alice', 'Bob ', 'Carol'],
'age': ['30', '35', ''],
'address': [' 123 Main St', '125 Main St', '']
}
# 转换成pandas DataFrame
df = pd.DataFrame(data)
# 清洗数据
df['name'] = df['name'].str.strip() # 去除字符串两端的空格
df['age'] = pd.to_numeric(df['age'], errors='coerce') # 转换数据类型并处理缺失值
df['age'] = df['age'].fillna(0) # 填充缺失值为0
print(df)
```
以上代码段演示了使用Pandas库对数据进行清洗的过程。`str.strip()`方法用于去除字符串两端的空格,`pd.to_numeric()`用于转换数据类型并处理无法转换的值,`fillna()`用于填充缺失值。
## 3.3 内容聚合的逻辑实现
### 3.3.1 数据去重和分类聚合策略
在处理动态内容时,通常会有大量重复数据需要被清洗掉。去除重复的数据有助于减少存储空间的使用,提高数据处理的效率,还能提升用户体验。
在Python中,可以使用集合(set)数据结构来去重:
```python
data = ['Alice', 'Bob', 'Alice', 'Carol']
# 使用集合去除重复项
unique_data = set(data)
print(unique_data)
```
上述代码将输出一个集合,其中包含了不重复的数据项。集合(set)是一个无序的、不包含重复元素的集合数据结构。
对于更复杂的数据去重,可能需要结合多个字段进行判断,可以使用Pandas库中的`duplicated()`方法:
```python
import pandas as pd
# 假设有重复的DataFrame记录
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Alice', 'Carol'],
'age': [30, 35, 30, 20]
})
# 使用duplicated方法标记重复项
df['is_duplicate'] = df.duplicated(subset=['name', 'age'], keep=False)
print(df[df['is_duplicate']])
```
这段代码标记了DataFrame中所有重复的记录,并将它们打印出来。
在内容聚合方面,除了数据去重之外,我们还需要将内容进行分类聚合。这通常意味着根据某些字段的值将数据分组,并进行统计或汇总。使用Pandas的`groupby`方法可以很容易地完成这一步骤:
```python
# 继续使用上面的DataFrame
grouped_data = df.groupby('name')['age'].sum()
print(grouped_data)
```
在这个示例中,我们根据`name`字段对数据进行分组,并计算每个组中`age`字段的总和。通过这种方式,我们可以聚合来自不同数据源的相似内容。
### 3.3.2 基于时间序列的内容更新机制
在内容聚合的应用场景中,经常需要根据时间序列来更新内容。例如,社交媒体动态更新、新闻网站内容刷新等。为确保内容及时且高效地更新,可以使用定时任务和事件驱动机制。
Python中有多个库可以帮助实现定时任务,例如`schedule`和`APScheduler`。以下是使用`schedule`库实现定时任务的简单示例:
```python
import schedule
import time
def job():
print("Content update is happening.")
schedule.every().day.at("10:30").do(job)
while True:
schedule.run_pending()
time.sleep(1)
```
这个简单的脚本每在每天的10:30执行`job`函数,你可以在这个函数中添加你的内容更新逻辑。
对于事件驱动型的更新,可以使用`Celery`这样的任务队列。`Celery`是一个异步任务队列/作业队列,基于分布式消息传递。它被广泛用于运行任务调度,例如定期更新内容或者响应用户操作。
安装Celery很简单:
```shell
pip install celery
```
然后你可以设置一个Celery应用并安排任务执行:
```python
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task
def update_content():
print("Updating content according to a schedule.")
# 调度任务,例如每天10:30执行
from celery.schedules import crontab
app.add_periodic_task(
crontab(hour=10, minute=30),
update_content.s()
)
```
这段代码设置了每天的10:30自动更新内容的任务。通过`Celery`,你可以以异步的方式处理大规模的、周期性的内容更新任务。
# 4. ```
# 第四章:Django视图、模板与用户界面
## 4.1 视图逻辑的编写
在Web开发中,视图逻辑是处理客户端请求并返回响应的核心组件。Django通过视图函数和类视图提供了灵活的方式来编写这些逻辑。
### 4.1.1 创建视图函数和类视图
Django的视图可以简单到只是一个返回HTTP响应的函数,也可以是复杂的类,提供更多的功能和灵活性。类视图特别适用于视图有相似行为的情况。
#### 示例代码:使用函数视图
```python
from django.http import HttpResponse
def hello_world(request):
return HttpResponse("Hello, world. You're at the hello_world view.")
```
这段代码定义了一个简单的函数视图,当访问这个视图时,它返回一个包含"Hello, world..."文本的HttpResponse对象。
#### 示例代码:使用类视图
```python
from django.views import View
from django.http import HttpResponse
class HelloWorldView(View):
def get(self, request):
return HttpResponse("Hello, world. You're at the HelloWorldView.")
```
这个例子展示了如何使用Django的类视图来实现和前面函数视图相同的功能。`HelloWorldView`类继承自`View`,并重写了`get`方法来处理GET请求。
### 4.1.2 使用中间件和装饰器增强视图功能
中间件和装饰器为Django视图提供了强大的扩展点,允许开发者在请求处理流程中的特定点插入自定义逻辑。
#### 示例代码:使用装饰器
```python
from django.http import HttpResponse
from django.views.decorators.http import require_http_methods
@require_http_methods(["GET", "POST"])
def my_view(request):
if request.method == "GET":
return HttpResponse("Got a GET request.")
elif request.method == "POST":
return HttpResponse("Got a POST request.")
```
`@require_http_methods`装饰器确保只有在请求方法为GET或POST时,才会调用`my_view`函数。这对于创建RESTful API特别有用。
#### 示例代码:创建中间件
```python
from django.utils.deprecation import MiddlewareMixin
class MyMiddleware(MiddlewareMixin):
def process_request(self, request):
# 在请求处理前做一些处理
pass
```
创建一个中间件类需要继承`MiddlewareMixin`。在这个类中,可以定义`process_request`方法在视图函数处理请求之前执行一些操作,或者`process_response`方法在视图函数处理请求之后执行。
## 4.2 模板引擎的深入应用
Django的模板引擎是MVC架构中的V(视图),负责将数据动态地插入HTML页面。它提供了一种灵活的方式来展示内容。
### 4.2.1 模板继承和包含的高级用法
模板继承是Django模板语言中最强大的特性之一,它允许创建一个基础模板,并让其他模板继承它的内容。
#### 基础模板示例
```django
<!-- base.html -->
<!DOCTYPE html>
<html>
<head>
<title>{% block title %}My Site{% endblock %}</title>
</head>
<body>
{% block content %}
{% endblock %}
</body>
</html>
```
在这个基础模板`base.html`中,我们定义了两个块(`{% block title %}`和`{% block content %}`),这些块可以在继承这个模板的子模板中被重写。
#### 继承基础模板的子模板示例
```django
{% extends "base.html" %}
{% block title %}My Page{% endblock %}
{% block content %}
<p>This is my page.</p>
{% endblock %}
```
在这个子模板中,`{% extends "base.html" %}`声明了它继承自`base.html`。我们可以自定义`title`块和`content`块来为这个页面提供特定的内容。
### 4.2.2 模板中动态内容的展示与控制
在模板中展示动态内容涉及使用变量、标签和过滤器,这些工具帮助我们将从视图传递的数据渲染到HTML中。
#### 使用变量和标签
```django
{% for item in items %}
<p>{{ item.name }}: {{ item.description }}</p>
{% endfor %}
```
在这个例子中,我们使用`{% for %}`标签遍历`items`变量。对于`items`中的每一个元素,我们使用`{{ item.name }}`和`{{ item.description }}`变量来展示元素的属性。
#### 使用过滤器
```django
{{ some_date|date:"Y-m-d" }}
```
`|date:"Y-m-d"`是一个过滤器,它格式化`some_date`变量为`YYYY-MM-DD`格式的日期字符串。过滤器可以用来修改变量的输出方式,它们通过管道符`|`来应用。
## 4.3 用户界面的交互设计
现代Web开发重视用户体验,Django不仅提供了后端逻辑的构建,还通过模板和前端技术的整合支持优秀的用户界面设计。
### 4.3.1 响应式设计的最佳实践
响应式设计允许网页在不同设备上都能提供良好的显示效果,通过媒体查询、灵活的布局和可伸缩的组件实现。
#### 媒体查询示例
```css
@media (max-width: 600px) {
.sidebar {
display: none;
}
}
```
这个CSS媒体查询在屏幕宽度小于600px时,会隐藏侧边栏。这是响应式设计中常用的一个技巧。
### 4.3.2 AJAX与前端框架的整合
AJAX(异步JavaScript和XML)技术允许网页在不重新加载的情况下与服务器通信,并更新部分网页内容。
#### 简单的AJAX示例
```javascript
function load_content(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url, true);
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
document.getElementById("content").innerHTML = xhr.responseText;
}
};
xhr.send();
}
// 调用函数加载内容
load_content('/path/to/content/');
```
这段JavaScript代码展示了如何使用AJAX请求从服务器加载内容,并将其插入到HTML页面中的指定元素内。
通过结合这些技术和最佳实践,开发者可以构建出不仅功能强大,而且界面友好且易于使用的Web应用。
```
# 5. 性能优化与部署策略
## 5.1 Django应用的性能调优
在当今互联网环境下,用户对Web应用的响应速度有着极高的期待。性能调优是确保网站能够快速响应用户请求的关键步骤。Django框架提供了多层级的优化选项,旨在加速应用的处理速度。
### 5.1.1 Django缓存机制的配置与应用
缓存机制是提高Web应用性能的重要手段,它可以存储频繁访问的数据或页面,减少数据库访问次数,从而加快响应速度。
```python
# 在Django的settings.py中配置缓存
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '***.*.*.*:11211',
}
}
```
配置完成后,可以在视图函数中使用缓存:
```python
from django.core.cache import cache
def my_view(request):
# 检查缓存中是否存在数据
value = cache.get('my_key')
if value is None:
# 如果不存在,则进行计算,并将其存储到缓存中
value = compute_heavy_task()
cache.set('my_key', value, timeout=300) # 缓存时间为5分钟
return HttpResponse(str(value))
```
### 5.1.2 SQL查询优化与数据库索引策略
数据库查询性能直接影响Web应用的响应速度。合理的索引设置、减少查询次数和优化查询语句可以显著提升性能。
```sql
-- 假设有一个模型Book,我们经常根据书名搜索书籍
-- 未使用索引的查询
SELECT * FROM books WHERE title LIKE '%Python%';
-- 使用索引的查询
CREATE INDEX idx_title ON books (title);
```
在Django ORM中,查询优化也很重要,例如,使用`select_related`和`prefetch_related`来减少数据库查询次数:
```python
# 使用select_related进行预加载,减少数据库查询
Book.objects.select_related('author').filter(title__icontains='python')
# 使用prefetch_related进行预加载,适用于多对多和反向关系
Book.objects.prefetch_related('authors__books').filter(title__icontains='python')
```
## 5.2 应用的安全加固
随着Web应用的普及,安全问题日益凸显。Django提供了一系列安全特性,来帮助开发者抵御常见的网络攻击。
### 5.2.1 Django的安全配置和常见的安全问题
安全配置是保护应用的第一道防线。Django默认启用了许多安全措施,例如:
- 使用`SECURE_PROXY_SSL_HEADER`防止HTTPS中隐藏的安全问题。
- 通过`SECURE_SSL_REDIRECT`确保所有HTTP请求都重定向到HTTPS。
- 使用`CSRF_TRUSTED_ORIGINS`来指定哪些源可以提交CSRF令牌。
```python
# 在settings.py中启用CSRF保护
CSRF_COOKIE_SECURE = True
CSRF_COOKIE_HTTPONLY = True
```
### 5.2.2 跨站请求伪造(CSRF)和跨站脚本(XSS)的防御
跨站请求伪造(CSRF)和跨站脚本(XSS)是Web应用常见的安全威胁。Django提供了内置的防护机制:
- CSRF保护:Django为所有POST请求生成唯一的CSRF令牌,确保请求是用户主动发起的。
- XSS过滤:Django可以自动过滤模板中的XSS攻击。
```python
# 在模板中使用自动XSS过滤
{{ some_variable|safe }}
```
## 5.3 系统部署与持续集成
系统部署是应用上线前的最后一步,也是保障应用稳定运行的关键。持续集成和持续部署(CI/CD)是现代软件开发中不可或缺的部分。
### 5.3.1 利用Docker进行应用容器化
Docker是一个开源的容器化平台,使得开发者可以将应用和依赖项打包进一个可移植的容器中。
```Dockerfile
# Dockerfile 示例
FROM python:3.8-slim
WORKDIR /app
COPY . /app
RUN pip install -r requirements.txt
CMD ["python", "manage.py", "runserver", "*.*.*.*:8000"]
```
构建镜像并运行容器:
```bash
docker build -t my_django_app .
docker run -d -p 8000:8000 my_django_app
```
### 5.3.2 集成Jenkins实现持续集成与部署流程
Jenkins是一个开源的自动化服务器,可以用来自动化各种任务,例如构建、测试和部署软件。
```groovy
// Jenkinsfile 示例,定义了自动化部署流程
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'python -m venv venv'
sh 'source venv/bin/activate && pip install -r requirements.txt'
}
}
stage('Test') {
steps {
sh 'python manage.py test'
}
}
stage('Deploy') {
steps {
// 这里可以集成Docker部署命令,或直接使用代码部署
}
}
}
}
```
通过容器化和CI/CD流程,可以确保应用的稳定部署,并且在出现问题时能够快速回滚到之前的稳定版本。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Django Syndication Feeds 学习专栏,我们将深入探索 Django 中用于创建和管理内容聚合的强大库。从定制化 Feed 到整合 RESTful API,再到提升性能和国际化支持,我们将提供一系列全面且实用的指南。通过深入剖析代码示例、分享专家策略和提供调试技巧,本专栏将帮助您掌握 Django Syndication Feeds 的方方面面,使您能够高效地分发内容、提升网站性能并优化搜索引擎优化。无论您是 Django 新手还是经验丰富的开发者,本专栏都将为您提供宝贵的见解,帮助您充分利用 Django Syndication Feeds 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入gzip模块的缓冲机制:选择合适的缓冲策略
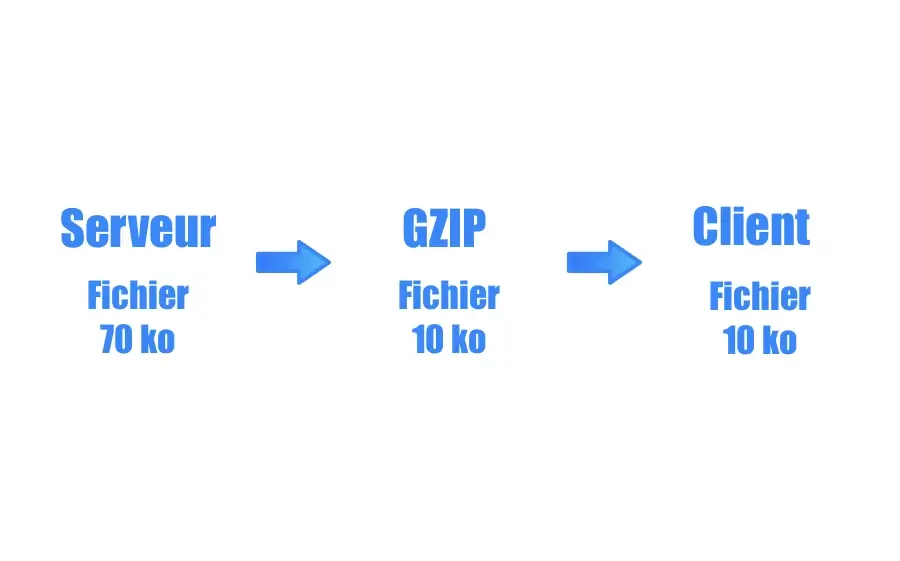
# 1. gzip模块概述与基本使用
在如今数据爆炸的时代,数据压缩变得尤为重要。gzip作为一种广泛使用的文件压缩工具,它通过gzip模块提供了一系列高效的数据压缩功能。本文将首先介绍gzip模块的基本概念、核心功能以及如何在各种环境中进行基本使用。
gzip模块不仅支持Linux、Unix系统,也广泛应用于Windows和macOS等操作系统。它通过DEFLATE压缩算法,能够有效减小文件大小,优化存储空间和网
构建个人JSON库:simplejson设计哲学与实现教程
# 1. JSON数据格式概述
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集。数据在键值对中存储为文本,使用Unicode编码,并且可以跨平台使用。在Web应用中,JSON常用于服务器和客户端之间进行数据传输。
## 1.1 JSON数据的结构
JSON
CherryPy中间件与装饰器剖析:增强Web应用功能的6大策略
# 1. CherryPy中间件与装饰器的基础概念
## 1.1 CherryPy中间件简介
在Web框架CherryPy中,中间件是一种在请求处理流程中起到拦截作用的组件。它能够访问请求对象(request),并且决定是否将请求传递给后续的处理链,或者对响应对象(response)进行修改,甚至完全替代默认的处理方式。中间件常用于实现跨请求的通用功能,例如身份验证、权限控
【Django缓存管理艺术】:django.utils.cache自动化维护与监控策略

# 1. Django缓存机制概览
## Django缓存的核心概念
在深入探讨Django的缓存系统之前,先了解一些核心概念是至关重要的。Django缓存的基本原理是将经常访问的数据保存在内存中,这样当用户请求这些数据时,可以从缓存中迅速地读取,而无需每次都去数据库
【深入email.Utils】:代码层面解析邮件处理的核心工作原理(技术深度解析)

# 1. 深入理解email.Utils的功能与应用
邮件已经成为现代通信不可或缺的一部分,而`email.Utils`库是许多开发者在处理电子邮件任务时的得力助手。本章将深入探讨`email.Utils`的功能和应用,不仅包括库的基础使用方法,还有实际工作中一些高级功能的案例分析。
## 1.1 email.Ut
Python项目中的Tagging Fields策略:高效使用方法与案例分析

# 1. Tagging Fields策略概述
在数据管理与处理的领域中,Tagging Fields策略作为一种创新的数据组织方法,正逐渐成为IT行业关
构建响应式Web界面:Python Models与前端交互指南
# 1. 响应式Web界面设计基础
在当今多样化的设备环境中,响应式Web设计已成为构建现代Web应用不可或缺的一部分。它允许网站在不同尺寸的屏幕上都能提供一致的用户体验,从大型桌面显示器到移动设备。
## 什么是响应式设计
响应式设计(Responsive Design)是一种网页设计方法论,旨在使网站能够自动适应不同分辨率的设备。其核心在于使用流
【Mako模板个性化定制】:打造专属用户体验的个性化模板内容
# 1. Mako模板引擎入门
## 1.1 Mako模板引擎简介
Mako模板引擎是Python中一种广泛使用的模板引擎,以其简洁和高效的特点获得了开发者的青睐。它允许开发者将业务逻辑和展示逻辑分离,从而提高代码的可维护性和可重用性。Mako不仅仅是一个模板引擎,它还支持宏、过滤器等高级特性,
【Django认证与授权】:从零构建django.contrib.auth.decorators指南

# 1. Django认证与授权基础
在当今互联网时代,一个网站或者应用的核心需求之一便是能够验证用户的身份,并提
数据备份新策略:zipfile模块的作用与备份恢复流程
# 1. zipfile模块简介
`zipfile`模块是Python标准库中的一个模块,它提供了一系列用于读取、写入和操作ZIP文件的函数和类。这个模块使用户能够轻松地处理ZIP压缩文件,无论是进行文件的压缩与解压,还是检查压缩文件的内容和结构。对于系统管理员和开发者来说,它是一个强有力的工具,可以用来创建备份、分发文件或者减少文件的存储大小。
本章将为读者展示`zipfile`模块的基础概念,以及它如何简化数据压缩和备份的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )