数据库事务的隔离级别与并发控制
发布时间: 2023-12-16 01:43:51 阅读量: 43 订阅数: 42 
# 简介
## 1.1 数据库事务的定义
数据库事务是指作为单个逻辑工作单位的一系列数据库操作,要么全部成功执行,要么全部失败回滚。事务的目的是维护数据的一致性和完整性。
## 1.2 事务的特性和ACID属性
事务具有以下四个特性,也称为ACID属性:
- **原子性(Atomicity)**:事务中的操作要么全部成功,要么全部失败回滚,不会出现部分执行的情况。
- **一致性(Consistency)**:事务的执行使数据库从一个一致性状态变为另一个一致性状态,即满足事务的预定义规则和约束条件。
- **隔离性(Isolation)**:事务的执行在逻辑上与其他事务隔离,使得每个事务感知不到其他事务的存在。
- **持久性(Durability)**:事务一旦提交,其结果应该被永久保存在数据库中,即使系统发生故障也不会丢失。
## 1.3 并发控制的重要性
在数据库系统中,可能有多个事务同时访问和操作数据库。并发访问可以提高系统的吞吐量和响应时间,但同时也会引发一些问题,如读写冲突、脏读、不可重复读和幻读。为了保证数据的一致性和避免并发访问引发的问题,需要进行并发控制。
并发控制的目标是确保事务的隔离性,即使多个事务并发执行,也能保证对数据库的操作结果与串行执行相同。同时,也需要平衡并发控制对性能的影响,以提高系统的吞吐量和响应时间。
## 2. 隔离级别的概念
隔离级别是指在数据库中多个事务之间的隔离程度,以及允许并发访问的方式。它定义了一个事务能够看到其他事务的结果以及其他事务能够看到该事务的结果的方式。数据库管理系统提供了不同的隔离级别,以满足不同的应用场景和需求。
在并发环境中,多个事务可能同时访问同一个数据项。如果没有合适的隔离级别和并发控制机制,这种并发访问可能导致数据不一致或者丢失的问题。因此,了解和选择合适的隔离级别和并发控制方法至关重要。
### 2.1 隔离级别的定义
隔离级别指定了一组规则,用于控制在并发事务中发生的读和写操作之间的相互影响。隔离级别越高,事务间的隔离越严格,但在一定程度上也会影响并发性能。
常见的隔离级别有以下四种:
1. 读未提交(Read Uncommitted):事务可以读取其他事务未提交的数据。这种隔离级别最低,事务间的隔离最小。
2. 读已提交(Read Committed):事务只能读取其他事务已经提交的数据。读取到的数据是一致的,但在同一事务内可能有不同的结果。
3. 可重复读(Repeatable Read):在同一事务内,多次读取同一数据项时,会得到一致的结果。即使其他事务对该数据项进行了修改,该事务读取的结果也不会改变。
4. 串行化(Serializable):最高的隔离级别,确保每个事务之间完全串行执行,可以避免所有并发问题。但在性能和并发性方面表现最差。
### 2.2 事务隔离级别的种类
不同的数据库管理系统可能支持不同的事务隔离级别,但一般都会支持上述的四种基本级别。此外,一些数据库还提供了其他的扩展隔离级别,如快照隔离(Snapshot Isolation)和可序列化快照隔离(Serializable Snapshot Isolation)等。
### 2.3 每种隔离级别的特点和应用场景
- **读未提交(Read Uncommitted)**:事务可以读取其他事务未提交的数据,导致脏读(Dirty Read)的问题。适用于对数据一致性要求不高但并发性要求较高的场景。
- **读已提交(Read Committed)**: 事务只能读取其他事务已经提交的数据,避免了脏读问题,但可能出现不可重复读(Non-repeatable Read)的问题。适用于对数据一致性和并发性要求较为平衡的场景。
- **可重复读(Repeatable Read)**:在同一事务内,多次读取同一数据项时,会得到一致的结果,避免了脏读和不可重复读问题。但仍可能出现幻读(Phantom Read)的问题。适用于对数据一致性要求较高但对并发性要求稍低的场景。
- **串行化(Serializable)**:最高的隔离级别,确保每个事务之间完全串行执行,避免了所有并发问题。适用于对数据一致性要求最高的场景,但对并发性能要求较低。
选择合适的隔离级别需要根据业务需求和应用场景进行综合考虑。过高的隔离级别可能导致并发性能下降,而过低的隔离级别可能导致数据不一致问题。因此,在实际应用中需要权衡一致性和并发性能的关系,选择合适的隔离级别。
### 3. 并发控制的基本原理
在数据库管理系统中,并发控制是一个重要的概念,它涉及到多个事务同时访问和操作数据库时可能出现的问题。并发控制的基本原理包括以下内容:
#### 3.1 数据库中的并发问题
在多用户环境下,数据库可能面临多个事务同时读取和修改数据的情况。这种并发访问可能会导致以下问题:
- **丢失更新(Lost Update)**:两个事务同时读取同一行数据,然后同时对数据进行修改,其中一个事务的修改会覆盖另一个事务的修改,导致数据丢失。
- **脏读(Dirty Read)**:一个事务读取了另一个事务未提交的数据,然后基于这些未提交的数据进行操作。如果另一个事务回滚,读取的数据就是无效的。
- **不可重复读(Non-Repeatable Read)**:一个事务在多次读取同一行数据时,由于其他事务的修改,导致每次读取的结果不一致。
- **幻读(Phantom Read)**:一个事务在同一条件下多次查询时,由于其他事务的插入或删除操作,导致每次查询返回的结果集不一致。
#### 3.2 并发控制的基本概念
为了解决并发访问可能导致的问题,数据库管理系统采用了一系列并发控制的方法和技术,包括锁、事务时间戳、多版本并发控制(MVCC)和乐观并发控制等。
- **锁**:通过对数据进行加锁,限制并发事务对数据的访问,确保数据的一致性和隔离。
- **事务时间戳**:为每个事务分配一个时间戳,通过比较事务时间戳来确定事务的执行顺序,从而避免并发访问问题。
- **多版本并发控制(MVCC)**:数据库系统对数据的不同版本进行管理,实现不同事务之间的隔离,从而避免丢失更新和不可重复读等问题。
- **乐观并发控制**:假设并发冲突不常见,允许事务在提交时进行数据一致性的检查,从而减少加锁对并发性能的影响。
#### 3.3 为什么需要并发控制
### 4. 事务的隔离级别
事务的隔离级别决定了事务之间相互影响的程度。在并发环境中,不同事务之间的读写操作可能会出现一系列问题,如脏读、不可重复读、幻读等。为了解决这些问题,数据库引入了不同的隔离级别。
#### 4.1 读未提交(Read Uncommitted)
读未提交是最低的隔离级别,在该级别下,事务可以读取其他事务未提交的数据。这样可能导致脏读的问题,读到的数据可能是临时的、不准确的或无效的。
示例代码(Python):
```python
import pymysql
# 创建连接
conn = pymysql.connect(host='localhost', user='root', password='123456', db='test', charset='utf8mb4')
# 创建游标
cursor = conn.cursor()
try:
# 开启事务
conn.begin()
# 设置隔离级别为读未提交
cursor.execute("SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED")
# 执行查询语句
cursor.execute("SELECT * FROM users")
# 输出结果
for row in cursor.fetchall():
print(row)
# 提交事务
conn.commit()
except Exception as e:
# 回滚事务
conn.rollback()
print(f"Error: {e}")
# 关闭连接
cursor.close()
conn.close()
```
以上代码演示了在读未提交隔离级别下,事务可以读取到其他未提交的数据。但是,这样的读取是不可靠的,可能会产生脏读。
#### 4.2 读已提交(Read Committed)
读已提交是默认的隔离级别,在该级别下,事务只能读取已经提交的数据。这样可以避免脏读的问题,但是可能会导致不可重复读和幻读的问题。
示例代码(Java):
```java
import java.sql.*;
public class ReadCommittedIsolationLevelExample {
public static void main(String[] args) {
// 连接数据库
String jdbcUrl = "jdbc:mysql://localhost:3306/test?useSSL=false";
String username = "root";
String password = "123456";
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 创建连接
Connection connection = DriverManager.getConnection(jdbcUrl, username, password);
// 设置隔离级别为读已提交
connection.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
// 创建语句
Statement statement = connection.createStatement();
try {
// 开启事务
connection.setAutoCommit(false);
// 执行查询语句
ResultSet resultSet = statement.executeQuery("SELECT * FROM users");
// 输出结果
while (resultSet.next()) {
System.out.println("ID: " + resultSet.getInt("id") + ", Name: " + resultSet.getString("name"));
}
// 提交事务
connection.commit();
} catch (Exception e) {
// 回滚事务
connection.rollback();
e.printStackTrace();
}
// 关闭连接
statement.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
以上示例代码演示了在读已提交隔离级别下,事务只能读取已提交的数据,避免了脏读。但是,由于其他事务可以在事务进行过程中对数据进行更新,因此可能会导致不可重复读和幻读的问题。
#### 4.3 可重复读(Repeatable Read)
可重复读是保证事务期间读取的数据是一致的隔离级别。在该级别下,事务会锁定读取的数据,其他事务无法对该数据进行修改,从而避免了不可重复读的问题。
示例代码(Go):
```go
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// 连接数据库
db, err := sql.Open("mysql", "root:123456@tcp(localhost:3306)/test")
if err != nil {
fmt.Println(err)
return
}
defer db.Close()
// 开启事务
tx, err := db.Begin()
if err != nil {
fmt.Println(err)
return
}
// 设置隔离级别为可重复读
_, err = tx.Exec("SET TRANSACTION ISOLATION LEVEL REPEATABLE READ")
if err != nil {
fmt.Println(err)
return
}
// 执行查询语句
rows, err := tx.Query("SELECT * FROM users")
if err != nil {
fmt.Println(err)
return
}
defer rows.Close()
// 输出结果
for rows.Next() {
var id int
var name string
err := rows.Scan(&id, &name)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("ID: %d, Name: %s\n", id, name)
}
// 提交事务
err = tx.Commit()
if err != nil {
fmt.Println(err)
return
}
}
```
以上示例代码演示了在可重复读隔离级别下,事务可以读取到一致的数据,并且其他事务无法对该数据进行修改,避免了不可重复读的问题。但是,可能会出现幻读问题,即其他事务在事务进行过程中插入新的数据。
#### 4.4 串行化(Serializable)
串行化是最高的隔离级别,在该级别下,事务会完全串行地执行,保证事务之间的互相影响问题完全被避免。不会出现脏读、不可重复读和幻读等问题,但是会降低数据库的并发性能。
示例代码(JavaScript):
```javascript
const mysql = require('mysql');
// 创建连接池
const pool = mysql.createPool({
host: 'localhost',
user: 'root',
password: '123456',
database: 'test',
connectionLimit: 10,
});
// 设置隔离级别为串行化
pool.getConnection((err, connection) => {
if (err) {
console.error(err);
return;
}
connection.query('SET TRANSACTION ISOLATION LEVEL SERIALIZABLE', (err) => {
if (err) {
console.error(err);
return;
}
// 开启事务
connection.beginTransaction((err) => {
if (err) {
console.error(err);
return;
}
// 执行查询语句
connection.query('SELECT * FROM users', (err, results) => {
if (err) {
console.error(err);
return;
}
// 输出结果
results.forEach((row) => {
console.log(`ID: ${row.id}, Name: ${row.name}`);
});
// 提交事务
connection.commit((err) => {
if (err) {
console.error(err);
connection.rollback();
return;
}
// 关闭连接
connection.release();
});
});
});
});
});
```
以上示例代码演示了在串行化隔离级别下,事务会完全串行地执行,保证了事务之间的互相影响问题完全被避免。不会出现脏读、不可重复读和幻读等问题。但是,由于串行化执行的特性,会降低数据库的并发性能。
#### 4.5 其他数据库支持的隔离级别
除了上述四个基本的隔离级别,不同的数据库还可能支持其他的隔离级别,如Oracle数据库支持的读写一致性(Read Consistency)、SQL Server数据库支持的快照隔离级别(Snapshot Isolation)等。这些隔离级别的具体特点和应用场景可以根据不同数据库的文档进行了解。
### 5. 并发控制的方法
并发控制是确保多个并发事务在数据库中执行时保持一致性的关键技术。下面介绍常用的几种并发控制方法。
#### 5.1 锁
锁是最常用的并发控制方法之一。当事务访问某个数据项时,可以通过给该数据项加锁来防止其他事务同时修改该数据项。锁分为共享锁和排他锁。共享锁允许多个事务同时读取数据,但不允许其他事务对该数据项进行修改。排他锁则只允许一个事务对数据项进行读写操作。锁的粒度可以是整个数据库、数据表、数据页或数据行。在使用锁进行并发控制时,需要注意死锁的问题,并采取相应的解决方法。
下面是一个使用锁的示例代码(使用Python语言):
```python
# 获取共享锁
def acquire_shared_lock(data_item):
# 加锁逻辑
pass
# 获取排他锁
def acquire_exclusive_lock(data_item):
# 加锁逻辑
pass
# 释放锁
def release_lock(data_item):
# 释放锁逻辑
pass
# 事务1
def transaction1():
acquire_shared_lock(data_item)
# 事务1的操作逻辑
release_lock(data_item)
# 事务2
def transaction2():
acquire_exclusive_lock(data_item)
# 事务2的操作逻辑
release_lock(data_item)
```
#### 5.2 事务时间戳
事务时间戳是一种基于时间戳的并发控制方法。每个事务在开始时都被分配一个唯一的时间戳,事务的执行顺序按照时间戳的先后顺序进行。当一个事务要访问一个数据项时,会比较自己的时间戳与该数据项的读时间戳和写时间戳,根据比较结果确定是否允许访问。这种方法可以避免锁带来的死锁问题,但需要额外的存储空间来存储时间戳信息。
下面是一个使用事务时间戳的示例代码(使用Java语言):
```java
// 事务类
class Transaction {
private int timestamp;
public Transaction(int timestamp) {
this.timestamp = timestamp;
}
public int getTimestamp() {
return timestamp;
}
// 其他事务操作的方法
}
// 数据项类
class DataItem {
private int readTimestamp;
private int writeTimestamp;
public int getReadTimestamp() {
return readTimestamp;
}
public int getWriteTimestamp() {
return writeTimestamp;
}
public void setReadTimestamp(int readTimestamp) {
this.readTimestamp = readTimestamp;
}
public void setWriteTimestamp(int writeTimestamp) {
this.writeTimestamp = writeTimestamp;
}
}
// 并发控制类
class ConcurrencyControl {
private int globalTimestamp = 0;
public int assignTimestamp() {
globalTimestamp++;
return globalTimestamp;
}
public boolean validateRead(Transaction transaction, DataItem dataItem) {
int transactionTimestamp = transaction.getTimestamp();
int readTimestamp = dataItem.getReadTimestamp();
int writeTimestamp = dataItem.getWriteTimestamp();
return transactionTimestamp >= readTimestamp && transactionTimestamp >= writeTimestamp;
}
public boolean validateWrite(Transaction transaction, DataItem dataItem) {
int transactionTimestamp = transaction.getTimestamp();
int writeTimestamp = dataItem.getWriteTimestamp();
return transactionTimestamp >= writeTimestamp;
}
}
// 示例代码
Transaction transaction1 = new Transaction(concurrencyControl.assignTimestamp());
Transaction transaction2 = new Transaction(concurrencyControl.assignTimestamp());
DataItem dataItem = new DataItem();
// 事务1读取数据项
if (concurrencyControl.validateRead(transaction1, dataItem)) {
// 事务1的读操作
}
// 事务2写入数据项
if (concurrencyControl.validateWrite(transaction2, dataItem)) {
// 事务2的写操作
}
```
#### 5.3 多版本并发控制(MVCC)
多版本并发控制(MVCC)是一种基于多个数据版本的并发控制方法。当一个事务开始时,会获取当前的数据库快照,并在该快照上执行。每个数据项会保存多个版本,每个版本都记录了该数据项在某个时间点的值。当事务要读取数据时,会根据自己的时间戳选择合适的版本进行读取。这种方法可以避免锁带来的并发性能问题。
#### 5.4 乐观并发控制
乐观并发控制是一种基于冲突检测的并发控制方法。事务在执行时不对数据加锁,而是在提交时检查是否存在冲突。当一个事务要提交时,会检查其他事务是否已经修改了事务要提交的数据项。如果存在冲突,事务需要放弃提交并重新执行。这种方法适用于并发冲突较少的场景,可以提高并发性能。
### 本章小结
本章介绍了常用的并发控制方法,包括锁、事务时间戳、多版本并发控制和乐观并发控制。每种方法都有不同的应用场景,选择合适的方法可以提高数据库的并发性能和数据一致性。在实践中,需要根据具体的需求和业务场景来选择适当的并发控制策略。
## 6. 优化并发控制策略
在实际应用中,优化并发控制策略是至关重要的,可以提高数据库系统的性能和吞吐量。以下是一些优化并发控制策略的建议:
### 6.1 优化数据库设计
良好的数据库设计可以减少数据访问的复杂性,降低并发冲突的可能性。合理的范式设计、索引设计、以及合适的数据分片方式都可以有效优化数据库设计,提高并发控制的效率。
```sql
-- 示例:使用合适的索引优化数据库查询
CREATE INDEX idx_customer_name ON customer (name);
```
### 6.2 使用合适的隔离级别
根据应用场景的需要,选择合适的事务隔离级别也是优化并发控制的关键。对于读密集型系统可以选择较低的隔离级别,而对于写密集型系统可能需要更高的隔离级别。
```java
// 示例:设置事务隔离级别为可重复读
connection.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
```
### 6.3 性能与一致性的权衡
在设计并发控制策略时,需要权衡系统的性能和数据的一致性。有时候可以通过牺牲一定的一致性来换取更好的性能,例如采用乐观并发控制。
### 6.4 避免死锁
合理的并发控制策略还需要注意避免死锁的发生。可以通过合理的事务设计、资源加锁顺序的规定等方式来避免死锁的发生。
```python
# 示例:使用加锁顺序来避免死锁
SELECT * FROM table1 FOR UPDATE;
SELECT * FROM table2 FOR UPDATE;
```
### 6.5 实践中的并发控制技巧
在实际应用中,还可以根据具体场景灵活运用各种并发控制的技巧,如分批处理、异步处理、缓存技术等,来优化并发控制策略,提升系统性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏主要关注数据库事务回滚日志和审计技术,通过一系列相关文章的介绍,探讨了数据库事务的基本概念、实现原理、隔离级别与并发控制,以及回滚日志的机制、存储与管理等方面。同时还涵盖了基于日志的数据库事务恢复技术,以及数据库事务审计技术的概述,包括审计日志的生成与记录方式、持久化存储与保护、查询与分析工具,以及实时监控与报警系统等。此外,还讨论了审计日志的安全保护与加密技术、自动化清理与归档策略、应用于合规性与安全审计等应用场景。最后,还介绍了数据库审计技术中的异常检测与预防、与身份验证技术的集成、事务与审计日志的实时传输与同步、高性能存储与查询优化,以及故障排除与诊断技术等相关内容。通过这些文章的阐述,读者可全面了解数据库事务回滚日志和审计技术的原理、应用和实践,从而更好地保护和管理数据库系统的安全与完整性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【嵌入式系统实战】:如何巧妙利用MX25L25645G数据手册
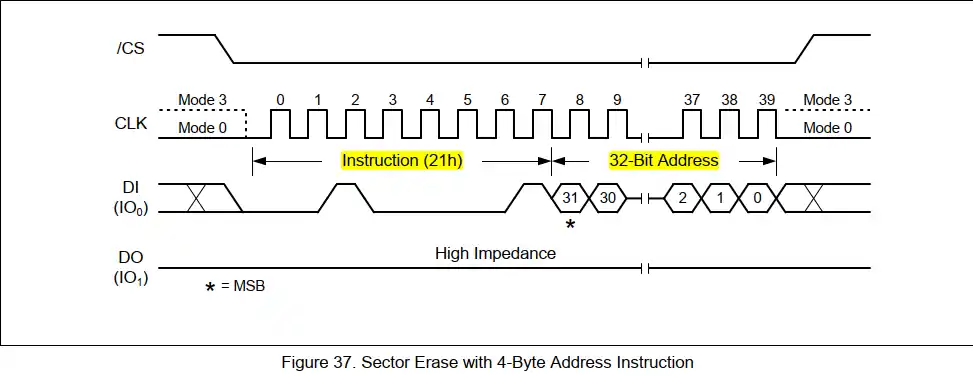
参考资源链接:[MX25L25645G:32M SPI Flash Memory with CMOS MXSMIO Protocol & DTR Support](https://wenku.csdn.net/doc/6v5a8g2o7w?spm=1055.2635.3001.10343)
# 1. 嵌入式系统与MX25L25645G简介
嵌入式系统是信息技术的核心,广泛应用于消费电子
GSM 03.40协议栈分析:网络层优化的5个关键策略

参考资源链接:[GSM 03.40:短消息传输协议详解](https://wenku.csdn.net/doc/6412b4b1be7fbd1778d407d0?spm=1055.2635.3001.10343)
# 1. GSM 03.40协议栈概述
## GSM 03.40协议栈概述
GSM 03.40协议是GSM(全球移动通信系统)标准的核心组成部分,它定义了移动终端和网络之间的无
STM32F407裸机编程指南
参考资源链接:[STM32F407中文手册:ARM内核微控制器详细指南](https://wenku.csdn.net/doc/6412b69dbe7fbd1778d4
【注册不再难】Spire.Doc for Java失败分析与对策

参考资源链接:[全面破解Spire.Doc for Java注册限制,实现全功能无限制使用](https://wenku.csdn.net/doc/1g1oinwimh?spm=1055.2635.3001.10343)
# 1. Spire.Doc for Java
【Origin线性拟合技巧全解】:在复杂数据中寻找最佳线性拟合

参考资源链接:[Origin中线性拟合参数详解:截距、斜率与相关分析](https://wenku.csdn.net/doc/6m9qtgz3vd?spm=1055.2635.3001.10343)
# 1. Origin线性拟合基础
Origin软件以其强大的数据处理和图表绘制功能,被广泛应用于科学研究和工程
FLAC3D操作界面布局全攻略:让模拟效率翻倍
参考资源链接:[FLAC3D中文手册:入门与应用指南](https://wenku.csdn.net/doc/647d6d7e543f8444882a4634?spm=1055.2635.3001.10343)
# 1. FLAC3D软件概述与界面介绍
## 1.1 FLAC3D软件的简介
FLAC3D(Fast Lagrangian Analysis of Continua in 3 Dimensions)是一款在岩
【印刷设计色彩转换】:RGB与印刷,专家告诉你如何校对与管理
参考资源链接:[色温所对及应的RGB颜色表](https://wenku.csdn.net/doc/6412b77bbe7fbd1778d4a745?spm=1055.2635.3001.10343)
# 1. 印刷设计中的色彩转换概述
在印刷设计领域,色彩转换是实现高质量印刷品的关键环节。色彩转换不仅涉及到色彩理论,更是一门将理论应用于实际的艺术。正确的色彩转换能够保证设计在不同介质
STM32 HAL库多线程应用:RTOS集成与任务管理

参考资源链接:[STM32CubeMX与STM32HAL库开发者指南](https://wenku.csdn.net/doc/6401ab9dcce7214c316e8df8?spm=1055.2635.3001.10343)
# 1. STM32 HAL库多线程概述
在嵌入式系统设计领域,STM32微控制器因其高性能和灵活的配置而广受欢迎。随着应用的复杂性增加
【网络编程学习路径】
参考资源链接:[Java解决SocketException:Connection reset异常](https://wenku.csdn.net/doc/6401abb1cce7214c316e9287?spm=1055.2635.3001.10343)
# 1. 网络编程基础概念与原理
## 1.1 网络编程的基本概念
网络编程是通过
AT89C52 LED显示与控制技术:打造炫酷的显示效果
参考资源链接:[AT89C52中文手册](https://wenku.csdn.net/doc/6412b60dbe7fbd1778d4558d?spm=1055.2635.3001.10343)
# 1. AT89C52微控制器基础介绍
微控制器是现代电子设计不可或缺的核心组件之一,它们在自动化控制领域扮演着至关重要的角色。在众多微控制器中,AT89C52以其可靠性、灵活性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )